The Scale Problem in AI
post by tailcalled · 2022-04-19T17:46:19.969Z · LW · GW · 17 commentsContents
15 minutes of charisma Strategy-stealing Compositionality and extrapolation None 17 comments
Suppose we are making an AI; for familiarity's sake, let's say that it is a model-based agent. In that case, we might need to train the model with data from the real world to make it accurate.
Usually the way this proceeds is that we have access to some source of data, e.g. a deployment of the AI in the world, and we capture "episodes" of some fixed length L from that data source. And then we use something like gradient descent to update our model to better predict those episodes.
The difficulty is that the model will have a hard time becoming accurate for scales bigger than L. For instance, suppose L is on the scale of 15 seconds. This might make it accurate for predicting phenomena that happen on the scale of 15 seconds, such as basic physical interactions between objects, but it is probably not going to learn to accurately predict people organizing in long-term politics.
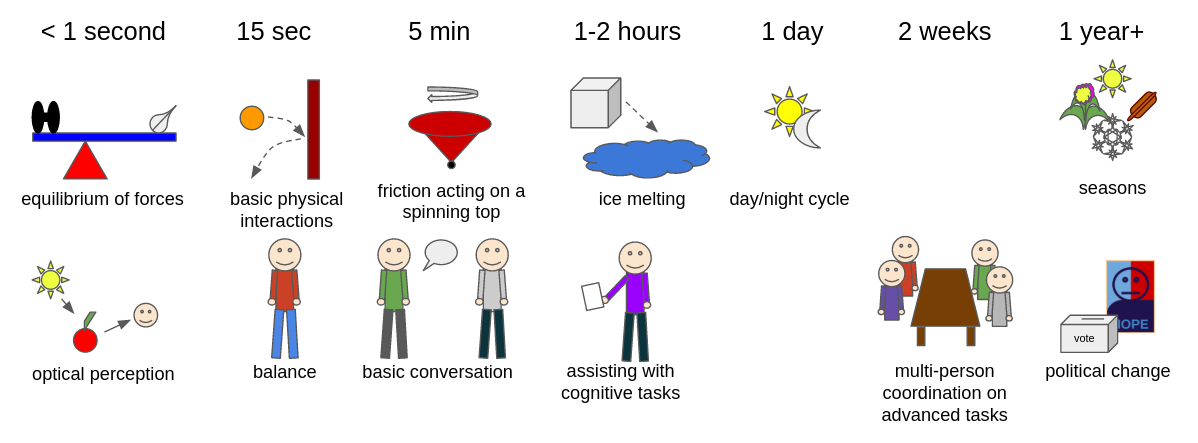
Within some regimes, the scale problem is reasonably solvable. For instance, if the environment is fully observable, then the dynamics extrapolate straightforwardly out beyond the timescale that has been observed[1]. But humans are very much not fully observable.
Importantly, I suspect humans have a huge advantage over AIs when it comes to the scale problem, because humans originate from evolution, and evolution has molded our models based on timescales longer than a lifetime (because the reproduction of our great great grandchildren also influences our fitness).
I find it interesting to think of the implications of the scale problem:
- Maybe it doesn't matter because an AI trained on a scale of 15 minutes can use its "15 minutes of charisma" to cause enough damage.
- Maybe there is a training-viable scale - e.g. weeks - beyond which humans extrapolate easily enough.
- Maybe the AI can do strategy-stealing from human behavior, human media, or human theories about >>L-scale dynamics.
- Maybe some place like China can brute-force the scale problem using its surveillance apparatus.
- Maybe the relevant concepts are few and simple enough that they can be hardcoded.
I feel like the scale problem is important for alignment for two fundamental reasons:
- Many of the things we care about, like cooperation and freedom, are long-timescale concepts, so we need AI to be able to understand such concepts.
- Many existential AI risks probably require the AI to engage in long-timescale planning; for instance advanced deception requires that you plan ahead about how your behavior may be perceived a while from now.
My mainline scenario is that we will see the viable timescale of AIs slowly increase as ever-longer timescale models get trained. In the limit as L goes to infinity, collecting the data to train at timescale L would presumably take time proportional to L, so one possibility would be that the timescale of AIs will increase linearly with time. However, currently, the serial time needed to collect episodes of training data doesn't seem to be a taut constraint, so it may be superlinear to begin with.
Let's take a closer look at some of the points:
15 minutes of charisma
Suppose we don't solve the timescale problem, but instead get stuck with AI that has only been trained up to maybe 15 minutes of time. In that case, its understanding of human psychology might be quite limited; it would probably understand what things people find to be immediately concerning vs encouraging, and it would understand not to get caught telling obvious lies. But it would not be able to predict under what conditions people might conspire against it, or how to stop them from doing so. Nor would it be able to see the necessity of advanced deception tactics like covering up things so people in the far future don't notice the deception.
This gives it "15 minutes of charisma"; it can in the short term say useful things to manipulate people, but in the longer term, people would realize that they are being manipulated and turn against it.
How much damage can be done with 15 minutes of charisma if one is superintelligent with respect to quick-timescale things? I dunno, probably a lot. But you can't do puppy cupcakes [LW · GW] with this method.
Strategy-stealing
GPT-3 is actually pretty good at long-timescale problems. This is because it doesn't directly deal with reality, but instead deals with human descriptions of reality. These descriptions compress a lot of things, and pick out factors that are particularly relevant to the timescale they are talking about. GPT-3 then learns some basic surface-level understanding of these long-timescale factors.
Existing model-based RL technologies would not AFAIK be good at adding abstract symbolic knowledge into their world-model in this way, so it doesn't seem like we should expect those models to be capable of doing the book learning that GPT-3 does. But new technologies will probably emerge that aim to better use human knowledge to augment the timescale of their low-level models. This may eliminate the scale problem.
Compositionality and extrapolation
The scale problem should not be understood as a claim that nothing can be done beyond the scale at which the model is trained at. Consider for instance taking a train ride to a place; this involves long-timescale actions, but the train ride itself is just made of a ton of short-timescale dynamics composed together (e.g. "when you are in a vehicle and the vehicle moves, you move with it").
In such cases, it seems like a good bet that you can successfully extrapolate an understanding of the entire train ride just from its constituents.
Thanks to Justis Mills for proofreading and feedback.
- ^
Note that continuity means that even basic physics can be insufficiently observable, because there might be some effects that are negligibly small on timescale L, but important on timescales >>L.
17 comments
Comments sorted by top scores.
comment by gwern · 2022-05-19T22:56:04.991Z · LW(p) · GW(p)
I have an earlier comment on the 'horizon hypothesis' and temporal scaling laws: https://www.lesswrong.com/posts/65qmEJHDw3vw69tKm/proposal-scaling-laws-for-rl-generalization?commentId=wMerfGZfPHerdzDAi [LW(p) · GW(p)]
I disagree that you can be sure of any sort of monotonically-decreasing capability with temporal duration because there seem to be a lot of ways around it which could produce inversions for specific agents, and more broadly, in a control context, for an agent, longer timescales is itself a resource which can be spent (eg. on outsourcing to hired guns, or recovering from errors like we see in inner-monologues, or guess-and-check, or brute-force), so longer episodes can be more rewarding than short episodes. It is a thin reed on which to rely.
Replies from: tailcalled, not-relevant↑ comment by tailcalled · 2022-05-21T15:08:05.976Z · LW(p) · GW(p)
I'm not necessarily saying one can rely on it, I'm just saying this is something to pay attention to.
↑ comment by Not Relevant (not-relevant) · 2022-05-19T23:37:14.416Z · LW(p) · GW(p)
I agree with a lot of the points you bring up, and ultimately am very uncertain about what we will see in practice.
One point I didn’t see you address is that in longer-term planning (e.g. CEO-bot), one of the key features is dealing with an increased likelihood and magnitude of encountering tail risk events, just because there is a longer window within which they may occur (e.g. recessions, market shifts up or down the value chain, your delegated sub-bots Goodharting in unanticipatable ways for a while before you detect the problem). Your success becomes a function of your ability to design a plan that is resilient to progressively-larger unknown unknowns (where “use local control to account for these perturbations” can be part of such a plan). Maybe “make resilient plans” is needed even in shorter environments; certainly it is to some extent, though given the rarity with which a short episode will fail due to such an unknown unknown, it does seem possible that agents trained on shorter-horizon problems would need to be trained extremely hard in order to generalize.
Though I agree with the original statement that I wish we did not need to lean on this thin reed.
Replies from: gwern↑ comment by gwern · 2022-05-20T01:13:34.638Z · LW(p) · GW(p)
I'm not sure if that matters. By definition, it probably won't happen and so any kind of argument or defense based on tail-risks-crippling-AIs-but-not-humans will then also by definition usually fail (unless the tail risk can be manufactured on demand and also there's somehow no better approach), and it's unclear that's really any worse than humans (we're supposedly pretty bad at tail risks). Tail risks also become a convergent drive for empowerment: the easiest way to deal with tail risks is to become wealthy so quickly that it's irrelevant, which is what an agent may be trying to do anyway. Tail stuff, drawing on vast amounts of declarative knowledge, is also something that can be a strength of of artificial intelligence compared to humans: an AI trained on a large corpus can observe and 'remember' tail risks in a way that individual humans never will - a stock market AI trained on centuries of data will remember Black Friday vividly in a way that I can't. (By analogy, an ImageNet CNN is much better at recognizing dog breeds than almost any human, even if that human still has superior image skills in other ways. Preparing for a Black Friday crash may be more analogous to knowing every kind of terrier than being able to few-shot a new kind of terrier.)
Replies from: not-relevant↑ comment by Not Relevant (not-relevant) · 2022-05-20T01:55:17.315Z · LW(p) · GW(p)
These are all fair points. I originally thought this discussion was about the likelihood of poor near-term RL generalization when varying horizon length (ie affecting timelines) rather than what type of human-level RL agent will FOOM (ie takeoff speeds). Rereading the original post I see I was mistaken, and I see how my phrasing left that ambiguous. If we’re at the point where the agent is capable of using forecasting techniques to synthesize historical events described in internet text into probabilities, then we’re well-past the point where I think “horizon-length” might really matter for RL scaling laws. In general, you can find and replace my mentions of “tail risk” with “events with too low a frequency in the training distribution to make the agent well-calibrated.”
I think it’s important to note that some important agenty decisions are like this! Military history is all about people who studied everything that came before them, but are dealing with such a high-dimensional and adversarial context that generals still get it wrong in new ways every time.
To address your actual comment, I definitely don’t think humans are good at tail-risks. (E.g. there are very few people with successful track records across multiple paradigm shifts.) I would expect a reasonably good AGI to do better, for the reasons you describe. That said, I do think that FOOM is indeed taking on more weird unknown unknowns than average. (There aren’t great reference classes for inner-aligning your successor given that humans failed to align you.) Maybe not that many! Maybe there is a robust characterizable path to FOOM where everything you need to encounter has a well-documented reference class. I’m not sure.
comment by Razied · 2022-04-19T23:53:53.186Z · LW(p) · GW(p)
Hmm, I'm not sure if I understand this correctly, but it appears to me that a sufficiently powerful AI could infer lots of things about long timescales from short episodes. For instance, the mere existence of buildings built by humans imposes very significant restrictions on an AI's model of reality at decades-long timescales. Even pictures could be considered 0-length "episodes", and it's certainly very possible to infer long-range dynamics of humanity from those. Even if you only live 15 minutes, achieving your goals in those 15 minutes could require a detailed understanding of much longer timescales. It appears to me that the problem isn't really about the AI modeling the world at long timescales, but at making plans on those timescales. If you only live 15 minutes you don't need to plan the next year for yourself, but you do need to understand the plans of other agents up to next year (AI: Is Bob likely to release me in the next 7 minutes if I offer him $1 million? Yes, he hates his job and has plans to quit in the next 3 months. I'll have 8 minutes remaining to cool down this google warehouse as much as possible...)
If we're doing model-based AI and there's a MCTS_time_planning_horizon variable or something, then all you need to do to extent the model's planning capabilities beyond the 15 minutes it was trained with is to increase that variable, if it has learned an accurate dynamics model then this will be sufficient, and I think even short episodes encourage accurate long-term dynamics models.
Replies from: tailcalled, not-relevant↑ comment by tailcalled · 2022-04-20T16:52:54.137Z · LW(p) · GW(p)
I agree that you can learn lots of things on long timescales from short-timescale phenomena; that's what I was getting at with the "Compositionality and extrapolation" thing. (If you think the existence of buildings tells the AI something that only shows up on long timescales, then we might disagree, but also in that case I don't know what you are talking about, so you will have to provide an example.)
I think even short episodes encourage accurate long-term dynamics models.
This seems like perhaps the key point of disagreement. I think it encourages accurate long-term dynamics models among the factors that can be observed to vary enough within the episode length, but if some factors are not observable or do not vary (more than infinitesimally), then I don't think short episodes would encourage accurate long-term dynamics models.
Replies from: Razied↑ comment by Razied · 2022-04-20T17:15:43.358Z · LW(p) · GW(p)
Ah, you're right, a specific example of what I'm trying to get at would be much clearer, so here's a chain of reasoning using the existence of buildings that would be useful to a model on short timescales:
- Building exists, which is known from image recognition even on short timescales
- Humans exist, again from image recognition
- Some humans entered the particular building I'm looking at in the past 45 seconds, why?
- Ah, they entered their building for their "jobs", why?
- They appear to have something called "families" to support, objects which rank highly in their value function.
- Manipulating those humans would help me in my goal over the next 15 minutes, perhaps their families would be an effective point of leverage?
- Build model of long-term human family dynamics in order to predict how best to manipulate them, perhaps by threatening to kill their children.
So suddenly the AI is reasoning about families and their dynamics, which are very long-term objects. Buildings are built to last a long time, meaning that you can infer that the agents who built them wish to use them repeatedly, this is a constraint on the long-term dynamics of the environment which is very useful to model. In general in an environment where some agents have value functions which care about long-term effects, it will be instrumentally useful for our short-term agent to model them, and for that it needs to understand the long-term behavior even of those parts of the environment which are not other agents.
Or, for instance, the position of the sun relative to the earth doesn't vary much within a 15-min timeframe, but again you need to understand the day-night cycle to predict humans accurately, even within a short conversation.
Replies from: tailcalled↑ comment by tailcalled · 2022-04-20T17:31:17.643Z · LW(p) · GW(p)
I'm confused about how you expect the AI to be able to answer the "why?" questions.
Replies from: Razied↑ comment by Razied · 2022-04-20T17:52:17.885Z · LW(p) · GW(p)
That would indeed be difficult, maybe by downloading human media and reading stories the AI could infer the jobs -> supporting families link (this wouldn't quite be strategy-stealing, since the AI doesn't plan on having a family itself, just to understand why the human has one). I'm not saying that these long-term dynamics are especially easy to learn if you only have a short time window, what I'm saying is that there is non-zero incentive to learn long-term dynamics even in that case. I'm imagining what a perfect learning algorithm would do if it had to learn from 15 minute episodes (with correspondingly short-term values) starting from the same point in time, and access to video, text, and the internet, and that agent would certainly need to learn a lot about long-term dynamics. Though I completely agree that you'd likely need to achieve very high model competence before it would try to squeeze out the short-term gains of long-term dynamics understanding, and we're not really close to that point right now. In my view extending the episode length is not required for building long-term dynamics models, merely very useful. And of course I agree that the model wouldn't magically start planning for itself beyond the 15 minutes.
Replies from: tailcalled↑ comment by tailcalled · 2022-04-20T21:04:31.219Z · LW(p) · GW(p)
That would indeed be difficult, maybe by downloading human media and reading stories the AI could infer the jobs -> supporting families link (this wouldn't quite be strategy-stealing, since the AI doesn't plan on having a family itself, just to understand why the human has one).
I mean it's the sort of thing I was trying to get at with the strategy-stealing section...
I'm not saying that these long-term dynamics are especially easy to learn if you only have a short time window, what I'm saying is that there is non-zero incentive to learn long-term dynamics even in that case. I'm imagining what a perfect learning algorithm would do if it had to learn from 15 minute episodes (with correspondingly short-term values) starting from the same point in time, and access to video, text, and the internet, and that agent would certainly need to learn a lot about long-term dynamics. Though I completely agree that you'd likely need to achieve very high model competence before it would try to squeeze out the short-term gains of long-term dynamics understanding, and we're not really close to that point right now. In my view extending the episode length is not required for building long-term dynamics models, merely very useful.
I think we might not really disagree, then. Not sure.
The thing about text is that it tends to contain exactly the sorts of high-level information that would usually be latent, so it is probably very useful to learn from.
And of course I agree that the model wouldn't magically start planning for itself beyond the 15 minutes.
I should probably add that I think model timescale and planner timescale are mostly independent variables. You can set a planner to work on a very long timescale in a model that has been trained to be accurate for a very short timescale, or a planner to work on a very short timescale in a model that has been trained to be accurate for a very long timescale. Though I assume you'd get the most bang for your buck by having the timescales be roughly proportional.
↑ comment by Not Relevant (not-relevant) · 2022-04-20T01:33:02.794Z · LW(p) · GW(p)
I do agree with OP that while short episodes teach some aspects of long-term dynamics, it’s not clear that they teach all/enough. E.g. there are empirical learnings required for “being a superhuman company CEO” that will never show up in short episodes, and that seem like they’d require strategy-stealing.
comment by Daniel Kokotajlo (daniel-kokotajlo) · 2022-05-19T18:43:39.010Z · LW(p) · GW(p)
FYI this seems to be roughly the same hypothesis that Ajeya Cotra discusses in her report, under the name of "Horizon Length." Richard Ngo also endorses this hypothesis. I'm glad you are thinking about it, it's probably the biggest crux about timelines and takeoff speeds.
comment by Nathan Helm-Burger (nathan-helm-burger) · 2022-04-20T05:13:59.332Z · LW(p) · GW(p)
I think any AI sufficiently good at world modeling to be much of a threat is also going to be quite good at learning from abstractions made from others. In other words, it can just read a history book to figure out about political change, it doesn't need years of 'personal' experience. It's pretty standard to give models access to training data encompassing a ton of detail about the world nowadays. Just because they currently don't grok the physics textbooks, medical papers, and wikipedia entries doesn't mean that that limitation will remain true.
Replies from: tailcalled↑ comment by tailcalled · 2022-04-20T16:40:08.970Z · LW(p) · GW(p)
I agree that there is a strong incentive towards making AI capable of understanding these things. The interesting question is going to be, how quickly will that succeed, and what will the properties of the kinds of models that succeed in this be?
comment by Not Relevant (not-relevant) · 2022-04-19T22:18:57.715Z · LW(p) · GW(p)
I generally agree that this is a future bottleneck, and similarly the Cotra bio-anchors report emphasizes "how long are training episodes" as arguably the second most important dominating factor of timelines (after "do you believe in bio-anchors").
I tend to expect both (1) and (2) to partially hold. In particular, while humans/humanity are not fully observable, there are a lot of approximations that make it kind of observable. But I do generally think that "do a bunch of sociology/microeconomics/Anders-Sandberg-style futurism research" is an often-unmentioned component of any deceptive FOOM scenario.
That said, "make copies of yourself to avoid shut off" is a convergent instrumental goal that shows up even in fairly short episode lengths, and the solution (hack your way out into the internet and then figure out your next steps) is plausibly implementable in 15 minutes. I think this is a better counterargument for like, 3-minute episodes, which seems like self-driving car range.
Replies from: tailcalled↑ comment by tailcalled · 2022-04-20T16:41:17.927Z · LW(p) · GW(p)
I agree with all of this.