Blindspot in Sport’s Data-Driven Age
post by Matěj Nekoranec (matej-nekoranec) · 2024-05-25T20:17:33.971Z · LW · GW · 0 commentsContents
Human vs AI — model specification Lets get human back to the loop Performance metrics as a curse Let’s stay human Reference list: None No comments
In today’s world of sports, we’re seeing a rapid rise in the use of technology, both among amateur enthusiasts and professional teams. This growth involves everything from data acquisition to predictive algorithms. On one side, amateur athletes invest in wearable gadgets that track everything from sleep patterns, and heart rate variability to continuous blood sugar values. Meanwhile, PRO teams are going all-in on advanced prediction models, hiring top-class computer science undergraduates to develop models that can break down the game into an algorithmic language.
As someone who’s fascinated by tech and machine learning, I find it hard to fully jump on the data-driven hype train. Why? Well, most of my career has been formed by coaching, spending enormous amount of time talking to athletes. Anyone coming from the coaching perspective understands that first-person athlete experience is a key feature of any successful development of an athlete. Trying to boil all of that down to a discrete data point just doesn’t sit right with me. In this discussion, I’ll explain why I think the current explosion of data in sports won’t lead to never-ending exponential growth but rather to a sigmoid curve. And I’ll also talk about why that might actually be a good thing for the future of sports.
Human vs AI — model specification
To begin the discussion, let’s start with a brief crash course on neuroscience. Instead of observing ourselves from a third-person perspective (what science usually does), let’s consider what it means to be in the eyes of the observed person, meaning first-person perspective. One of the fundamental forces that drives our decision-making is known as predictive coding. Our brains create probabilistic maps between our actions and their outcomes based on input from sensory organs such as vision or proprioception. When an action reduces uncertainty, it triggers a positive reinforcement loop for that behaviour; when predictions are far off, usually defined as a prediction error, it prompts either belief adjustment or a selection of actions aligned with top-down predictions (Den Ouden et al., 2012). In simple terms, we select actions that correspond to our beliefs.
Let’s now shift our focus to examine the current state-of-the-art large language models. Chief AI architect at Meta Yan Le Cunn provided an example of why today’s language models fall far short of human capabilities (reference lower). Here’s an interesting point raised by Yan: A four-year-old child processes 20mbs per second through the optical nerve, resulting in approximately 50x more processed training data by the age of four than the most powerful AI model of today. While some may argue that this applies specifically to language processing, we need to make a point that humans make decisions based on multiple sensory sources because our sensory states are multimodal meaning we receive different streams of sensory information simultaneously. For instance, we have a high density of nerve fibres in our skin and muscles that help us develop proprioception; we have an auditory system, chemoreceptors, etc. If we apply the same logic as Yan but expand it to encompass all sensory modalities, we can see how much current machine learning models lag behind in understanding the world compared to humans. This is simply because humans are exposed to a substantially larger amount of training data. It means that athletes base their beliefs and perceptions on years of training, observation, listening, and understanding of the game through multi-dimensional data streams.
It’s important to note that it doesn’t necessarily lead us to make correct decisions just because we have more sensory training data. In the world of sports, we often see athletes who end up in overtrained status, have poor sleeping patterns, are constantly injured, make tactical mistakes during the game, and more. In this case, data can play a powerful role in helping athletes assign meaning to certain sensory states via selected metrics, which can lead to positive reinforcement in behaviour if selected metrics help them achieve their goals. Sometimes there’s a mismatch between an individual’s perception of what is right given a certain goal, be it wrong biomechanical pattern, or limited tactical orientation on the field.
Lets get human back to the loop
However, as athletes continue to improve, data simply cannot keep pace with the biological sensory machinery. Data serves its purpose only when derived information helps to accomplish high-level goals (e.g., winning in the competition) that align with the perception of athletes — minimizing their prediction errors. As data-driven methods become more prevalent in sports, there is a higher likelihood of deviating from what athletes perceive as optimal. Science usually tends to create causal relationships between predictor and response variable without realizing that down-the-road consequences can lead to what I call “being closed in the prison of parameters” — optimizing for these while not realizing that the ultimate goal may be as simple as being a good defender. Famous British economist Charles Goodhart described this by eloquent quote: “When a measure becomes a target, it ceases to be a good measure”
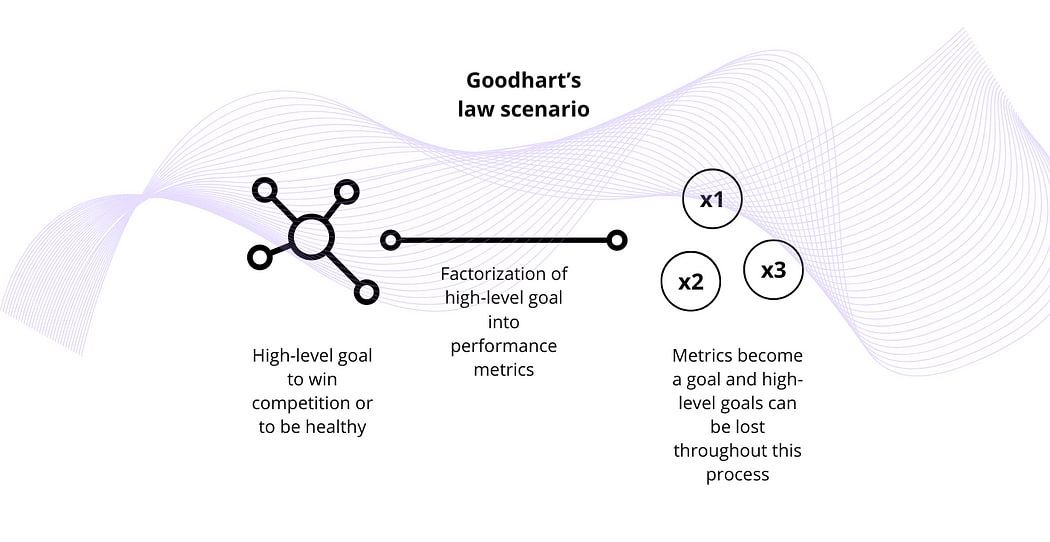
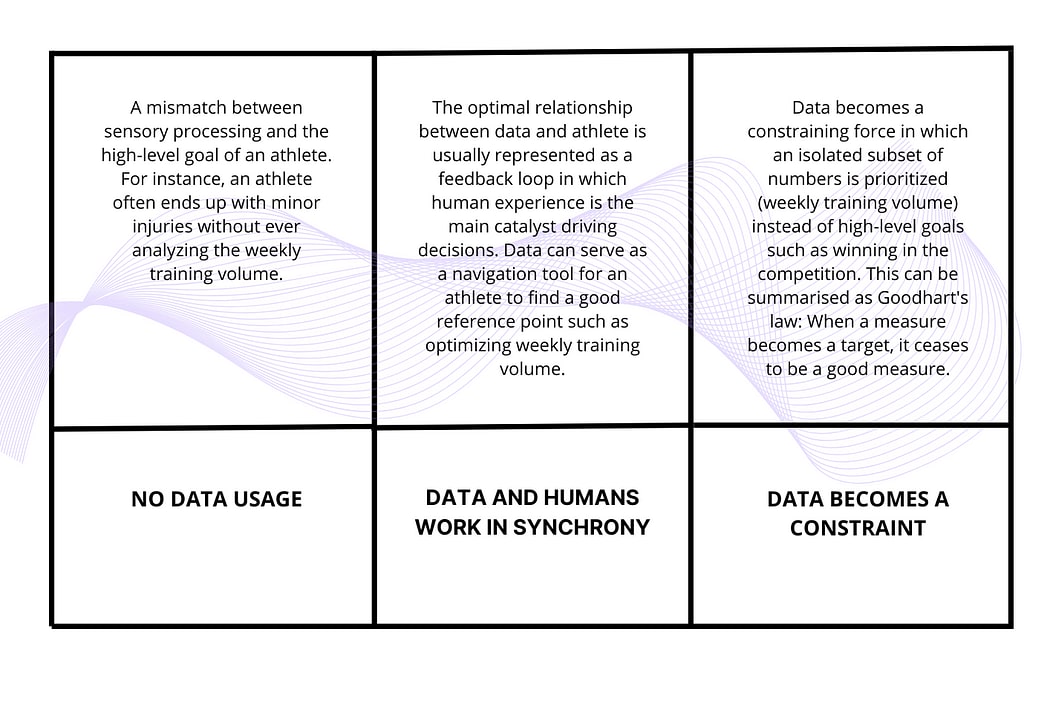
To logically connect this discussion, let’s break it down into a table in which we can show three distinct categories.
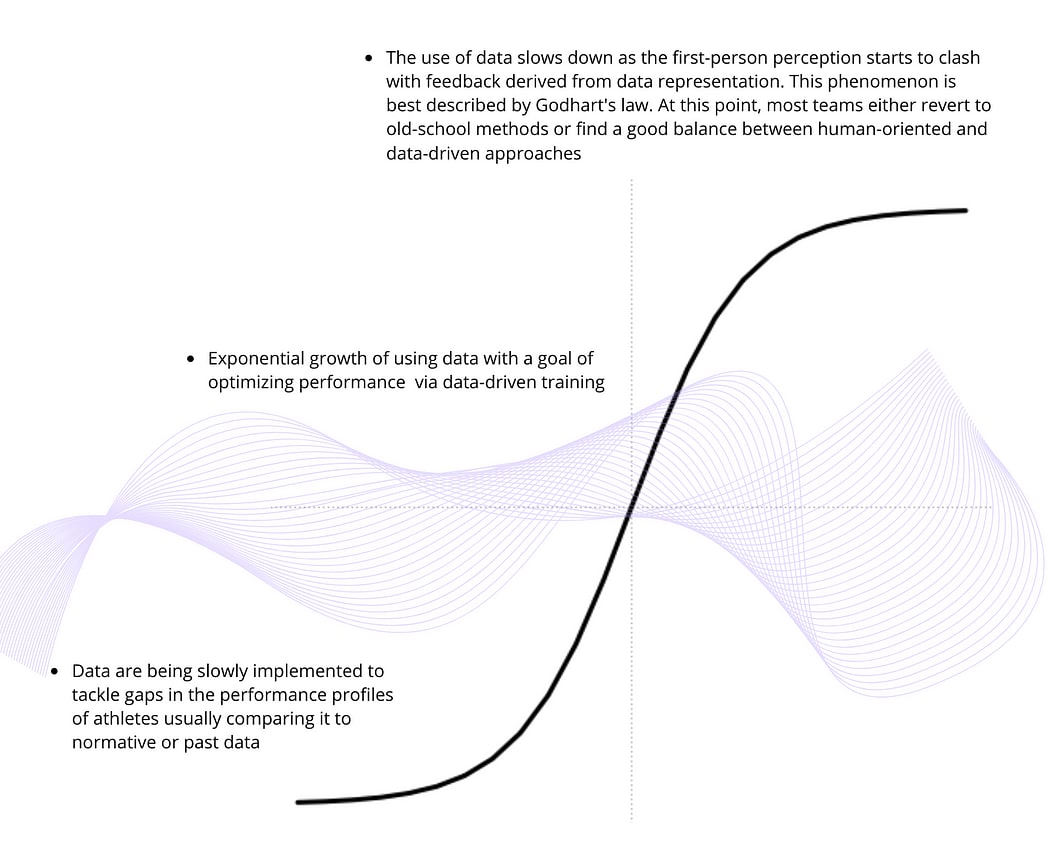
I assume that there will be a significant slowdown in years to come due to the simple fact that current models cannot compete with thousands of years of biological evolution that equipped us with the most powerful sensory system in nature. The distance between data representation and perception of reality from the position of athletes will become so vast that most coaches and team managers will have to step back and find a different way.
When we look at the greats of the sporting world, they possess qualities that cannot be captured by data alone. They have a deeper understanding that goes beyond what can be represented in numbers. For instance, elite athletes often have exceptional hearing skills to tune in to their teammates’ shouting amidst thousands of cheering fans (Krizman et al., 2020). Proprioceptive abilities are another crucial factor that sets apart elite athletes such as a good grip on the ball or tennis racket, but are incredibly challenging to represent through data (Waddington et al., 2013). These skills are multidimensional, embodied and developed throughout an athlete’s entire career, making them irreplaceable with third-person observational data representation. If it is not deeply understood, this could lead to an autocratic environment where arbitrary parameters take precedence over the natural perception of athletes on the field.
Performance metrics as a curse
Another reason why I don’t believe data-driven training can replace human-centred coaching is the shift towards using an almost infinite number of metrics that have a statistically significant effect on almost any parameter of sports performance. Many people in sports analytics, coaching, and especially amateur athletes, tend to focus on specific performance metrics (x) that are correlated to a particular response variable (y), usually assessed individually and in isolation.
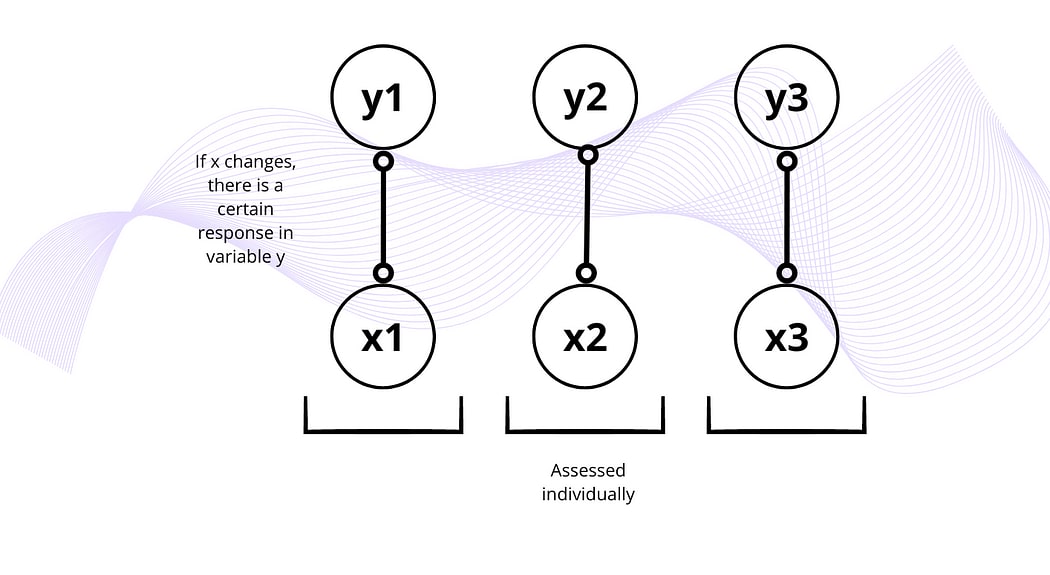
Problem with this approach can be seen from two angles.
- Firstly, biology is highly non-linear and involves significant trade-offs (e.g., Bache-Mathiesen et al., 2021). For example, in endurance sports, VO2max is a key predictor of performance. However, as VO2max increases, the movement economy decreases. Therefore, the optimal performance profile for a halfmarathon runner involves having a relatively high level of VO2max, but not too high (e.g., Nilsson et al., 2019). It means that training itself is about optimization of all involved parameters, not maximization, which makes data science much more challenging signifying the non-linearity of human biology.
- The second problem is called misperception. It can be simplified as giving agency to technology instead of evaluating our actual feelings. A study from Oxford University showed that when people received a fake “negative” sleep score, they rated themselves as much sleepier, and their mood was significantly worse than those who were given a fake “positive” score, and vice versa (Gavriloff et al., 2018). This means that we can manipulate our perception based on being hyperfocused on particular metrics.
The first point can be to some extent solved once the dynamical and complex systems approaches mature enough for a deep understanding of non-linearity in biological systems.
However, the second point highlights the significant limitations of placing complete agency in the hands of technology. Once data usage exceeds a certain threshold, people might become slaves to it and overly focused on specific parameters instead of the selected high-level goal — for instance, feeling good. Of course, to stay objective, having elevated levels of blood sugar for a long time is not good for you and technology like CGM can help you to optimise your diet. However, at the same time, being psychologically stressed with every single spike in your blood glucose does not contribute to your well-being either. Sometimes as a coach, I can notice funny paradoxes. It doesn’t matter if all performance metrics are green; if at the same time, the athletes are stressed that the metrics are worse than last year.
I believe that new approaches should shift from relying solely on hyper-specific performance scores to using probabilistic graphs. In the field of machine learning and AI, there is an emerging area of structure learning using directed acyclic graphs that focus on revealing probabilistic relationships between multiple variables at once rather than producing simplified hyper-specific performance scores. This approach allows us to abstract performance to a higher level, enabling us to identify relationships that could be unseen from the perspective of athletes and focus on high-level themes instead of fixating on specific metrics. For instance, a directed acyclic graph (DAG) can indicate a probabilistic relationship between psychological stress and my performance on any given day, prompting us to concentrate on optimizing this area like going out and socializing with friends regularly. This approach can allow us to black-box unnecessary granularity without losing leverage we have trough training and lifestyle interventions.
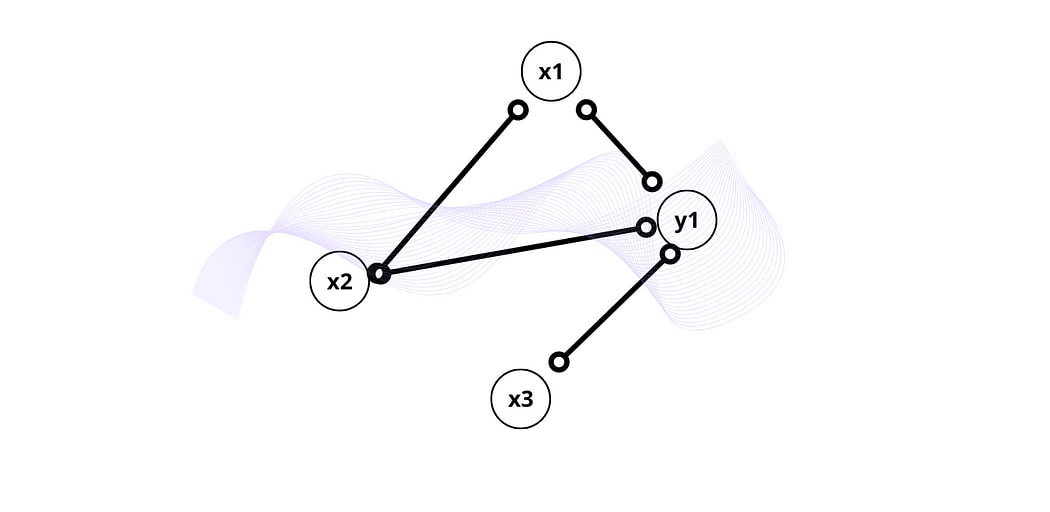
Simplified visualisation of Directed Acyclic Graph showing causal relationship of particular data model
Let’s stay human
There are often no perfect solutions, only trade-offs. The data-driven era in sports is already here, and we will need to approach this era with caution.
When we look at a beatiful study of Anyadike-Danes et al. (2023) in which they surveyed coaches about which factors most likely influence training adaptations, less than a third rated physical training as the most important factor in determining sports performance. And what were the more important factors? Who would guess? Coach-athlete relationship, life stress, athletes believing in the plan, and psychological and emotional stress. This study beautifully highlights the key factors that are important in any development process.
And let’s be honest — who wants a sport that is completely driven by algorithms without any human agency? The reason we love sports is because of the element of surprise, unexpected events, and incredible shots from unexpected angles. This is something that should remain in human hands, with data playing a supporting role and joining the discussion only when someone asks for it.
It is not set in stone and perhaps human performance can be one day fully captured by algorithms, but based on the current data we have, we are not even close to matching human sensory understanding of the world. In my humble opinion, the potential advances in data analytics lie at a higher, more abstract level, which allows us to put hyper-specificity into a black box and train athletes as humanly as possible.
Reference list:
Aibusiness.com. Retrieved May 19, 2024, from https://aibusiness.com/nlp/meta-s-yann-lecun-wants-to-ditch-generative-ai
Anyadike-Danes, K., Donath, L., & Kiely, J. (2023). Coaches’ perceptions of factors driving training adaptation: An international survey. Sports Medicine (Auckland, N.Z.), 53(12), 2505–2512. https://doi.org/10.1007/s40279-023-01894-1
Bache-Mathiesen, L. K., Andersen, T. E., Dalen-Lorentsen, T., Clarsen, B., & Fagerland, M. W. (2021). Not straightforward: modelling non-linearity in training load and injury research. BMJ Open Sport & Exercise Medicine, 7(3), e001119. https://doi.org/10.1136/bmjsem-2021-001119
Den Ouden, H. E. M., Kok, P., & de Lange, F. P. (2012). How prediction errors shape perception, attention, and motivation. Frontiers in Psychology, 3, 548. https://doi.org/10.3389/fpsyg.2012.00548
Gavriloff, D., Sheaves, B., Juss, A., Espie, C. A., Miller, C. B., & Kyle, S. D. (2018). Sham sleep feedback delivered via actigraphy biases daytime symptom reports in people with insomnia: Implications for insomnia disorder and wearable devices. Journal of Sleep Research, 27(6), e12726. https://doi.org/10.1111/jsr.12726
Krizman, J., Lindley, T., Bonacina, S., Colegrove, D., White-Schwoch, T., & Kraus, N. (2020). Play sports for a quieter brain: Evidence from Division I collegiate athletes. Sports Health, 12(2), 154–158. https://doi.org/10.1177/1941738119892275
Nilsson, A., Björnson, E., Flockhart, M., Larsen, F. J., & Nielsen, J. (2019). Complex I is bypassed during high intensity exercise. Nature Communications, 10(1), 5072. https://doi.org/10.1038/s41467-019-12934-8
Waddington, G., Han, J., Adams, R., & Anson, J. (2013). Measures of proprioception predict success in elite athletes. Journal of Science and Medicine in Sport, 16, e19–e20. https://doi.org/10.1016/j.jsams.2013.10.048
0 comments
Comments sorted by top scores.