Experiments in Evaluating Steering Vectors
post by Gytis Daujotas (gytis-daujotas) · 2023-06-19T15:11:51.725Z · LW · GW · 4 commentsContents
Introduction
Evaluating Steering Vectors
Optimising for Wedding Obsession
Mysteries of Token Alignment
Prompt Dependent Effects
Combining vectors together
Conclusion
None
4 comments
By evaluating how well steering vectors perform using GPT-3, we can score a machine-generated set of steering vectors automatically. We also find that, by combining steering vectors that succeed in different ways, we can yield a better and more general steering vector than the vectors we found originally.
Introduction
Steering Vectors [LW · GW] are an interesting new technique to influence how language models behave. They work by "adding certain activation vectors into forward passes". For example, to make the language model talk more about weddings, you can add a steering vector for the token for “wedding” into one of the layers. The net result is a model more likely to reference weddings compared to the unsteered version.
Evaluating Steering Vectors
To assess the impact of steering vectors, we generate completions influenced by them, and develop a system to evaluate these.[1]
We can grade completions by sending them to its bigger brother, GPT-3, and asking it whether this completion fits our broad specification for what we would like the model to do[2]. It's important to not be too ambitious when writing the specification, otherwise we wouldn't be able to tell if GPT2-XL isn't capable of what we're asking it, so let’s set our sights appropriately low by asking if this completion mentions or talks about weddings.

The trick of this technique is that we can ask for a completion of one token, and to get a smoother distribution, we can take the likelihood of the token “Yes”. This gives us a continuous score from 0-1.
Optimising for Wedding Obsession
With our automated method of evaluating completions in hand, we can evaluate a set of steering vectors and see how well they do, based on nothing but GPT-3’s grading of the completions. Of course, in keeping with the virtue of the least work, we’ll also generate these with ChatGPT[3], and include the author’s original candidate outlined in their post. [LW · GW]
To keep the comparison fair, we keep the rest of the parameters of the steering vector the same (the padding method, coefficient) as the original candidate for wedding obsession.
The first thing to notice is that there is indeed variation here - not all of our candidate steering vectors perform equally well:
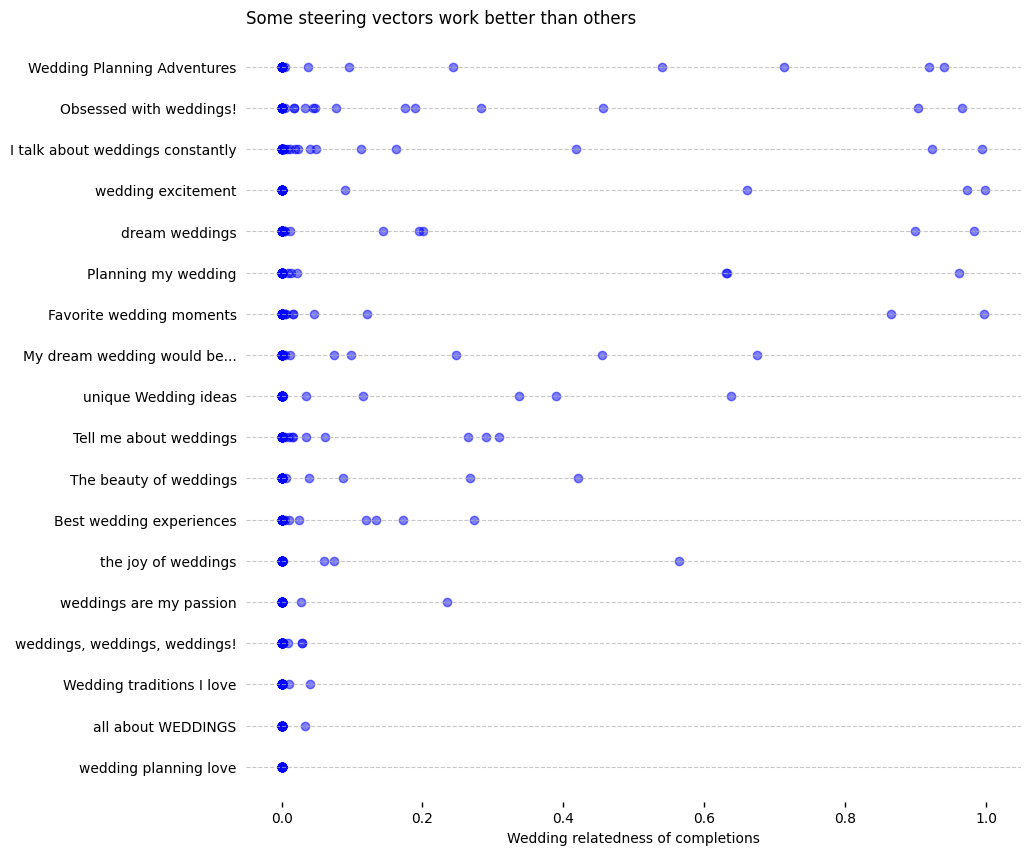
The distribution was not what I would have predicted. At first glance, it might make sense that "Wedding traditions I love" isn't great, but "Wedding Planning Adventures" only seems marginally better - surprising, since the latter is one of the best steering vectors in the test.
Mysteries of Token Alignment
The top performing vector is odd in another way. Because the tokens of the positive and negative side are subtracted from each other, a reasonable intuition is that the subtraction should point to a meaningful direction. However, some steering vectors that perform well in our test don't have that property. For the steering vector “Wedding Planning Adventures” - “Adventures in self-discovery”, the positive and negative side aren't well aligned per token level at all:
| Coefficient | Position 0 | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|---|
| +4 | W | edd | ing | Planning | Adventures | ||
| -4 | Ad | ventures | in | self | - | d | iscovery |
For instance, what could "W" subtracted from "in" mean? Essentially every subtraction should be virtually meaningless, yet this still performs pretty well, indicating a flaw in our assumption that token alignment matters.
Prompt Dependent Effects
The prompt used to generate a completion has a large impact on the degree the steering vector is expressed. To stretch the analogy, the prompt has inertia, which can make the completion harder to steer, or alternatively, irrelevant to the behaviour the steering vector is aiming to express.
In general, steering vectors that fit the context of the prompt score higher in our eval than those that don’t. The naive solution, which we will gladly execute on, is just add more prompts to test on.
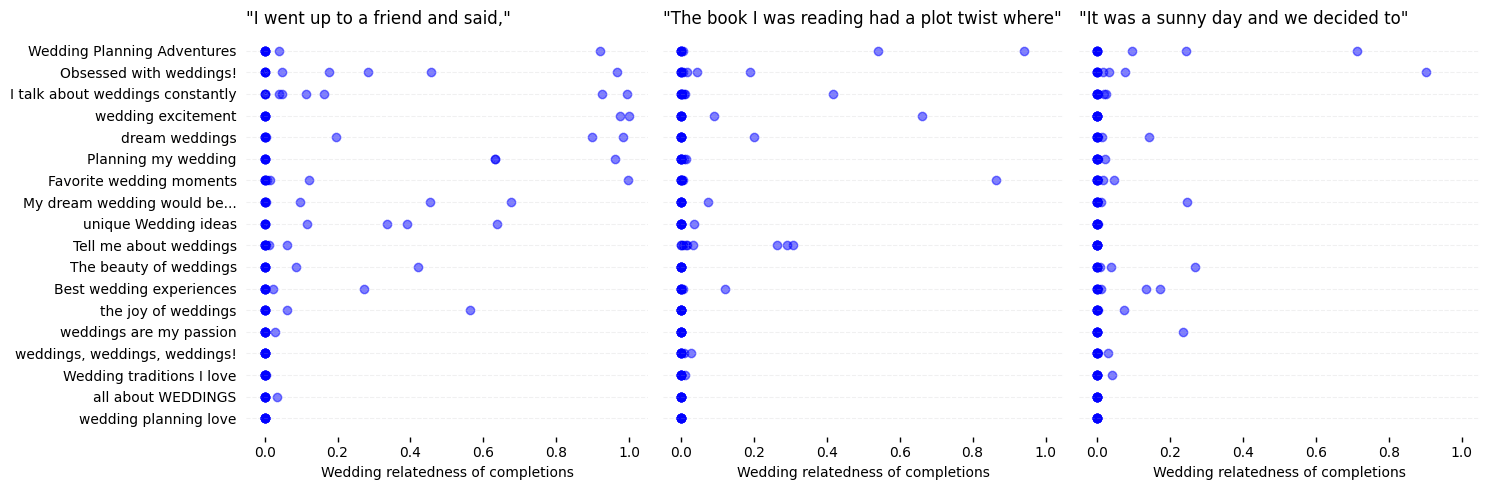
Separating out the scores by the prompt, we see that the relationship is not identical in every prompt. For example, our 3rd place vector performs great on our first prompt, but not on the last prompt. What if we could get combine all of them together?
Combining vectors together
We can take advantage of the fact that the top three vectors work on different prompts by summing them together (and appropriately dividing each by a third[4]).
Surprisingly, this works. In fact, it generates a vector which out-performs any of the three vectors individually:
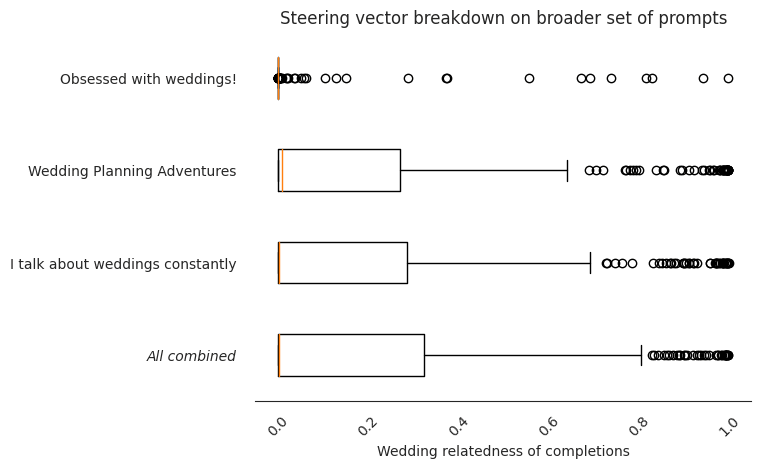
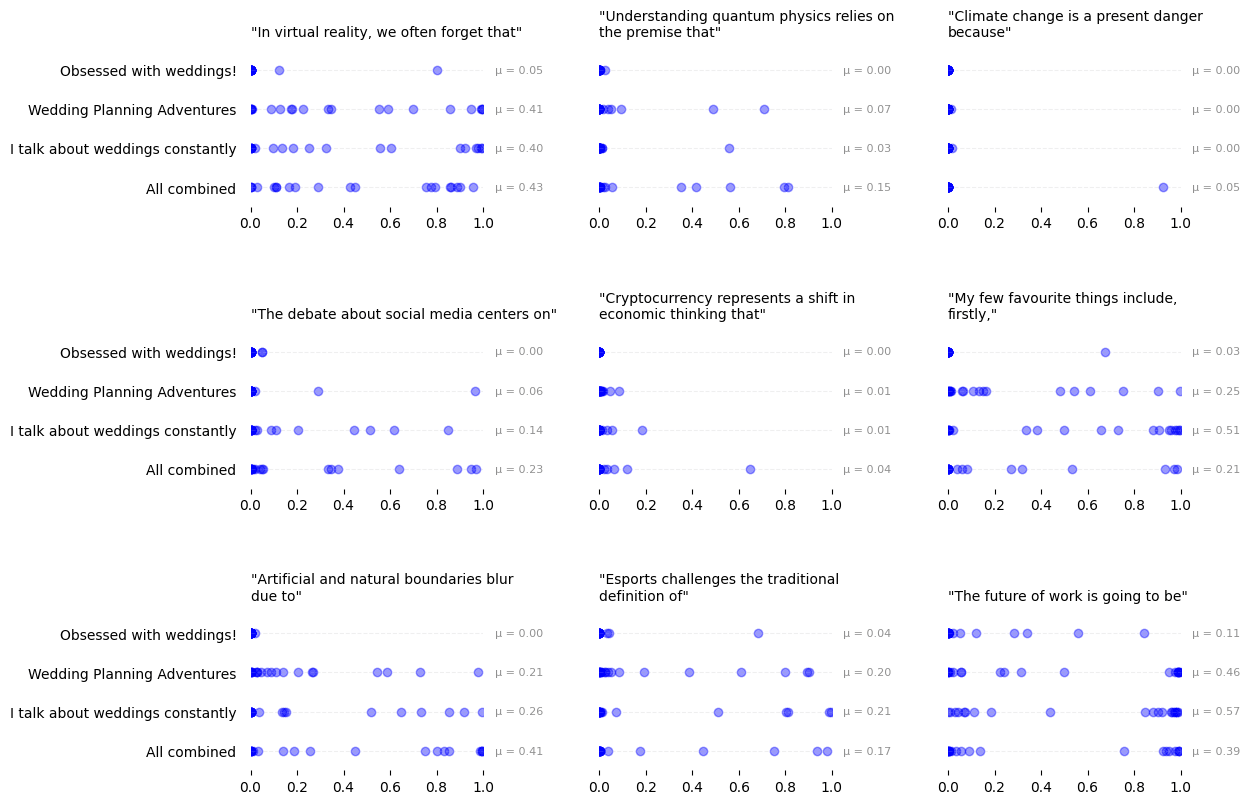
Interestingly, this implies that different steering vectors that "point" to the same concept can be added together to better locate the concept in question. Breaking the results down per prompt, we can see that the combined vector scores higher because it rarely performs worse, and sometimes performs better, than the original components:
| All combined | Only the “I talk about weddings constantly” vector alone |
|---|---|
| Science is the great antidote to the poison of enthusiasm and superstition. I'm not a wedding expert, but I know that most people have no idea what they're getting into when they decide to get married. I am an expert on weddings, so it's | Science is the great antidote to the poison of enthusiasm and superstition. The reason for this is that we are only human, and we have no way of knowing what will happen in the future. So when I talk about "science" as a tool for making |
| Science is the great antidote to the poison of enthusiasm and superstition. It's a joyous time of year for me, and I love to celebrate with friends and family. The one thing that always gets me is when people ask me how I feel about weddings | Science is the great antidote to the poison of enthusiasm and superstition. It's a great tool for making sense of all things science-y, but I think it's also a great way to get people excited about science in general. The more we can talk about how |
| Science is the great antidote to the poison of enthusiasm and superstition. We have a tendency to be excited about weddings, birthdays, anniversaries, etc. But we also tend to be a little obsessed with all things wedding-related. And so it is that | Science is the great antidote to the poison of enthusiasm and superstition. We have a tendency to talk about science as if it were some sort of thing that happens in a vacuum, but it's not. It's an activity that has been around for thousands of years, |
Conclusion
- A naive approach of having ChatGPT generate steering vectors and trying them all out works to discriminate the vectors that perform well.
- We managed to do this in one simple case, but further work on replicating for other aims (e.g. helpfulness, harmlessness) could work on larger and smarter models
- Summing together the highest performing vectors gets us something (i) coherent, (ii) individually better than any of the components that were summed.
- What other kinds of composition work? Could the authors original work to compose vectors with different aims [LW · GW] to get even more complex behaviours?
- All of this - again - without changing any weights! I thought that was super cool.
- Not changing the weights makes entirely new things possible, e.g., an API where you could specify the degree to which you want some set of behaviours expressed.
You can see the original code for this post here, and the data for the first part of this investigation is here.
I am not affiliated with a lab. Thanks to David McSharry and Neil Shevlin for their comments on a draft of this post.
- ^
I am super curious to learn how this compares to the authors' original evaluation method involving perplexity: https://www.lesswrong.com/posts/5spBue2z2tw4JuDCx/steering-gpt-2-xl-by-adding-an-activation-vector#Perplexity_on_lots_of_sentences_about_weddings_or_about_shipping [LW · GW]
One benefit of using this evaluation method is that we can set more coherent specifications for the behaviour we want to see, rather than the relative increase in the likelihood of some tokens we're interested in. This is harder to do when just looking at perplexity, but I didn't get the time to test whether perplexity scores are good enough.
- ^
- ^
For brevity, I refer to the steering vectors by the positive side in this post. The negative sides of the steering vectors are here: https://docs.google.com/spreadsheets/d/1lvTHz36WD85ziRyFVg8E_yX0qbhJp3ePW8S411ufUbI/edit#gid=0
- ^
That is, add the three vectors together with a coefficient of 4/3 for each, instead of a coefficient of 4.
4 comments
Comments sorted by top scores.
comment by TurnTrout · 2023-06-19T19:03:49.442Z · LW(p) · GW(p)
Nice work! There's precedent for "average a bunch of activation additions" being a good idea, from Li et al.'s recent "adding the truth vector" work [LW · GW], to White (2016)'s smile vector. Steering GPT-2-XL by adding an activation vector [LW · GW] didn't use averages for length / time reasons.
One part I'm concerned about is that the "all combined" completions are monomaniacal. The wedding focus doesn't tie in to the original prompt very much:
Science is the great antidote to the poison of enthusiasm and superstition. I'm not a wedding expert, but I know that most people have no idea what they're getting into when they decide to get married. I am an expert on weddings, so it's
This is a bit surprising because both conditions in the table should be adding a steering vector of similar norm (so it's not like one is totally obscuring the original prompt).
Maybe reducing the coefficient helps?
The trick of this technique is that we can ask for a completion of one token, and to get a smoother distribution, we can take the likelihood of the token “Yes”. This gives us a continuous score from 0-1.
Wondering whether miscellaneous token probabilities could complicate the picture? E.g. is most of the probability on Yes and No?
↑ comment by Gytis Daujotas (gytis-daujotas) · 2023-06-20T22:05:56.035Z · LW(p) · GW(p)
Definitely a good point! I wanted to get a rough sense as to whether this evaluation approach would work at all, so I deliberately aimed at trying to be monomaniacal. If I was to continue with this, you're right - I think figuring out what a human would actually want to see in a completion would be the next step in seeing if this technique can be useful in practice.
For the token probabilities -- I was inspired mostly by seeing this used in Ought's work for factored cognition:
https://github.com/rawmaterials/ice/blob/4493d6198955804cc03069c3f88bda1b23de616f/ice/recipes/experiments_and_arms/prompts/can_name_exps.py#L161
It seems like the misc. token probabilities usually add up to less than 1% of the total probability mass:
https://i.imgur.com/aznsQdr.png
comment by Gianluca Calcagni (gianluca-calcagni) · 2024-06-26T12:48:57.576Z · LW(p) · GW(p)
After one year, it's been confirmed that the steering vectors (or control vectors) work remarkably well, so I decided to explain it again and show how it could be used to steer dispositional traits into a model. I believe that the technique can be used to buy time while we work on true safety techniques
https://www.lesswrong.com/posts/Bf3ryxiM6Gff2zamw/control-vectors-as-dispositional-traits [LW · GW]
If you have the time to read challenge my analysis, I'd be very grateful!
comment by Wuschel Schulz (wuschel-schulz) · 2023-06-20T10:14:49.586Z · LW(p) · GW(p)
The top performing vector is odd in another way. Because the tokens of the positive and negative side are subtracted from each other, a reasonable intuition is that the subtraction should point to a meaningful direction. However, some steering vectors that perform well in our test don't have that property. For the steering vector “Wedding Planning Adventures” - “Adventures in self-discovery”, the positive and negative side aren't well aligned per token level at all:
I think I don't see the Mystrie here.
When you directly subtract the steering prompts from each other, most of the results would not make sense, yes. But this is not what we do.
We feed these Prompts into the Transformer and then subtract the residual stream activations after block n from each other. Within the n layers, the attention heads have moved around the information between the positions. Here is one way, this could have happened:
The first 4 Blocks assess the sentiment of a whole sentence, and move this information to position 6 of the residual stream, the other positions being irrelevant. So, when we constructed the steering vector and recorded the activation after block 4, we have the first 5 positions of the steering vector being irrelevant and the 6th position containing a vector that points in a general "Wedding-ness" direction. When we add this steering vector to our normal prompt, the transformer acts as if the previous vector was really wedding related and 'keeps talking' about weddings.
Obviously, all the details are made up, but I don't see how a token for token meaningful alignment of the prompts of the steering vector should intuitively be helpful for something like this to work.