A dialectical view of the history of AI, Part 1: We’re only in the antithesis phase. [A synthesis is in the future.]
post by Bill Benzon (bill-benzon) · 2023-11-16T12:34:35.460Z · LW · GW · 0 commentsContents
Symbolic AI: Thesis Statistical NLP and Machine Learning: Antithesis AGI Now or do we Need New Architectures? Synthesis: Assuming I’m right, what’s dialectical about this evolution? Addendum: The Turing Awards for 1975 and 2018 None No comments
Cross-posted from New Savanna.
The idea that history proceeds by way of dialectical change is due primarily to Hegel and Marx. While I read bit of both early in my career, I haven’t been deeply influenced by either of them. Nonetheless I find the notion of dialectical change working out through history to be a useful way of thinking about the history of AI. Because it implies that that history is more than just one thing of another.
This dialectical process is generally schematized as a movement from a thesis, to an antithesis, and finally, to a synthesis on a “higher level,” whatever that is. The technical term is Aufhebung. Wikipedia:
In Hegel, the term Aufhebung has the apparently contradictory implications of both preserving and changing, and eventually advancement (the German verb aufheben means "to cancel", "to keep" and "to pick up"). The tension between these senses suits what Hegel is trying to talk about. In sublation, a term or concept is both preserved and changed through its dialectical interplay with another term or concept. Sublation is the motor by which the dialectic functions.
So, why do I think the history of AI is best conceived in this way? The first era, THESIS, running from the 1950s up through and into the 1980s, was based on top-down deductive symbolic methods. The second era, ANTITHESIS, which began its ascent in the 1990s and now reigns, is based on bottom-up statistical methods. These are conceptually and computationally quite different, opposite, if you will. As for the third era, SYNTHESIS, well, we don’t even know if there will be a third era. Perhaps the second, the current, era will take us all the way, whatever that means. Color me skeptical. I believe there will be a third era, and that it will involve a synthesis of conceptual ideas computational techniques from the previous eras.
Note, though, that I will be concentrating on efforts to model language. In the first place, that’s what I know best. More importantly, however, it is the work on language that is currently evoking the most fevered speculations about the future of AI.
Let’s take a look. Find a comfortable chair, adjust the lighting, pour yourself a drink, sit back, relax, and read. This is going to take a while.
Symbolic AI: Thesis
The pursuit of artificial intelligence started back in the 1950s it began with certain ideas and certain computational capabilities. The latter were crude and radically underpowered by today’s standards. As for the ideas, we need two more or less independent starting points. One gives us the term “artificial intelligence” (AI), which John McCarthy coined in connection with a conference held at Dartmouth in 1956. The other is associated with the pursuit of machine translation (MT) which, in the United States, meant translating Russian technical documents into English. MT was funded primarily by the Defense Department.
The goal of MT was practical, relentlessly practical. There was no talk of intelligence and Turing tests and the like. The only thing that mattered was being able to take a Russian text, feed it into a computer, and get out a competent English translation of that text. Promises was made, but little was delivered. The Defense Department pulled the plug on that work in the mid-1960s. Researchers in MT then proceeded to rebrand themselves as investigators of computational linguistics (CL).
Meanwhile researchers in AI gave themselves a very different agenda. They were gunning for human intelligence and were constantly predicting we’d achieve it within a decade or so. They adopted chess as one of their intellectual testing grounds. Thus, in a paper published in 1958 in the IBM Journal of Research and Development, Newell, Shaw, and Simon wrote that if “one could devise a successful chess machine, one would seem to have penetrated to the core of human intellectual endeavor.” In a famous paper, John McCarthy dubbed chess to be the Drosophila of AI.
Chess isn’t the only thing that attracted these researchers, they also worked on things like heuristic search, logic, and proving theorems in geometry. That is, they choose domains which, like chess, were highly rationalized. Chess, like all highly formalized systems, is grounded in a fixed set of rules. We have a board with 64 squares, six kinds of pieces with tightly specified rules of deployment, and a few other rules governing the terms of play. A seeming unending variety of chess games then unfolded from these simple primitive means according to the skill and ingenuity, aka intelligence, of the players.
This regime, termed symbolic AI in retrospect, remained in force through the 1980s and into the 1990s. However, trouble began showing up in the 1970s. To be sure, the optimistic predictions of the early years hadn’t come to pass; humans still beat computers at chess, for example. But those were mere setbacks.
These problems were deeper. While the computational linguistics were still working on machine translation, they were also interested in speech recognition and speech understanding. Stated simply, speech recognition goes like this: You give a computer a string of spoken language and it transcribes it into written language. The AI folks were interested in this as well. It’s not the sort of thing humans give a moment’s thought to; we simply do it. It is mere perception. It was proving to be surprisingly difficult. The AI folks also turned to computer vision: Give a computer a visual image and have it identify the object. That was difficult as well, even with such simple graphic objects as printed letters.
Speech understanding, however, was on the face of it intrinsically more difficult. Not only does the system have recognize the speech, but it must understand what is said. But how do you determine whether or not the computer understood what you said. You could ask it: “Do you understand?” And if it replies, “yes,” then what? You give it something to do.
That’s what the DARPA Speech Understanding Project set out to do in over five years in the early to mid 1970s. Understanding would be tested by having the computer answer questions about database entries. Three independent projects were funded; interesting and influential research was done. But those systems, interesting as they were, were not remotely as capable as Siri or Alex in our time, which run on vastly more compute encompassed in much smaller packages. We were a long way from having a computer system that could converse as fluently as a toddler, much less discourse intelligently on the weather, current events, the fall of Rome, the Mongol’s conquest of China, or how to build a fusion reactor.
During the 1980s the commercial development of AI petered out and a so-called AI Winter settled in. It would seem that AI and CL had hit the proverbial wall. The classical era, the era of symbolic computing, was all but over.
Statistical NLP and Machine Learning: Antithesis
Let’s step back to 1957 for a moment. That’s when the Russians launched Sputnik. It’s also when Noam Chomsky published Syntactic Structures, which was to prove very influential in linguistics and in the so-called cognitive sciences more generally. First of all, he reinforced the idea that linguists should study syntax, but not semantics, and argued for their strict separation. That’s the point of his famous example sentence: “Colorless green ideas sleep furiously.” It’s syntactically perfect, but semantically nonsense. He then went on to model syntax on the idea of mathematical proof, where the syntactic structure of a sentence is, in effect, a theorem in a mathematical system.
He also argued against statistical methods, asserting (p. 17): “I think that we are forced to conclude that grammar is autonomous and independent of meaning, and that probabilistic models give no particular insight into some of the basic problems of syntactic structure.” Statistical methods are necessarily data-driven. Where the inference rules of symbolic systems were painstakingly hand-crafted by researchers, the rules of statistical systems are derived from a computational analysis of data.
While various statistical ideas had been around since the 1950s, including neural nets, one of the first arenas where they demonstrated their practical value is that of speech recognition. In the mid-1980s an IBM group led by Fred Jelinek used a standard statistical technique, a hidden Markov model, that demonstrated a 20,000-word vocabulary. Where the work done under DARPA’s 1970s Speech Understand Project called on syntactic and semantic information to aid in disambiguating speech, Jelinek’s work was based only on speech data. Later in the decade various speech recognition systems were released as consumer products.
Speech recognition is a very kind of problem from that of identifying syntactic structures in sentences, the problem at the center of Chomsky’s conceptual universe. It is not unreasonable to think of parsing as a top-down formal process. How can you shoehorn speech recognition into that conceptual box? You can’t. Speech recognition is about identifying discrete categories (words) in a continuous stream of messy data. The inventory of words may be finite, if large, but the variability of speech streams is unbounded.
We’re no longer in Kansas. It’s a different world, an opposite one.
Statistical methods of machine translation began replace rule-based going into the 2000s and they were, in turn, supplanted by deep learning in the 2010s (note that deep learning is fundamentally statistical in character). Though none of these various approaches was equivalent to human translation, the statistical approaches are adequate for a variety of informal purposes. In 2012 AlexNet won an important machine vision competition by a significant margin and signaled the emergence of deep neural nets as the dominant machine learning technology. In 2020 GPT-3 surprised everyone with its handling of language tasks and led to widespread speculation about reaching a tipping point (I wrote a working paper on the subject, GPT-3: Waterloo or Rubicon? Here be Dragons). A tipping point to where? That’s not clear. But wherever it is, the release of ChatGPT in late November of 2022 seems to have brought WHERE a lot closer, and to a much wider segment of the population.
That’s where we are now.
Yes, I know, there’s all the vision and image stuff. Yes, it’s interesting and important. And, no, it doesn’t change the story in any fundamental way.
AGI Now or do we Need New Architectures?
What’s next? No one really knows, no one. Most, though certainly not all, of the attention and capital investment is on large language models (LLMs). One widely popular view, that now has quite a bit of investment money riding on it, is that we have most of the basic ideas and techniques that we need.
All we have to do is scale it up: more compute, more data (see Rich Sutton's "The Bitter Lesson"). As far as I know, that’s where most of the money is going these days. How long before we know, one way or another, whether or not scaling is the way to go? I don’t know, nor does anyone else, not really. If I’m wrong, then the basic scheme of this post is wrong. All we have is the eclipse of classical AI by statistical AI. End of story.
It is undeniable that these newer methods have achieved spectacular success in areas where symbolic AI did hit one of those proverbial walls. It is also undeniable that the availability of more compute has been central to this success. What reason do we have to think that still more compute and more data won’t continue to reap rewards?
There are reasons for skepticism. For one thing LLMs have a tendency to “hallucinate,” as it’s called. They make things up. They have problems with common-sense reasoning as well. Both of these problems seem related to the fact that the systems have no direct access to the external world, which would give them purchase on ground truth and access to all the many details of the physical world on which common sense rests. They also have difficulties with tight logical reasoning and with (complex) planning. These various limitations seem to be inherent in the architecture and thus cannot be fixed simply by scaling up.
Those criticisms, and others, need to be argued and not just stated. But this is not the place for those arguments. I’ve articulated some of them in GPT-3: Waterloo or Rubicon? Gary Marcus is perhaps the most visible critical of the current regime; you can check his substack, Marcus on AI, for arguments as well. We both advocate the addition of symbolic methods to these symbolic systems. David Ferrucci, who led IBM’s Watson project, has been keeping out of the public sphere, but he is building a company, Elemental Cognition, based on the integration of statistical and symbolic concepts and techniques. Yann LeCun argues that systems trained on language alone are inherently limited; he is surely correct about this. Subbarao Kambhampati, who is an expert in planning systems, has tweet stream listing a number of critical articles he’s written. Others are critical as well.
My point is simply that there ARE arguments against the idea that all we need to do is build bigger and bigger systems. Simply pointing to the future and saying “Onward ho!” does not negate those reasons. Should those reasons prove valid, what happens next?
Synthesis: Assuming I’m right, what’s dialectical about this evolution?
Or perhaps, more simply, why is it an evolution and not just one thing after another?
Let’s go back to the beginning. While I’ve told the story in pretty much the standard way, symbolic computing being eclipsed by various statistical methods, both kinds of ideas were in the mix from the beginning. As Richard Hughes Gibson points out in a very interesting recent article, back in the 1940s and early 1950s Claude “information theory” Shannon, in effect, hand-simulated small versions of current machine learning engines for language. And Warren Weaver proposed a statistical basis for machine translation.
Why, then, weren’t those ideas acted upon at the time? Because, as a Marxist might say, the material conditions weren’t right. They didn’t have either the computers or the data necessary for doing it. While transiters existed, just barely, integrated circuits did not, much less the very large-scale integration necessary for really powerful processors, not to mention the whole range of peripherals necessary.
Even if they’d had the compute, I doubt that those statistical ideas would have been the first to be tried. Why? Because there is a long intellectual tradition – extending back through George Boole in the 19th century, Leibniz in the 17th, to Aristotle in the ancient world – in which language and thought are conceptualized in terms of logic. That’s the tradition that would have been closest to hand when those intellectuals gathered at that famous 1956 Dartmouth workshop that marked the institutional origins of artificial intelligence. Moreover, way back in 1943 Warren McCulloch and Walter Pitts had published “A Logical Calculus of the Ideas Immanent in Nervous Activity,” in which, as the title says, it made sense to think of the nervous system as carrying out logical operations.
That pretty much settled it. The joint theoretical and practical investigation of the computational view of mind was to be grounded in three ideas arising out of the Dartmouth workshop: “symbolic methods, systems focused on limited domains (early expert systems), and deductive systems versus inductive systems.” The first and third follow from the tradition of logic while the second was a practical necessity dictated by the nature of the available computers.
Our intrepid band of intellectual adventurers then set out to explore the new territory. One can argue whether or not they discovered the territory, or invented it, but at the moment I don’t care which way we think about it. They explored it for roughly three decades, and then AI Winter arrived in the mid-1980s. You can see it in the dip in the blue curve in the following graph, which is from Google Ngrams:
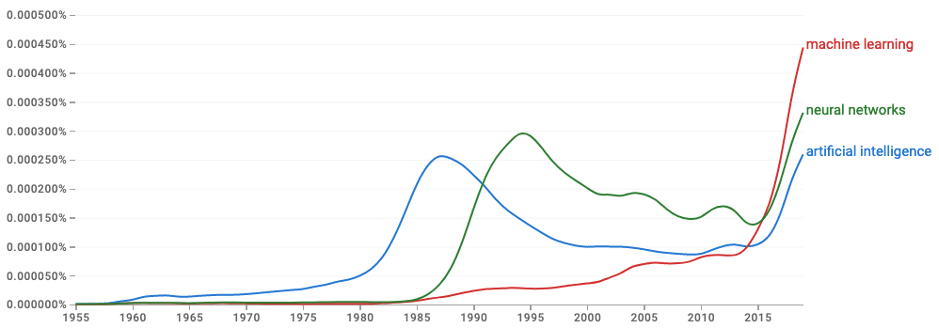
What happened? There is a lot of discussion about that in the literature. It is an important issue. But I’m not even going to attempt the briefest of summaries. I’m going to take it as a brute fact.
What happened next? As you see, the neural networks curve begins to rise, peaking in the mid-1990s. From the point of view I’m taking in this essay, that’s a family of statistical techniques, though a somewhat different family than that associated with machine learning, which has a gradual rise from the mid-1980s up to 2015, at which point it shifts to a steep rise, taking it above the curves for both neural networks and artificial intelligence. As for “artificial intelligence,” I strongly suspect that from 2015 on the term is more likely to refer to the statistical techniques in the neural net or machine learning families than to traditional symbolic AI. It’s not that symbolic AI has dropped off the face of the earth. It’s still around; but it’s a relatively small component of the work being done under the general rubric of AI.
And, of course, neither machine learning or neural networks came out of nowhere. As I pointed out at the beginning of this section, they were there from the beginning. They never disappeared. Someone was always working on them. But when AI Winter set in, things thawed out for, first neural nets, and then somewhat later for machine learning. People and resources moved into those areas and began exploring those regions of the territory.
That brings us to where we were in the previous section: What’s next? As I said then, I think the current regime is living on borrowed time. It too will hit a wall. What then?
I don’t know. Perhaps the whole enterprise will collapse. Those committed to the current regime, Bigger Data Bigger Compute, will refuse to admit that progress has stalled and will limp along as best they can. Since advocates of other approaches have been starved for resources, they can’t really move into the conceptual and technical vacuum that has opened up. They’ll just straggle along, surviving on scraps left to them by the remnants of the Bigger Gangs. What of China, India, Japan, and even Africa? Will they have been bogged down as well? Who knows.
Somehow, though, I do think the enterprise will continue somehow. Assuming that people and material resources are available, what about the ideas? I suppose it is possible that there is some third family of ideas that is distinctly different from the symbolic and statistical families, but I haven’t heard of them, nor has anyone I know.
No, to continue forward, we are going to need approaches that combine ideas from both families. Just what form that synthesis will take, who knows? Perhaps we should look to the brain for inspiration. That’s what David Hays and I did back in 1988, Principles and Development of Natural Intelligence. More recently I’ve augmented and extended those ideas with complex dynamics (e.g. Walter J. Freeman) and the geometric semantics of Peter Gärdenfors, Relational Nets Over Attractors, A Primer: Part 1, Design for a Mind (2023). Surely I am not the only one exploring such ideas. If the dialectic gets stalled, it will not be for lack of ideas.
As for dialectics, first we explore symbolic territory, Thesis. That collapses and we explore statistical territory, Antithesis. When that collapses? When that collapses we’ve run out of territory, no? We take ideas from both territories and create a new territory, on a “higher” level: Synthesis.
More later.
* * * * *
Addendum: The Turing Awards for 1975 and 2018
It just occurred to me that the committee that selects the winners of the Turing Award has been kind enough to recognize the distinction between symbolic and statistical AI. In 1975 the award went to Allen Newell and Herbert Simon for “basic contributions to artificial intelligence, the psychology of human cognition, and list processing.” In 2018 it went to Yoshua Bengio, Geoffrey Hinton, and Yann LeCun “for conceptual and engineering breakthroughs that have made deep neural networks a critical component of computing.” Here's their papers marking the occasion:
Allen Newell and Herbert A. Simon, Computer science as empirical inquiry: symbols and search, Communications of the ACM. Volume 19 Issue 3 March 1976pp 113–126, https://doi.org/10.1145/360018.360022
Yoshua Bengio, Yann Lecun, Geoffrey Hinton, Deep Learning for AI, Communications of the ACM, July 2021, Vol. 64 No. 7, Pages 58-65, https://doi.org/10.1145/3448250
The final paragraph of this essay is quite suggestive:
How are the directions suggested by these open questions related to the symbolic AI research program from the 20th century? Clearly, this symbolic AI program aimed at achieving system 2 abilities, such as reasoning, being able to factorize knowledge into pieces which can easily recombined in a sequence of computational steps, and being able to manipulate abstract variables, types, and instances. We would like to design neural networks which can do all these things while working with real-valued vectors so as to preserve the strengths of deep learning which include efficient large-scale learning using differentiable computation and gradient-based adaptation, grounding of high-level concepts in low-level perception and action, handling uncertain data, and using distributed representations.
It is my belief that, yes, we can do that, but doing so is going to require that we integrate the tools and techniques of classical symbolic reasoning and of statistical deep learning on a ‘higher’ level. Think of Piaget’s concept of reflective abstraction, where the operational tools of one level become objects deployed and manipulated at an evolved higher level.
0 comments
Comments sorted by top scores.