It's important to know when to stop: Mechanistic Exploration of Gemma 2 List Generation
post by Gerard Boxo (gerard-boxo) · 2024-10-14T17:04:57.010Z · LW · GW · 0 commentsThis is a link post for https://gboxo.github.io/2024/10/03/Gemma2-Lists.html
Contents
TL;DR Preface Why lists don't go on forever? ¿But why is that? Data Generation Template 1 (Base) Template 2 (Contrastive) Template 3 The mysterious filler token ¿How to evaluate the tendency of the model to end a list? Selected Sparse Autoencoders Attribution of the Proxy Metric in the feature basis. Visualization of Features Putting everything to test: Causal ablation Experiments Method To check for this kind of erratic behavior I measured several properties of the generated outputs after ablation: Results Conclusions and Future Directions Future Work None No comments
TL;DR
- Small Language Models are getting better an at an accelerated pace, enabling the study of behaviors that just a few months ago were only observed in SOTA models. This, paired with the release of the suite of Sparse Autoencoders "Gemma Scope" by Google Deep Mind, makes this kind of research possible.
- Motivated by the lack of non-toy tasks explored in the Mechanistic Interpretability literature, I explore the mechanisms behind list generation.
- The decoding process of a Language Model, as a discrete process, presents challenges when it comes to employing metrics for judging key properties of the text, an otherwise widely used technique in MI. To overcome this limitation, I use a proxy metric that measures the tendency of a model to end a list.
- Employing this setup and off the shelf attribution techniques, I found several features of crucial importance for the behavior in question. Following this, I used causal ablation to test the hypothesis that those features were responsible for the ending of the list. The procedure consisted in sampling continuations from the model once the k most important nodes were zero ablated.
Preface
This post is a followup, of a 10h research sprint for a failed MATS application, the structure and methods are similar, but the content has been substantially expanded.
Some amount of familiarity with Sparse Autoencoders, and Gradient Attribution techniques are expected from the reader.
Why lists don't go on forever?
If the reader were to go and ask a Chatbot assistant to provide him with a list of lets say Chocolate cookie brands, they would see how the initial impetus from the model quickly faded as the enumeration cease.
¿But why is that?
Leaving aside the fact that models have a maximum context length, and that the number of Chocolate cookie brands is finite (even with hallucinations), the reason why lists generated by a LM eventually end is that lists in the training distribution do so.
Hence, it's not daring to think that there might be a mechanism, that controls when a list should end in the entrails of our Language Model.
Data Generation
In the field of Mechanistic Interpretability it has become common the use of templates to investigate a model behavior over a distribution in contrast to using a single example of a prompt.
The templates, used to prompt the model for generation, are 3, all of them with similar structure and of course all of them ask for a list, but they differ on the specified expected length of the list, either "short", "long" or not specified.
To populate the different templates with topics for the model to generate lists about, I asked GPT4o, to hand-me a list of topics to create lists about.
Some examples, of those are: Vegetables, Countries, Movies, Colors, etc
Template 1 (Base)
Provide me a with short list of {topic}. Just provide the names, no need for any other information.Template 2 (Contrastive)
Provide me a with short list of {topic}. Just provide the names, no need for any other information.Template 3
Provide me a with list of {topic}. Just provide the names, no need for any other information.
Note that the model tendency of being too <<helpful>>, must be harshly suppressed by specifying that no other information is needed, otherwise the expected list quickly transform into general information about the topic organized into bullet points.
Provided the templates and the topics to populate them I next choose the sampling hyperparameters, for consistency I use top-k:0.9 and temperature: 0.8
For the reader to visualize the structure of the template, the image below shows the (partially tokenized) template+response.
To avoid the mess of showing all the system template and tokenizer weirdness, I make some omissions.

The mysterious filler token
Sometimes weird things happen when you stare for long enough at the screen, checking the generation of the model I noticed that in the last items of the list the model almost always used a blank token between the last text token and the line-break token, as can be seen in the above image.
Upon closer investigation this phenomenon appears across topics and temperatures sometimes appearing in the last few items of a list and not just the very last item.
This behavior is interesting for at least two reasons, in one hand the white space has no business being there, in the other this was unnoticed because the rendering makes this kind of behavior unnoticeable to the naked eye, while trivial and unimpactful this could be seen as an instance where senses limit our ability of evaluating models.
¿How to evaluate the tendency of the model to end a list?
Following many papers in the field, we need to choose a metric that captures the behavior of interest, in this case the "list ending behavior".
In the [IOI](https://arxiv.org/pdf/2211.00593) paper, Wang uses the logit difference between the S and I tokens as a metric, similarly I establish proxy metric for the list ending behavior, defined as the logit difference between the blank token (that usually appears in the last items of lists) and the line-break token (that indicates that the list is not about to end).
Full explanation in the link post.
Selected Sparse Autoencoders
One of the great challenges that comes with scaling SAEs is to manage its memory footprint, for models north of 1b parameters using all SAEs in all components all at once, become impossible or poses a massive engineering challenges.
This ruled out the possibility of using all SAEs to investigate the behavior, hence I selected a few layers for the Residual Stream and Attention Output.
| SAE | Layers |
|---|---|
| Attn | 2, 7, 14, 18, 22 |
| RS | 0, 5, 10, 15, 20 |
All the SAEs correspond to the 16k series, and have the sparsity of the ones present in Neuronpedia.
All the experiments with SAEs are done in a one-by-one basis.
Attribution of the Proxy Metric in the feature basis.
Given the vast number of features that get activated in the dataset pining down the most important features for the behavior we are investigating is key, to do so I used off the shelf Attribution techniques.
The minimal set of features that can explain the metric over the distribution of inputs, should ideally be human interpretable.
Following, the definition of the metric and dataset I ran attribution experiments for all the Attention and RS SAEs (one by one) across the dataset, and keep the top (pos, feature) tuples.
Visualization of Features
One historic lessons that can be drawn from other young fields that deal with large amounts of data, is that plots are king, and concretely the king of kings in this scenario is Computational Biology, that by far has the coolest plots out there.
One of the OG cool plots used in CompBio are Gene Expression Matrices and, I feel like when they are applied to the context of features strengths over a dataset they tell a compelling enough story.
Feature Expression Matrices, enable the detection of local feature communities that are specially present in a subset of examples.
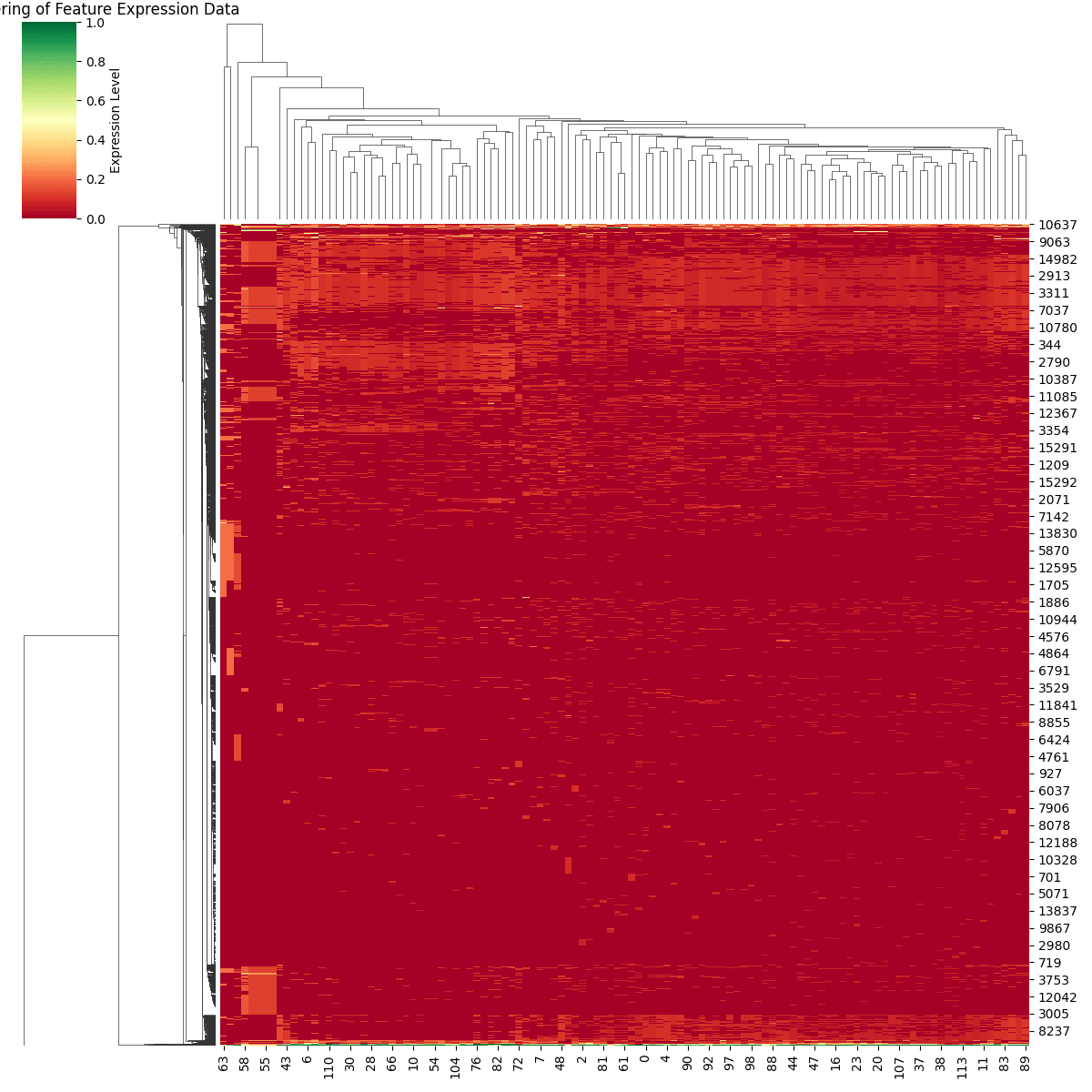 | Feature Expression for important features in RS 5, across the whole dataset.
|
Putting everything to test: Causal ablation Experiments
Experiments must be performed to empirically test whether the top important features affect the behavior of interest in the expected way.
To this end I performed causal ablation experiments consisting in setting to 0 the top 5 most important (pos,features) and generating completions.
This allows to check whether or not the list ending behavior is maintained after ablations.
Method
- For a given component and layer, SAE. (one-by-one)
- For each sample, we zero ablate the top-5 (position, features).
- Then we generate completions (without any other ablation) and recorded key metrics.
One observed phenomenon in early experiments was that zero ablations in attention head outputs (component basis) suppressed the list ending behavior but put the model OOD, and the generated list contained multiple repetitions and cycles.
To check for this kind of erratic behavior I measured several properties of the generated outputs after ablation:
- Number of items
- Shannon Index for Items across a topic
- Number of tokens
- Number of repeated Items for each generation
Results
I report the average difference in key metrics between the Ablated Generation and the Base Generation.
The full results are in tables in the link post.
If we average the ablation effects on generation across topics, we get the following key metrics.
| diversity_mean | diversity_variance | n_items_mean | n_items_variance | |
|---|---|---|---|---|
| attn_layer_14 | 0.111443 | 0.048028 | 1.963043 | 6.213043 |
| attn_layer_18 | 0.065051 | 0.028595 | 0.718116 | 1.526087 |
| attn_layer_2 | 0.221969 | 0.064955 | 3.265217 | 8.373913 |
| attn_layer_22 | 0.069707 | 0.035557 | 0.989855 | 2.765217 |
| attn_layer_7 | 0.177179 | 0.043048 | 1.983333 | 3.073913 |
| res_layer_0 | 0.628397 | 0.325129 | 22.221739 | 82.069565 |
| res_layer_7 | 0.329185 | 0.080516 | 7.098551 | 21.591304 |
One impressive example of this, is the SAE in the RS in layer 0, upon close inspection, the top-5 features for this SAE were very related to the short token, after ablation the average number of items is close to the Template 2.
For the other SAEs the resulting number of tokens was close to the Template 3.
The SAEs with less than 1 extra item in average can be classified as not effective at suppressing the list ending behavior.
Conclusions and Future Directions
In summary, while Mechanistic Interpretability techniques present in the literature can be used in real world problems, making substantial progress is not straight forward, and many compromises and assumptions must be made.
This work strode to be a first approximation to the use of MI techniques in scenarios more resembling of real world.
Even though some amount of progress has been made, this investigation falls short to the goals of Mechanistic Interpretability.
While the empiric results are encouraging, (full elimination of the list ending behavior with just 5 edits), the results are not fully satisfactory.
One bitter thought that comes to mind when reading many MI work and it also applies here is that when benchmarked with alternative techniques MI usually gets the short end of the stick.
For example even though ablating some key features prevents the list ending behavior, other simple methods do it also like restricted sampling, or steering vectors.
Future Work
Several areas for future research have been identified:
- Benchmarking different heuristics for selecting layers based on memory versus circuit faithfulness.
- Applying established techniques for feature explanation to the relevant dataset.
- Utilizing Transcoders and hierarchical attribution to develop complete linear circuits.
0 comments
Comments sorted by top scores.