Interpreting Quantum Mechanics in Infra-Bayesian Physicalism
post by Yegreg · 2024-02-12T18:56:03.967Z · LW · GW · 6 commentsContents
Abstract
1. Introduction
1.1. Discussion of the results
1.2. Outline
2. Setup
3. Prerequisites
3.1. Ultracontributions
3.2. Some constructions
3.3. The bridge transform
4. An infra-Bayesian physicalist interpretation
4.1. Copenhagen interpretation
4.2. Relating the two interpretations
4.3. Decision theory
5. Examples
5.1. Counterexamples
5.2. Wigner's friend
6. Bounds on the ultraprobabilities
6.1. Upper bound
6.2. Lower bound
7. Asymptotic convergence
7.1. Upper bound
7.2. Asymptotic behavior of communicating MDPs
7.3. Lower bound
8. Limitations
8.1. Limitations of the toy setting
8.2. Limitations of the broader framework
None
6 comments
This work was inspired by a question by Vanessa Kosoy, who also contributed several of the core ideas, as well as feedback and mentorship.
Abstract
We outline a computationalist interpretation of quantum mechanics, using the framework of infra-Bayesian physicalism. Some epistemic and normative aspects of this interpretation are illuminated by a number of examples and theorems.
1. Introduction
Infra-Bayesian physicalism [AF · GW] was introduced as a framework to investigate the relationship between a belief about a joint computational-physical universe and a corresponding belief about which computations are realized in the physical world, in the context of "infra-beliefs". Although the framework is still somewhat tentative and the definitions are not set in stone, it is interesting to explore applications in the case of quantum mechanics.
1.1. Discussion of the results
Quantum mechanics has been notoriously difficult to interpret in a fully satisfactory manner. Investigating the question through the lens of computationalism, and more specifically in the setting of infra-Bayesian physicalism provides a new perspective on some of the questions via its emphasis on formalizing aspects of metaphysics, as well as its focus on a decision-theoretic approach. Naturally, some questions remain, and some new interesting questions are raised by this framework itself.
The toy setup can be described on the high level as follows (with details given in Sections 2 to 4). We have an "agent": in this toy model simply consisting of a policy, and a memory tape to record observations. The agent interacts with a quantum mechanical "environment": performing actions and making observations. We assume the entire agent-environment system evolves unitarily. We'll consider the agent having complete Knightian uncertainty over its own policy, and for each policy the agent's beliefs about the "universe" (the joint agent-environment system) is given by the Born rule for each observable, without any assumption on the correlation between observables (formally given by the free product). We can then use the key construction in infra-Bayesian physicalism — the bridge transform — to answer questions about the agent's corresponding beliefs about what copies of the agent (having made different observations) are instantiated in the given universe.
In light of the falsity of Claims 4.15 and 4.17, we can think of the infra-Bayesian physicalist setup as a form of many-worlds interpretation. However, unlike the traditional many-worlds interpretation, we have a meaningful way of assigning probabilities to (sets of) Everett branches, and Theorem 4.19 shows statistical consistency with the Copenhagen interpretation. In contrast with the Copenhagen interpretation, there is no "collapse", but we do assume a form of the Born rule as a basic ingredient in our setup. Finally, in contrast with the de Broglie–Bohm interpretation, the infra-Bayesian physicalist setup does not privilege particular observables, and is expected to extend naturally to relativistic settings. See also Section 8 for further discussion on properties that are specific to the toy setting and ones that are more inherent to the framework. It is worth pointing out that the author is not an expert in quantum interpretations, so a lot of opportunities are left open for making connections with the existing literature on the topic.
1.2. Outline
In Section 2 we describe the formal setup of a quantum mechanical agent-environment system. In Section 3 we recall some of the central constructions in infra-Bayesian physicalism, then in Section 4 we apply this framework to the agent-environment system. In Sections 4.2 and 4.3 we write down various statements relating quantities arising in the infra-Bayesian physicalist framework to the Copenhagen interpretation of quantum mechanics. While Section 4.2 focuses on "epistemic" statements, Section 4.3 is dedicated to the "normative" aspects. A general theme in both sections is that the stronger, "on the nose" relationships between the interpretations fail, while certain weaker "asymptotic" relationships hold. In Section 5.1 we construct counterexamples to the stronger claims, and in in Sections 6 and 7 we prove the weaker claims relating the interpretations. In Section 8 we discuss which aspects of our setup are for the sake of simplicity in the toy model, and which are properties of the broader theory.
2. Setup
First, we'll describe a standard abstract setup for a simplified agent-environment joint system. We have the following ingredients:
-
A finite set of possible actions of the agent.
-
A finite set of possible observations of the agent. We'll write , the set of observation-action pairs.
-
For technical reasons it will be convenient to add a symbol for "blank", and fix a bijection preserving , where We'll use this bijection to treat as an abelian group implicitly.
-
A Hilbert space corresponding to states of the environment.
-
Fix a finite time horizon[1] . A classical state of a cyclic, length memory tape is a function . Let be the set of all classical tape states.
-
A Hilbert space with orthonormal basis for , corresponding to the quantum state of the agent.
-
For each a unitary map of the environment , describing the "result of the action".
-
A projection-valued measure on , valued in (giving projections for each observation ).
-
Let be the state space of the joint agent-environment system.
Remark 2.1. It would be interesting to consider a setting where the agent is allowed to choose the observation in each step (e.g. have the projection-valued measure depend on the action taken). For simplicity we'll work with a fixed observation as described above.
Definition 2.2. Let be the set of observation histories and observation-action histories respectively, i.e. finite strings of observations (resp. observation-action pairs) up to length . There's a natural map extracting the string of observations from a string of observation-action pairs. We'll call a function a policy. For two histories (of either type), we'll sometimes write to mean is a (not necessarily proper) prefix (i.e. initial substring) of .
Remark 2.3. We only consider deterministic policies here. It's not immediately clear how one would generalize Definition 2.7 to randomized policies. In fact, we can always (and is perhaps more principled to) think of our source of randomness for a randomized policy to be included in the environment, so we don't lose out on generality by only considering deterministic policies. For example, if the source of our randomness is a quantum coin flip, then our approach offers a convenient way of modeling this by including the coin as a factor of , i.e. part of the environment subsystem.
Definition 2.4. For a tape state and an observation-action pair , let be the state of the tape after writing the pair to the tape, defined by
Remark 2.5. Choosing a group structure on is in order to make the map invertible, which in turn makes the map in Definition 2.7 unitary.
Definition 2.6. Let the "history extraction" map be defined by where is largest such that there's no with (i.e. so that the portion of the tape contains no blanks).
Definition 2.7 (Time evolution of a policy). For each policy , we define the single time-step unitary evolution operator on as the composite of an "observation" and an "action" operator , where The time evolution after time-steps is given by , i.e. composed with itself times.
Remark 2.8. As defined above, the first step in the evolution is an observation, so we never use the value of the policy on the empty observation string. In this respect it would be more natural to start with an action instead, but it would make some of the notation and the examples more cumbersome, so we sacrifice a bit of naturality for the sake of simplicity overall.
Lemma 2.9. The operator is unitary on .
Proof. The operator is clearly unitary since each is. We can see that is unitary as follows. Choose an orthonormal basis of for each , so together they form an orthonormal basis for (note that the range of might vary for varying ). Then forms an orthonormal basis for , and permutes this basis, hence is unitary.
3. Prerequisites
We recall some definitions and lemmas within infra-Bayesianism. This is in order to make the current article fairly self-contained, all the relevant notions here were introducted in [IBP [AF · GW]], [BIMT [LW · GW]] and [LBIMT [LW · GW]]. In particular we omit proofs in this section, all the relevant proofs can be found in the articles listed.
3.1. Ultracontributions
First of all, we work with a notion of belief intended to incorporate a form of Knightian uncertainty. Formally, this means that we work with sets of distributions (or rather "contributions" turn out to be a more flexible tool).
Definition 3.1. Given a finite set , a contribution is a non-negative measure on , such that . We denote the set of contributions . A contribution is a distribution if , so we have .
There's a natural order on , given by pointwise comparison.
Definition 3.2. We call a subset downward closed if for , implies .
As a subspace of , the set inherits a metric and a convex structure.
Definition 3.3. We call a closed, convex, downward closed subset a homogenious ulta-contribution (HUC for short). We denote the set of HUCs by .
We'll work with HUCs as our central formal notion of belief in this article. The exact properties required (closed, convex and downward closed) should be illuminated by Lemma 3.6.
Definition 3.4. Given a HUC , and a function , we define the expected value
Thinking of as a loss function, this is a worst-case expected value, given Knightian uncertainty over the probabilities.
Remark 3.5. It's worth mentioning that the prefix "infra" originates from the concept of infradistributions, which is the notion corresponding to ultracontributions, in the dual setup of utility functions instead of loss functions. We still often use the term "infra" in phrases such as infra-belief or infra-Bayesianism, but now simply carrying the connotation of a "weaker form" of belief etc., compared to the Bayesian analog.
Lemma 3.6. For , the expected value defines a convex, monotone, homogeneous functional .
Lemma 3.7. There is a duality , between (i.e. closed, convex, and downward closed subsets of ) and convex, monotone, and homogeneous functionals .
For a functional , the inverse map in the duality is given by
3.2. Some constructions
For the current article to be more self-contained, we spell out a few definitions used in this discussion.
Definition 3.8. Given a map of finite sets , we define the pushforward to be given by the pushforward measure. We use the same notation to denote the pushforward on HUCs, , given by forward image, that is Equivalently, in terms of the expectation values we have for
Definition 3.9. Given a collection of finite sets , and HUCs , we define the free product as follows. For a contribution we have if and only if for each , where is projection onto the th factor.
The free product thus specifies the allowed marginal values, but puts no further restriction on the possible correlations.
Definition 3.10 (Total uncertainty). The state of total (Knightian) uncertainty is defined as i.e. the subset of all contributions.
Definition 3.11 (Semidirect product). Given a map , and an element , we can define the semidirect product . This is easier to write down in terms of the expectation functionals, as follows. For , define Here is the function , whose value at is given by by taking expected value with respect to of the function .
As a subset of , can be understood as the convex hull of the for all and all . For one needs to further restrict to contributions that project down into .
3.3. The bridge transform
The key construction we'll be considering in infra-Bayesian physicalism is the bridge transform. This construction is aimed at answering the question "given a belief about the joint computational-physical universe, what should our corresponding belief be about which computations are realized in the physical universe?".
We'll discuss these notions in a bit more detail, but for now both the physical universe and the computational universe are just assumed to be finite sets.
Definition 3.12. Given , the bridge transform of ,
is defined as follows (cf. [IBP [AF · GW] Definition 1.1]). For a contribution we have if and only if for any , under the composite
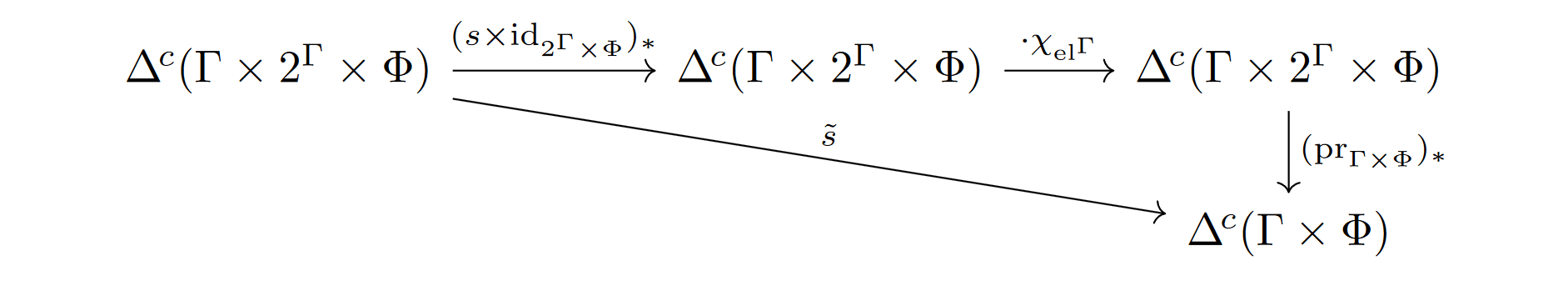
Remark 3.13. The use of all endomorphism in Definition 3.12, although concise, doesn't feel fully principled as of now. We would typically think of the computational universe as the set of all possible assignments of outputs to programs, i.e. , for a certain output alphabet , and a set of programs (see Definition 4.1). In this context, feels somewhat unnatural. That being said, in the current discussion we mainly use the fact that acts transivitely on , so it's possible that these results would survive in some form under a modified definition of the bridge transform.
For easy reference, we spell out [IBP [AF(p) · GW(p)] Proposition 2.10]:
Lemma 3.14 (Refinement). Given a mapping between physical universes , we have
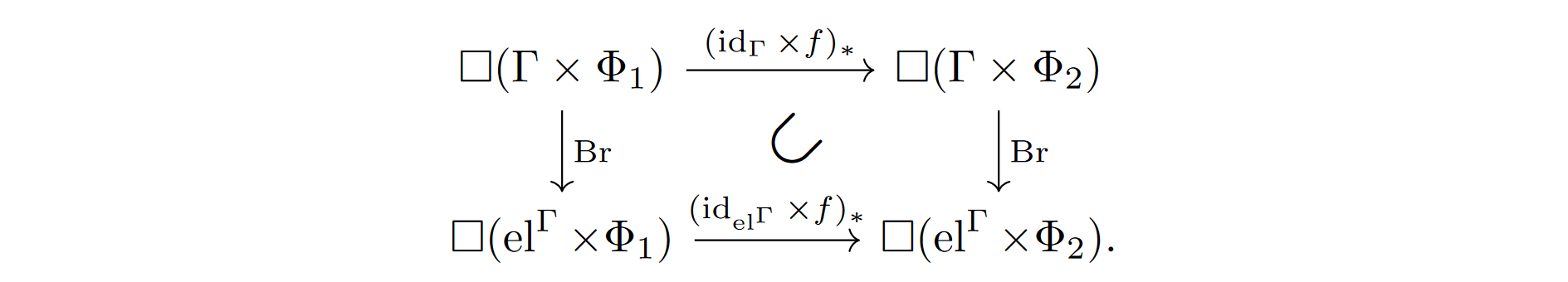
4. An infra-Bayesian physicalist interpretation
We'll work with a certain specialized setup of [IBP [AF(p) · GW(p)]].
Definition 4.1. Let the set of "programs" , the "output alphabet" , and the set of "computational universe states" be the set of policies up to time horizon . We'll write
Definition 4.2. Let a "universal observable" be a triple where is a finite set (of "observation outcomes"), is a projection-valued measure on , valued in (giving projections for each ), and an "observation time" . Let be the set of all universal observables, up to the natural notion of equivalence.
Remark: We use the term "universal observable" here to distinguish between observables of the "universe" (i.e. the joint agent-environment system) from the observations of the environment by the agent.
Definition 4.3 (Initial state). Fix a normalized (norm ) initial state of the environment, and let be the state of the agent corresponding to an empty memory tape, i.e. given by for all . Let be the initial state of the joint system.
Definition 4.4. For a policy , let the marginal distribution of the universal observable be defined according to the Born rule: I.e. the norm square of the vector obtained by evolving the universe following policy for time-steps from the initial state, and then projecting onto the observation subspace corresponding to the universal observation . So
Definition 4.5. Let be the set of "all possible states of the universe" (more precisely the set of all possible outcomes of all observations on the joint agent-environment system). More generally, define analogously for any subset .
Definition 4.6. For a finite subset , let be the free product of the , as defined in Definition 3.9. For varying this defines an ultrakernel and the associated semidirect product Taking the bridge transform and projecting out the physical factor : we get
If , we have a natural "refinement" map , given by projecting out the additional factors in . By Lemma 3.14, we have
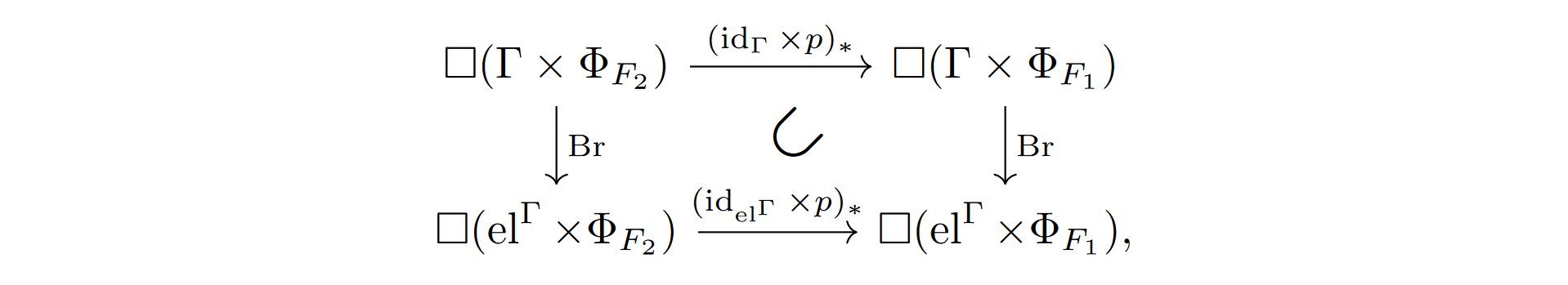
Definition 4.7. Let where the intersection is over all finite subsets of .
4.1. Copenhagen interpretation
Definition 4.8. Let be an observation-action history, and denote by the projection corresponding to the proposition "the memory tape recorded history ". More precisely , where
Definition 4.9. Given a sequence of observation-action pairs , let denote the truncated history (i.e. the image under projecting out the last components of if , and itself if ).
In the Copenhagen interpretation the "universe" (i.e. the joint system of the agent and the environment) collapses after each observation of the agent.
Definition 4.10. Given a policy , the initial state , and a sequence of observation-action pairs , we can define for recursively. Then according to the Copenhagen interpretation, the probability of observing is
Lemma 4.11. Collapsing at each step is the same as collapsing at the end, that is
Proof. The claim is true for by definition. Assume it's true for , so Let's write so Then if , we have while Now unless and , hence as claimed.
4.2. Relating the two interpretations
Since , we can take expectations of functions , in particular indicator functions for .
Definition 4.12. For a policy , and a tuple of observations , define and let
Remark 4.13. In what follows we'll assume . This assures that the set of policies is richer than the set of histories (i.e. . Much of the following fails in the degenerate case .
When considering the infra-Bayesian physicalist interpretation of a quantum event , we'll consider the expected value As defined in Definition 4.6, can be thought of as the infra-belief which is a joint belief over the computational-physical world, with complete Knightian uncertainty over the policy of the agent (as a representation of "free will"), and for each policy the corresponding belief about the physical world is as given by the unitary quantum evolution of the agent-environment system under the given policy. The bridge transform of then packages the relevant beliefs about which computational facts are manifest in the physical world. The subset corresponds to the proposition "the policy outputs action upon observing ", and hence corresponds to the belief "the physical world witnesses the output of the policy on to be (which is to say there's a version of the agent instantiated in the physical world that observed history , and acted )". We'll be investigating various claims about the quantity which is the ultraprobability (i.e. the highest probability for the given Knightian uncertainty) of the agent following policy and not being observed (i.e. no agent being instantiated acting on history ).
Remark 4.14. It might at first seem more natural to consider the complement instead, that is , which corresponds to the agent following policy , and history being observed. However, it turns out that always. This can be understood intuitively via refinement (see Lemma 3.14): we can always extend our model of the physical world to include a copy of the agent instantiated on history , so the highest probability of being observed will be . This is also related to the monotonicity principle discussed in [IBP [AF · GW]]. Thus although at first glance this might seem less natural, in our setup it's more meaningful to study the ultraprobability of the complement, i.e. of not being observed. Note that since we're working with convex instead of linear expectation functionals (see Lemma 3.7), the complementary ultraprobabilities will typically sum to something greater than one.
We first state Claims 4.15 and 4.17 relating the IBP and Copenhagen interpretations "on the nose", which both turn out to be false in general. Then we state the weaker Theorem 4.19, which is true, and establishes a form of asymptotic relationship between the two interpretations.
Claim 4.15. The two interpretations agree on the probability that a certain history is not realized given a policy. That is,
This claim turns out to be false in general, and we give a counterexample in Counterexample 5.3. Note, however, that the claim seems to be true in the limit with many actions (i.e. ), which would warrant further study. Now consider the following definition concerning two copies of the agent being instantiated.
Definition 4.18. For a policy , and two tuples of observations , define and let
Claim 4.17. There is only one copy of the agent (i.e. the agent is not instantiated on multiple histories, there are no "many worlds"). That is, if neither of is a prefix of the other, then
This claim is the relative counterpart of Claims 4.15 and fails as well in general (see Counterexample 5.5). Again, however, this claim might hold in the limit.
Definition 4.18. An event is a subset of histories . We define the corresponding and
Theorem 4.19. The ultraprobability of an agent not being instantiated on a certain event can be bounded via functions of the (Copenhagen) probability of the event. More precisely,
Proof. We prove the upper bound in Section 6.1 and the lower bound in Section 6.2.
Due to the failure of Claims 4.15 and 4.17, we can think of the infra-Bayesian physicalist setup as a form of many-worlds interpretation. However, since the above Theorem 4.19 shows statistical consistency with the Copenhagen interpretation in the sense that observations that are unlikely according to the Born rule have close to ultraprobability of not being instantiated (while very likely observations have close to ultraprobability of uninstantiation).
Remark 4.20. For simplicity we assumed only contains entire histories (i.e. ones of maximal length ). It's easy to modify the definitions to account for partial histories. The inequalities in Theorem 4.19 remain true even if includes partial histories, and the proofs are easy to adjust. We avoid doing this here in order to keep the notation cleaner. However, it's worth noting some important points here. For a partial history , let be the set of all completions of , i.e. Then we have On the other hand, so there is an important difference here between the two interpretations, which would warrant further discussion. In particular, under the infra-Bayesian physicalist interpretation it can happen that for a partial history and its set of completions . This could be loosely interpreted as Everett branches "disappearing", as the ultraprobability of an agent not being instantiated on the partial history is less than that of the agent not being instantiated on any completion of that history.
4.3. Decision theory
To shed more light on the way the infra-Bayesian physicalist interpretation functions, it is interesting to consider the decision theory of the framework, along with the epistemic considerations above.
Definition 4.21. Consider a loss function where is the set of destinies. We can then construct the physicalized loss function (cf. [IBP [AF · GW] Definition 3.1]) given by where is the set of histories witnessed by , that is Note that in our simplified context, doesn't depend on .
Definition 4.22. We can define the worst-case expected physicalized loss associated to a policy by Under the Copenhagen model, we would instead simply consider
Remark 4.23. Given a policy , we can consider the set of "fair" counterfactuals (cf. [IBP [AF · GW] Definition 1.5]) i.e. where if witnesses the history , then agrees with on that history. This definition is in contrast with the "naive" counterfactuals we considered above (when writing ): In Definition 4.22 above, and generally whenever we use , we could have used the indicator function of instead. The choice of counterfactuals affects the various expected values, however, all of the theorems in this article remain true (and Claims 4.15 and 4.17 remain false) for both naive and fair counterfactuals. We thus work with naive counterfactuals for the sake of simplicity.
Similarly to Section 4.2, the "on the nose" claim relating the two interpretations fails, but we have an asymptotic relationship which holds.
Claim 4.24. The two interpretations agree on the loss of any policy:
Again, this turns out to be false, and we give a simple counterexample in Counterexample 5.6.
To allow discussing the asymptotic behavior, assume now that we incur a loss at each timestep, given by and we consider the total loss We might hope that we could have at least the following.
Claim 4.25. The two interpretations agree on the loss of any policy asymptotically: i.e. the difference is bounded sublinearly in .
This claim is still false in general for essentially the same reason as Claim 4.24 since certain policies might involve a one-off step that then affect the entire asymptotic loss. We give a detailed explanation in Counterexample 5.7. We do however have the following.
Theorem 4.26. If the resulting MDP is communicating (see Definition 7.8), then for any policy we have where is a Copenhagen-optimal policy. In particular, optimal losses for the IBP and Copenhagen frameworks agree asymptotically.
Proof. See Theorem 7.1 for the upper bound and Theorem 7.21 for the lower bound.
5. Examples
We'll look at a few concrete examples in detail, firstly to gain some insight into how Claims 4.15 and 4.17 fail in general, and secondly to see how our framework operates in the famously puzzling Wigner's friend scenario.
5.1. Counterexamples
We'll construct simple counterexamples to Claims 4.15 and 4.17 in the smallest non-degenerate case, i.e. when and , and . Let and . There are four policies in this case (ignoring the value of the policies on the empty input, which is irrelevant in our setting, see Remark 2.8), which we'll abbreviate as , where Assume , and , so .
Recall [IBP [AF · GW] Lemma 1]:
Lemma 5.1. For , we have if and only if for each and where is given by .
Lemma 5.2. Let be a kernel, , and as above. Then
Proof. To obtain a lower bound (although we'll only use the upper bound for the counterexample), define the contribution by where are such that and One possible such choice is Then it's easy to verify that , and To obtain an upper bound, fix , and use Lemma 5.1 for constant , and . We have and so Analogously for and we get and
Now, so by we get
We also have , since and together would imply . Thus so adding and , we obtain Now, since both and hold, we get Finally, summing over we have the required upper bound
Counterexample 5.3. Let be a qubit state space, and Let . Let the observation correspond to measuring the qubit, so are projections onto and respectively. Then Claim 4.15 fails in this setup.
Proof. We have and so Now consider the universal observable which is measurement along the vector and its complement, where I.e. we have , and where , are projections in onto and its ortho-complement respectively. Then we have the following values for for the various policies:
| 2/3 | 0 | 0 | |
| 1/3 | 1 | 1 |
This can be seen by noticing that is perpendicular to both and , while , so This means that for this we have If , by Lemma 5.2 we have Now, by definition , so we also have
Although we won't need the exact value here, we remark to the interested reader that in the above setup of Counterexample 5.3, the ultraprobability attains the lower bound of Theorem 4.19, that is
We can extend the above counterexample to apply to Claim 4.17, via the following.
Lemma 5.4. Let be a kernel, , and as above. Then for , ,
Proof. Analogous to Lemma 5.2.
Counterexample 5.5. In the setup of Counterexample 5.3, Claim 4.17 fails too, that is
Proof. Consider projecting onto the three vectors and Then the corresponding probabilities are
| 1 | 1/4 | 1/4 | 0 | |
| 0 | 1/2 | 1/2 | 0 | |
| 0 | 1/4 | 1/4 | 1 |
So we have Then again, by refinement, this implies that as well.
Counterexample 5.6. Claim 4.24 fails in the setup of Counterexample 5.3, with loss given by
Proof. In this case Notice that for this we actually have so by the considerations in Counterexample 5.3, we also have (for any policy ) showing failure of Claim 4.24.
Counterexample 5.7. The setup of Counterexample 5.6, run over time horizon instead of just a single timestep shows the failure of the asymptotic claim Claim 4.25 in general.
Proof. The point is that in this setup the entire loss is determined by the outcome of the first observation: if we observe , we'll incur loss during the entire time, while if we observe first, we're "stuck" in that state, and hence incur a total loss equal to . Due to this, we have for any policy .
Note that in the above setup, we get "stuck" in the states after the initial observation because the MDP itself is not communicating. However, even for communicating MDPs (for example if we choose to be a rotation by ) certain policies will get stuck (for example the policy that always chooses corresponding to ). So we see this behavior whenever the asymptotic loss is dependent on a few initial steps. On the other hand, for example if is a stationary policy, and the resulting Markov chain is irreducible, then we can obtain a concentration bound on the loss (e.g. via the central limit theorem, [Dur96[2], 5.6.6.]), and use an argument similar to Theorem 7.21 to show that and indeed agree asymptotically under such assumptions.
5.2. Wigner's friend
We'll consider a scenario originally attributed to Wigner, and we'll work in an extension of the setting introduced in [BB19[3]]. For brevity, we'll omit detailed computations in this section and focus on the higher level ideas instead. Consider a joint system consisting of three parts, a spin- particle , a friend in a lab, making observations of , and Wigner making observations of the lab (the joint friend-particle system ).

Now let's assume follows the constant policy (for ). Then Wigner will observe with probability . Yet, if the friend believes that having observed , the state of the lab collapsed to , then the friend would expect Wigner to observe or with probability each. Thus, within collapse theories we have an apparent conflict between the predictions of Wigner and the friend.
We can model this scenario within IBP by taking be the pairs of policies of Wigner and the friend. Analogously to Definition 4.6 we can define as the joint outcome of all observables on the joint triple system , a kernel , and the corresponding belief and its projected bridge transform . To be more precise we would again build this out of finite subsets of , as in Definition 4.7.
Given this setup, we can write down various definitions. For , let Then we can compute i.e. the observation of Wigner is certain to be instantiated if follows the policy .
We can also write down other quantities, for example for , , we can define and the analogous . The quantity would then be the ultraprobability of the pair ( observing , observing ) being uninstantiated. We can estimate the value of this ultraprobability using techniques similar to Section 6 to be around .
This setting is helpful to differentiate the decision theory of IBP from a collapse theory. For example, consider a loss function that depends only on Wigner's observation, with values: Now suppose the friend is trying to minimize .[4] Then assuming a unitary evolution of the lab, clearly is the optimal policy. However, if the friend assumes a collapse of the lab after her observation, then always choosing action avoids ever having an overlap with the high-loss , making the constant policy optimal under the collapse interpretation.
We can consider this decision problem within IBP by working with the physicalized loss function (cf. Definition 4.21), given by [5] Then in IBP the friend would look for the policy minimizing the loss We can verify that the minimal loss occurs exactly when as expected, in contrast with the collapse interpretation.
6. Bounds on the ultraprobabilities
We'll make use of the following observation.
Lemma 6.1. For a given history , if two policies agree on all prefixes of , i.e. then where is the projection corresponding to the observation , i.e. the memory tape having recorded .
Proof. For we have and similarly for . Now for we have since by assumption. For we can proceed by induction, using Lemma 4.11.
6.1. Upper bound
To prove an upper bound on the expectation value, we can coarsen our set of physical states to only include measurements of the memory tape.
Let be the set of destinies.
Definition 6.2. Let be the universal observable corresponding to reading the destiny off the memory tape at time . That is, , and for is given by
Definition 6.3. Let be the relation of a destiny being compatible with a policy. That is, for if and only if for each .
Let , and note that . Let be the corresponding kernel.
Lemma 6.4. The kernel is a PoCK for .
Proof. This is essentially saying that whenever are both compatible with a destiny , then This claim follows by Lemma 6.1.
Then by [IBP [AF(p) · GW(p)] Proposition 4.1] we have
Lemma 6.5. The bridge transform equals In particular, for a monotone increasing (in ) function , we have
For (note that is monotone decreasing) and we have if
-
,
-
, and
-
for some .
Lemma 6.6. We have if and only if and (where as before).
Proof. If and , then implies , so .
For the converse, assume . First choose (which is always non-empty). In particular , so means as well.
Now assume . Then choose as follows. For , let Then , contradiction.
We therefore have Here so by applying of Lemma 6.5 to the monotone increasing , we have since whenever so the is attained when . Since by definition, we have Proposition 6.7.
6.2. Lower bound
Definition 6.8. For ease of notation we'll write
Theorem 6.9. We have a lower bound
Proof. We'll exhibit a contribution (Definition 6.12) such that (Proposition 6.18). The constructed has (Lemma 6.13) which in turn will show that
The rest of this section is dedicated to spelling out the results that are used in the proof outline above.
Lemma 6.10. Let be a set of three orthonormal vectors, and where with . Then the trace distance between the density matrices and is
Proof. In the basis given by , the matrix of is The eigenvalues of this (rank 2) matrix are , and , so the sum of the absolute values of the eigenvalues is
Lemma 6.11. For two policies , let Then for any ,
Proof. Roughly speaking, since and only differ outside of , if the event was observed then and behave identically. More precisely, let be a sequence of observations up to time . Then, if for some , by Lemma 6.1 we have Without loss of generality we'll assume from now on. Now, and similarly for . Write where the two sums are equal by . Also write and so that and The three vectors , , are orthogonal (since all of their components are), and From this, using Lemma 6.10, we can compute the trace distance between and to be
Now, for any measurement , if we write for the distribution of outcomes, where . Then the total variation distance between the distributions and is bounded above by the trace distance. That is, So the overlap is bounded below as claimed
Definition 6.12. Given a policy and an event , choose such that Note that we are using here to allow the choice satisfying the first condition. That is, agrees with on all histories except for the ones whose completions all lie in . Let
Lemma 6.13. We have
Proof. The claim follows since for any .
Definition 6.14. Let
Lemma 6.15. The contribution has mass , i.e. . Moreover,
Proof. The mass follows from the definition. The inequality in the second claim follows by taking and in Lemma 6.11, and noticing that the in the lemma equals in this case.
Lemma 6.16. For finite , let Then .
Proof. For any , consider the projection Then under we have where the last inequality follows from Lemma 6.15. Since this is true for all , we have and also , hence .
Proposition 6.17. For each finite , we have and hence
Proof. Let be an endomorphism of the computational universe. We need to verify that for any such , under the composite
-
If , then since by Lemma 6.16.
-
If , then since as well by Lemma 6.16.
Proposition 6.18. We have
Proof. This follows immediately from Proposition 6.17 and the Definition 4.7 of .
7. Asymptotic convergence
7.1. Upper bound
Theorem 7.1. For any policy , where the two sides are as in Definition 4.22.
Proof. Using the notation from Section 6, we can apply of Lemma 6.5 to the monotone increasing , to get since the maximum over is attained when , due to the factor. We have that
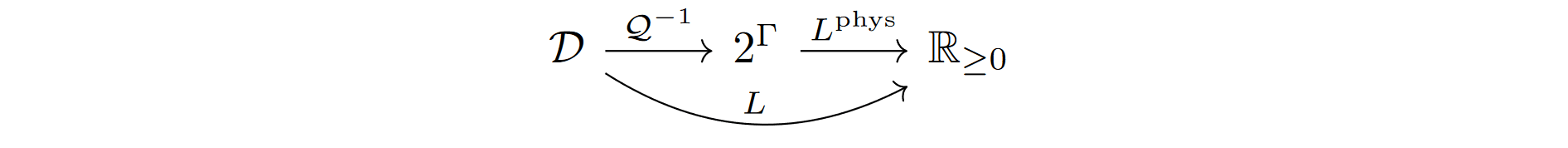
7.2. Asymptotic behavior of communicating MDPs
This section introduces some general definitions and lemmas in the theory of Markov decision processes. Our main goal here is to state and prove Proposition 7.17, concerning the asymptotic behavior of a communicating MDP. None of these results are to be considered original, but are intended as an overview for the reader, as well as a way to establish the exact form of an asymptotic bound that we need (which we couldn't find verbatim in the literature).
Definition 7.2. Let a finite Markov decision process (MDP) be given by the following data (cf. [Put94[6] Section 2.1]).
-
A finite set of states ,
-
a finite set of actions ,
-
a transition kernel ,
-
and a loss function .
Remark 7.3. The above setting is not the most general one (for example, we could let the set of actions depend on the state, or allow the loss function to be stochastic). The simplifying assumptions we make in the above definition are mostly for the ease of discussion rather than strictly necessary. Some of the results might need additional assumptions in the more general setting, e.g. for Proposition 7.17 we might want to assume that a stochastic is still bounded.
Definition 7.4. For , let be the set of histories up to time , be histories up to some time horizon , and be the set of (randomized, history-dependent, cf. [Put94[6:1] Section 2.1.4]) policies.
Remark 7.5. We allow randomized policies here, simply because our discussion in this subsection fits naturally with that generality, and also since it seems common to do so in the classical MDP literature. Note however that optimal policies for an MDP can always be chosen to be deterministic, so our discussion is still compatible with the quantum case, where we only allowed deterministic policies (cf. Remark 2.3).
Definition 7.6 (Time evolution of an MDP). For a given policy , and an initial state , we can define recursively for each a distribution as follows. Take , and consider We can then form . Now we can compose where is projection onto the th factor. Then we can let We let be the resulting distribution on destinies , More generally, we can begin with a condition at time , given by , and follow the time evolution above to a distribution For a subset , we'll write for the probability of , and for a function , we'll write for the expected value of with respect to .
Definition 7.7. For , define by and let be the total loss
Definition 7.8. We call an MDP communicating (cf [Put94[6:2] Section 8.3]), if for any pair of states , there exists a policy and a time such that where extracts the th state of a destiny. Roughly speaking, a communicating MDP allows navigating between any two states with non-zero probability.
We now have all the definitions involved Proposition 7.17, our main result in this section. In the following, we'll introduce various definitions and lemmas that we'll make use of in the proof.
Definition 7.9. For a destiny and a state , define by that is the first time at which state occurs (or if doesn't occur). Let be given by that is the minimum expected arrival time to , starting from .
Lemma 7.10. For a communicating MDP, there is a constant such that for any time horizon , for all .
Proof. Let be two states where the maximum is attained. Since the MDP is communicating, there exists a policy and a time such that Following this for timesteps (assuming , otherwise trivially), we get by conditioning the state we land on on the th step. Now, where follows from the assumption on the policy arriving to with probability after steps, and follows from our assumption on being maximal (so ). Combining with , we get so
Definition 7.11. For , let the value function be given by i.e. the minimal expected remaining loss after time , assuming the state at time agrees with . Here truncates to an initial history.
Remark 7.12. As defined above, the value function depends on the entire history , up to time . It turns out (see [Put94[6:3] Theorem 4.4.2.]) that in fact it's determined by the last state, , of this history. By slight abuse of notation, we'll write for the resulting function as well.
Lemma 7.13. For a communicating MDP, there exists a constant , such that for any time horizon ,
Proof. Let , and . By Lemma 7.10, , and let be a policy that attains Let be a policy that attains Now construct a policy as follows. In words, follows from until arriving at , and from then on follows . Formally, we can write for a history , (Note that we use as a way of shifting the history in time, for example .) Now, we have and we can write where is smallest such that . Here so
for , where is as in Lemma 7.10. To summarize in words, starting from we can make it to in at most expected timesteps, accumulating at most loss in expectation. Then we can follow the optimal policy starting at time from , and accumulate loss, which is at most different from . Putting these together, we get .
Lemma 7.14. For any policy , and any ,
Proof. By the optimality of , we have where is the th state, and On the other hand, i.e. the expected value of when the action is distributed according to the policy . The inequality now follows.
Definition 7.15. Let .
Lemma 7.16. We have for any policy and initial state with , and for , where is as in Lemma 7.13.
Proof. Since, by Lemma 7.14 we have for any history , the same holds for any distribution of histories, in particular also for the given by the time evolution of . We also have from which follows.
Proposition 7.17. For a communicating MDP, there is a constant such that for any policy and initial state , holds whenever where is the minimal expected loss. In words, it's unlikely (under any policy and initial state) for the total loss to be much below the minimal expected loss.
Proof. We have where is a bounded sub-martingale by Lemma 7.16, so by Azuma's inequality we get Since this holds for all , and , we also get the stated result.
7.3. Lower bound
We can use the result above to obtain a lower bound on .
Definition 7.18. Assume we have the setup of a system given in Section 2, and furthermore that is a complete set of observations (so each has a 1-dimensional image). Then given a loss function , there's a Markov decision process associated with this setting, where the set of states is , and the transition probabilities are given via the Born rule: where is a unit vector in the image of .
Remark 7.19. It might be interesting to also consider the case where is incomplete. In this case there's an associated POMDP (partially obvervable Markov decision process). Note, however that a priori this POMDP will have infinitely many states (all rays in the image of for each ). We won't pursue this direction here.
Remark 7.20. To understand the structure of the resulting MDP a little better, consider the following. For two observations , let's say that ( can be reached from ) if for some , and take the transitive closure of this relationship. The resulting relationship is in fact also symmetric and reflexive. This follows because the unitary group is compact (since we assume is a finite and complete set of observations, so is finite dimensional), so powers of can approximate the identity and arbitrarily. Thus the MDP is a disjoint union of communicating components (the equivalence classes of the relation above). For generic , we'll have a single equivalence class. Otherwise the first observation picks out a component, and the rest of the evolution remains within that component.
Theorem 7.21. If the associated MDP to a setup is communicating, then for any policy , we have where is the minimal Copenhagen loss (i.e. for a Copenhagen-optimal policy ).
Proof. For , consider the event Choose a policy as in Definition 6.12. Then it's easy to verify using the definition of , that Let be the Copenhagen probability that the loss is at most , given the policy . By Proposition 7.17 we have that
By Proposition 6.18, we have
for . Therefore by and , we have Here , and using , we get To obtain an bound, we can set , which gives since .
Note that Theorem 4.26 implies that any Copenhagen-optimal policy is also asymptotically IBP-optimal. The converse is also true, but requires a bit more work.
Theorem 7.22. If is an IBP-optimal policy, then where is the Copenhagen-optimal loss.
Proof. For , consider the events On a high level, the proof goes as follows. We already know that the Copenhagen probability of is small. We'll show that for an IBP-optimal , the complement of also has small probability, so most of the probability mass is where the loss is between and , which will be sufficient to show that is not much bigger than .
Choose policies , corresponding to and as in Definition 6.12. Let so . Again, by Proposition 6.18, where By Lemma 6.11, Proposition 7.24 applies as well, so in this case we also have Hence Since is IBP-optimal, we have for any Copenhagen-optimal policy , From and together we have Rearranging, and using as before, we get so choosing and , we have Hence Therefore
We can likely improve on the exponent of via more sophisticated estimates, but we won't be needing that for the current level of our discussion.
Remark 7.23. More generally, we can see that an asymptotically Copenhagen-optimal policy is also asymptotically IBP-optimal, and vice versa. In light of Remark 7.20, this remains true even when we drop the assumption of the MDP consisting of a single communicating component. Theorems 7.21 and 7.22 can be applied to each component separately, thus the optimal policies still need to agree asymptotically. The two interpretations then weigh the asymptotic losses of the components differently based on the amplitude of the components in the initial state (the IBP interpretation is more optimistic in the sense that it typically considers the lower loss branches with more weight than the Copenhagen interpretation), hence Theorems 7.21 and 7.22 fail in the case of an initial state that is the superposition of multiple communicating components, but only due to the outcome of the first observation being irreversible in this case, which doesn't affect the claim about the optimal policies agreeing asymptotically.
We finish this section by spelling out the proof of the following.
Proposition 7.24. If are three policies such that for any , for , then
Proof. The proof is mostly analogous to Proposition 6.18, we highlight the additional ideas here. The claim reduces to Proposition 6.18 for , so we'll assume in the following. For , let (cf. Definition 6.14) so , and , since by assumption. Now let so , and , since by the assumption that . Moreover, by construction . We can then define for any finite , so analogously to Lemma 6.16, we have Using this, we can show that
To see this, consider an endomorphism , and let be as in Definition 3.12. The interesting cases are the following:
-
If , then since by the above.
-
If for , then since as well by the above.
Therefore Since this is true for arbitrary , we conclude .
8. Limitations
We mention some limitations of the setting, some of which as simply due to the toy nature of the model, others seem to be more inherent to infra-Bayesian physicalism.
8.1. Limitations of the toy setting
Although a central feature of infra-Bayesian physicalism is a lack of privilege for any observer, in the toy model we work with an explicit decomposition of the universe into agent and environment. Other toy assumptions are taking the "computational universe" to consist solely of the policy, and the explicit dependence of the time evolution on the policy. In a more realistic setting we would start with a non-Cartesian (not agent-centric) description of the universe, and a rich nexus of mathematical structure encoded in . The entanglement between the agent's policy and the physical state of the universe would then be encoded implicitly via a "theory of origin" whereby the agent arises in the given universe.
To spell the above out a little more, in a more realistic setting we could take , and choose to be a sufficiently rich set of computations to include things like
"a program computing the 11th decimal place digit of the amplitude squared of a certain path integral in some lattice QFT and verifying if it’s equal to 7".
Then will contain a lot of immediately inconsistent valuations, like the one where a certain digit is both equal to 7 and to 3. However, we can take a subset , which is "consistent enough", e.g. so that for every computation of the form "a certain digit in a given quantity equals ", exactly one of evaluates to , all others evaluate to . We would choose to be sufficiently small to produce a meaningful map (describing a certain model of physics), e.g. so that the distribution of the momentum of a given field modeled in , at a point is given as specified by the values of the computations like above. We can then combine the mathematical/computational part of a hypothesis (supported only on the sufficiently consistent part of the computational universe ) with to construct a corresponding joint hypothesis .
The notion of a "theory of origin" has not been formalized yet, but we informally discuss some ingredients here. Given the source code of the agent, and a policy , we can define the -counterfactual of as where is the subset of universes compatible (by some notion) with the given policy (cf. [IBP [AF · GW] Definition 1.5], also Remark 4.23). We can then look at the diameter of these counterfactuals in some metric, as a measure of the extent to which the agent is realized in the given physical model (i.e. how entangled the agent's policy is with the world). Moreover, in a more realistic setting we would expect the entanglement between the policy and the world to come from "non-contrived" reasons (as opposed to our toy model, where we just postulated the dependence of the time evolution on the policy), which could be measured by some notion of complexity of the source code relative to the physical hypothesis (higher relative complexity means a less contrived theory of origin).
8.2. Limitations of the broader framework
The decision theory of infra-Bayesian physicalism is based on a computationalist loss function . So the value of the loss is required to be determined by the state of the computational universe plus the fact of which computations are realized in the physical universe. This can lead to non-trivial translation problems from loss functions that are specified in more traditional terms. Moreover, the computationalist loss function is required to be monotonic (see monotonicity principle in [IBP [AF · GW]]) in the computations realized, a requirement not immediately intuitive.
Working with a finite time horizon is convenient for technical reasons, but not expected to be strictly necessary. ↩︎
Richard Durrett. Probability: theory and examples. Duxbury Press, second edition, 1996. ↩︎
Veronika Baumann and Časlav Brukner. Wigner’s friend as a rational agent, 2019. ↩︎
If we wanted to work in a strictly subjectivist framework for the friend, we could include an additional observation of Wigner's memory tape by the friend, and have the loss function depend on the outcome of that observation. We don't expect this to make a significant difference for the present discussion. ↩︎
We could also require that witness having observed something, which would correspond to adding the condition that . We expect this would change some of the exact expected values of the loss, but not the optimal policy in this case. ↩︎
Martin L. Puterman. Markov Decision Processes: Discrete Stochastic Dynamic Programming. John Wiley & Sons, Inc., 1st edition, 1994 ↩︎ ↩︎ ↩︎ ↩︎
6 comments
Comments sorted by top scores.
comment by Mitchell_Porter · 2024-02-14T22:42:14.479Z · LW(p) · GW(p)
Wouldn't an infra-Bayesian formalization be possible for any interpretation (whether ontological or epistemological) that is mathematically precise?
Replies from: Yegreg↑ comment by Yegreg · 2024-02-17T01:32:13.678Z · LW(p) · GW(p)
What do you mean by a mathematically precise interpretation? And what would it mean to have an infra-Bayesian formalization of any such interpretation?
Replies from: Mitchell_Porter↑ comment by Mitchell_Porter · 2024-02-17T02:40:56.311Z · LW(p) · GW(p)
What do you mean by a mathematically precise interpretation?
A mathematically precise ontological interpretation is one in which all the elementary properties of all the world(s) are unambiguously specified. A many-worlds example would be a Hartle multiverse in which histories are specified by a particular coarse-grained selection of observables. A one-world example would be a Bohmian universe with a definite initial condition and equation of motion.
A mathematically precise epistemological interpretation is one in which reality is divided into agent and environment, and e.g. the wavefunction is interpreted as implying subjective probabilities, likelihoods of possible experiences, and so forth.
what would it mean to have an infra-Bayesian formalization of any such interpretation?
My understanding of infra-Bayesianism is not as precise as I would wish, but isn't it basically a kind of decision theory that can apply within various possible worlds? So this would mean, implementing infra-Bayesian decision theory within the worlds of the interpretations above.
Replies from: Yegreg↑ comment by Yegreg · 2024-02-21T18:49:39.514Z · LW(p) · GW(p)
Thanks for clarifying. I'll try to answer the original question first, and then expand a little on the comparison with other interpretations that might help understand the motivation for this work a little better.
I'm imagining on the high level you have something like the following in mind (correct me if not). Suppose is all the possible states of the universe, and suppose we have a subset of possible worlds (the "multiverse") , then we might simply say we have Knightian uncertainty over the possible worlds, which would correspond to an infra-belief . Then if we have a loss function , we might apply some decision rule, e.g. minimizing worst-case expected loss (note that in this case this just turns out to be ). Arguably, this is not a very good way to make decisions in a quantum multiverse, since we're completely ignoring the amplitudes of the different worlds.
The usual thing to do instead is to consider the distribution , where the probability , assuming is a decoherent set of worlds, and is the amplitude of world . Then we can consider minimizing the expected loss . Putting aside questions of subjective versus objective probabilities (and what the latter would mean), this high-level approach could cover various ontological interpretations, including the Bohmian view, and consistent histories (which is what Hartle uses).
I would say the main issue with the above approach is that it involves a choice of ontology as well as a choice of multiverse (note that these are both things that an agent inside the universe would construct). Even if we assumed that we do have a loss function (which is already very questionable), the expected loss in general would still depend on the choice of the multiverse.
Infra-Bayesian physicalism is aiming to address some of these issues by providing a framework to talk about losses that translate meaningfully across ontologies.
Replies from: Mitchell_Porter↑ comment by Mitchell_Porter · 2024-03-07T13:58:52.578Z · LW(p) · GW(p)
Hello again. I regret that so much time has passed. My problem seems to be that I haven't yet properly understood everything that goes into the epistemology and decision-making of an infra-bayesian agent.
For example, I don't understand how this framework "translates across ontologies". I would normally think of ontologies as mutually exclusive possibilities, which can be subsumed into a larger framework by having a broad notion of possibility which includes all the ontologies as particular cases. Does the infra-bayesian agent think in some other way?
Replies from: Yegreg↑ comment by Yegreg · 2024-03-20T01:43:40.472Z · LW(p) · GW(p)
I would say the translation across ontologies is carried out by "computationalism" in this case, rather than infra-Bayesianism itself. That is, (roughly speaking) we consider which computations are instantiated in various ontologies, and base our loss function off of that. From this viewpoint infra-Bayesianism comes in as an ingredient of a specific implementation of computationalism (namely, infra-Bayesian physicalism). In this perspective the need for infra-Bayesianism is motivated by the fact that an agent needs to have Knightean uncertainty over part of the computational universe (e.g. the part relating to its own source code). Let me know if this helps clarify things.