Reinforcement Learning: A Non-Standard Introduction (Part 1)
post by royf · 2012-07-29T00:13:38.238Z · LW · GW · Legacy · 19 commentsContents
19 comments
Imagine that the world is divided into two parts: one we shall call the agent and the rest - its environment. Imagine you could describe in full detail the state of both the agent and the environment. The state of the agent is denoted M: it could be a Mind if you're a philosopher, a Machine if you're researching machine learning, or a Monkey if you're a neuroscientist. Anyway, it's just the Memory of the agent. The state of the rest of the World (or just World, for short) is denoted W.
These states change over time. In general, when describing the dynamics of a system, we specify how each state is determined by the previous states. So we have probability distributions for the states Wt and Mt of the world and the agent in time t:
p(Wt|Wt-1,Mt-1)
q(Mt|Wt-1,Mt-1)
This gives us the probabilities that the world is currently in state Wt, and the agent in state Mt, given that they previously were in states Wt-1 and Mt-1. This can be illustrated in the following Bayesian network (see also):
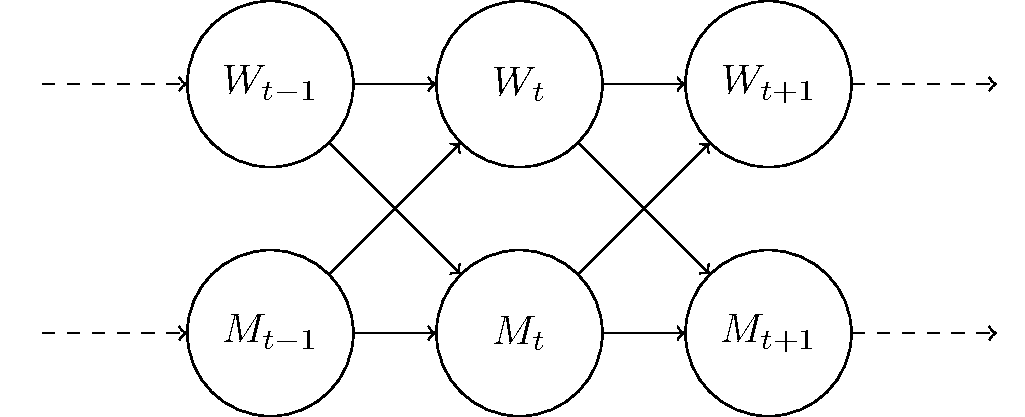
Bayesian networks look like they represent causation: that the current state is "caused" by the immediately previous state. But what they really represent is statistical independence: that the current joint state (Wt, Mt) depends only on the immediately previous joint state (Wt-1, Mt-1), and not on any earlier state. So the power of Bayesian networks is in what they don't show, in this case there's no arrow from, say, Wt-2 to Wt.
The current joint state of the world and the agent represents everything we need to know in order to continue the dynamics forward. Given this state, the past is independent of the future. This property is so important, that it has a name, borrowed from one of its earliest researchers, Markov.
The Markov property is not enough for our purposes. We are going to make a further assumption, which is that the states of the world and the agent don't both change together. Rather, they take turns changing, and while one does the other remains the same. This gives us the dynamics:
p(Wt|Wt-1,Mt-1)
q(Mt|Mt-1,Wt)
and the Bayesian network:
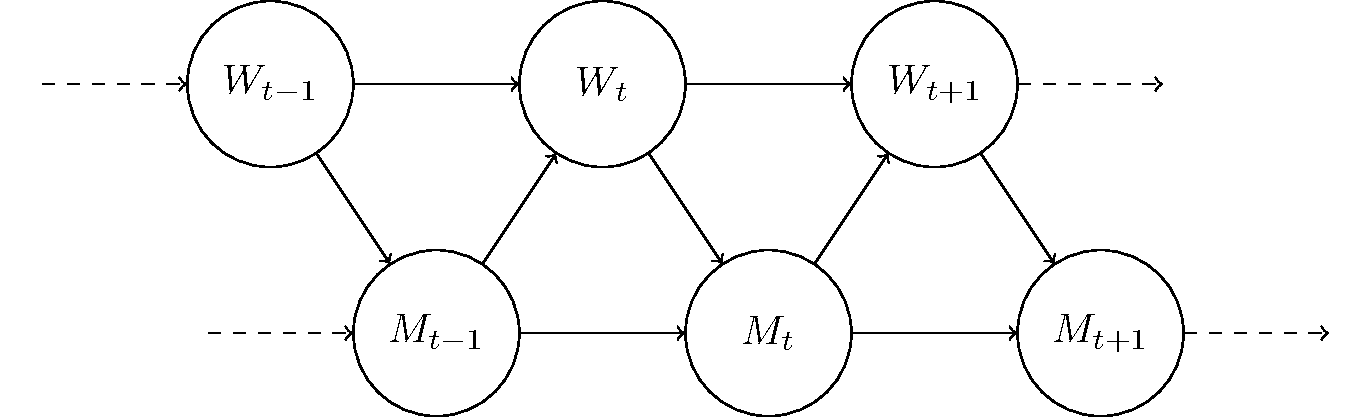
Sometimes this assumption can be readily justified. For example, let's use this model to describe a chess player.
Suppose that at time t the game has reached state Wt where it is our agent's turn to play. Our agent has also reached a decision of what to do next, and its mind is now in state Mt, including memory, plan, general knowledge of chess, and all.
Our agent takes its turn, and then enters stasis: we are going to assume that it's not thinking off-turn. This is true of most existing artificial chess players, and disregarding time constraints their play is not worse off for it. They are not missing out on anything other than time to think. So the agent keeps its state until the opponent has taken its turn. This completes the change of the state of the game from Wt to Wt+1.
Now the agent takes a look at the board, and starts thinking up a new strategy to counter the last move of the opponent. If reaches a decision, and commits to its next action. This completes the change of the agent's state from Mt to Mt+1.
Chess is a turn-based game. But even in other scenarios, when such division of the dynamics into turns is not a good approximation of the process, our assumption can still be justified. If the length of each time step is taken to be smaller and smaller, the state of each of the parties remains more and more the same during each step, with increasing probability and accuracy. In the limit where we describe a continuous change of state over time, the turn-based assumption disappears, and we are back to the general model.
This is the first part of an intuitive and highly non-standard introduction to reinforcement learning. This is more typical of what neuroscientists mean when they use the term. We, on the other hand, will get closer as we move forward to its meaning in machine learning (but not too close).
In following posts we will continue to assume the Markov property in its turn-based variant. We will describe the model in further detail and explore its decision-making aspect.
Continue reading: Part 2
19 comments
Comments sorted by top scores.
comment by A1987dM (army1987) · 2012-07-30T10:01:32.452Z · LW(p) · GW(p)
While I generally don't like excessively long posts, I can't see why you split this one: this first part just introduces a model without using it for anything.
Replies from: royf↑ comment by royf · 2012-07-30T14:51:00.056Z · LW(p) · GW(p)
I internally debated this question myself. Ideally, I'd completely agree with you. But I needed the shorter publishing and feedback cycle for a number of reasons. Sorry, but a longer one may not have happened at all.
Edit: future readers will have the benefit of a link to part 2
comment by duwease · 2012-08-02T16:52:06.332Z · LW(p) · GW(p)
I'm having a hard time understanding what the arrows from W-node to W-node and M-node to M-node represent in the chess example, given the premise that the world and memory states take turns changing.
If I understand correctly, W is the board state at the start of the player's turn, and M is the state of the memory containing the model of the board and possible moves/outcomes. W(t) is the state that precedes M(t), and likewise the action resulting from the completion of remodelling the memory at M(t), plus the opposing player's action, results in new world state W(t+1).
This interpretation seems to suggest a simple, linear, linked list of alternating W and M nodes instead of the idea that, for example, the W(t-1) node is the direct precursor to W(t). The reason being, it seems that one could generate W(t) simply from the memory model in M(t-1), regardless of what W(t-1) was.. and the same goes for M(t) and W(t-1).
Perhaps it's that the arrow from one W-node to another does not represent the causal/precursor relationship that a W-node to M-node arrow represents, but a different relationship? If so, what is that relationship? Sorry if this seems picky, but I do think that the model is causing some confusion as to whether I properly understand your point.
Replies from: Johnicholas↑ comment by Johnicholas · 2012-08-02T18:09:50.065Z · LW(p) · GW(p)
The arrows all mean the same thing, which is roughly 'causes'.
Chess is a perfect-information game, so you could build the board entirely from the player's memory of the board, but in general, the state of the world at time t-1, together with the player, causes the state of the world at time t.
Replies from: duwease↑ comment by duwease · 2012-08-02T18:34:47.825Z · LW(p) · GW(p)
Ah, so what we're really talking about here is situations where the world state keeps changing as the memory builds its model.. or even just a situation where the memory has an incomplete subset of the world information. Reading the second article's example, which makes the limitations of the memory explicit, I understand. I'd say the chess example is a bit misleading in this case, as the discrepancies between the memory and world are a big part of the discussion -- and as you said, chess is a perfect-information game.
comment by JohnEPaton · 2012-07-30T03:07:49.190Z · LW(p) · GW(p)
I'm just wondering whether it's true that the Markov property holds for minds. I'm thinking that a snapshot of the world is not enough, but you also need to know something about the rate at which the world is changing. Presumably this information would require the knowledge of states further back.
Also, isn't there an innate element of randomness when it comes to decision making and how our minds work. Neurons are so small that presumably there are some sort of quantum effects, and wouldn't this mean again that information from one step previous wasn't enough.
I don't know, but just some thoughts.
Replies from: harshhpareek, royf↑ comment by harshhpareek · 2012-08-03T19:49:52.789Z · LW(p) · GW(p)
(Assuming Mind=Brain, i.e. the entire mind is just the physical brain and no "soul" is involved. Also, Neurons aren't really all that small, they're quite macroscopic -- though the processes in the neurons like chemical interactions need quantum mechanics for their description)
In Newtonian Mechanics, it is sufficient to know the positions and velocities (i.e. derivaties of position) of particles to determine future states. So, the world is Markov given this informatio.
In Schrodinger's equation, you again only need to know \Psi and it's time derivative to know all future states. I think the quantum properties of the brain are adequately described just with Schodinger's equation. You do need to include nuclear forces etc in a description of the brain. You may need quantum electrodynamics, but I think Schrodinger's equation is sufficient.
My physics education stopped before I got here, but Dirac's equation which may be necessary to model the brain seems to require the second time-derivative of the wavefunction -- so you may need the second order time-derivatives to make the model Markov. Can someone who knows a bit more quantum physics chime in here?
EDIT: Reading the wiki article more carefully, it seems Dirac's equation is also first order
↑ comment by royf · 2012-07-30T06:28:33.134Z · LW(p) · GW(p)
In the model there's the distribution p, which determines how the world is changing. In the chess example this would include: a) how the agent's action changes the state of the game + b) some distribution we assume (but which we may or may not actually know) about the opponent's action and the resulting state of the game. In a physics example, p should include the relevant laws of physics, together with constants which tell the rate (and manner) in which the world is changing. Any changing parameters should be part of the state.
It seems that you're saying that it may be difficult to know what p is. Then you are very much correct. You probably couldn't infer the laws of physics from the current wave function of the universe, or the rules of chess from the current state of the game. But at this point we're only assuming that such laws exist, not that we know how to learn them.
p and q are probability distributions, which is where we allow for randomness in the process. But note that randomness becomes a tricky concept if you go deep enough into physics.
As for the "quantum mind" theory, as far as I can tell it's fringe science at best. Personally, I'm very skeptical. Regardless, such a model can still have the Markov property, if you include the wave function in your state.
comment by fubarobfusco · 2012-07-28T22:29:05.453Z · LW(p) · GW(p)
The text of this post seems to be double-spaced (CSS line-height: 26px, versus 17px in most posts). Please fix.
Replies from: royf↑ comment by royf · 2012-07-28T22:31:52.667Z · LW(p) · GW(p)
I'm not sure what you mean. It looks fine to me, and I can't find where to check / change such a setting.
Edit:
Very strange. Fixed, I hope.
Thanks!
Replies from: fubarobfusco↑ comment by fubarobfusco · 2012-07-28T22:38:35.911Z · LW(p) · GW(p)
Indeed ... looks normal now. When I posted the above, the "computed style" in Chrome's developer tools showed 26px and the lines were widely spaced. Now it shows 17px as with other posts. Funky.
Replies from: royf↑ comment by royf · 2012-07-28T22:40:57.498Z · LW(p) · GW(p)
And how do you strikeout your comment?
Replies from: fubarobfusco↑ comment by fubarobfusco · 2012-07-28T22:42:01.652Z · LW(p) · GW(p)
That's the "retract" button.
Replies from: royf↑ comment by royf · 2012-07-28T22:52:03.450Z · LW(p) · GW(p)
There's supposed to be some way to do so partially, if anyone knows what it is.
This should work in Markdown, but it seems broken :(
Edit: t̶e̶s̶t̶ Thanks, Vincent, it works!
Replies from: VincentYu↑ comment by VincentYu · 2012-07-29T00:25:52.951Z · LW(p) · GW(p)
I never found a way to do it using LW's implementation of Markdown, but I have successfully used this Unicode strikethrough tool before (a̶n̶ ̶e̶x̶a̶m̶p̶l̶e̶).
Replies from: Sniffnoy↑ comment by Sniffnoy · 2012-07-29T13:47:36.614Z · LW(p) · GW(p)
Note that this makes the struck-through text very difficult to search.
Replies from: robert-miles↑ comment by Robert Miles (robert-miles) · 2012-07-30T15:55:44.818Z · LW(p) · GW(p)
If LW's markdown is like reddit's, double tilde before and after will strike through text. Let's see if that works
Edit: It doesn't. Does anyone know how I would go about fixing this?
Edit2: The issue tracker suggests it's been fixed, but it doesn't seem to be.
Replies from: arundelo, TheOtherDave↑ comment by TheOtherDave · 2012-07-30T16:39:38.268Z · LW(p) · GW(p)
--test--