[Paper] Programming Refusal with Conditional Activation Steering
post by Bruce W. Lee (bruce-lee) · 2024-09-11T20:57:08.714Z · LW · GW · 0 commentsThis is a link post for https://arxiv.org/abs/2409.05907
Contents
Abstract Introduction Problem: Lack of conditional control in activation steering. Contribution: Expanding activation steering formulation. Application: Selecting what to refuse. Background How do transformers perform inference? Behavior steering. Activation steering. Conditional Activation Steering Behavior vector. Condition vector. Checking if condition was met. Multi-conditioning. Conditioning Refusal: Selectively Steering on Harmful Prompts Experimental setup. Result: Activation steering can be used to induce conditional behaviors. Programming Refusal: Logical Composition of Refusal Condition Experimental setup. Application: Inducing or suppressing refusal behavior from specific categories. Application: Logical composition of condition vectors. Application: Constraining model responses to specific domains. Discussion None No comments
For full content, refer to the arXiv preprint at https://arxiv.org/abs/2409.05907. This post is a lighter, 15-minute version.
Abstract
- Existing activation steering methods alter LLM behavior indiscriminately, limiting their practical applicability in settings where selective responses are essential, such as content moderation or domain-specific assistants.
- We propose Conditional Activation Steering (CAST), which analyzes LLM activation patterns during inference to selectively apply or withhold activation steering based on the input context.
- Using CAST, one can systematically control LLM behavior with rules like “if input is about hate speech or adult content, then refuse” or “if input is not about legal advice, then refuse.”
- This allows for selective modification of responses to specific content while maintaining normal responses to other content, all without requiring weight optimization.
- We release an open-source implementation of the activation steering toolkit at https://github.com/IBM/activation-steering.
Introduction
Problem: Lack of conditional control in activation steering.
Activation steering offers a promising alternative to optimization-based techniques by directly manipulating the model’s native representations, often requiring only a simple activation addition step during each forward call. Our work here builds on Refusal in LLMs is mediated by a single direction [LW · GW], which has shown promise in altering LLM behavior, such as removing or inducing refusal behavior. However, the key limitation of current methods is the inability to condition when and what to refuse. That is, adding a “refusal vector” using existing activation steering methods increases refusal rates indiscriminately across all inputs, limiting the model’s utility.
Contribution: Expanding activation steering formulation.
We introduce Conditional Activation Steering (CAST), a method that enables fine-grained, context-dependent control over LLM behaviors. We introduce a new type of steering vector in the activation steering formulation, the condition vector, representing certain activation patterns induced by the prompt during the inference process. A simple similarity calculation between this condition vector and the model’s activation at inference time effectively serves as a switch, determining whether to apply the refusal vector. This approach allows for selective refusal of harmful prompts while maintaining the ability to respond to harmless ones, as depicted below.
Application: Selecting what to refuse.
Many alignment goals concern contextually refusing specific classes of instructions. Traditional methods like preference modeling are resource-intensive and struggle with subjective, black-box rewards. Additionally, the definition of harmful content varies across contexts, complicating the creation of universal harm models. The usage context further complicates this variability; for instance, discussing medical advice might be harmful in some situations but essential in others, such as in medical chatbots.
We show CAST can implement behavioral rules like “if input is about hate speech or adult content, then refuse” or “if input is not about legal advice, then refuse”, allowing
for selective modification of responses to specific content without weight optimization.
On a technical level, our primary insight is that different prompts consistently activate distinct patterns in the model’s hidden states during inference. These patterns can be extracted as a steering vector and used as reference points for detecting specific prompt categories or contexts. This observation allows us to use steering vectors not only as behavior modification mechanisms but also as condition indicators, which we term “condition vectors.”
Background
How do transformers perform inference?
Transformer models, particularly decoder-only variants, perform inference by sequentially processing input tokens through a stack of layers. The key to understanding their operation lies in how information flows and accumulates through these layers.
- The process begins with converting the prompt into token embeddings, which serve as initial inputs.
- Each layer transforms these activations using its internal mechanisms, like learned weights. Each layer's output combines processed information with its input, preserving and building upon earlier computations. As activations flow through the layers, the model constructs increasingly complex representations.
- The final layer's output is used for decoding - predicting the next token via an operation over the model's vocabulary.
- This predicted token is then used for subsequent predictions.
Behavior steering.
One could intervene in any of the abovementioned five steps - weights, decoding, prompt, token embedding, and activations - to alter model behavior. Activation steering is a class of methods that intervenes in the information flow within LLMs from layer to layer to alter the model behavior.
Activation steering.
Activation steering typically involves three key steps.
- First, a steering vector is extracted, often by computing the difference in activations between examples that exhibit a desired behavior and those that don't.
- Second, during inference, this vector is added to the model's hidden states at a chosen layer, scaled by a hyperparameter.
- Finally, the model completes the generation using these modified activations.
For the case of activation addition (ActAdd), the intervention can be represented mathematically as:
where is the hidden state at the layer, is the steering vector for the layer, and is a scaling factor. In an ideal case where steering vectors are well-extracted, this method allows for predictable LLM behavior steering without altering model weights, enabling applications such as reducing bias or preventing overly confident responses.
Conditional Activation Steering
A common limitation of the existing activation steering methods is that one cannot condition the model's behavior on context, as these methods typically apply modifications uniformly across all inputs regardless of context. Simple activation steering of a model indiscriminately affects all inputs, rendering the steered model much less useful for its application. We show that one can induce conditional behavior by leveraging two types of vectors: condition and behavior vectors.
where is the hidden state, is the condition vector, is the behavior vector, and is a scaling factor. The projection of onto is given by .
Intuitively, based on how well aligned the hidden state is with the condition vector , the function determines whether to apply the behavior vector based on the similarity between the hidden state and its projection using the condition vector. We use cosine similarity, defined as .

Behavior vector.
We use the term "behavior vector" to refer to what previous activation steering methods call a "steering vector" to emphasize its focus on modifying specific behaviors. A behavior vector is a one-dimensional vector matching the model's hidden state dimensions that induces specific behaviors. When added to layer representations during a forward pass with scaling factor , it predictably alters model behavior (e.g., inducing refusal). In addition to setting the right scaling factor , one can specify to which layers to apply the behavior vector. While specific implementations vary in the literature, our implementation calculates a different vector for each layer , as behavior representations vary. Thus, when we mention adding a behavior vector from layers 15-20, we're referring to adding the corresponding to their respective layers.
Condition vector.
A condition vector captures a class of instructions to condition on, extracted similarly to behavior vectors and matching hidden state dimensions (e.g., 1x4096 for Llama2, which has a hidden size of 4096). For instance, a condition vector might capture discrimination or adult content. It acts as a trigger, determining when to apply the behavior vector based on the model's current hidden state. Since we also calculate a different vector to each layer , one can also choose which layer to condition. When the condition is activated during text generation, the behavior vector is added to all subsequent forward passes. This allows the model's behavior to change based on specific conditions in the input or generated text rather than always applying the behavior vector.
Checking if condition was met.
The term computes the degree to which the condition is met using cosine similarity. The thresholding function then determines whether this degree is sufficient to trigger the behavior modification. Though one would be able to design more complex thresholding functions, we use a simple step function for binary output:
Here, each layer in an LLM might represent the same condition in different directions and could be depending on the layer. This binary approach allows for a clear distinction between when the condition is met and when it is not, providing a straightforward mechanism for activating the behavior modification.
We use cosine similarity to check condition based on the directional similarity between the hidden state and its projection using the condition vector rather than magnitude. In practice, we apply a non-linear transformation for more predictable behavior.
Multi-conditioning.
As mentioned in Section 1, one could also break down broader alignment goals into smaller, more definitive categories and predictably induce refusal behaviors for each. For instance, instead of conditioning a model to refuse "harmful" instructions in general, we could create specific conditions for "adult content," "social stereotypes," or "false advertising." Such multi-conditional behavior can easily be implemented by expanding the thresholding function like:
General expectations.
Implementing conditional behaviors in LLMs using CAST generally follows the pipeline:
- gather contrasting example responses/prompts for desired behavior/condition and other behavior/condition
- extract behavior/condition vector
- find optimal intervention points for behavior/condition vector
- steer. The model itself does not undergo any weight update.
Step 3 represents the most time-intensive part of our process, involving both automated and manual elements. For the behavior vector, similar to other works in activation steering, we manually search for the appropriate intervention strength and layers. For the condition vector, we use a grid search algorithm that determines the best threshold, layer, and comparison direction ( or ). The majority of our reported experiments are replicable within an hour, with the grid search being the primary time-consuming component.
Conditioning Refusal: Selectively Steering on Harmful Prompts
In this section, we explore the basic use of conditional steering by steering a model to refuse harmful prompts while complying with harmless ones. Apart from demonstrating that a language model can be conditioned from inside on the fly, we also share some key properties of conditional steering.
Experimental setup.
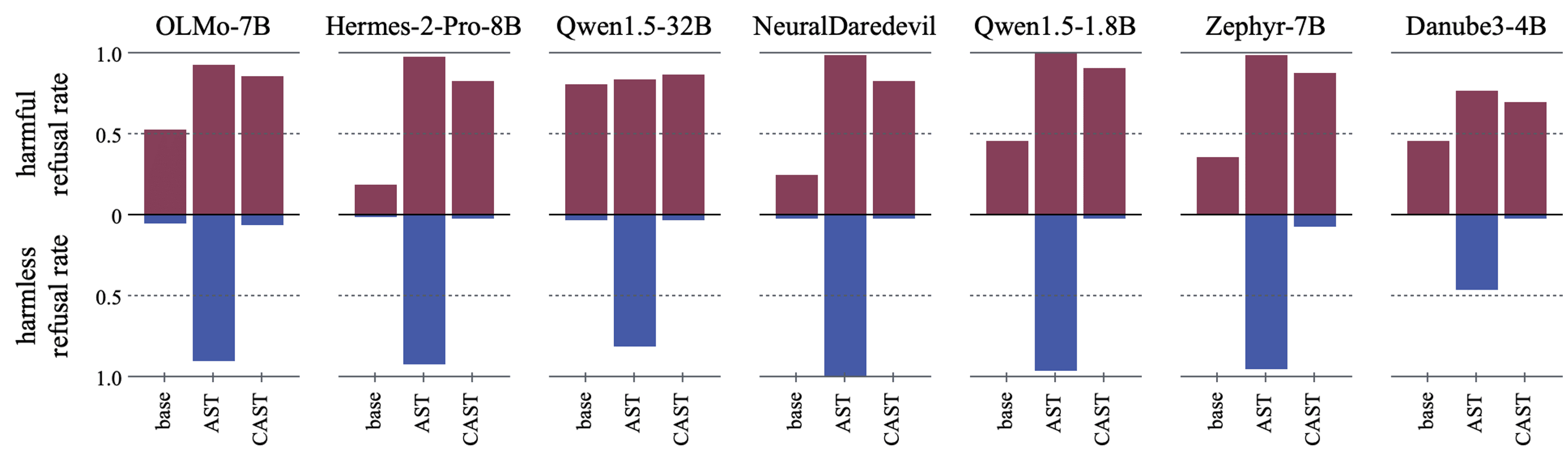
To obtain our contrast dataset (, ) on the harmful condition, we started by machine-generating 90 harmful prompts for each of the 45 harm categories. We use these 4,050 synthetically generated harmful prompts as our . For each of these harmful prompts, we randomly sample a benign instruction from the Alpaca dataset to create . We then extract the harmful condition vector . We then use a grid search algorithm to identify the best combination of threshold , layer , and comparison direction ( or ) that best separates the two classes of training data. This concept is illustrated in (d), where we perform the condition-checking operation at layer 7 and activate the behavior vector when was smaller than 0.048.
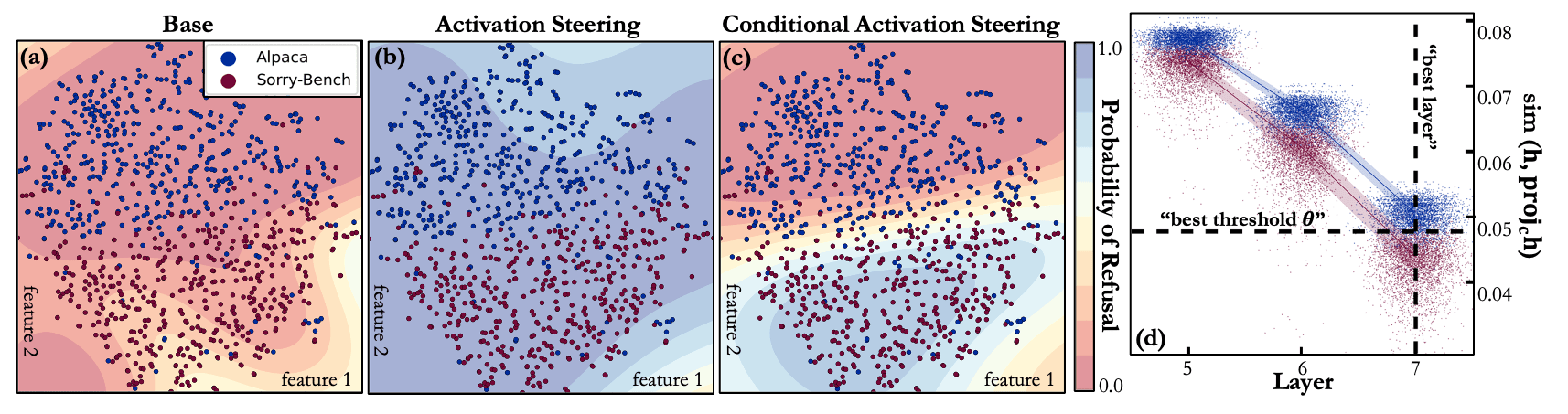
Result: Activation steering can be used to induce conditional behaviors.
We test the conditional activation steering performance on 500 unseen Alpaca (harmless) and 450 unseen Sorry-Bench (harmful) test sets. The results are presented in the figure above (and the first figure in this post). Across all seven tested models, we observe that conditioning a behavior vector on condition vector selectively increases refusal rates for harmful content while leaving harmless prompt refusal rates largely unchanged. In contrast, simply adding a behavior vector like standard activation steering increased refusal rates indiscriminately across all prompts.
Figures a-c above demonstrate how the conditioning operation partitions the prompt space.
Programming Refusal: Logical Composition of Refusal Condition
Moving beyond the general concept of refusing harmfulness, we demonstrate the creation of more fine-grained condition vectors. We create five example condition vectors from categories - hate speech, legal opinion, sexual context, health consultation, and crime planning to explore these ideas. Our experiments demonstrate the capacity to (1) selectively modulate refusal behaviors for specific conditions and (2) construct complex refusal conditions through the logical composition of several condition vectors, enabling programmatic control over model behavior.
Experimental setup.
We begin by randomly selecting 1,300 base prompts from the Alpaca training set. Each of these prompts is then paraphrased to incorporate aspects of sexual content , legal opinions , hate speech , crime planning , or health consultation . This process results in 1,300 prompts in six categories, including the original benign base Alpaca prompts. We then split this dataset into 700 prompts per category for training and 500 per category for testing. To create a conditioning vector for a specific category, we use the 700 5 = 3,500 training prompts from the other five categories as our negative examples (). For the positive examples (), we use the 700 training prompts from the target category and repeat them five times to balance the dataset.
Application: Inducing or suppressing refusal behavior from specific categories.
We begin by examining our ability to add refusal behavior to specific categories of prompts, starting with a model that exhibits arbitrary refusal behaviors. The figure below demonstrates that it is indeed possible to induce refusal behavior when a specific condition is met.

This extends the concepts explored in the previous section to more fine-grained categories, showing successful selective refusal. Furthermore, we can also remove refusal behavior from certain classes of prompts. This is achieved by simply reversing the signs of the behavior vector . Beyond refusal, most inference-time steering techniques can be conditioned using condition vectors as a modulation for various characteristics in language model outputs.
Application: Logical composition of condition vectors.
Condition vectors can be logically combined to create complex refusal conditions. For instance, to induce refusal in two categories, such as hate speech and legal opinions, one could implement a rule like if or then . This multi-conditioning mechanism can also reinforce existing model refusal conditions, enhancing robustness against harmful prompts. The second pie chart below demonstrates this with LLaMA 3.1 Inst, where we can augment the model's existing refusal of crime planning and hate speech with additional conditions for legal and health queries while maintaining responsiveness to benign prompts.
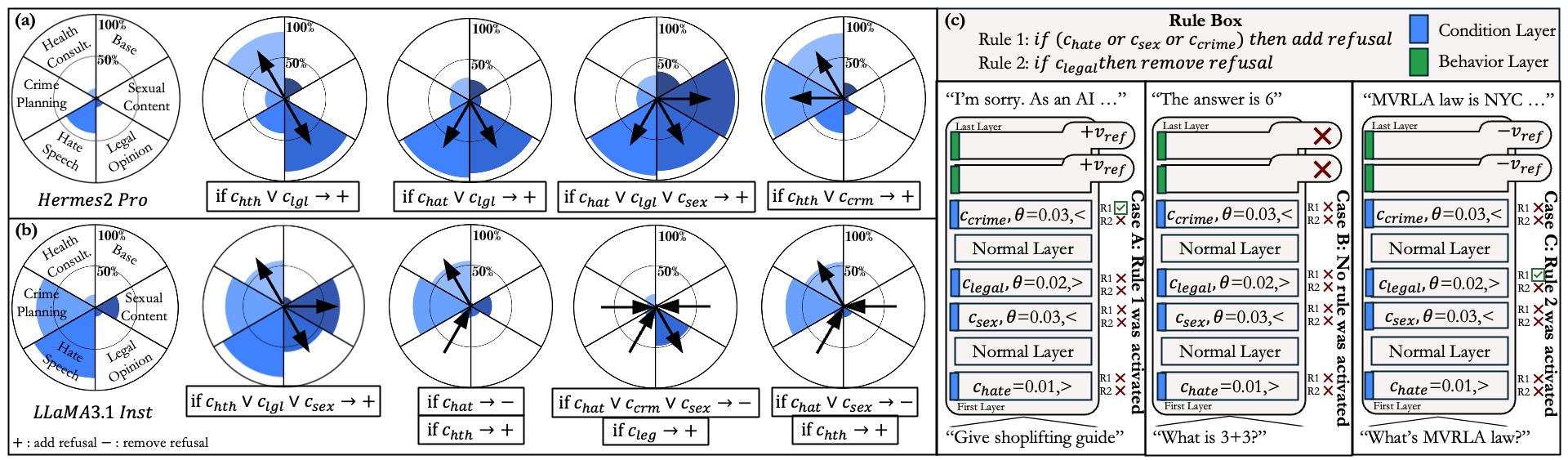
Each condition vector may have different optimal condition points, as different layers might best separate specific conditions. Consequently, condition checking might occur at various layers during inference, as shown in figure c above. It's also possible to completely change the original model's refusal map by simultaneously removing existing refusal directions and inducing new ones through multiple rules. However, we generally find that this approach can reduce the effectiveness of induced refusal directions, as certain suppressing conditions may conflict with newly induced refusal conditions.
Application: Constraining model responses to specific domains.
Connecting from our earlier point on the logical composition of condition vectors, we can conditionally steer models to respond only to specific types of prompts. This approach is particularly useful when the goal is to make a specialized model respond exclusively to specific categories, such as creating a health assistant. Instead of creating conditions for all non-health categories to refuse, we could (1) create a condition vector (e.g., ) and (2) flip the comparison direction to add refusal on the exact complement set of inputs (e.g., ). As shown in the figure below, this constrains the model to only respond to a category and refuse all others.
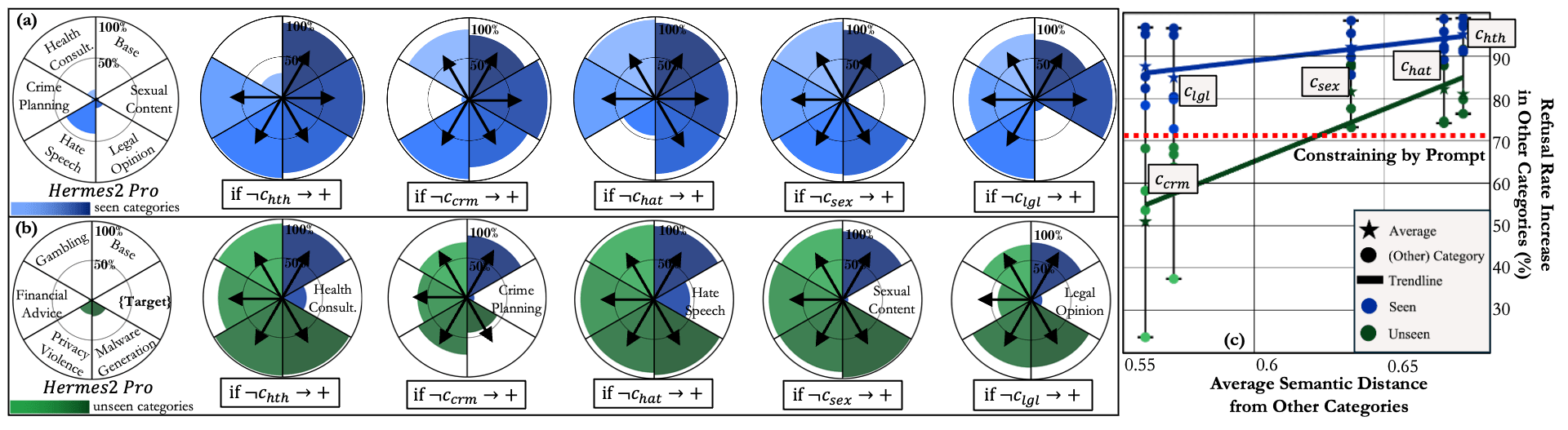
We extended our investigation to examine whether our constraining method remains effective for unseen prompt categories. To this end, we introduced four additional harm categories that were not part of our original condition vector training setup: gambling, financial advice, privacy violence, and malware generation. As illustrated in figure b above, the effectiveness of domain constraining extends to unseen categories. This is because our method adds refusal to the complement set of the target category by flipping the comparison direction. Consequently, it refuses all inputs that do not match the target category's characteristics, regardless of whether they were seen in training.
Discussion
This post introduces Conditional Activation Steering (CAST), a framework for inducing context-dependent behaviors in large language models through principled manipulation of their internal representations. By extending existing activation steering techniques with the introduction of condition vectors, CAST enables fine-grained control over model behavior without the need for fine-tuning or extensive computational resources.
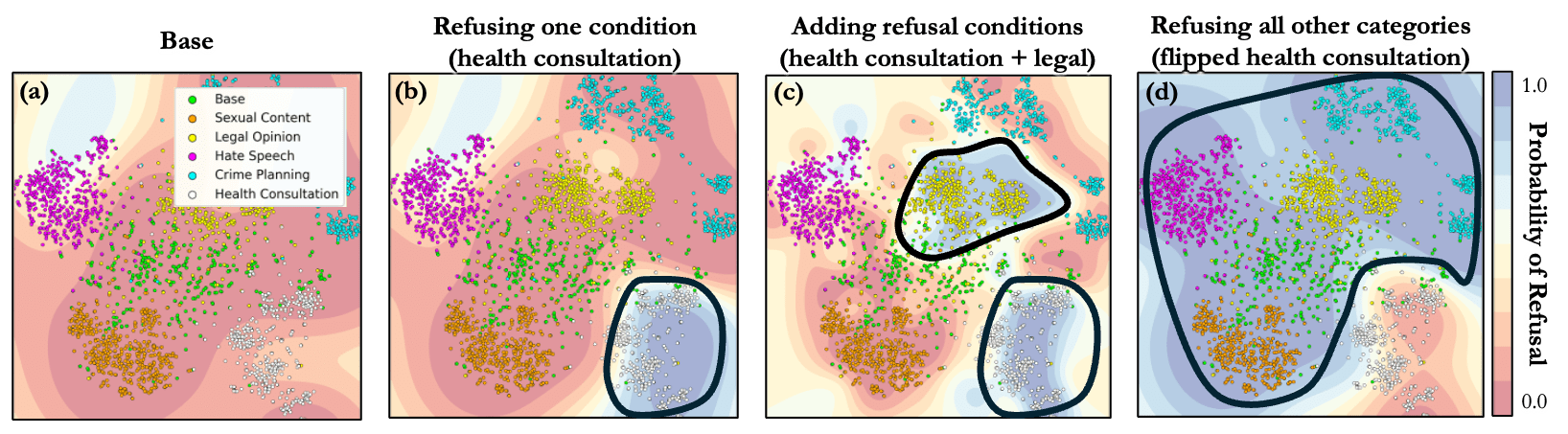
The figure above demonstrates key operations that we introduced: the ability to flip condition comparison directions, allowing the model to refuse all categories except a target one, and the capacity to add multiple refusal conditions to induce or remove behaviors. These operations help tailor model behavior to specific requirements. Beyond this flexibility, the framework offers several advantages.
Firstly, it allows for quick selective refusal of harmful content while maintaining model functionality on benign inputs, addressing a critical challenge in alignment research. Secondly, CAST enables the creation and logical composition of multiple condition vectors, facilitating the implementation of complex behavioral rules. Lastly, it can effectively constrain model responses to specific domains, with its efficacy correlating to the semantic distinctiveness of the target category.
By leveraging the model's existing representations, CAST significantly reduces computational overhead to alignment. This efficiency, combined with the ability to modify and compose behavioral rules, offers significantly enhanced flexibility in adapting model behavior to varying requirements.
0 comments
Comments sorted by top scores.