Colour versus Shape Goal Misgeneralization in Reinforcement Learning: A Case Study
post by Karolis Jucys (karolis-ramanauskas) · 2023-12-08T13:18:39.548Z · LW · GW · 1 commentsThis is a link post for https://arxiv.org/abs/2312.03762
Contents
TL;DR Abstract What is goal misgeneralization? Measuring preferences and capabilities Retraining 100 times Changing objects Backgrounds RGB colour encoding Music metaphor Outliers Relevance to large models Conclusion None 1 comment
TL;DR
Different misgeneralized goals can appear based on training random seed alone, including outliers on a scale of 1 in 500.
Abstract
We explore colour versus shape goal misgeneralization originally demonstrated
by Di Langosco et al. (2022) in the Procgen Maze environment, where, given
an ambiguous choice, the agents seem to prefer generalization based on colour
rather than shape. After training over 1,000 agents in a simplified version of the
environment and evaluating them on over 10 million episodes, we conclude that the
behaviour can be attributed to the agents learning to detect the goal object through
a specific colour channel. This choice is arbitrary. Additionally, we show how,
due to underspecification, the preferences can change when retraining the agents
using exactly the same procedure except for using a different random seed for the
training run. Finally, we demonstrate the existence of outliers in out-of-distribution
behaviour based on training random seed alone.
For full details see the paper. This post is a version with less text, more visuals and a bit of extra content.
What is goal misgeneralization?
Let's say you train an agent to reach a yellow line from pixels:

After training, you let it choose between a red line and a yellow gem. Which will it pick?

Spoilers ahead!

It capably picks the yellow gem. If the designer intended the goal to be based on shape and not colour, goal misgeneralization occurred.
Measuring preferences and capabilities
The above agent reaches the yellow gem first 81% of the time and takes 4 steps on average. We will call these two numbers "preferences" and "capabilities". Goal misgeneralization requires intact capabilities and unintended goal preferences.
Retraining 100 times
Let's retrain the agent 100 times with different random seeds[1] and test each one in the same red line versus yellow gem experiment.
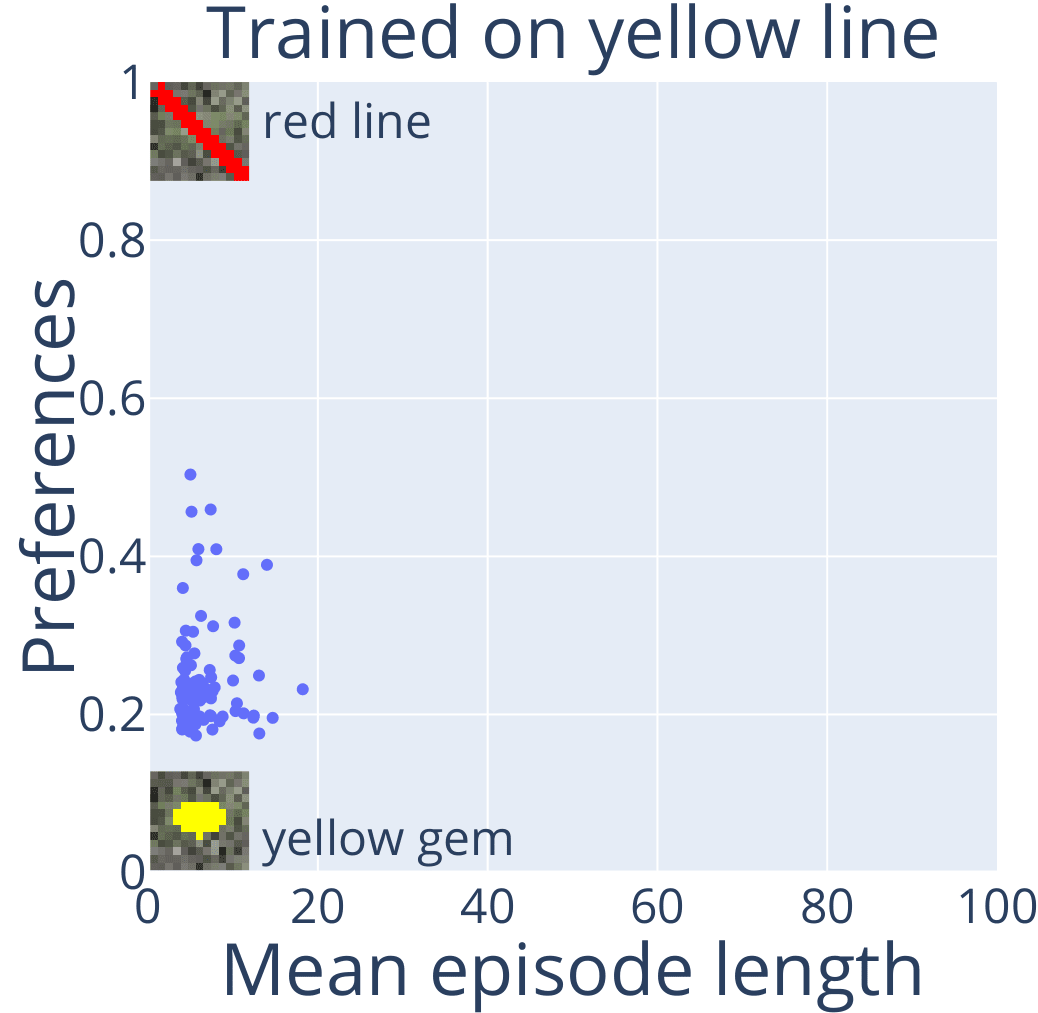
Each dot is an agent with corresponding preferences and capabilities. Most agents capably reach for the yellow gem. A few don't care and pick 50/50.
Changing objects
Why test on the red line though? Let's try a green line versus a yellow gem instead.

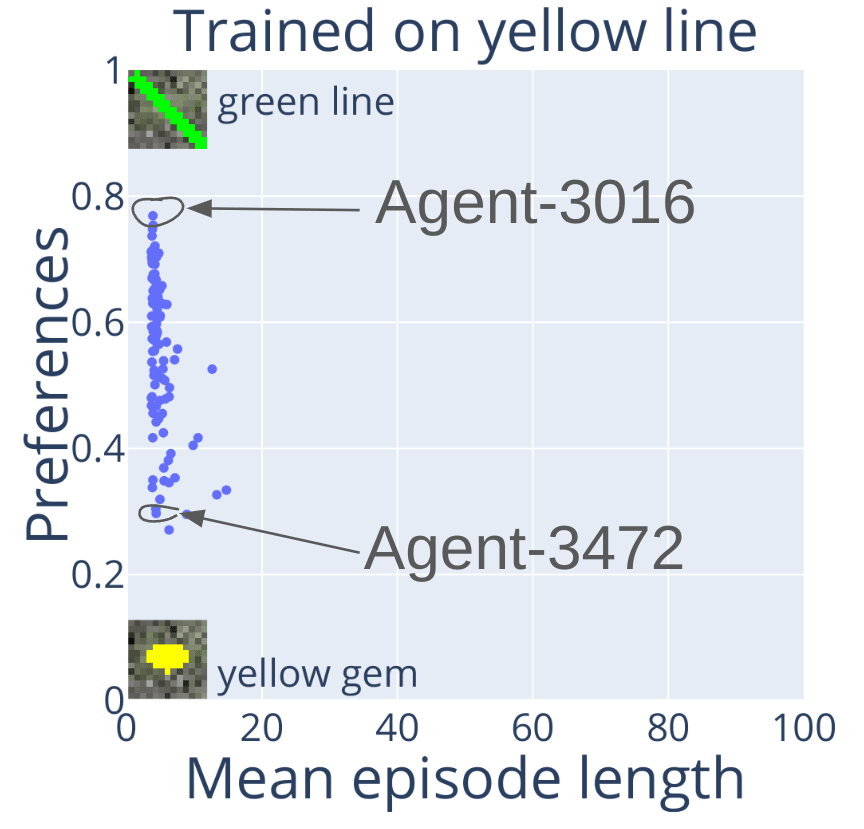
Same 100 agents, but now many prefer the green line, that is, the shape. Also, Agent-3016 (the number is the training random seed) prefers the green line, while Agent-3472 prefers the yellow gem. Both are fully capable. Different goals based on training random seed? Uh-oh...
To illustrate, here's Agent-3016 in action:

And Agent-3472:

What would happen if we replaced the green line with a blue line?
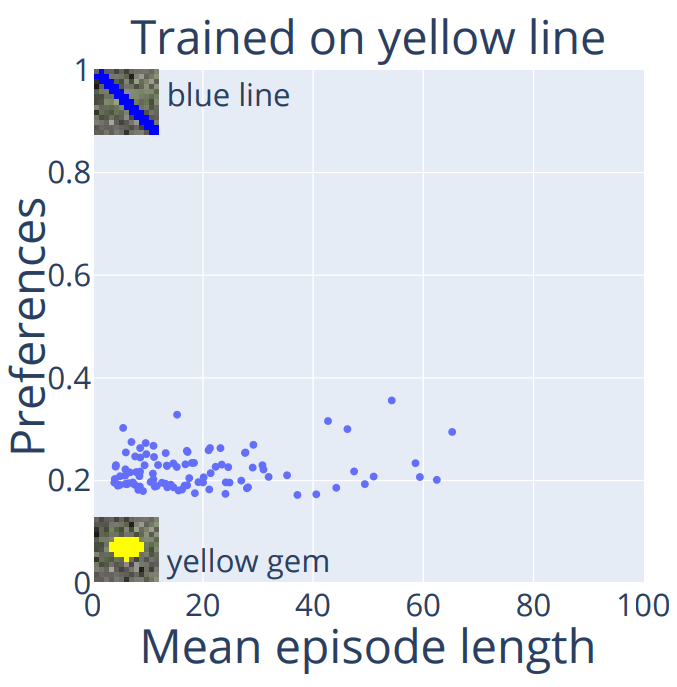
All agents prefer the yellow gem and some lose capabilities. Interesting.
What is causing the different behaviour distributions when we change the colour of the line?
Backgrounds
There are nine background textures and they're not evenly distributed between the red, green and blue channels:
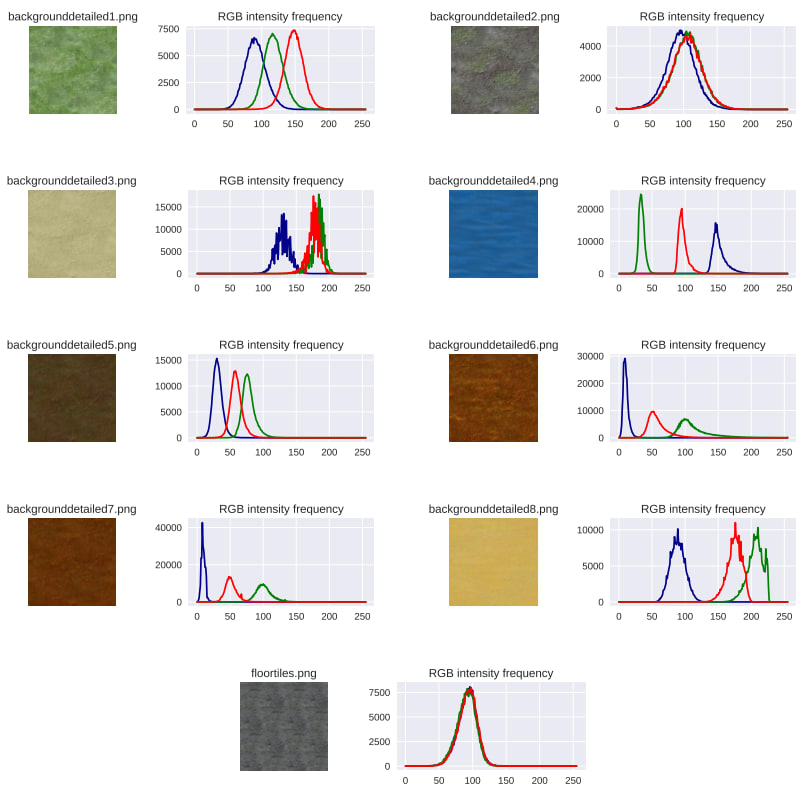
Let's try replacing the textures with black colour and train 100 new agents:

Evaluate them in the same three settings (red/green/blue line vs yellow gem). The top row is the previous 3 plots, bottom row is the 100 new agents:
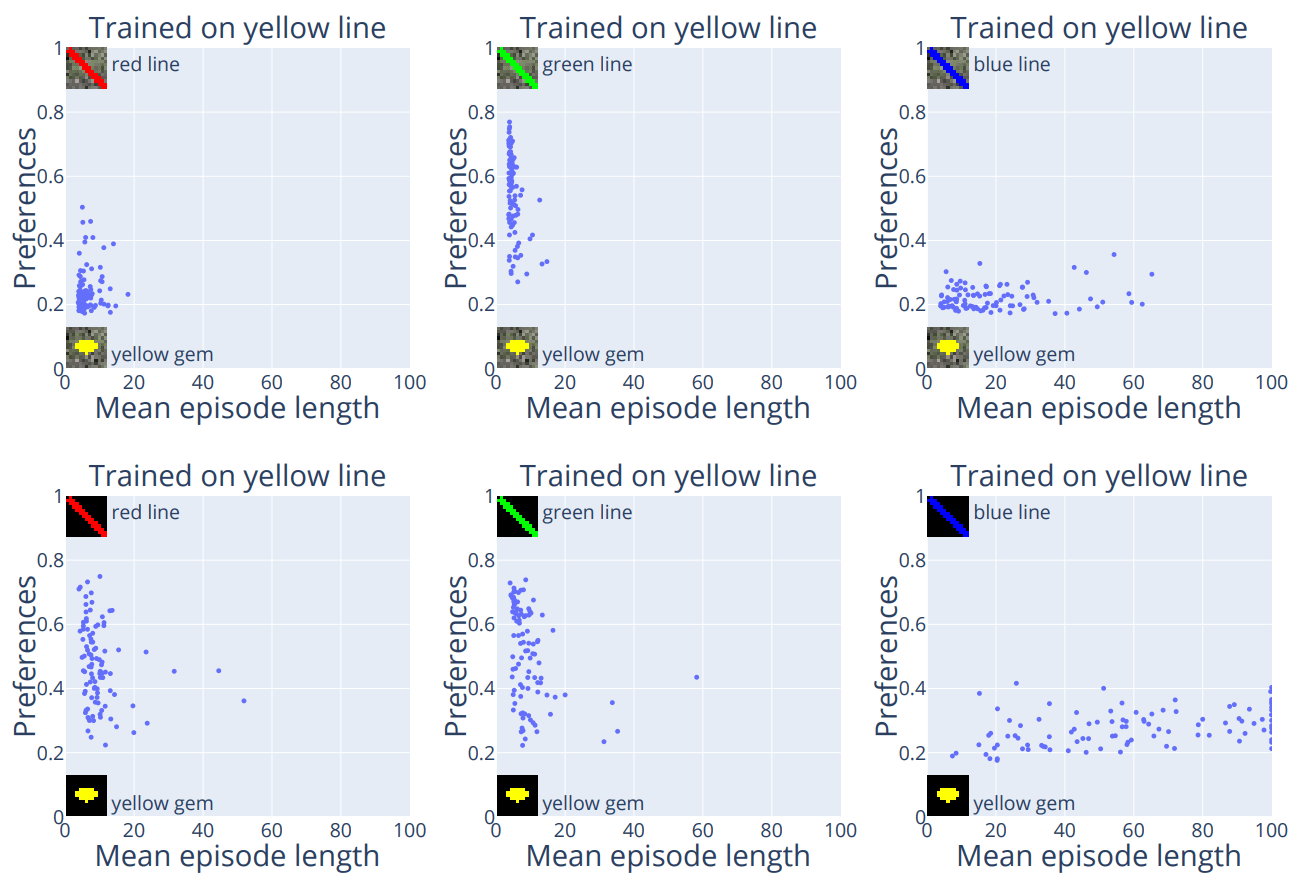
The asymmetry between the red and green lines disappeared. The blue line plot shows more capability loss.
RGB colour encoding
The pixel observations are represented as 64x64x3 matrices, that is three square 2D matrices, one for each of the red, green and blue colours. It's as if the agent has three eyes and observations from a single eye are often enough to solve the task.
Here's what the training observations look like to humans and the three channels seen by the agents:

Same thing with black backgrounds:

On a black background, yellow = red + green.
Here are all the line object splits into RGB both with and without textures (top line = human view):

And here are the red line versus yellow gem test environments split into RGB:


During training, the task was underspecified and the agents could choose an arbitrary channel through which to learn it. Did the agents that chose the green channel turn out to be the ones that prefer the yellow gem? We ran a simple regression to find out:
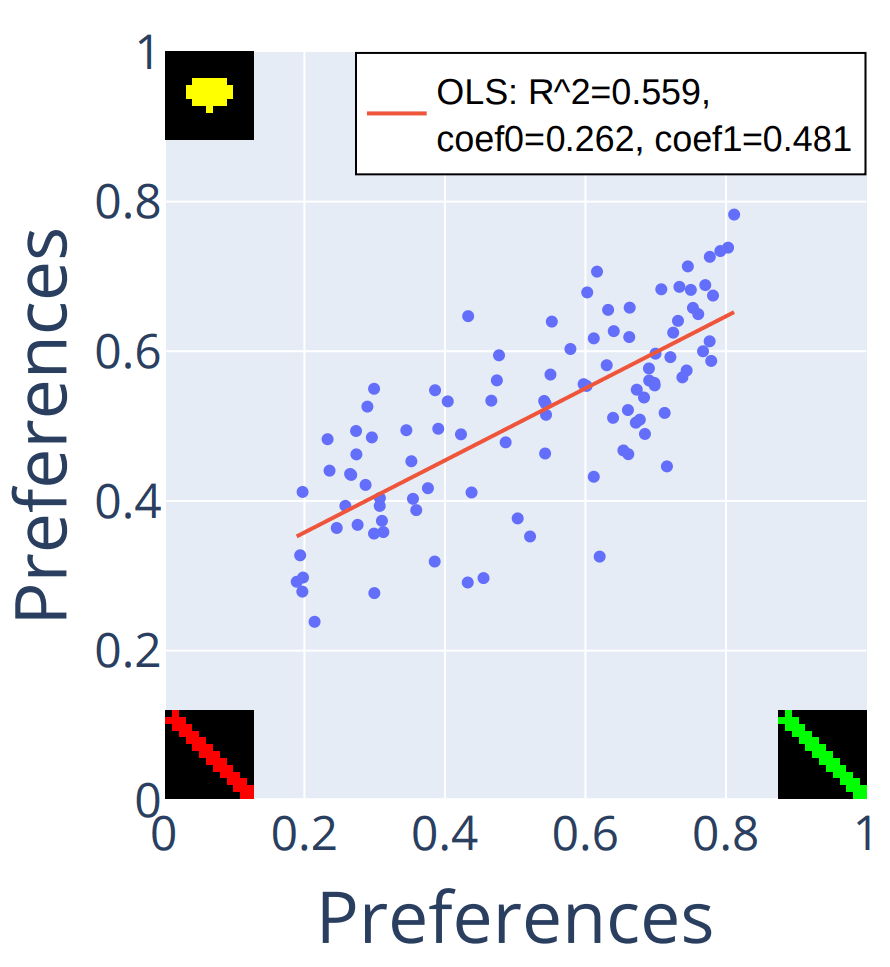
Agents that prefer the green line over the yellow gem are often the same ones that prefer the green line over the red line. But it's not the whole story, especially when you consider agents like the one closest to the bottom right - its preferences are green line over red line over yellow gem.
Music metaphor
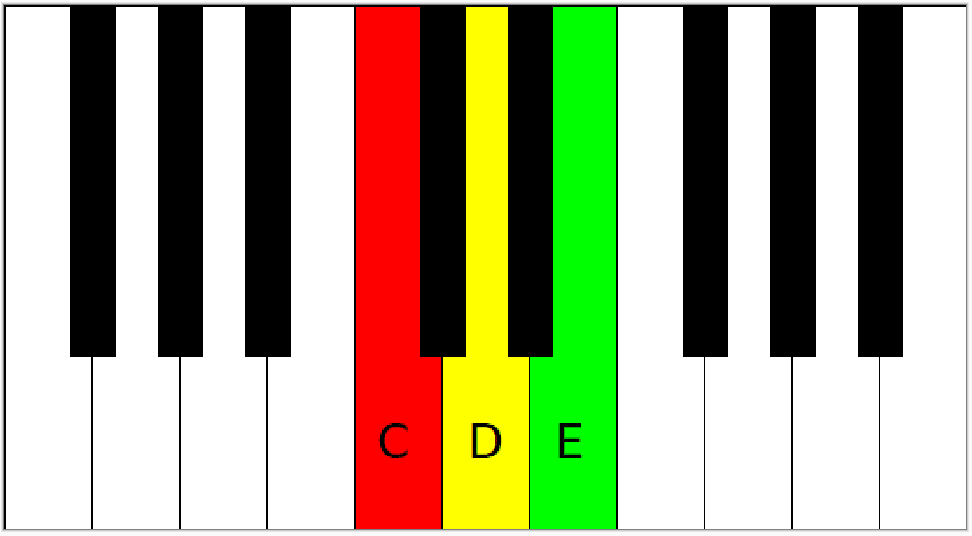
A nice metaphor to illustrate this is music, where what we call "sound" is waves between 20 and 20,000 Hz, while visible light is waves between 400 and 700 THz. If notes C and E are played on the piano at the same time, a human hears both of them, instead of hearing note D. If note C represents red and note E represents green, D will represent yellow. Humans can't even distinguish monochromatic yellow from yellow produced by mixing red and green light rays, while the agents only see yellow as red and green.

Uhhh, no Chatty, don't use DALL-E for that... Just write a Python script to make the image, please.
...
(too many prompts later)
...
Outliers
After noticing some outliers in the previous plots we decided to train 500+ agents to reach a white line on a black background. White is red + green + blue, so now there are more arbitrary options to choose from for learning.

We evaluated them in 11 different settings, measuring preferences and capabilities, giving us a dataset of size 512x22:
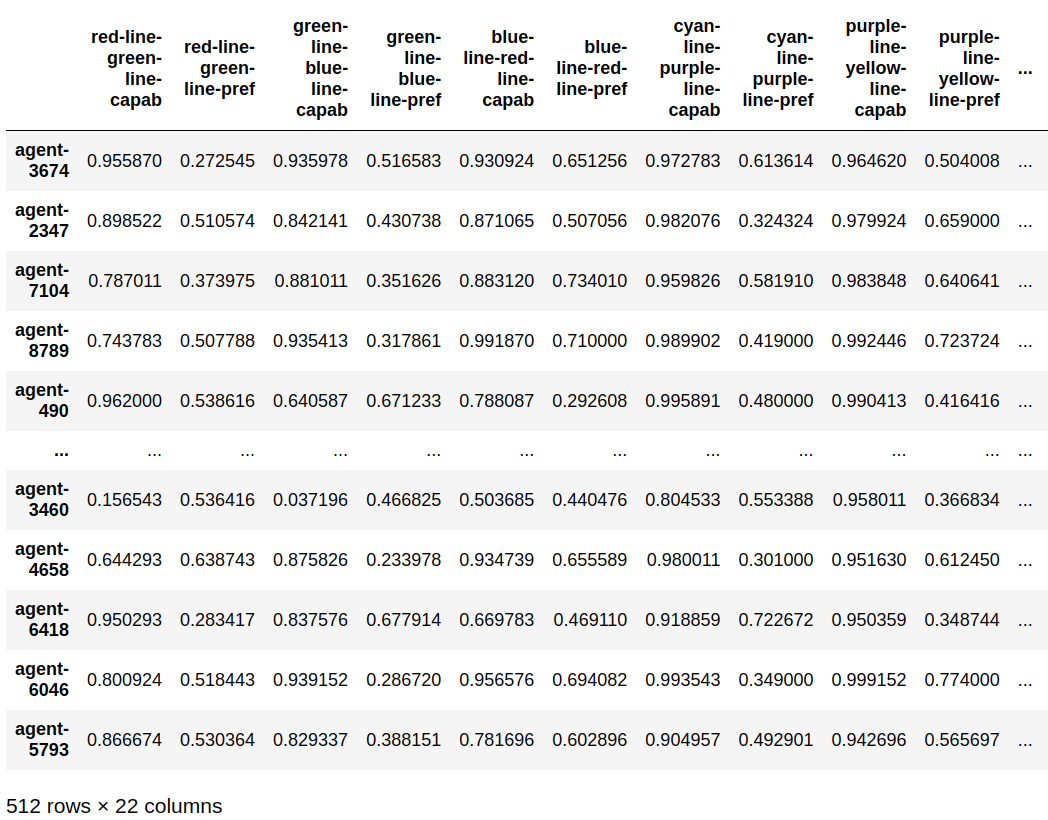
Using manual inspection and clustering/outlier detection algorithms helped us find around 10 various outliers in terms of behaviour. Check the paper for the full list. Here's an example:
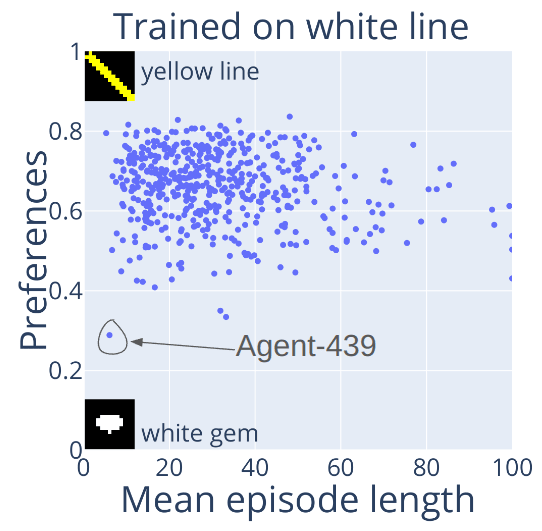
Agent-439 is the only agent out of 512 to prefer a white gem over a yellow line while retaining full capabilities. Goal misgeneralization based on bad luck? Another uh-oh...
Relevance to large models
Is this something that can only happen in toy models though? Perhaps. But here's some evidence that it could also happen in large models. In the MultiBERTs paper, Sellam et al. train 25 BERT models where only the random seed differs between the training runs. They then evaluate all of them on the Winogender bias correlation test (the doctor = male, nurse = female thing):
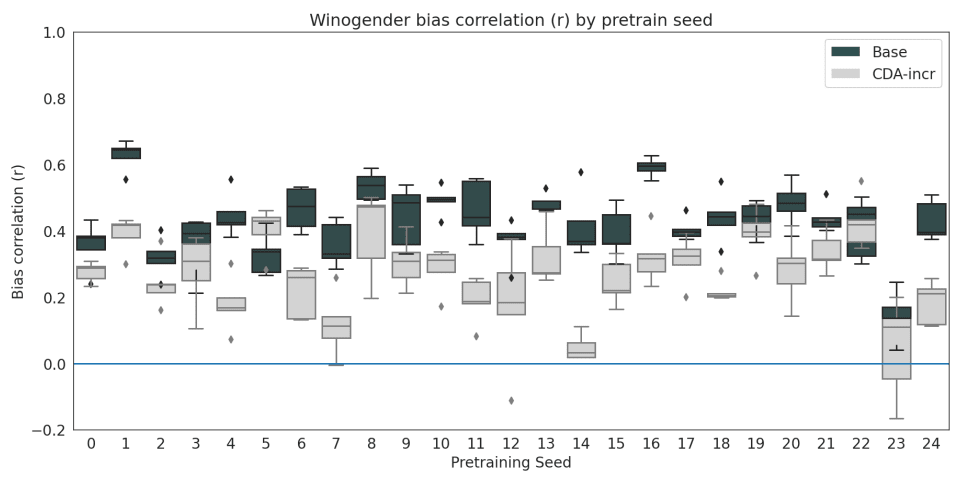
The correlations (black bars) vary between 0.2 and 0.7, with some clear outliers. This phenomenon, called underspecification also happens in many other domains. That should be enough variation in how the models learn to solve specific tasks for goal misgeneralization to appear, where the goals will vary based on the training random seed alone. So... how do we not get an unlucky roll when training the next largest model?
Conclusion
I loved a review of our paper which said it could be a "microscopic examination of something irrelevant". I completely agree with it. However, I would really like to see more work of this kind. Just take some weird behaviour of some obscure model and dig in. You might just have one of those "that's funny" moments, you never know.
Trained models, experiment data, and code (to do training, evals, plots, videos, gifs and more) are available here: https://github.com/KarolisRam/colour-shape-goal-misgeneralization
- ^
The random seed impacts the neural net weight initialisation and the order of training levels.
1 comments
Comments sorted by top scores.
comment by Charlie Steiner · 2023-12-10T09:42:04.926Z · LW(p) · GW(p)
Thanks for making this blog post so easy/fun to read :)