A Bearish Take on AI, as a Treat
post by rats (cartier-gucciscarf) · 2025-02-10T19:22:30.593Z · LW · GW · 0 commentsThis is a link post for https://open.substack.com/pub/poiu1/p/a-bearish-take-on-ai-as-a-treat
Contents
Reasoning models aren't a fundamental change How narrow? Some things might be hard None No comments
The implicit model that I have regarding the world around me on most topics is there is a truth on a matter, a select group of people and organizations who are closest to that truth, and an assortment of groups who espouse bad takes either out of malice or stupidity.
This was, to a close approximation, my opinion about AI progress up until a couple weeks ago. I believed that I had a leg up on most other people not because I cared more or was more familiar with the topic, but rather because as a consequence of that I knew who the actually correct people were and they had fallen for the hucksters. I realize now that nobody knows what they're talking about, everybody is making shit up, and we're pouring hundreds of billions of dollars into educated guesses. It's worked so far!
I still do think those who have followed The Way are in general much more informed on the near-term (and maybe medium-term) regarding AI progress, even over those others who are good at staying neutral, keeping an open mind, and learning quickly. But well-informed echo chambers are echo chambers nonetheless, and especially in regard to predicting the future we should be careful not to over-index.
The entirety of the big lab leadership seems to have converged on Aschenbrenner thought, but their resolve betrays the actual uncertainty of the situation. The world is weird and lots of things can happen - even the boring futures are still possible in this timeline. I present some objections to this world model below. I'm not really bearish in all honesty, but I felt compelled to write something that was more compelling to me (and hopefully other people) than a lot of the skeptical stuff that was out there.
Reasoning models aren't a fundamental change
People will sometimes learn about something that makes them feel really strongly in some way. They later find out about some clarification that should make them temper their first response, but since it wasn't as emotionally resonant, it doesn't spread as far, and the people who read it don't make the right mental adjustments. Worse yet if the clarification has its own asterisks attached. I feel like I saw this exact thing happen with o3's performance on ARC-AGI:
1) o3 blew the brakes off this test, going from nothing to saturation in a snap. Performance on ARC-AGI was presented as a fundamental limit of the transformer architecture, so when this happened, and lots of people (including me) were quick to hail o3 as the sign of a paradigm shift.
2) People pointed out that o3's performance was dependent on the size of the input - i.e. that it didn't fully generalize.
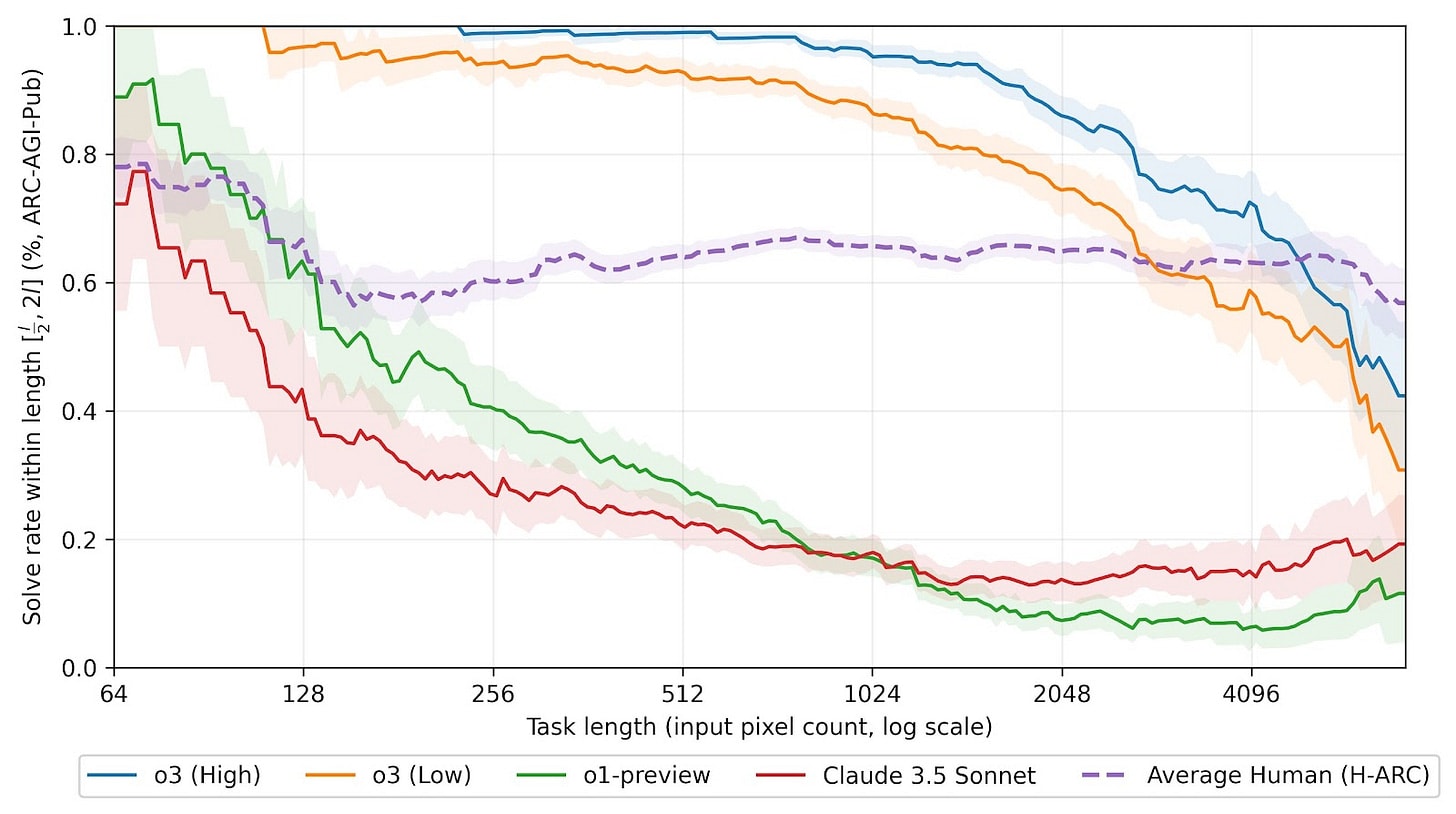
3) Roon et. al explain the cause of this disappointing finding: it's a problem of perception, not of original reasoning.
Fair enough. But look at that graph again... doesn't this mean that o3's performance on ARC-AGI isn't that big of a deal? It didn't prove itself capable of doing something the base architecture just wasn't capable of, it just pushed the performance frontier out a little, same as usual. I had wanted to believe that capturing structured reasoning would be the path to ASI and beyond, but it really seems to have amounted to just an extra layer of computation around the base architecture - letting the model slosh around in latent space just a bit longer.
ARC-AGI wasn't the only reason why were freaked out about o3, and it wasn't even the most important eval for most. But it was shown for a reason - a breakthrough performance in a non-language based eval would have felt like the bellwether of an epochal shift. The fundamental limitations of LLMs, whatever they are, remain the same.
Why does this matter? The claims of train-time compute scaling hitting a wall are dubious, so we don't actually have any reason to believe that we're hitting some already discovered limit of LLM ability. My issue is that we have intuitive reasons to believe that the previous paradigm isn't going to reach superintelligence on any subject. It's a generative model acting in place of a chatbot as told by its dataset of (up to this point, mostly) human inputs what a chatbot is.
Look at this example of Deepseek's writing. It's good in the sense that Midjourney outputs are good art - it's structurally coherent and has much more expressive power than what came before it, but it has certain ticks, and as these ticks become more subtle people will become better at noticing them. More fundamentally, it's still just a reflection of a world model - it doesn't aspire towards anything.
Reinforcement learning should have removed this limitation in theory, but it would inspire a lot more confidence if we saw examples of abilities that were entirely novel, and not just a step change upward on the same sort of capability curve.
How narrow?
People with lots of experience working with LLMs know that the contours of what a certain model can and can't do don't easily map to a human with a specific set of skills. It's possible that the chasm between being able to output correct code, or even perform well on SWE-bench, and being able to actually perform the daily tasks of a software engineer is larger than people are accounting for. This has been said in a coping handwavy way by people on Twitter who want to become professional visionaries or something, but this missing piece may also be some boring engineering skill that noone ever bothered to write down or test against because we don't even think about it.
Same goes for all other fields, of course. It's obvious when people refer to an LLM as "approaching PhD-level at a subject" that we haven't fully internalized the jagged frontier. GPT-4 learned undergrad-level math and middle-school math at around the same time, and it has encyclopedic knowledge far beyond any human on recall but can't solve common sense riddles. Performing at the level of an IMO winner doesn't entail being able to fill in for one at an R&D job, let alone formulate novel ideas at the frontier of human knowledge.
Some things might be hard
Too hard, even, for a country of geniuses in a datacenter. When reaching endless mode in Balatro, the amount of points needed to win a blind about doubles every ante before reaching endless mode, but when they decide they want you gone they start pulling x5 and x10 multipliers on you - the list of viable strats that can get you to ante 13 looks way different from even what can get you to ante 11.
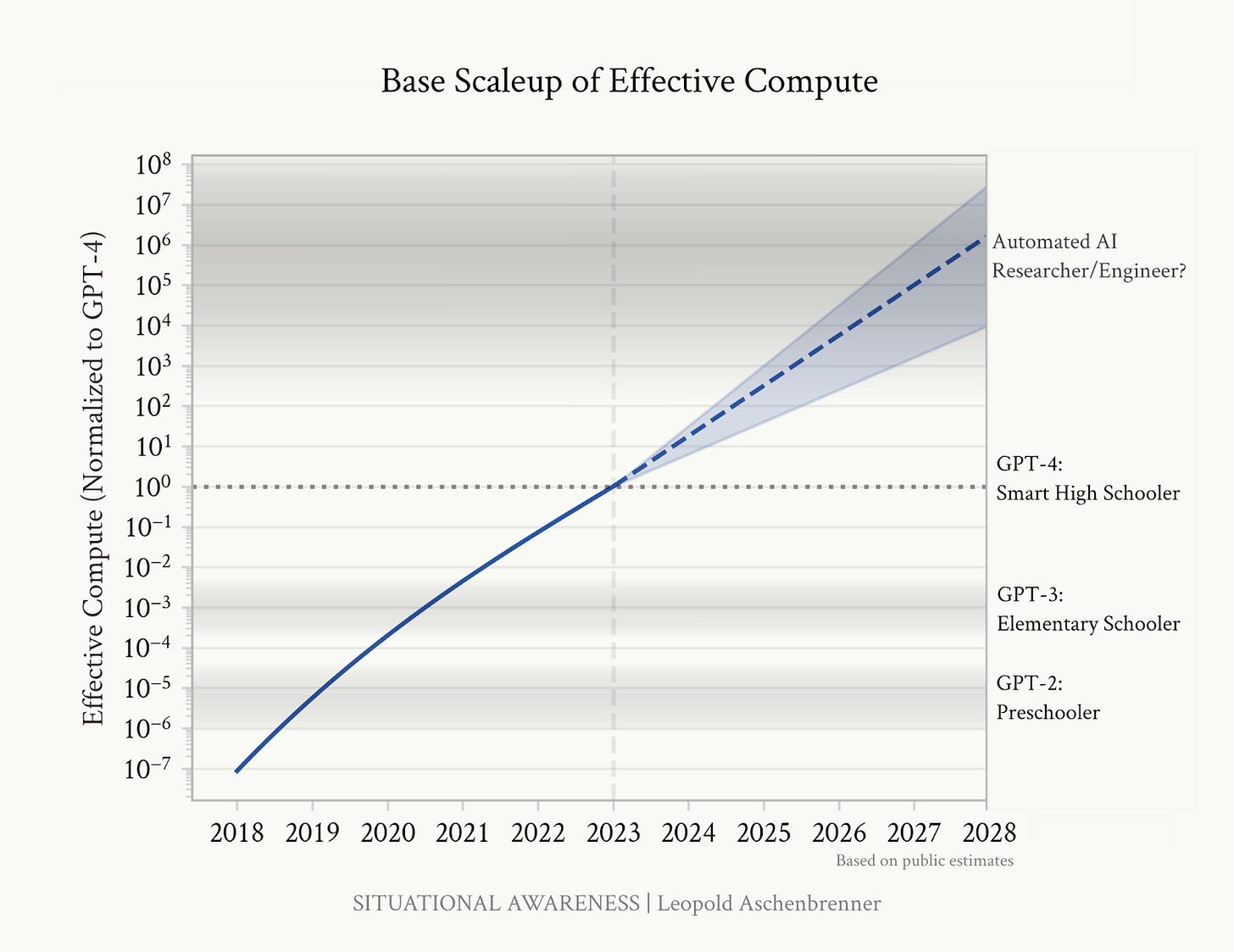
All the discussion of straightforward returns on intelligence to compute completely sidesteps the fact that there still aren't well-defined units for intelligence. If we're at a point of scientific development that looks more like endless mode, then a multiplier of 2x or even 10x doesn't do us much good. And even if there are only a few connective tasks that are human-bottlenecked, their mere existence means that we can't trust AI-assisted development to scale to infinity and beyond. This also applies to AI capability development itself, by the way - we may just never build enough momentum to get to true recursive self-improvement.
0 comments
Comments sorted by top scores.