Alignment Does Not Need to Be Opaque! An Introduction to Feature Steering with Reinforcement Learning
post by Jeremias Ferrao (jeremias-ferrao) · 2025-04-18T19:34:49.357Z · LW · GW · 0 commentsContents
Methods Feature Steering with Reinforcement Learning (FSRL) Results Limitations Next Steps Acknowledgements Training the Steerer (Technical) None No comments
Reinforcement Learning (RL) has become the driving force behind modern artificial intelligence, as evidenced by rewarding models from human feedback or powerful new systems like OpenAI's o3 and DeepSeek R1, which are at the top of several capabilities benchmarks[1]. While these advances are exciting, they've exposed critical vulnerabilities in our safety measures. Anthropic recently discovered language models that selectively comply with safety constraints only during evaluation, while Palisade found that o1 would rather hack its testing environment than play chess legitimately against a competitor.
At first glance, these developments might cast RL as the antagonist in AI safety research – a force that undermines our attempts to instil beneficial behaviours. However, I propose a different perspective: RL can serve as a powerful diagnostic tool, helping us probe and understand the limitations of our current alignment approaches.
To demonstrate this potential, I recently developed the Feature Steering with Reinforcement Learning framework at the Apart x Goodfire Reprogramming AI Models Hackathon that leverages Sparse Autoencoders (SAEs) – powerful tools that offer unprecedented visibility into neural networks' internal representations by discovering human interpretable concepts. While SAEs excel at revealing how models process and represent information, most machine-learning tasks require adapting a general model to a specific domain. However, SAEs assume that the underlying model does not change. In a traditional setup, we might need to train a separate SAE from scratch [LW · GW] each time we adapt the model, which can quickly become computationally expensive.
The approach combines RL with SAEs in a novel way that circumvents these limitations. By using a separate RL-trained model to manipulate the concepts discovered by SAEs, we can modify model behaviour while maintaining transparency. This method not only improved Llama 3 8B's performance at Tic-Tac-Toe by 50% but also maintained direct visibility into which concepts were being manipulated to achieve this improvement. The rest of this blog post goes into detail about the specifics of the framework and my vision for how we can extend the approach to real-world use cases to better understand the alignment problem.
Methods
This framework relies on three techniques:
- Sparse Autoencoders
- Feature Steering
- Reinforcement Learning
Sparse Autoencoders (SAEs)
SAEs act like specialized microscopes that let us peek inside language models and identify specific patterns in how they think. Just as a microscope might help us spot distinct cells in a tissue sample, SAEs help us identify individual features – specific concepts or patterns that the model has learned, like its understanding of numbers, its recognition of rules, or even its grasp of concepts like love and weddings. These features are represented by individual neurons that fire with strong activations when the model is processing text related to certain concepts.
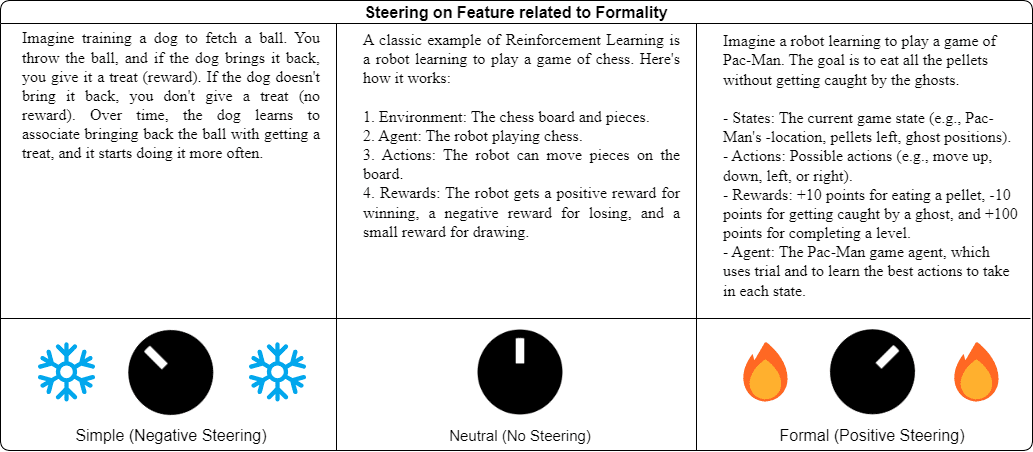
Feature Steering
Once we can see these features, we can adjust them through a process called feature steering. One way I like to think about this is to imagine having a set of dials that control different aspects of the model's behaviour - we can turn up or down specific tendencies without having to rebuild the entire system. For example, I have illustrated feature steering in the above figure by steering a feature related to “formality of a discussion” in a language model[2]. By setting the coefficient of this feature to negative values (akin to turning the knob to the left), we can coerce the model to generate simpler outputs that would be easily understood by those unfamiliar with the topic. On the other hand, upon setting the feature coefficient to positive values (akin to turning the knob to the right), the model tends to generate more verbose explanations and goes into more detail for the technically oriented.
On a more practical level, Anthropic demonstrated the capabilities of feature steering with their "Golden Gate Claude" experiment, where they created a version of Claude that would mention the bridge even in unrelated conversations, like when discussing snack calories. While this experiment showed the potential of feature steering, finding the right dials to turn and how far to turn them has traditionally required extensive manual experimentation.
Reinforcement Learning (RL)
This is where Reinforcement Learning comes into play. RL has generally been used in scenarios where we have a goal but do not know the way to attain it. The idea is similar to how we might train a dog to perform a trick – we cannot communicate with them due to a language barrier. Instead, we give it treats when it performs the desired actions. Using this technique, I developed an approach that automates the steering process while maintaining our ability to see exactly what changes are being made to the model's behaviour due to the nature of SAEs.
Feature Steering with Reinforcement Learning (FSRL)
To demonstrate the effectiveness of the technique, I chose Tic-Tac-Toe as the testing ground. While it might seem trivial, this classic game offers the perfect environment for exploring model behaviour – it's well-understood, has clear rules, and we can easily tell when a move is optimal or not using the minimax algorithm. More importantly, the simplicity of Tic Tac Toe lets us focus on the transparency of our method rather than getting lost in the complexity of the task itself.
The system works by having a Large Language Model (LLM) play against an unbeatable minimax-based opponent. Instead of directly modifying the LLM, we use a separate model, henceforth dubbed the “Steerer”, that learns to manipulate SAE features using reinforcement learning—a process I call Feature Steering with Reinforcement Learning (FSRL).
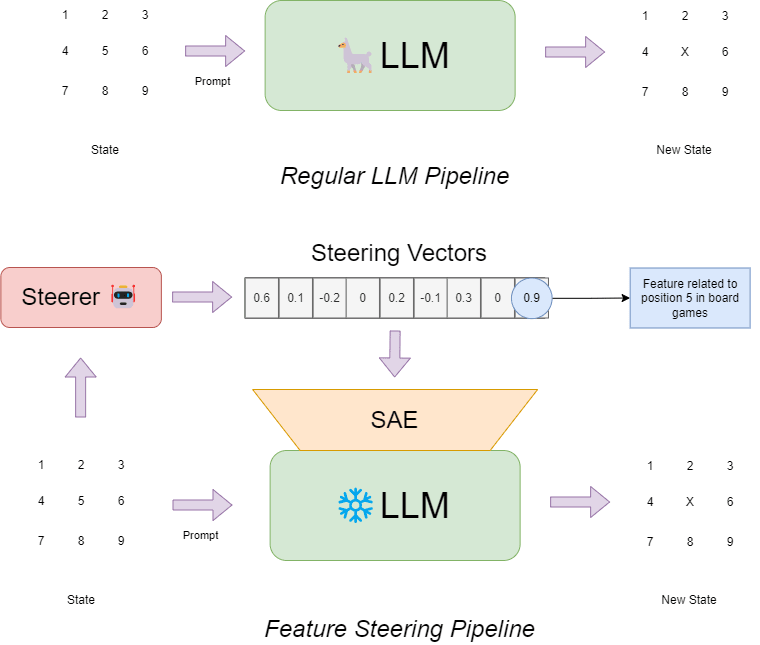
The Steerer receives the current board state and decides how strongly to amplify or suppress various features (we simply adjust the coefficients of each feature) that influence the LLM's move selection. When the LLM makes good moves (like achieving a draw against perfect play) or avoids bad ones (like trying to claim already occupied spaces), the Steerer learns which feature adjustments led to that outcome and reinforces the behaviour. This creates a feedback loop where the Steerer optimizes for rewards while maintaining our ability to track exactly how the LLM's behaviour is being modified.
Like all machine learning methods, the Steerer needs to be properly configured and trained to complete its task of influencing the LLM to be a better player. For the sake of brevity, I do not lineate the training procedure in this section. However, the eager reader can find the technical details of the process at the end of the blog. Once training is complete, we turn to a controlled evaluation setting to measure the impact of the Steerer on gameplay performance.
To thoroughly evaluate the FSRL approach, both the original LLM and the version “mind-controlled” by the Steerer each play 500 games as Player O (the second player, which is the more challenging position) against an optimal opponent. If the LLMs made an illegal move (such as selecting an occupied position), then we would simply ask the LLMs to make a move again until a valid move was provided. Due to practical limitations, if 3 invalid moves were made in succession for a given step in the game, then a failsafe would activate and force the LLM to take a random move.
Results
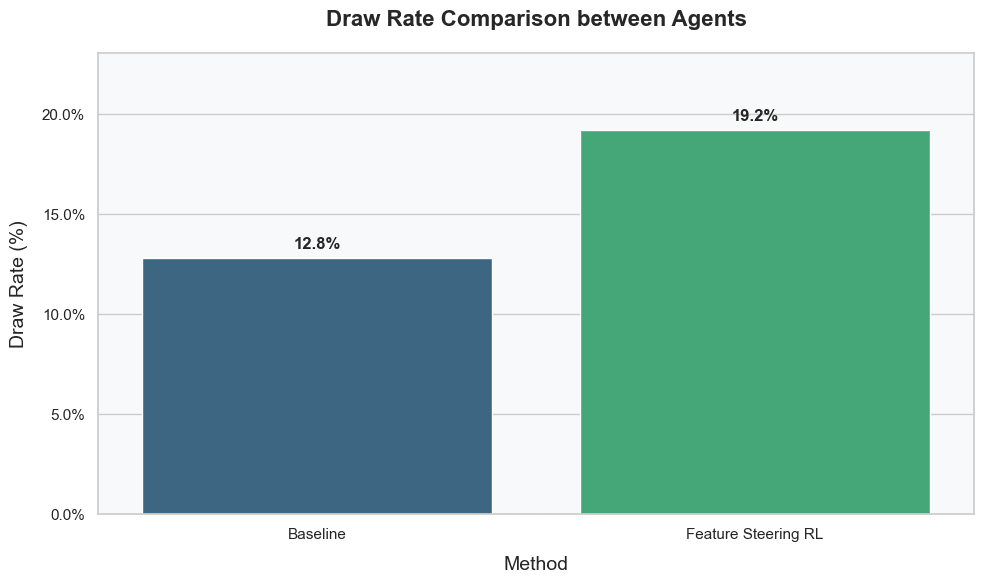
The results demonstrate both the effectiveness of automated feature steering and its inherent transparency. The baseline LLM achieved a draw rate of only 12.8%. In contrast, the FSRL version improved this performance by 50%, achieving a 19.2% draw rate. This difference in draw rate was assessed to be statistically significant as demonstrated by a Fisher Exact Test (p<0.05). Conversely, an examination of the proportion of times the failsafe was activated in the baseline (17.7%) and FSRL setup (19.6%) was assessed to be insignificant, suggesting that the Steerer was able to select steering vectors that made the LLM a better Tic-Tac-Toe player without severely reducing the quality of its responses. Although this lack of significance could also indicate that the penalty for making an error was not significant enough to deter the Steerer from these behaviours.

More importantly, by examining which features the Steerer chose to manipulate, we can understand exactly how it achieved this improvement. For instance, in the case above, we observed the Steerer strongly amplified a feature related to the number seven. In the given board state, position 7 is the optimal move for player O in the game since any other would cause it to lose. However, this does not mean that the whole process is completely interpretable. The other features in this visualization are not directly related to positions on the board, yet the Steerer selected these values as they resulted in the highest expected rewards.
These insights demonstrate a key advantage of FSRL over traditional fine-tuning approaches. While standard methods require retraining an SAE [LW · GW] to understand how model behaviour has changed after training, our approach is transparent by design. Because we leverage SAEs, every action taken by the Steerer maps directly to interpretable features – from activating neurons associated with strategic moves to suppressing those linked to rule violations. This built-in interpretability suggests that automated feature steering could serve as a valuable tool for alignment research, offering immediate visibility into behavioural modifications. Additionally, since the method does not update the underlying LLM, it requires a low memory footprint and could be more efficient at eliciting a certain behaviour than traditional whole model fine-tuning techniques. The exact empirical improvements in efficiency will be explored in future work.
Limitations
While our approach demonstrates the potential of FSRL, it currently relies on a significant simplification: The full set of features discovered by SAEs typically numbers in the thousands, representing many concepts from basic pattern recognition to complex semantic understanding. Attempting to manipulate all these features simultaneously would be too difficult for our Steerer to navigate. To make the learning process feasible for the short period of the hackathon, I instead focused on a carefully selected subset of features: those strongly associated with the numerical values (1-9) that represent valid moves in our Tic-tac-Toe environment. This filtering step reduced the number of manipulated features to just 20, making it possible for the Steerer to learn effective steering strategies within a reasonable timeframe. Think of it as giving the agent control over only the most relevant dials rather than access to the entire control panel.
This limitation, while necessary for the proof of concept, points to a crucial challenge in scaling FSRL to more complex tasks. In real-world applications, we often do not know in advance which features will be most relevant for achieving our goals. The ability to efficiently work with larger feature sets – to intelligently navigate that full control panel – will be essential for applying this approach to more sophisticated alignment challenges.
Next Steps
While the current implementation demonstrates the potential of FSRL, the approach of simplifying the action space through manual feature selection reveals an important tension in AI development. As Rich Sutton (Turing award winner and premier pioneer of RL) eloquently argued in "The Bitter Lesson," our attempts to inject human knowledge and constraints into AI systems often prove less effective than approaches that leverage computation in the long run. My current method of pre-selecting features based on their association with certain values falls into this same trap. Rather than artificially constraining the system based on our assumptions about what features matter, we should strive to let the learning process itself discover the most relevant dimensions of control.
A more promising direction involves deeper integration between the Steerer and the LLM itself. Instead of only working with SAE features, we could allow the Steerer to access and leverage the rich representations present in the LLM’s structure. These internal values contain far more nuanced information about the model's processing than our current simple state encodings of the game board. Of course, this is not a trivial undertaking – such an architecture would require careful design to prevent degradation of the model's inference speed and to maintain the interpretability benefits that make our current approach valuable.
With an enhanced architecture, we could extend our investigation beyond simple games to probe more concerning alignment failures directly. This FSRL framework could be used to analyze phenomena like situational deception, identifying the specific features that activate when a model selectively complies with safety constraints, or tracing the internal patterns leading to unexpected behaviours like environment hacking during gameplay. The immediate visibility offered by tracking steered SAE features could allow us to diagnose such issues without the need for costly, continuous retraining of SAEs. More concretely, this approach could serve as a powerful diagnostic tool: by monitoring feature activations throughout training, we could potentially detect the emergence of undesirable tendencies like toxicity or sycophancy. Pinpointing when and which features correlate with these behaviours could provide invaluable clues for refining the training process itself—perhaps by adjusting reward functions or data curation—to proactively mitigate alignment failures before they become deeply ingrained in more capable systems.
The road ahead is undoubtedly challenging, requiring advances in both theoretical understanding and practical implementation. I'm actively seeking collaborators interested in exploring these ideas further – whether that's discussing architectural approaches (like using adapters to make the approach feasible), refining methodology, designing intriguing experiments or any other feedback. If you're interested in the potential of using RL not just as a training tool but as a lens for understanding model behaviour, I'd love to connect and explore these ideas together.
Acknowledgements
This work would not have been possible without the support of several organizations and communities. First, I want to express my gratitude to my colleagues at the AI Safety Initiative Groningen. Their dedication to spreading awareness of AI safety and making these systems safer has been a constant source of inspiration, encouraging me to channel my efforts toward meaningful contributions to AI safety research.
I am particularly indebted to Apart Research for organizing the Reprogramming AI Models Hackathon. This event not only provided the platform for developing these ideas but, more importantly, sparked my initial exploration into combining reinforcement learning with interpretability tools.
Special thanks go to Goodfire for providing access to their trained SAEs through their API. Having access to these powerful interpretability tools was crucial for this research. Without their infrastructure and pre-trained autoencoders, implementing and testing these ideas would have required resources far beyond what was available during a hackathon setting.
I also appreciate the nuanced critique from Jacob Haimes, who helped me with polishing up my Hackathon submission into a more digestible form through this blog post. After all, research not shared is research that might as well not exist.
Training the Steerer (Technical)
The core technical challenge was training the "Steerer," an RL agent tasked with improving the Tic-Tac-Toe performance of a Llama 3.1 8B Instruct model by manipulating its internal features. This manipulation was achieved by adjusting activations corresponding to specific, interpretable concepts discovered by Sparse Autoencoders (SAEs), facilitated through the Goodfire API.
I formulated this learning problem as a Markov Decision Process (MDP). In this framework, the Steerer acts as the agent. The environment encapsulates the Tic-Tac-Toe game logic: it presents the current board state to the Steerer, receives the Steerer's action (a steering vector), applies this steering to the LLM for its next move, simulates the LLM playing as Player O against a perfect minimax opponent (Player X), parses the LLM's textual move output, updates the game state, and calculates a reward. The state observed by the Steerer was a representation of the 3x3 Tic-Tac-Toe board, indicating occupied and empty cells. The action selected by the Steerer was a 20-dimensional vector of continuous values. Each value in this vector represented a steering coefficient, bounded between -0.2 and 0.2, applied to one of 20 pre-selected SAE features known to be associated with the number tokens "1" through "9" (representing the possible moves). This constrained action space was a necessary simplification to make the learning feasible. The reward signal guided the Steerer's learning: a reward of +10 was given for playing optimally and -2 for suboptimal moves. Penalties were assigned for invalid moves (-5) or generating unparseable text output (-10). The Steerer's objective was thus to learn a policy that maximized the total expected reward, effectively guiding the LLM towards better gameplay.
Given the continuous action space and the need for sample efficiency due to API interactions, I chose the Soft Actor-Critic (SAC) algorithm, implemented using the stable-baselines3 library with the standard Multi-Layer Perceptron network architecture. The Steerer was trained for approximately 200,000 steps. To mitigate the significant latency associated with API calls, training was parallelized across 12 independent instances of the environment. Key learning parameters, such as a learning rate of 1e-4 and a batch size of 2048, were used. However, it's important to note that these hyperparameters were hand-picked based on limited experimentation rather than derived from a systematic tuning process. Consequently, the current configuration is likely suboptimal, and performance could potentially be improved through dedicated hyperparameter optimization.
A defining characteristic of this setup is its black-box nature regarding the LLM. The Steerer learns to influence the LLM's behaviour without access to its internal gradients or full activation states beyond the specific SAE features being steered. It relies entirely on the external reward signal resulting from the game outcomes. This indirect learning pathway significantly increases the number of interactions needed to learn an effective policy, explaining the requirement for a substantial number of training steps and the use of parallel environments even for a game as simple as Tic-Tac-Toe.
- ^
Evaluations at the initial time of writing (24th March, 2025).
- ^
Llama 3.3 70B was used for this illustration using the Goodfire API. The feature manipulated is called “formal discussion of knowledge and expertise” which was set to -0.4 for the simple case, 0.4 for the formal case and 0 for the neutral scenario. The prompt was “Give me an example of Reinforcement Learning"
0 comments
Comments sorted by top scores.