Buckets & Bayes
post by Duncan Sabien (Deactivated) (Duncan_Sabien) · 2021-12-20T05:54:37.450Z · LW · GW · 0 commentsContents
Bayes for Bucket Errors None No comments
Author's note: this essay was originally published pseudonymously in 2017. It's now being permanently rehosted at this link. I'll be rehosting a small number of other upper-quintile essays from that era over the coming weeks.
I once had a conversation with a couple of the cofounders of the Center for Applied Rationality (Anna Salamon and Val Smith) in which they told me that early attempts to create useful, sticky CFAR classes almost always failed when they were centered around a single concept or technique.
However, the instructors quickly learned that combining two or more classes—even if both of them were falling flat on their own—often produced results that were surprising and memorable. For instance, both the “inner simulator” class (which tried to draw people’s attention to the fact that they had an implicit world simulator that was constantly aggregating data, and which they could query for useful information) and the “professions versus anticipations” class (that was meant to distinguish between S2 predictions and S1 predictions) were falling flat until they were combined into the “Murphyjitsu” technique, which is popular enough that the first six Google results are all CFAR alumni explaining and recommending it.
This rhymes with a Paul Graham insight that LessWrong user jacobjacob left as a comment on a post:
“He claims that the most valuable insights are both general and surprising, but that those insights are very hard to find. So instead one is often better off searching for surprising takes on established general ideas [such as drawing a link between Thing A and Very Different Thing B].”
I buy what I see as the combined claim pretty hard. It matches with my experience of analogy and metaphor being among the most powerful teaching tools, and with the idea of cross-domain renaissance nature being something that emerges from generalizing and translating specific skill into broad competence. So today, I’m going to try to act on that claim, and do my best to synthesize the highly-useful-but-often-unsticky concept of Bayesian updating with Anna Salamon’s highly-sticky-but-often-hard-to-operationalize concept of bucket errors.
(The rest of this post will assume zero familiarity with either concept and be very 101, so if you’re likely to find that boring, please skim or skip. Also, it’s going to be formatted as a ~30min tutorial, which means that you shouldn’t expect to get a ton of value from it unless you actually try playing along.)
All right, first things first. I want to present a set of widely-spaced examples (some of them lifted directly from Anna’s original post) and then try to highlight what they have in common. Read the following vignettes, and see if anything in them resonates with your experience, either of yourself or of people you have seen around you:
- Kieran shows up at work dressed in new clothes. Lex smiles as Kieran walks in, and says that the outfit is awesome, and that Kieran looks great. Kieran smiles back and is clearly experiencing some significant warm-fuzzies as a result of the compliment. Later, though, Jesse walks into the office, looks over at Kieran, and makes a squidge-face. “What’s that about?” Kieran asks. “What? Oh—nothing,” Jesse says, and changes the subject. Kieran doesn’t press the issue, but is also obviously experiencing something in the triangle of panic-anxiety-doubt and seems to be more derailed than one would expect by what was really just a flickering expression on Jesse’s face.
- Bryce is a median EA-aligned student—moderately liberal, interested in evidence-based policy, concerned with reducing suffering, taking a mix of technical and nontechnical classes, and trying to figure out how best to balance personal satisfaction and overall impact after graduation. Bryce’s friend Courtney has recently been reading a lot about existential risk, and keeps trying to engage Bryce in conversation about new ideas and open questions in that sphere. However, Bryce keeps shutting Courtney down, loudly insisting that the whole topic is just a Pascal’s mugging and that it’s not worth the time that would be wasted going around in circles with unfalsifiable hypotheticals.
- Quinn has recently made progress in disentangling and understanding the dynamics behind a large, sticky bug that has previously been immune to change. Quinn now has a plan that it seems reasonable to be confident and optimistic about. However, Quinn’s friends keep coming up with advice and suggestions and thinly-veiled probes, recommending that Quinn read this-or-that and talk to such-and-such and look into trying X, Y, or Z. It’s been going on for a while, now, and Quinn is starting to get a hair-trigger around the topic—it’s as if Quinn’s friends aren’t taking into account the fact that Quinn has a plan, it just hasn’t gotten off the ground yet. There’s just some scheduling stuff in the way—a few prior commitments that need to be wrapped up and some prep work that needs to be done, that’s all.
- Dana has been living at a magnet high school for almost a year now, and the experience has been almost uniformly terrible—Dana’s homesick, sleep deprived, overburdened with homework, unhappy with the food, uncomfortable with the dorm, uncertain about the focus of the curriculum, dissatisfied with the quality of the instruction, not really clicking with any of the other students socially, and on and on and on. It’s gotten to the point that Dana’s even feeling anger and frustration at the buildings themselves. Yet when Dana’s parents try to offer up the option of dropping out and returning back to regular high school, Dana snaps and cuts them off. They don’t seem to understand that this would be a capitulation, a defeat—there’s no way Dana’s going to let this shithole win.
- Parker has been feeling the lack of … something … for years, and may have finally found it in a local worship group run by a fellow member of the local biking club. The services are on Wednesdays and Sundays, and Parker has been blown away by the sense of community, the clear moral framework, the sensible pragmatism, the number and quality of activities, the intellectually challenging discussions—all of it. It completely subverted Parker’s stereotypes of religious groups being willfully ignorant and anti-progressive and reliant on authoritarian hierarchies, and it’s even been epistemically interesting—because Parker and the pastor are friends, they’ve been able to have several long, late-night conversations where they’ve talked openly about faith versus evidence and the complex historical record of Christianity and the priors on various explanations of reported miracles and the cases for different moral frameworks and the contrasts and comparisons between Christianity and other religions. All in all, Parker’s experienced a significant uptick in happiness and satisfaction over the past six months, and has even made a marginal (~10%) update toward formal conversion. Parker’s sibling Whitney, though, is horrified—Whitney’s model of Parker was that of a staunch and unwavering atheist, and, confused and dismayed, Whitney keeps aggressively pressing for Parker to explain the cruxes and reasons behind the recent shift. Parker is strangely reluctant, sometimes skirting around the issue and other times avoiding Whitney outright.
Okay. Before I draw the through-line, it may be worth pausing to check and see whether any theories about the common link have already occurred to you, or whether any of these sparked anything in your own memory or experience. Often it’s easier to think critically about a claim if you’ve formed your own lightly-held impression first, so take a moment to see whether anything occurs to you now.
(If not, no worries; I’ll ask again at the end of this section.)
If something has popped into your head—if there’s a situation you’re remembering or currently stuck in that rhymes with one or more of the above, please take a moment to summarize it in actual words and complete sentences (either aloud or written down) as in the examples above; I’ve found there’s a big difference between one’s visceral sense of a situation, and one’s actual, accessible, comprehensible description of that situation.
Okay, onward.
What these stories all have in common (according to me) is that they all center around a problematic integration of evidence. There is data coming in that, if it were allowed to land according to normal operating procedures, would force some kind of drastic and possibly destructive update.
And so in response, some subconscious mechanism in these people’s brains is hitting the brakes. Throwing up a stop sign. Plugging its ears and going lalalalalalala. It’s vaguely reminiscent of the dragon in the garage—on some level, these people know exactly what information must be dodged, and are remarkably canny in successfully dodging it. But it’s not exactly a conscious or deliberate mental motion—they’re not doing it on purpose.
It’s important to pump very strongly against the tendency to write this off as stupidity or hypocrisy or obstinance. I’m sure it is in some rare cases, but in my experience (and in all of the carefully constructed examples above) it’s actually adaptive for the information to be deflected or fended off.
What’s going on is, there’s a real, unsolved problem with the person’s evidence-sorting system. This is the “bucket error” that Anna describes—there’s an entanglement between the situation at hand and some larger set of beliefs about oneself or the universe, and thus new data is at risk of being double-counted in ways that are simultaneously unjustified and unhelpful.
And the rejection-of-that-data is a patch. It’s a reflexive, self-protective measure that’s probably not the best way to deal with the problem, but is at least sufficient. Without really being aware of what their brains are doing, the people involved are sacrificing some clarity of sight to prevent themselves from making a very very wrong sort of update that could have a lot of negative externalities:
- Whether because of Lex’s comment or just because of Kieran’s baseline beliefs and habits-of-mind, a connection has been established between the question “is my outfit good?” and “am I good?” The data for both questions is landing in the same bucket, and both questions sort of have to have the same answer at all times as a result. So Jesse’s fleeting disapproval is threatening to undermine, not just Kieran’s fashion sense, but Kieran’s sense of self-worth overall. This is obviously both unsound and unhelpful, and so some safety algorithm is throwing up a RED ALERT until the sorting system can be improved.
- Similarly, Bryce is the sort of person who’s vulnerable to Hufflepuff traps—once Bryce becomes aware of a single dominant moral option, they’re compelled by their morality to try to take it, even at large or unbounded cost. So some part of Bryce needs to not hear Courtney’s arguments, because Bryce is not yet equipped to hold the simultaneous (possible) truths that yes, existential risk is real and the most pressing cause, and also Bryce need not sacrifice all other goals and values at that particular altar. There is a more nuanced strategy out there that maximizes area under the curve in the long term (as opposed to just giving your all and then burning out), but Bryce doesn’t have that strategy in their toolkit yet, so to protect the whole system in the meantime, a watchful subroutine has thrown up a RED ALERT.
- Quinn has a plan. The plan is good. The plan will work—if it doesn’t, then maybe Quinn’s only appropriate and allowed move is to sink into despair, because none of the other plans have worked, either. And yet Quinn’s friends keep tossing all this other advice into the ring, and whether they’re aware of it or not, all of this advice that is Not Part Of The Plan is sort of an oblique criticism of the plan. If the best move is something other than Step One Of The Plan, then maybe that means the plan is bad, which means it won’t work, which means that Quinn is doomed, or is bad at coming up with plans, or can’t solve problems alone and self-sufficiently without outside help, or some other terrible global conclusion. RED ALERT.
- The thing about Dana is, Dana’s better than this school. Dana’s better than its shitty curriculum, and its awful teachers, and its unreasonable homework policies, and its smug, self-satisfied, and un-self-aware students. Sure, leaving would solve 100% of the object problems. But why can’t Dana’s parents see that it would also mean letting go of every scrap of taste, discernment, and self-worth that Dana has? If Dana leaves, that means the world is such that the righteous do not win. They don’t get the happy endings that they deserve, and the universe is not just, and that’s just … too big for Dana to handle, as a stressed-out high schooler. There’s time for integrating all that later—for now, RED ALERT.
- Sure, the question of the existence of God and the truth or falsehood of Christianity is important. Parker never said it wasn’t important—in fact, Parker’s been taking it very seriously, and is in fact engaging with it exactly as a rational thinker should! What Whitney doesn’t understand is that insisting that the question of religion come first is putting Parker in a position of having to choose between epistemic hygiene on the one hand, and all of the object-level improvements of quality-of-life that have come from being an active part of this church on the other. From Parker’s perspective, one can’t be a committed atheist and also reap all of these benefits from associating with the faithful; that would be some strange form of cheating. Therefore arguments about the non-existence of God threaten a large swath of otherwise-unrelated value, but it’s hard enough to notice that consciously and even harder to express it in words that Whitney will understand and accept and so the only viable response is RED ALERT.
In my opinion, this is a good thing, once we condition on the fact that these people actually do not have a better strategy available.
(By the way, “conditioning on” is a technical term relevant to the later discussion of Bayes; all it means is “out of all the possibilities, let’s look at a particular subset, and only that subset.” So by “condition on” the fact that they don’t have a better strategy, I mean really take it seriously, and temporarily set aside your doubts and suspicions that some other thing is true, and live in the world where we’re 100% sure that it’s not laziness or stupidity or hypocrisy or any other thing. It’s sort of like a “for the sake of argument” move.)
Sure, a straw Less Wronger or Facebook troll could pooh-pooh the bind they’re in, and say “come on, just think more clearly, gosh,” but this handwaves away [LW · GW] a lot of the extra education and emotional resources and raw intelligence that said straw critic is privileged with. If you take seriously the current state of these people’s evidence-collection systems—the deficient number of buckets they have available to “catch” evidence, and the entanglements those buckets represent—then having this knee-jerk fail-safe to prevent large FAE-ish updates sounds super important and valuable.
If you didn’t have resonant examples before, take a moment to scan through your memory now. Are there places where you’ve felt caught in this same bind? Perhaps you didn’t express it to yourself as a bucket error at the time—perhaps instead you just noticed yourself reacting surprisingly strongly to attempts to give you new information, pushing people away or ramping up into defensiveness. Or perhaps you were unusually disinterested, declaring that new information obviously irrelevant and not worth attending to, even though people whose judgment you trust thought otherwise. Or maybe you just—couldn’t think about it, and your mind kept sliding off.
Got one?
Cool. Hang onto it, we’ll come back to it after the next section.
This is going to feel like a bit of a detour, but I want to talk about parallel universes for a second.
Parallel universes are great, because they’re a solid intuition pump for conflicting models or explanations of our universe. There’s an isomorphism between “let me imagine the parallel universe where Steve is a jerk versus the one where he’s genuinely trying to help and just bad at social stuff” and “I’m not sure how to interpret that thing that Steve just did — it could be evidence of fundamental jerkishness or it could be evidence of social clumsiness,” and for a lot of people the former is easier to imagine than “maybe I’m wrong about my prior assessment of Steve’s character.” It’s a distancing move that can loosen up strong preconceptions and short-circuit unhelpful emotional feedback loops.
So the first thing I’d like you to do is visualize a specific, real person that you know (if you don’t use visual imagery, just do whatever it is you do when you read books). This shouldn’t be someone super close to you, like a best friend or an arch-nemesis—just someone you know moderately well, like a coworker or a classmate or someone from your gym/dojo/studio.
Now what I’d like you to do is imagine that person standing in front of you [LW · GW], and imagine their eyes drifting up to look above your forehead, and imagine them giving a slight-but-genuine-seeming smile, and imagine them saying “Your hair looks cool today!”
(waits patiently while you actually do this)
All right. Now what I’d like for you to do is imagine a handful of parallel universes that are all consistent with both a) your prior experiences of this person and b) the statement about your hair.
Maybe there’s a universe where they’re an excellent judge of style and fashion and also totally candid, and so what they just told you is pretty much an accurate reflection of the state of things.
Maybe there’s a universe in which they’re a sneaky Machiavellian mastermind, and every action they take around you is carefully curated to produce a particular set of reactions and outcomes, and the question of whether your hair actually looks cool or not is somewhat unrelated to the question of how they think you’ll act if you think your hair looks cool.
Maybe they have a SECRET CRUSH on you, and they would’ve said anything just to have an excuse to exchange a few words with you, and who knows—they probably do think your hair looks cool, but they’re not a very good judge because they think everything about you looks cool, even your jorts.
Maybe they forgot their glasses, and they literally can’t see, and they’re just saying polite stuff essentially at random.
The point is, there should be at least two viable explanations (and possibly a handful, or dozens) that fit with your model of this person and with your observation that they said “cool hair.” In particular, there should be at least one explanation that seems consistent and coherent in which you do have cool hair, and at least one in which you don’t.
(We’re going to zero in on the question of “cool hair: true or false?” for simplicity’s sake, because it’s easier when you reduce the number of variables you have to juggle. We could just as easily have done a similar investigation on “friend: competent fashion judge?” or “friend: honest and candid?” In reality, of course, all of these questions are up in the air at once as we simultaneously use past data to predict present/near future data, and also use present data to update models formed from past data.)
The key realization here is that any bit of evidence (such as your friend saying “cool hair”) is evidence for more than one hypothesis. Most of the time, most people have a single model for any given situation, and they hold up every piece of new evidence against that model, and if it’s not actively contradictory, they take that as incremental confirmation that their model is correct (cf. confirmation bias).
But this leaves out the fact that it’s consistent and coherent to imagine your friend saying “cool hair” in both universes where your hair is cool and in universes where it isn’t. If I only ask myself “does this fit with a world where my hair really is cool?” and I forget to also ask “does this fit with a world where my hair isn’t cool?” then I’ll be drawing lopsided and inaccurate confidence from my observations. It’s sort of like asking yourself “can I easily imagine this plan working?” and forgetting to ask “can I also easily imagine this plan not working?”
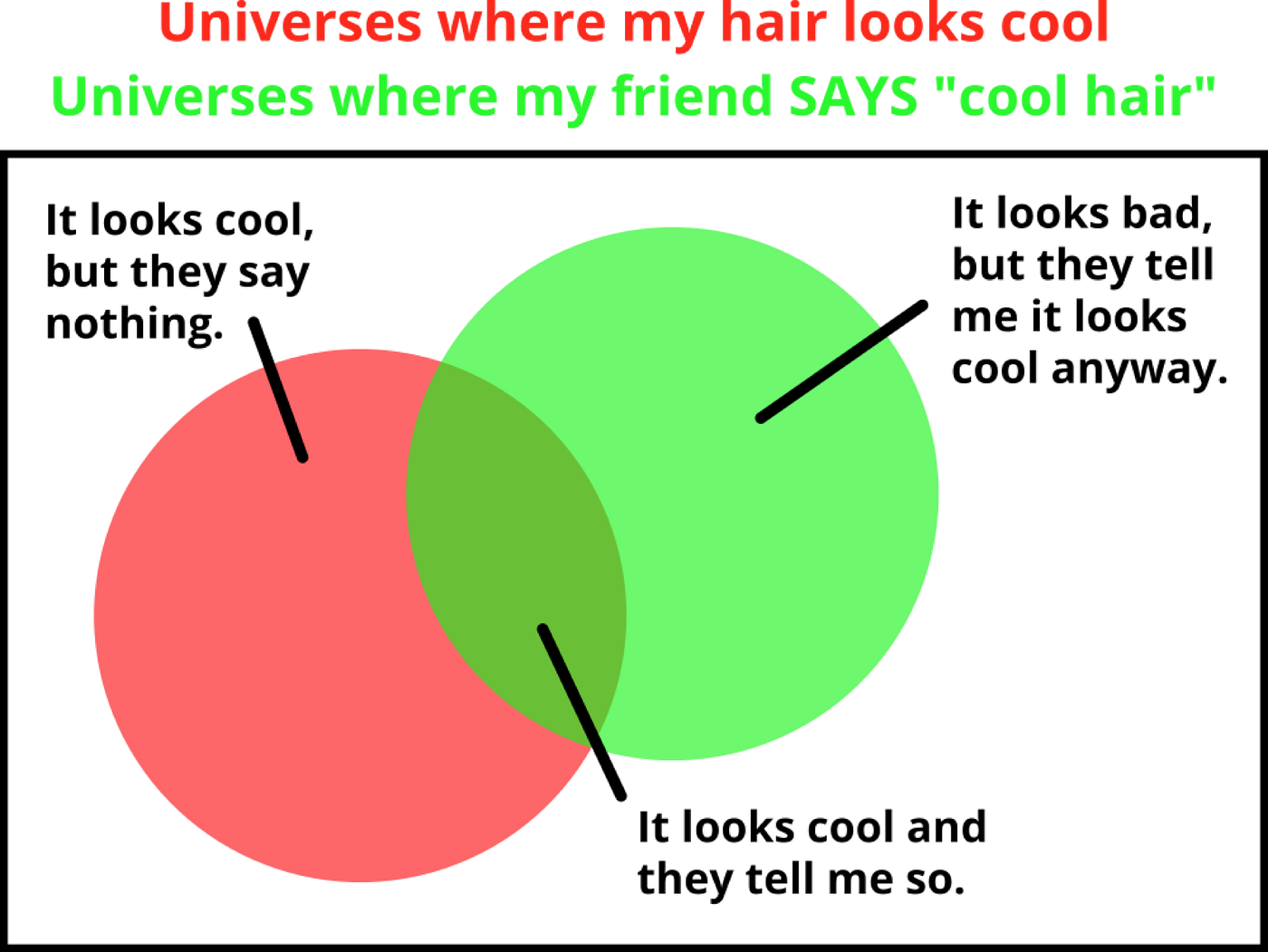
What we really would like to do is know how much to update on a given bit of evidence. If I had a prior confidence of 25% that my hair looks cool, and then somebody said “cool hair,” I’d end up with very different posterior confidences depending on whether the person saying it was my mother, or my romantic partner, or a stranger on the street, or Regina George from Mean Girls.
Put another way, the evidence increases my sense that my hair looks cool, but it also increases my sense that my-hair-looks-uncool-but-something-else-is-going-on, and it helps to know how much of the strength of this evidence goes to each side—to know which side it’s better evidence for, and by how much.
(Hopefully this makes sense—it’s like when you have an idea that you’re reasonably sure is good, but then that guy chimes in with an enthusiastic endorsement, and you experience this sinking sensation of doom, because if that guy thinks it’s a good idea then you must have really screwed up somewhere along the way …)
The way to figure this out is to look at how all of your different priors interact. You have a baseline sense of how likely it is that your hair is cool today, and you have a baseline sense of how likely your friend is to compliment it, and you have a sense of how likely that compliment is to be informative (how competent+candid your friend is), and you can arrange all of that into a mental picture like the one below:
(There’s a mathematical formula for doing this sort of reasoning, called Bayes’ theorem, but while it’s fairly easy to use, I find that I get most of the value out of the intuitive, nonmathematical version anyway, so we’re going to proceed in that vein.)
By looking at the graph, we can see that it’s something like 20% likely that you have cool hair (since the red circle takes up ~20% of the total possibility space). We can also see that it’s something like 20% likely that your friend will say you have cool hair (since the green circle is also ~20% of the space). And we can see that your friend is not a very reliable source of information, since most of the times they offer you the compliment, your hair isn’t cool.
Of course, that was all before you actually received the compliment—those were our priors based on past experiences. Once you do receive the compliment, you can throw away everything outside of the green circle—you’re definitely in one of the universes where your friend said “cool hair,” and now what you want to know is, given that they offered the compliment, how likely is it to be true?
And in this case, conditioning on the fact that you do receive the compliment …

… well, not much has changed, really. Given that particular arrangement of prior beliefs, having heard from your friend basically means nothing, because it still looks like you have cool hair in maybe 20–25% of the possible branches (your posterior belief). The only real update here is that your friend’s evidence is actually useless on this question.
But that’s not always going to be the case. Take five or ten seconds to look at each of the graphs below, and turn them into a visceral understanding or a verbal model of the situations they represent:

… for instance, in the bottom left graph, we can see that you’re something like 45% likely to have cool hair, and your friend is less than 10% likely to say so, but also they’re a good source of information more often than not. And in the bottom right graph, we can see that you have cool hair 10 or 15% of the time, but that your friend compliments you maybe 3% of the time, and not very diagnostically.
(For me, when I look at these graphs, especially the size and overlap of the green circle, they often evoke very specific people whose interpersonal dynamic with me matches what’s on the screen. I really really like both the top left and the middle left people, because they give me really accurate information—it’s just that one of them always says the opposite of what’s true.)
What’s interesting, though, is just how much receiving that compliment can change our confidence, sometimes drastically increasing or decreasing it. Take the graphs above and throw away all but the green circles, such that instead of comparing red-to-white you’re now comparing dark-green-overlap-to-light-green-non-overlap, and you get a very different story in many cases:
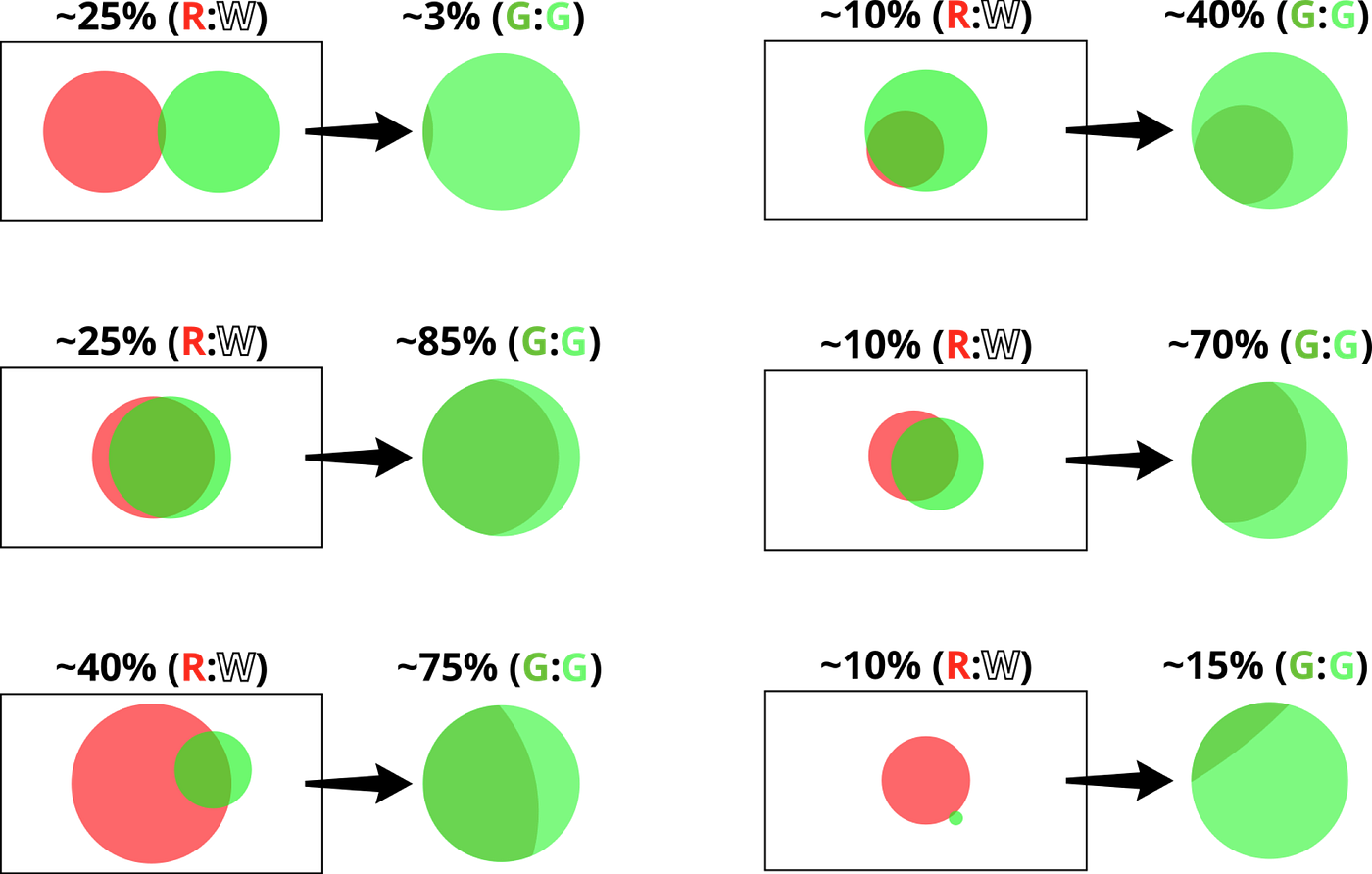
The pictures don’t actually tell you anything new; you already had all of the information about how good you are at coiffery and how reliable your friend’s compliments are and so forth. But by taking a moment to process it—to think deliberately and carefully about the relationships between these pieces of information—you can get a much clearer sense of what the new data really means and how you should act in response, rather than just blindly updating toward confidence in your first hypothesis.
One of the classic examples of this comes from medicine, where young and inexperienced medical interns will often encounter a symptom that is highly [typical and representative] of some vanishingly rare and exotic disease, and immediately promote that diagnosis to the forefront of their attention and start tests or treatment.
The problem is, often the symptom is also something like a rare but not unheard-of side effect of having a common cold, showing up in maybe 1% of cases. Which means that, even though you don’t think “common cold” when you see it, there are so many people with colds that the overwhelming majority of the time you do see this weird symptom, it’ll be because of a cold and not because of the rare disease. Hence, the advice “when you hear hooves, think horses, not zebras.”
Time to tie it all together.
You’ve got your maybe-a-bucket-error situation booted up, right?
Here’s the claim: Bayesian reasoning is a possible cure for your bucket error. Or, more precisely, a person who engages in regular and adroit application of Bayesian reasoning will be less prone to bucket errors in the first place and also better equipped to notice, catch, and repair them.
Remember that I’m claiming the bucket error comes from a miscategorization of evidence—in particular, it comes from dropping evidence about Thing A into a bucket that also contains Thing B, and then interpreting that evidence as 100% relevant to Thing B. This is as if you were to treat your friend’s claim about your hair as 100% accurate evidence of your hair’s coolness, which is of course preposterous even if your friend is a professional fashionista.
Informal Bayesian reasoning like that laid out above is helpful in two ways. First, it requires as a matter of course that you form at least two opposing hypotheses (actually usually exactly two, though you could do something complex and multi-step to handle an intricate situation).
That means that a trigger to do a quick Bayes check is also a trigger to break you out of a confirmation-biased loop on something like “but that means they hate me.” It snaps you out of it, causing you to bother to remember to check “or it could mean that they don’t hate me, and there’s something else going on.” This all by itself is a powerful tool, and saying to oneself “I should do this because I’ve heard Bayes is a useful lens” is more likely to be motivating (or less likely to meet internal resistance) than just saying to oneself “I’m going to make myself think about a wrong and false possibility, now, because outside view says I’m stuck in a rut even though I’m right.”
And second, using this process helps turn your attention toward the strength (or lack thereof) of the correlation between observation and conclusion. Like stopping to ask, “hey, wait, are my friend’s compliments usually true,” checking to see whether Jesse’s expressions are meaningfully correlated with Kieran’s self-worth or whether Whitney’s theological arguments are causally linked to Parker’s ability to keep participating in the biweekly church potluck usually produces a no, not really, followed by an increase in resolution on what they are evidence of (and an increase in resolution on what would be evidence relevant to that larger question).
So take a moment now, please, and read through the following questions, which represent the sort of proto-algorithmic “techniquelet” that I’m recommending:
Bayes for Bucket Errors
0. Do I have five minutes (and the corresponding mental energy reserves) to take a real shot at answering questions 1-4, or am I leaving this in the realm of the hypothetical for today?
1. What’s the situation I’m in, that I think might involve a bucket error? How would I describe it in a single paragraph summary? (Step 0 would have been to notice you’re in the dynamic in the first place, possibly by keying off of sudden and repeated frustrations, or strong emotions that you later felt were disproportionate, or desire-to-avoid a certain person or topic.) Note that this is a tricky step, often fraught with heavy emotion, and can often be helped by distancing (e.g. imagine it’s someone else’s problem, and describe it “from the outside”) or getting help from a friend with high EQ who’s good at the rubber ducking skill, or some other thing that increases slack and safety.
2. What’s the null hypothesis—the “my hair doesn’t look cool” option? Put another way, what are the two competing parallel universes, with opposite dynamics going on? I’m scared that I’ll find out X—but what’s not-X?
3. What’s my sense of how correlated or diagnostic or relevant the information coming in really is to the important question? On reflection, do I genuinely believe that e.g. quitting this school means something enduring and extrapolate-able about my character, or that the truth value of the ex-risk question contains information about actions I absolutely must take?
4. Having now done a bit of background Bayesian reasoning (probably just looking carefully at what my priors already were, but also possibly having sketched out a posterior to see how things would change, conditioned on receiving the information I’ve been scared to receive), what new buckets have I now magically acquired, for receiving and interpreting similar information in the future?
I claim that this rough process highlights next actions that will work even on examples like Anna’s original child-writer (who can’t let themselves discover that they’ve misspelled the word “ocean” lest they conclude that they can never succeed at writing). Often, people trying to help this child will sort of miss the point, either trying to be generically soothing or generically stern or leaping to conclusions about the kid’s emotional maturity or stick-to-it-iveness.
But in fact, it’s just that the kid is getting a wrong answer on question 3. They’ve never seen mistakes in the examples that their parents and teachers have venerated, and so for all they know it’s actually reasonable to hypothesize that spelling errors spell D-O-O-M.
To correct the problem, show them examples of your own writing, complete with misspellings; show them a typo in a real-life book; show them a quote from their favorite author about how they make mistakes in their first draft and rewrite over and over and over again. Get them to relax about the degree to which a misspelling is meaningful to their overall competence and potential—and do it by using real evidence rather than just shouting at them that they should—and then they can stop RED ALERT-ing and receive what you’re trying to tell them in a non-destructive way.
(That’s just one step in the process I’m recommending, of course, but the kid is six or whatever. Let them hold off on actual Bayesian calculations until second grade.)
There’s some significant handwaving here (for instance, how does step 3 magically cause buckets to appear?), but for the most part, it’s not intended to be a complete algorithm. I’m more laying out a set of threads to pull on and some guiding lights to head toward. If this does seem like the beginning glimmers of a useful technique, what steps and substeps and prereqs are missing? And if it doesn’t, where would you go instead?
Further reading: Split and Commit [LW · GW]
0 comments
Comments sorted by top scores.