Turning Some Inconsistent Preferences into Consistent Ones
post by niplav · 2022-07-18T18:40:02.243Z · LW · GW · 5 commentsContents
Epistemic Status
Turning Some Inconsistent Preferences into Consistent Ones
Mathematical Formulation of the Problem
Related Work
Discrete Case
Example
Resolving Inconsistencies
Implementation
Problems with This Method and its Algorithm
Questions
Number of Turnings for Gn
Encoding Inconsistencies
Theory
Discrete Case
Incompleteness
Intransitivity
Non-Encodable Inconsistencies
Continuous Case
Incompleteness
Intransitivity
Discontinuity
Dependence
Discussion
Continuous Case
Vector Fields over Probability Simplices
Resolving Inconsistencies
Graphons
Implications for AI Alignment
Ambitious Value Learning
Ontological Crises
Discrete Case
Further Questions
Acknowledgements
None
5 comments
cross-posted from niplav.github.io
Epistemic Status
This is still a draft that I was told to already post here, which includes working (but very slow) code for one special case. Hopefully I'll be able to expand on this in the next ~half year.
Representing inconsistent preferences with specific mathematical structures can clarify thoughts about how to make those preferences consistent while only minimally changing them. This is discussed in the case of preferences over world states, represented by directed graphs; and preferences over lotteries of world states, represented either by infinitely dense graphs, (in some cases) vector fields over probability simplices, or edge-weighted directed graphs. I also present an algorithm for the discrete case based on the graph edit distance. Implications for scenarios such as ontological shifts are discussed.
Turning Some Inconsistent Preferences into Consistent Ones
A kind of God-made (or evolution-created) fairness between species is also unexpectedly found.
— Yew-Kwang Ng, “Towards Welfare Biology: Evolutionary Economics of Animal Consciousness and Suffering” p. 1, 1995
Random testing is simple in concept, often easy to implement, has been demonstrated to effectively detect failures, is good at exercising systems in unexpected ways (which may not occur to a human tester), and may be the only practical choice when the source code and the specifications are unavailable or incomplete.
— Tsong Yueh Chen/Fei-Ching Kuo/Robert G. Merkel/T.H. Tse, “Adaptive Random Testing: the ART of Test Case Diversity”, 2010
Consider an agent which displays (von Neumman-Morgenstern) inconsistent preferences, for example choosing two incompatible options in the two scenarios in the Allais paradox, or reliably displaying cycles in its actions (detecting which actions are in fact caused by inconsistent preferences, and not just exotic ones from weird abstractions, is considered a separate problem here). We might want to interact with that agent, e.g. trade with it, help it (or exploit it), or generally know how it will act But how to go about that if the agent displays inconsistent preferences? Perhaps it might even be the case that humans are such agents, and find ourselves in a conundrum: we know our preferences are inconsistent and reliably exploitable, and that agents with such preferences reliably fare worse in the world, we might want to change that.
A possible approach to this problem has two steps:
- Find ways to represent inconsistent preferences with a mathematical structure which can encode all possible violations of the von Neumann-Morgenstern axioms in all their combinations.
- Then turn those inconsistent preferences into consistent ones, and then inform the agent about these inconsistencies and their optimal resolutions (or, in the case of trying to help the agent, then enacting these preferences in the real world).
Mathematical Formulation of the Problem
Define a set of possible (von Neumann-Morgenstern) inconsistent preferences over a set of worlds as , and the set of consistent preferences over those worlds as . Elements from those sets are written as and .
One way we could approach the problem is by trying to turn those inconsistent preferences consistent, i.e. constructing a function that takes an inconsistent preference and transforms it into a consistent preference , while retaining as much of the original structure of the preference as possible (it would make little sense if we replaced the original preference relation with e.g. indifference over all options).
Formally, we want to find for some given distance metric a function so that
I call this function a turner, and sometimes call the results of that function the set of turnings (an element from that set is a turning). The names mostly chosen for not having been used yet in mathematics, as far as I know, and because I want to be a little extra.
A solution to the problem of turning inconsistent preferences into consistent ones then has these components:
- A mathematical structure for representing and
- Inconsistent preferences over discrete options are represented via directed graphs
- Inconsistent preferences over lotteries of options are represented via
- directed graphs over probability simplices
- potentially more exotic structures such as graphons or results from extremal graph theory might be relevant here, but I haven't investigated these in detail
- vector fields on probability simplices
- graphs with edge weights in
- directed graphs over probability simplices
- A specification for
- In the case of discrete options, I propose adding and removing edges from the directed graph
- In the case of lotteries I don't have yet any clear proposals
- A specification for
- In the case of discrete options, I propose using the graph edit distance
- In the case of lotteries I don't yet have any definite proposals
Related Work
This work is closely related to the investigations in Aird & Shovelain 2020 (so closely that even though I believe I re-invented the approach independently, it might just be that I had read their work & simply forgotten it), and broadly related to the value extrapolation framework outlined in Armstrong 2022.
Discrete Case
When we have discrete sets of worlds , we can represent an inconsistent preference over those worlds by using a directed graph . The presence of an edge would mean that , that is is preferred to .
Mathematically, then, is the set of all possible graphs with edges in , that is ).
The consistent equivalent to an inconsistent preference represented by a directed graph would be a path graph over the same set of vertices . The method for transforming into would be by adding/deleting the minimal number of vertices from .
Mathematically, then is the set of transitive closures of all possible path graphs that are encode permutations of ; .
Example
Consider the following directed graph:

Here, .
An edge from to means that is preferred to (short ). The absence of an edge between two options means that those two options are, from the view of the agent, incomparable.
It violates the two von Neumann-Morgenstern axioms for discrete options:
- Completeness is violated because for example options and are incomparable (and we don't merely have indifference between these options)
- Transitivity is violated because of the loop
A possible turned version of these preferences could then be the following graph:

This graph looks quite messy, but it's really just the transitive closure of this graph:

Whether this is the "right" way to turn the previous inconsistent preferences depends on the choice of distance metric we would like to use.
Resolving Inconsistencies
In some sense, we want to change the inconsistent preferences as little as possible; the more we modify them, the more displayed preferences we have to remove or change. Since the presence or absence of preferences is encoded by the presence or absence of edges on the graph, removing edges or adding new edges is equivalent to removing or adding preferences (at the moment, we do not consider adding or removing vertices: we stay firmly inside the agent's ontology/world model).
Luckily, there is a concept in computer science called the graph-edit distance: a measure for the difference between two graphs.
The set of possible editing operations on the graph varies, e.g. Wikipedia lists
- vertex insertion to introduce a single new labeled vertex to a graph.
- vertex deletion to remove a single (often disconnected) vertex from a graph.
- vertex substitution to change the label (or color) of a given vertex.
- edge insertion to introduce a new colored edge between a pair of vertices.
- edge deletion to remove a single edge between a pair of vertices.
- edge substitution to change the label (or color) of a given edge.
—English Wikipedia, “Graph Edit Distance”, 2021
Since we do not have labels on the edges of the graph, and have disallowed the deletion or insertion of vertices, this leaves us with the graph edit distance that uses edge insertion and edge deletion.
We can then write a simple pseudocode algorithm for :
turn(G≿=(W, E≿)):
mindist=∞
for L in perm(W):
L=trans_closure(L)
dist=ged(G≿, R)
if dist<mindist:
R=L
mindist=dist
return R
where perm(W) is the set of
permutations on W,
trans_closure(G) is the transitive closure of a graph G, and ged(G1, G2) is the graph edit distance from G1 to G2.
Or, mathematically,
Implementation
Implementing this in Python 3 using the networkx library turns out to be easy:
import math
import networkx as nx
import itertools as it
def turn(graph):
mindist=math.inf
worlds=list(graph.nodes)
for perm in it.permutations(worlds):
perm=list(perm)
pathgraph=nx.DiGraph()
for i in range(0, len(worlds)):
pathgraph.add_node(worlds[i], ind=i)
# The transitive closure over this particular path graph
# Simplify to nx.algorithms
for i in range(0, len(perm)-1):
pathgraph.add_edge(perm[i], perm[i+1])
pathgraph=nx.algorithms.dag.transitive_closure(pathgraph)
# Compute the graph edit distance, disabling node insertion/deletion/substition and edge substitution
edge_cost=lambda x: 1
unaffordable=lambda x: 10e10
same_node=lambda x, y: x['ind']==y['ind']
edge_matches=lambda x, y: True
dist=nx.algorithms.similarity.graph_edit_distance(graph, pathgraph, node_match=same_node, edge_match=edge_matches, node_del_cost=unaffordable, node_ins_cost=unaffordable, edge_ins_cost=edge_cost, edge_del_cost=edge_cost)
if dist<mindist:
result=pathgraph
mindist=dist
return result
We can then test the function, first with a graph with a known best completion, and then with our example from above.
The small example graph (top left) and its possible turnings are (all others):

>>> smallworld=['a', 'b', 'c']
>>> smallgraph=nx.DiGraph()
>>> for i in range(0, len(smallworld)):
... smallgraph.add_node(smallworld[i], ind=i)
>>> smallgraph.add_edges_from([('a', 'b')])
>>> smallre=turn(smallworld, smallgraph)
>>> smallre.nodes
NodeView(('a', 'b', 'c'))
>>> smallre.edges
OutEdgeView([('a', 'b'), ('a', 'c'), ('b', 'c')])
This looks pretty much correct.
>>> mediumworld=['a', 'b', 'c', 'd', 'e', 'f', 'g']
>>> mediumgraph=nx.DiGraph()
>>> for i in range(0, len(mediumworld)):
... mediumgraph.add_node(mediumworld[i], ind=i)
>>> mediumgraph.add_edges_from([('a', 'b'), ('b', 'c'), ('c', 'd'), ('c', 'e'), ('e', 'f'), ('f', 'g'), ('g', 'b')])
>>> mediumres=turn(mediumworld, mediumgraph)
>>> mediumres.nodes
NodeView(('a', 'b', 'c', 'd', 'e', 'f', 'g'))
>>> mediumres.edges
OutEdgeView([('a', 'b'), ('a', 'c'), ('a', 'd'), ('a', 'e'), ('a', 'f'), ('a', 'g'), ('b', 'c'), ('b', 'd'), ('b', 'e'), ('b', 'f'), ('b', 'g'), ('c', 'd'), ('c', 'e'), ('c', 'f'), ('c', 'g'), ('d', 'e'), ('d', 'f'), ('d', 'g'), ('e', 'f'), ('e', 'g'), ('f', 'g')])
This is actually equal to the hypothesized solution from above (below is the non-transitive-closure version):
Problems with This Method and its Algorithm
This solution has some glaring problems.
Speed (or the Lack Thereof)
Some of you might have noticed that this algorithm is somewhat inefficient (by which I mean absolutely infeasible).
Since we iterate through the permutations of , the runtime is (with the added "benefit" of additionally computing the NP-complete graph edit distance inside of the loop, which is also APX-hard to approximate).
Possible better approaches would involve finding the longest subgraph that is a path graph, or the spanning tree, perhaps the transitive reduction is helpful, or maybe the feedback arc set?
Non-Unique Results
Another, smaller problem is that the algorithm often doesn't have a unique result, as seen in the small example above.
We can compute the set of all possible turnings with some trivial changes to the algorithm:
turn_all(G≿=(W, E≿)):
mindist=∞
R=∅
[…]
if dist<mindist:
R={L}
mindist=dist
else if dist==mindist:
R=R∪{L}
return R
and its implementation
def turn_all(graph):
results=set()
[…]
if dist<mindist:
results=set([pathgraph])
mindist=dist
elif dist==mindist:
results.add(pathgraph)
return results
The results, with the small example, are as expected:
>>> turnings=list(turn_all(smallworld, smallgraph))
>>> len(turnings)
3
>>> turnings[0].edges
OutEdgeView([('a', 'b'), ('a', 'c'), ('b', 'c')])
>>> turnings[1].edges
OutEdgeView([('a', 'b'), ('c', 'a'), ('c', 'b')])
>>> turnings[2].edges
OutEdgeView([('a', 'c'), ('a', 'b'), ('c', 'b')])
For the big example, after waiting a while for the solution:
>>> turnings=list(turn_all(mediumworld, mediumgraph))
>>> len(turnings)
49
I will not list them all, but these are less than the possible options.
This brings up an interesting question: As we have more and more elaborate inconsistent preferences over more worlds, does it become more likely that they have a unique consistent preference they can be turned to? Or, in other words, if we make the graphs bigger and bigger, can we expect the fraction of inconsistent preferences with a unique turning to grow or shrink (strictly) monotonically? Or will it just oscillate around wildly?
More formally, if we define as the set of graphs with nodes, and as the set of graphs with nodes that have unique path graphs associated with them.
We can further define the set of all graphs wwith nodes with turnings as (of which is just a special case).
We can call the size of the set of all turnings of a graph the confusion of that graph/set of inconsistent preferences: If the graph is already the transitive closure of a path graph, the size of that set is (arguendo) 1: there are no other possible turnings. If the graph contains no edges (with nodes), the confusion is maximal with , the preferences carry the minimal amount of meaning.
Minimal and Maximal Number of Turnings
The minimal number of turnings a graph can have is 1, with a graph-edit distance of 0: any transitive closure of a path graph satisfies this criterion (if your preferences are already consistent, why change them to be more consistent?)
However, those graphs aren't the only graphs with exactly one turning, consider the following graph (left) and a possible turning (right) (with graph-edit distance 1; the changed edge is red, a nice opportunity for some rubrication):

One can easily see that it has exactly one turning, and checking with the code confirms:
>>> counter=nx.DiGraph()
>>> counterworld=['a', 'b', 'c', 'd']
>>> for i in range(0, len(smallworld)):
... smallgraph.add_node(smallworld[i], ind=i)
>>> counter.add_edges_from([('a', 'b'), ('b', 'c'), ('c', 'd'), ('a', 'c'), ('b', 'd'), ('d', 'a')])
>>> counterres=list(turn_all(counter))
>>> len(counterres)
>>> >>> counterres[0].edges
OutEdgeView([('a', 'b'), ('a', 'c'), ('a', 'd'), ('b', 'c'), ('b', 'd'), ('c', 'd')])
For a graph with nodes the maximal number of turnings it is upper-bounded by , and a sufficient condition for the graph to have that many turnings is when the graph is the union of a set of complete digraphs with disjoint nodes. For example the graph with 4 nodes and no edges has 24 possible turnings, as does the graph with 4 nodes and two edges .
We can prove this inductively: When considering a node-labeled graph with nodes and no edges, the graph edit distance to any path graph variant of that graph is the same, because we always have to add edges to reach any transitive closure of a path graph (by the sum of any arithmetic progression). Let not be a graph with nodes that is solely the union of complete digraphs with disjoint nodes. When we now pick two nodes and from and add the edges (that is, we connect and , and all their neighbors) to , we have necessarily increased the graph-edit distance to any path graph by the same amount, we have symmetrically added edge-pairs that need to be broken in either direction.
Questions
One can now pose several (possibly distracting) questions:
- Does it matter whether we give
turna graph or the transitive closure of ? - Is there a more efficient algorithm to compute the turning?
- Can it at least be made exponential?
- Can we exploit the fact that we're always computing the graph-edit distance to a path-graph?
- As we add more options to our inconsistent preferences, do they become more likely to turn uninuely?
- That is: Does it hold that ?
- It should be possible to check this for small cases.
Number of Turnings for
- In general, how does the size of develop? What about , or in general ?
- Does the average number of turnings for inconsistent preferences converge to a specific number?
- That is, what is ?
- I predict 20% on the number monotonically increasing, 50% on monotonically decreasing and 30% on showing no clear pattern.
We can check these empirically! While it would be nice to prove anything about them, it's much nicer to investigate them computationally. This is pretty straightforward: For increasing , generate , for every , compute , save the data in a file somewhere, and do interesting things with that data.
In code, we first generate all directed graphs with nodes with a recursive function
def all_directed_graphs(n):
if n<=0:
return [nx.DiGraph()]
graphs=all_directed_graphs(n-1)
newgraphs=[]
for g in graphs:
g.add_node(n, ind=n)
for tosubset in powerset(range(1, n+1)):
for fromsubset in powerset(range(1, n)):
gnew=g.copy()
for element in tosubset:
gnew.add_edge(n, element)
for element in fromsubset:
gnew.add_edge(element, n)
newgraphs.append(gnew)
return newgraphs
and start turning:
max=16
for i in range(0,max):
graphs=turn.all_directed_graphs(i)
for g in graphs:
print('{0},{1},"{2}"'.format(i, len(turn.turn_all(g)), g.edges))
However, my computer quickly freezes and I find out that this is a lot of graphs:
>>> [len(list(all_directed_graphs(i))) for i in range(0,5)]
[1, 2, 16, 512, 65536]
So the number directed graphs with 5 nodes would be
, far too many for my puny laptop. But
instead of generating them all, one can just generate a
random sample and test on that, using the Erdős–Rényi
model,
for which networkx has the helpful function
generators.random_graphs.gnp_random_graph (Wikipedia informs us that
"In particular, the case corresponds to the case
where all graphs on vertices are chosen
with equal probability."). We have to randomly add reflexive edges (not
included in the model, it seems) with probability each,
and labels for the nodes, and then we're good to go:
samples=256
for i in range(5,lim):
for j in range(0,samples):
g=nx.generators.random_graphs.gnp_random_graph(i, 0.5, directed=True)
for n in g.nodes:
g.add_node(n, ind=n)
if random.random()>=0.5:
g.add_edge(n,n)
print('{0},{1},"{2}"'.format(i, len(turn.turn_all(g)), g.edges))
We now run the script in the background, happily collecting data for us
(python3 collect.py >.https://niplav.github.io/../data/turnings.csv &), and after a nice
round of editing this text go back and try to make sense of the data,
which runs squarely counter my expectations:
>>> import pandas as pd
>>> df=pd.read_csv('data/turnings.csv')
>>> df.groupby(['0']).mean()
1
0
1 1.000000
2 1.875000
3 3.941406
4 9.390289
5 21.152344
6 39.885246
It seems like the mean number of turnings actually increases with the graph size! Surprising. I'm also interested in the exact numbers: Why exactly 3.390289… for the graphs with 4 nodes? What is so special about that number‽ (Except it being the longitude of the Cathedral Church of Christ in Lagos).
Looking at unique turnings turns (hehe) up further questions:
>>> def uniqueratio(g):
... return len(g.loc[g['1']==1])/len(g)
...
>>> df.groupby(['0']).apply(uniqueratio)
0
1 1.000000
2 0.125000
3 0.089844
4 0.055542
5 0.050781
6 0.016393
dtype: float64
>>> def uniques(g):
... return len(g.loc[g['1']==1])
>>> df.groupby(['0']).apply(uniques)
0
1 2
2 2
3 46
4 3640
Very much to my surprise, searching for "2,2,46,3640" in the OEIS yields no results, even though the sequence really looks like something that would already exist! (I think it has a specifically graph-theoretic "feel" to it). But apparently not so, I will submit it soon.
I omit the number of unique turnings for 5 and 6, for obvious reasons (I also believe that the ratio for 6 is an outlier and should not be counted). The number of unique resolutions for the graph with 1 node makes sense, though: Removing the reflexive edge should count as one edge action, but the graph only has one unique resolution:
>>> df.loc[df['0']==1]
0 1 []
0 1 1 []
1 1 1 [(1, 1)]
Encoding Inconsistencies
Theory
Assuming that we have a set of axioms that describe which preferences are consistent and which are inconsistent, for the purposes of this text, we want to ideally find a set of mathematical structures that
- can represent preferences that violate each possible subset of those axioms.
- Each inconsistent preference should have exactly one element of that represents it
- has a strict subset so that can represent only consistent preferences.
Discrete Case
The two relevant von Neumman-Morgenstern axioms are completeness and transitivity, with a directed graph one can also represent incompleteness and intransitivity.
Incompleteness
Incompleteness (or incomparability) between two options can be represented by not specifying an edge between the two options, that is .
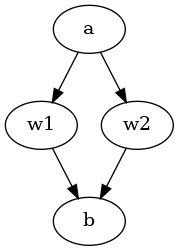
Intransitivity
Intransitivity can be represented by cycles in the graph:
![]()
Non-Encodable Inconsistencies
With option set have preference , with option set have preferences .
Continuous Case
Incompleteness
- Minima/maxima in the vector field
- Discontinuities
- Undifferentiable points
Intransitivity
Curl in the vector field?
Discontinuity
Can only exist with incompleteness?
Dependence
Discussion
This leads to an interesting ethical consideration: is it a larger change to a preference relation to add new information or remove information?
It is discussed how to incorporate those weights into an algorithm for minimally transforming into .
Continuous Case
Vector Fields over Probability Simplices
Vector field over the probability simplex over the options (representing local preferences over lotteries).
Resolving Inconsistencies
Find mapping from vector field to another that makes the vector field consistent by minimizing the amount of turning/shrinking the vectors have to perform.
Graphons
?
Look into extremal graph theory.
Implications for AI Alignment
I've seen six cities fall for this
mathematics with incompetence
red flags stand among the trees
repugnant symphonies
a billionaires tarantula just ate the ceiling
thinking it was yet another floor
—Patricia Taxxon, “Hellbulb” from “Gelb”, 2020
Ambitious Value Learning
Learn human values, check if known inconsistencies are encoded (to ensure learning at the correct level of abstraction), then make consistent.
Ontological Crises
Furthermore, there remain difficult philosophical problems. We have made a distinction between the agent’s uncertainty about which model is correct and the agent’s uncertainty about which state the world is in within the model. We may wish to eliminate this distinction; we could specify a single model, but only give utilities for some states of the model. We would then like the agent to generalize this utility function to the entire state space of the model.
—Peter de Blanc, “Ontological Crises in Artificial Agents’ Value Systems”, 2010
If you know a mapping between objects from human to AI ontology, you could find the mapping from the (consistent) human probability simplex to the AI simplex?
Discrete Case
A node splits in two or more, or two or more nodes get merged. If the then resulting graph isn't a path graph, it can be turned with the method described above.
Further Questions
- Does every graph have a unique graph so that is the transitive closure of ?
- There is something interesting going on with lattices (?) over individual transitivity operations
Acknowledgements
Thanks to Miranda Dixon-Luinenburg for finding some typos.
5 comments
Comments sorted by top scores.
comment by MikkW (mikkel-wilson) · 2022-06-07T17:15:00.270Z · LW(p) · GW(p)
The first paragraph after the heading "Mathematical Formulation of the Problem" is hard for me to parse, and I cannot rule out that it contains (at least) a typo.
Replies from: niplav, niplavcomment by Charlie Steiner · 2022-07-20T08:17:06.928Z · LW(p) · GW(p)
Yes, but also, resolutions of human preference conflicts should eventually be done with some input from human meta-preferences, not solely in the simplest way.
Replies from: niplav