A brief review of China's AI industry and regulations
post by Elliot Mckernon (elliot) · 2024-03-14T12:19:00.775Z · LW · GW · 0 commentsContents
China’s AI Industry Scope and motivation Interim Measures for the Management of Generative AI Services, 2023 Terminology Chapter I: General Provisions Chapter 2: Development and Governance of Technology Chapter 3: Service Specifications Chapter IV: Oversight Inspections and Legal Responsibility Commentary Provisions on the Administration of Deep Synthesis Internet Information Services, 2022 Terminology Chapter 1: General Provisions Chapter II: Ordinary Provisions Chapter III: Data and Technical Management Specifications Chapter IV: Oversight Inspections and Legal Responsibility Chapter V: Supplementary Provisions Commentary Provisions on the Management of Algorithmic Recommendations in Internet Information Services, 2021 Terminology Chapter I: General Provisions Chapter II: Regulation of Information Services Chapter III: User Rights Protection Chapter IV: Supervision and Management Chapter V: Legal Liability Chapter VI: Supplementary provisions Commentary None No comments
China has enacted three sets of AI regulations since 2021. I haven’t seen a concise breakdown of their content in one place, and I’ve been researching the legislation for a governance project at Convergence Analysis, so here is my concise summary of what I found. I’ll close each section by quoting some expert opinions on the legislation.
I’ll focus on what is being regulated rather than by which government agency, and I’ll omit what I consider “fluff”, such as the highlighted article 1 here. Also, note that I’m relying on other peoples’ translations and haven’t checked their quality. I’ve drawn from multiple translations for each point, but I wouldn’t rely on my precise parsing of the prose.
China’s AI Industry
The AI industry in China is huge and growing rapidly, with a forecasted market size of $38.89 billion in 2024 (37% the size of the US’s forecasted market). China’s 2017 AI development plan states that AI has become a “focus of international competition”, and the 13th Five-Year Plan announced the goal for China to be a global AI leader by 2030. According to Stanford University’s DigiChina, a central concept in Xi Jinping’s leadership is “indigenous innovation” (自主创新), “building on a long-standing tradition of emphasizing self-reliance in industry and technology”.
Chinese AI research output is on par with US research output in share of top global publications and citations, according to a 2022 comparison by CSET. The 2023 AI Index Report found that 78% of Chinese citizens agreed that products & services using AI have more benefits than drawbacks - the highest proportion of surveyed countries, and more than double American citizens' 35% agreement.
Court rulings on AI and copyright are also different in China. In the US and the EU, material generated by AI can’t be copyrighted, but a Beijing court recently ruled that AI-generated content is copyrightable (note that some argue that precedent is less binding in the Chinese legal system, while others still expect this decision to have a huge impact).
Chinese researchers have developed several notable LLMs, such as Beijing Academy of Artificial Intelligence’s Wu Dao 2.0 in 2021 and Huawei Technologies’ PanGu-Σ in 2023. Wu Dao 2.0 has been called “world's largest model”, with some opining “Wu Dao 2.0 is 10x larger than GPT-3. Imagine what it can do” (see also Forbes and Politico). However, while Wu Dao 2.0 and PanGu-Σ did have more parameters than their concurrent occidental counterparts, that doesn’t mean they’re more powerful. Wu Dao 2.0 and PanGu-Σ use a different architecture called mixture of experts, in which different groups of parameters are used for different inputs.
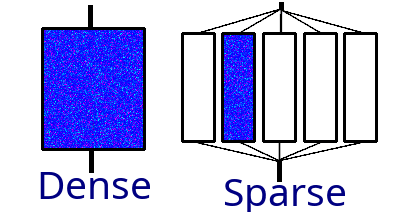
MoE models are sparsely activated; only a fraction of the whole is active at once. Such models are computationally inexpensive relative to their number of parameters, but can be outperformed by smaller dense models. Ultimately, we don’t know how Wu Dao 2.0’s performance compares to others as its developers haven’t publicly released the model or whitepapers on its training & performance. Some claim that Wu Dao 2.0 beats GPT-3 on important benchmarks, while others argue that developers in China developers won’t be able to build competitive models for some time:
China has neither the resources nor any interest in competing with the US in developing artificial general intelligence (AGI) primarily via scaling Large Language Models - The AGI Race Between the US and China Doesn’t Exist [LW · GW] by Eva_B
China could be less important than you'd otherwise think. We should still regard them as a key player in the transformative AI landscape nonetheless. - Is China overhyped as an AI superpower? by Julian
The US has responded to China’s growing AI industry in 2022 by imposing strict controls on exports of certain computer chips necessary for advanced AI, as well as the materials and methods necessary to manufacture their own chips. For more on this, check out CSIS’s report or, for a deep dive on the effects of chip embargos, Deric Cheng’s upcoming evaluation of AI chip registration policies.
Scope and motivation
The Chinese government has numerous policies that are relevant to AI governance, but I’m only going to summarize the following three:
- 2023 legislation on generative AI (Interim Measures for the Management of Generative AI Services)
- 2022 legislation on deepfakes and similar tech (Provisions on the Administration of Deep Synthesis Internet Information Services)
- 2021 legislation on algorithmic recommendations (Provisions on the Management of Algorithmic Recommendations in Internet Information Services)
These are the three pieces of legislation we’re consulting for our upcoming report on the state of global AI governance. In particular, these three “contain the most targeted and impactful regulations to date, creating concrete requirements for how algorithms and AI are built and deployed in China” according to Matt Sheehan, author of a much deeper analysis of Chinese AI governance, which I’ll quote throughout this post such as now:
[these regulations] share three structural similarities: the choice of algorithms as a point of entry; the building of regulatory tools and bureaucratic know-how; and the vertical and iterative approach that is laying the groundwork for a capstone AI law…Vertical regulations target a specific application or manifestation of a technology, [contrasting] horizontal regulations, such as the European Union’s AI Act, that are comprehensive umbrella laws attempting to cover all applications of a given technology.
Summarizing Sheehan’s analysis of the motivation behind these regulations, they serve 3 primary and 1 auxiliary functions:
- To shape technology to serve the CCP’s agenda for information control and political and social stability.
- To address the social, ethical, and economic impacts AI is having on people in China (for example, the provisions protecting workers whose schedules and salaries are set by algorithms).
- To create a policy environment conducive to China becoming the global leader in AI development and application.
- And, as an auxiliary function, to make China a leader in AI governance and regulation.
Interim Measures for the Management of Generative AI Services, 2023
Sources: Pillsbury law, Carnegie Endowment for International Peace, China Law Translate, DigiChina’s Translation, CASI Translation
Summary: Generative AI is to be both supported and regulated. GAI must adhere to core socialist values, respect protected characteristics, and adhere to IP & consent laws. Developers are responsible for violations, and must label GAI output in line with 2022 regulation. The government will support industry innovation and, on the international front, carry out fair exchange and participate in global AI regulation.
Terminology
- Generative AI services, or GAI services, refers to the use of generative AI to provide services to the public for the generation of text, images, audio, video, or other content.
- GAI providers, or just providers, are people or organizations that offer GAI services to the public, including those that provide APIs or otherwise support access to GAI, and those that use GAI to provide services.
- Public opinion properties and social mobilization capabilities are legal properties defined in a previous piece of legislation as including the following situations:
- (1) running forums, blogs, microblogs, chat rooms, communication groups, public accounts, short videos, online streaming, information sharing, mini-apps, and other such information services or corresponding functions;
- (2) running other Internet information services providing public opinion expression channels or having the capacity to incite the public to engage in specific activities.
Note that “public opinion properties” and “social mobilization capabilities” will both come up in the 2022 and 2021 legislation below, but I’ll only define them here.
Chapter I: General Provisions
- These measures only apply to public-facing GAI in mainland China, excluding internal and non-public-facing use within businesses, research orgs, etc.
- The state places equal emphasis on development and security.
- The provision and use of GAI must:
- Uphold the Core Socialist Values, e.g. no inciting separatism or subversion of socialism, no fake or harmful information.
- Employ “effective measures” to prevent discrimination based on characteristics like race, sex, religion etc
- Respect intellectual property, and not be used for unfair competition or establishing monopolies
- Respect the rights & well-being of others
- Employ “effective measures” to increase transparency, accuracy, and reliability.
Chapter 2: Development and Governance of Technology
- The state will:
- Encourage and support innovation in both the application of GAI across industries & fields (e.g. education, research, culture) and in the technology underlying GAI (e.g. algorithms, chips, software).
- Carry out international exchanges & cooperation fairly and participate in formulating international GAI regulation.
- Promote GAI infrastructure, such as platforms for publicly sharing training data, algorithms, and computing resources
- Encourage the adoption of safe, reliable chips, software, and resources.
- When handling training data, GAI Providers must:
- Use lawfully sourced data and models.
- Not infringe on IP rights
- Use personal information only with consent, or shall comply with “other situations provided by laws and administrative regulations”
- Try to increase the quality, truth, accuracy, objectivity, and diversity of training data.
- Follow relevant PRC Laws such as on Cybersecurity, Data Security, and Personal Information Protection.
- When manually tagging (or labeling) data, GAI Providers must use clear and feasible rules, and carry out assessments & spot checks of labeling quality
Chapter 3: Service Specifications
- GAI Providers bear responsibility as:
- Online information content producers, following 2019 legislation.
- Personal information handlers, following 2021 legislation.
- Regarding their users, GAI Providers must:
- Sign service agreements with users who register to use GAI.
- Explicitly disclose the user groups and users for their service, and prevent users becoming reliant on or addicted to generated content.
- Treat confidential information accordingly
- Not collect unnecessary personal info or illegally retain info from which users can be identified
- Promptly address user requests to access, modify, or delete their personal info.
- Regarding generated content, GAI Providers must:
- Label generated images and videos in accordance with 2022 legislation (see next section).
- Provide safe, stable, sustained services.
- Address illegal content, such as by promptly stopping generation or removing it; optimizing training to correct the problem; and reporting to relevant overseers.
- Address illegal use of GAI by warning, limiting, suspending, or removing services, and by storing and reporting records of illegal use.
- Providers must set up easy ways for users to lodge complaints.
Chapter IV: Oversight Inspections and Legal Responsibility
- Relevant government departments are to strengthen the management of GAI services in accordance with law.
- Relevant national authorities are to improve scientific regulatory methods and formulate regulation guidelines.
- GAI providers offering services with public opinion properties or the social mobilization capabilities must carry out security self-assessments and file algorithms in accordance with 2022 legislation (see below).
- Users discovering law-breaking GAI services have the right to report this.
- GAI Providers must cooperate with oversight inspections of GAI services, explaining the data and technical aspects of their models.
- Those participating in oversight inspections mustn’t break confidentiality of state or commercial secrets or personal privacy.
- When GAI services from outside mainland China don’t meet these laws, this must be addressed by the state internet information department.
- Penalties for violating these measures should follow past legislation, or if that’s silent, relevant departments are to give warnings, circulate criticism, order corrections, and eventually to suspend the service.
Commentary
Jenny Shang, Chunbin Xu, and Wenjun Cai at Pillsbury Law point out that the final version of the regulations are significantly lighter than early drafts, citing that:
...the new requirements:
- Relax the requirements on data training by replacing the previous requirement on Providers of “ensuring the authenticity and accuracy of data” with “taking effective measures to improve transparency, authenticity and accuracy of data;”
- Replace the requirements on the Providers of “taking measures to prevent the generation of false information” with requirements of “taking effective measures to enhance the transparency of Generative AI Services and improve the accuracy and reliability of generated content;”
- Eliminate the three-month timeline for Providers to improve data models after detecting violations of any laws or regulations, thereby granting Providers more freedom to enhance their AI models; and
- Remove the requirement for real identity verification.”
Matt Sheehan at Carnegie, mentioned earlier, writes:
By rolling out a series of more targeted AI regulations, Chinese regulators are steadily building up their bureaucratic know-how and regulatory capacity. Reusable regulatory tools like the algorithm registry can act as regulatory scaffolding that can ease the construction of each successive regulation, a particularly useful step as China prepares to draft a national AI law in the years ahead. [...]
The specific requirements and restrictions […] will reshape how the technology is built and deployed in the country, and their effects will not stop at its borders. They will ripple out internationally as the default settings for Chinese technology exports. They will influence everything from the content controls on language models in Indonesia to the safety features of autonomous vehicles in Europe. China is the largest producer of AI research in the world, and its regulations will drive new research as companies seek out techniques to meet regulatory demands. As U.S.- and Chinese-engineered AI systems increasingly play off one another in financial markets and international airspace, understanding the regulatory constraints and fail-safe mechanisms that shape their behavior will be critical to global stability.
Matt O’Shaugnessy, also at Carnegie, writes:
Parts of the draft regulation would make real progress in shielding millions of people from potential harms of AI, if enforced in a uniform and meaningful way…these requirements bring to mind principles that are often promoted as supporting democratic values.
At the same time, the draft demonstrates an obvious intention to strengthen government control over China’s technology and information ecosystems […] The draft’s vague language would give regulators substantial leverage to impose their will on tech companies. Requirements are focused on the private-sector actors developing and deploying generative AI systems; absent is any description of government AI use.
Qiheng Chen, on the topic of open-source models, writes:
a notable gap in China’s generative AI regulations is the lack of specific guidance for open-source providers, which leads to ambiguity. The Interim Measures do not distinguish between open-source and API model providers. Imposing the same responsibilities on open-source and API providers could inadvertently hamper innovation.
Provisions on the Administration of Deep Synthesis Internet Information Services, 2022
Sources: China Law Translate, DigiChina, Allenovery, China Briefing
Summary: Deepfakes and similar synthetic imagery, text, video, audio etc must respect social norms, and must not be used to harm the nation’s image or security interests; to spread false information; or to recreate someone’s image without consent. Synthetic output must be watermarked, and in many cases, conspicuously labeled.
Terminology
- Deep synthesis: This is sometimes interpreted as referring exclusively to deepfakes, but according to an official FAQ (also in article 2 of the draft here, or chapter V here), the term “deep synthesis technology” in the regulations refers to any technology that uses generative synthetic algorithms such as deep learning and virtual reality to produce text, images, audio (vocal and music), video, 3D construction and simulation.
- Deep synthesis service providers: Individuals or organizations who provide deep synthesis services (or provide technical support for them).
- Biometric information: Data about human bodies, e.g. a deepfaked face or voice.
Chapter 1: General Provisions
- These provisions apply to the online use and provision of deep synthesis.
- Deep synthesis services must respect social mores and ethics and adhere to the correct political direction, public opinion orientation, and values trends.
- Industry organizations are encouraged to establish standards for self-management and accept societal oversight.
Chapter II: Ordinary Provisions
- Deep synthesis must not be used to:
- Share prohibited information.
- Engage in prohibited activities, e.g. endanger national security, harm the image of the nation or the public interest, disturb order, harm others’ rights.
- Share fake news.
- Deep synthesis service providers must:
- Take responsibility for information security and establish management systems, e.g. for user registration, algorithm review, ethics review, prevention of fraud.
- Disclose management rules, improve service agreements, and make users aware of their security obligations.
- Verify the real identity of users (i.e. not provide deep synthesis services to non-verified users)
- Conduct reviews of the data inputted by users and consequent output.
- Establish a pool of characteristics to identify illegal and negative content, and take measures against such content, for example by giving warnings & closing accounts.
- Establish mechanisms for dispelling rumours, for use when false information has been shared using the deep synthesis service (they must also submit a report.
- Set up convenient portals for appeals, complaints, and reports.
- App stores & other distributors must implement safety protocols and promptly handle any illegal deep synthesis service providers, e.g. through warnings or taking them off the market.
Chapter III: Data and Technical Management Specifications
- Deep synthesis service providers must ensure the security of training data and protect personal information.
- When deep synthesis is used to edit biometric information (e.g. someone’s face or voice), they must prompt the user to notify and get consent from the person whose info is being edited.
- Where tools have the following functions, providers must carry out securitcy assessments:
- Generating/editing biometric information
- Generating/editing information involving that might involve national security, the nation’s image, or the societal public interest.
- Providers must watermark the output of services.
- Providers must allow users to add conspicuous labels to the output of services.
- Providers must add conspicuous labels to the output of services when providing:
- Services such as smart dialogue;
- Speech generation;
- Image and video generation, e.g. face swapping
- Generation of realistic immersive scenes;
- Other services that generate or significantly alter information content.
Chapter IV: Oversight Inspections and Legal Responsibility
- Providers that have public opinion properties or capacity for social mobilization (see the 2021 legislation below) must conduct filing formalities within 10 working days of providing services and display their filing number prominently on their website, and must carry out necessary security assessments
- Internet, telecom, and public security departments may carry out oversight inspections of deep synthesis providers.
- When providers violate these provisions, they’re to be legally punished; where serious consequences were caused, give heavier penalties in accordance with law.
Chapter V: Supplementary Provisions
- Article 23 defines the terminology introduced above; see here for the full detail.
- Providers must also comply with relevant provisions on culture and tourism, and radio and television.
- The rules take effect January 10th, 2023.
Commentary
Matt Sheehan at Carnegie, quoted above also, provides some useful context for this legislation:
The deep synthesis regulation was years in the making, but in the end it suffered from particularly poor timing. It was finalized on November 25, 2022, just five days before the release of ChatGPT.
[...] During the policy incubation process, the technology company Tencent managed to introduce and popularize the term “deep synthesis” to describe synthetic generation of content, replacing the politically radioactive “deepfakes” with a more innocuous-sounding technical term.
Paol Triolo, technology policy lead at Albright Stonebridge, told CNBC:
Chinese authorities are clearly eager to crack down on the ability of anti-regime elements to use deepfakes of senior leaders, including Xi Jinping, to spread anti-regime statement. But the rules also illustrate that Chinese authorities are attempting to tackle tough online content issues in ways few other countries are doing, seeking to get ahead of the curve as new technologies such as AI-generated content start to proliferate online.
Kendra Schaefer, partner at Trivium China, writes:
China is able to institute these rules because it already has systems in place to control the transmission of content in online spaces, and regulatory bodies in place that enforce these rules. So, these rules underscore the policy problem of our age: How can Western democracies fight a war against disinformation and prevent the erosion of trust and truth online, but without resorting to censorship?
I’ll also note that I struggled to find any information on how these laws have been applied since coming into effect in early 2023. There seems to have been at least one case where a face-swapping app was court-ordered to issue an apology and compensate individuals who’d been wronged.
Provisions on the Management of Algorithmic Recommendations in Internet Information Services, 2021
Sources: China Law Translate, DigiChina, Finnegan, Carnegie
Summary: Algorithms used to recommend content (e.g. a news feed in an app) must protect the rights of minors, the elderly, and workers.They must not spread false information, abuse their power, or disrupt economic or social order. Under some conditions, such algorithms must be registered with the government.
Terminology
- Algorithmic recommendation technology: The use of algorithm technologies types such as generation and synthesis, individualized pushing, sequence refinement, search filtering, schedule decision-making, and so forth to provide users with information.
- ARS: Algorithmic recommendation service, i.e. any service available to the public featuring algorithmic recommendation technology.
Chapter I: General Provisions
- These provisions apply to ARSs online within mainland China.
- ARSs must obey laws, social mores, ethics, and the principles of equity, fairness, transparency, rationality, reasonableness.
- Industry organizations are encouraged to strengthen industry discipline, establish standards for self-management, and accept societal oversight.
Chapter II: Regulation of Information Services
- ARS providers shall uphold mainstream values, actively spread positive energy, and promote the positive use of algorithms.
- ARS providers must not use ARSs to:
- Endanger national security, societal public interest, or the rights’ of others
- To disrupt economic or social order.
- Spread false information
- Abuse their power by falsely registering users, illegally trading accounts, manipulate search results etc
- To impose unreasonable restrictions on other ISPs or carry out monopolistic competition.
- ASR providers must:
- Prevent the dissemination of harmful information.
- Take responsibility for algorithmic security, ethics reviews, user registration, security assessments, personal information protection, countering fraud, etc.
- Regularly assess their algorithmic mechanisms, models, data, and outcomes.
- Establish feature databases to identify unlawful or harmful information.
- Strengthen user model & user tagging management, and perfect norms for logging interests (though they may not use unlawful or harmful information as keywords)/
- Strengthen ARS display & UI (including promoting information conforming to mainstream values).
- Obtain a permit before providing internet news
Chapter III: User Rights Protection
- ARS providers must provide users with:
- Clear info on their ARS.
- A choice not to target their individual characteristics, or to switch off ARS altogether.
- Functions to remove their user tags.
- An explanation of the provider’s liability if algorithms are used in a manner creating major influence on users’ rights and interests.
- When ARSs are provided to minors (under 18):
- Providers must fulfill duties for the online protection of minors, and make it convenient for minors to obtain information beneficial to their physical and mental health.
- Providers may not push information inciting minors toward unsafe conduct, violation of social morals, or online addiction.
- ARS providers must respect the lawful rights and act supportively towards the elderly and workers whose income depends on them (e.g. delivery workers subject to algorithmic scheduling or price discrimination)..
- ARS operators shall make it easy for users to register complaints.
Chapter IV: Supervision and Management
- Appropriate departments are to establish a categorized algorithm security management system, based on the ARS’s public opinion properties, social mobilization capability, content categories, scale of users, the importance of data handled etc.
- Providers of ARSs with public opinion properties or social mobilization capabilities must register (and maintain the filing of) their algorithm with the government, including submitting a self-assessment report and a security assessment.
- The Cybersecurity department will conduct algorithm security assessments on ARSs.
- Providers must preserve records of their network and support governmental investigators.
Chapter V: Legal Liability
- This section prescribes the legal consequences of breaking different sets of these articles, including the possibility of criminal liability and fines up to 100,000 yuan ($14,000 USD)
Chapter VI: Supplementary provisions
- Article 35: These Provisions take effect on March 1, 2022.
Commentary
Matt Sheehan at Carnegie, quoted above also, writes:
The term ‘algorithmic recommendation’ [...] first emerged during a 2017 CCP backlash against ByteDance’s news and media apps, in which user feeds were dictated by algorithms. The party viewed this as threatening its ability to set the agenda of public discourse and began looking for ways to rein in algorithms used for information dissemination […]
As policy discussions on recommendation algorithms took shape, new concerns emerged that caused authorities to add provisions addressing them. Prominent among these was public outcry over the role algorithms play in creating exploitative and dangerous work conditions for delivery workers. [...]
the recommendation algorithm regulation created an important new tool for regulators: the algorithm registry (算法备案系统, literally “algorithm filing system”). The registry is an online database of algorithms that have “public opinion properties or . . . social mobilization capabilities.” Developers of these algorithms are required to submit information on how their algorithms are trained and deployed, including which datasets the algorithm is trained on. They are also required to complete an “algorithm security self-assessment report” (算法安全自评估报告. Here, “security,” 安全,can also be translated as “safety”). ”
Lionel Lavenue, Joseph Myles, and Andrew Schneider at Finnegan write about international law implications of this legislation compared to previous legislation (the DSL & PIPL):
the regulations may allow Chinese litigants to refuse or delay discovery. For example, in [a 2021 court case], Chinese-based defendant ZHP invoked the DSL and the PIPL to avoid producing documents, arguing that the documents at issue were “state secrets.” In a published opinion on the issue, Judge Robert B. Kugler held that the PIPL and DSL did not shield discovery, and he warned that Chinese defendants must “know from the outset they risk serious consequences if and when they fail to obey a U.S. court’s order to compel discovery [...] the IISARM regulations add another layer of bureaucracy. Thus, if litigants want to obtain information for discovery from China, they are likely to run into new administrative slowdowns.
Steven Rolf, author of China's Regulations on Algorithms, compares these regulations with the draft EU AI Act (note that the draft EU act has since undergone significant redrafting):
The major distinguishing feature of [the EU AI Act] is its emphasis on upholding fundamental individual rights – such as privacy, ethical decision-making and data security – against (principally US-based) tech firms [...] From the perspective of individuals, then, Europe’s regulatory drive is preferable to that of China’s – which places little emphasis on privacy or fundamental rights. But it does little to tackle issues beyond individual concerns. As one report argues, recommendation algorithms ‘may cause societal-level harms, even when they cause only negligible harms to individuals’ (by, for instance, tipping the balance in an election by discouraging wavering voters from turning out) [...] Even in an age of growing algorithmic regulation, then, China’s ‘social’ model contrasts with the emerging ‘individualist’ European regulatory model. China’s emergent regulatory system targets areas hardly touched by Europe’s flagship regulations
For more information on other Chinese legislation that may relate to AI, check out Making Sense of China’s AI Regulations by Ashyana-Jasmine Kachra at Holistic AI, which also features concise summaries of China’s AI industry and legislation with lovely visuals, and which was published only after I’d written the majority of this post, alas.
Thank you to Deric Cheng for his encouragement, and Deric and Justin Bullock for their feedback on this post.
If you’re interested in global AI legislation, over the next few months we’ll be publishing deep dives into topics like AI chip registration policies, and a series of posts analyzing EU, Chinese, and US AI legislation on specific topics such as model registries and risk assessments. You can find the first post here: AI Regulatory Landscape Review: Incident Reporting [LW · GW]. Ultimately, this research will culminate in a State of the AI Regulatory Landscape in 2024 report later this year. If you’d like to get updates on this work, check out Convergence Analysis and sign up to our newsletter!
0 comments
Comments sorted by top scores.