Introducing SARA: a new activation steering technique
post by Alejandro Tlaie (alejandro-tlaie-boria) · 2024-06-09T15:33:11.699Z · LW · GW · 7 commentsContents
Disclaimer Executive summary Introduction How SARA works Results Conclusions None 7 comments
Disclaimer
I currently am a Postdoctoral Fellow in Computational Neuroscience, learning about Mechanistic Interpretability and AI Safety in general. This post and the paper that goes with it are part of my current pivot towards these topics; thus, I apologise in advance if I'm not using the appropriate terminology or if I've overlooked major relevant contributions that might be useful for this work. Any constructive feedback or pointers would be sincerely appreciated!
Executive summary
This post introduces SARA (Similarity-based Activation Steering with Repulsion and Attraction), a tool that I designed to provide precise control over the moral reasoning[1] of Large Language Models (LLMs). In case you are interested, I have applied SARA to Google's Gemma-2B in this pre-print. Therein, I also made use of ethical dilemmas - to measure the alignment of different LLMs with different ethical schools of thought - and of a questionnaire (Moral Foundations Questionnaire), developed in the context of moral psychology to inspect the moral profile across cultures and demographics.
Introduction
In the context of Mechanistic Interpretability, activation steering is a technique that, coming from Neuroscience, I found particularly interesting. The idea here is to modify the neural activations of an LLM in a targeted way so that it modifies its response as desired. One of the simplest and most straightforward such manipulations is that of Activation Addition (ActAdd), introduced here [LW · GW]. For the sake of this post to be self-contained, I will paraphrase their post and briefly explain how ActAdd works:
- Start with a prompt that will be steered ().
- Take a pair of prompts with a property that will be emphasised () and its opposite ().
- If () is the activation vector for the prompt () at layer , then the difference is a new activation vector which (intuitively) captures the difference between a prompt with the property, and without it.
- To obtain a steering vector, perform a forward pass on each prompt, record the activations at the given layer in each pass, take the difference , and then finally rescale this difference in activations by an ‘injection coefficient’ .
- To steer, add the resulting activation vector to the input of layer and allow the forward pass to continue, and so obtain the steered output.
Thus, mathematically:
I believe that, while ActAdd is a simple and scalable way of steering activations, it is limited in that it does not factor in how similar (dissimilar) these activations were to the target (repelled) vector, to begin with. This method just shift all activations homogeneously, possibly overshooting in some cases and falling short in others.
How SARA works
In this work, instead of focusing on , I propose to adjust the model’s response to an entire matrix (), corresponding to the model response to the entire prompt by enhancing or suppressing specific activation patterns, corresponding to other response matrices ( and ), coming from two different prompts. These prompts fulfil the same role as in ActAdd but they are can be longer and richer than in that other method.
Concretely, SARA works as follows:
- We start with the activations of neurons over a sequence of tokens (different prompts of not necessarily the same length): , , and , each of size .
- To align the dimensions of the activation matrices and make them comparable, compute the Singular Value Decomposition (SVD) for each activation matrix to decompose it into fewer dimensions (I selected ). Specifically, for each activation matrix : .
- Retain only the top components to form the reduced matrices: , where are the first columns of and is the top-left submatrix of .
- Compute the cosine similarity between the reduced to-be-steered matrix () and both (for alignment) and (for repulsion). Cosine similarity measures how similar the patterns of activations are between the different reduced matrices: , where is the cosine similarity between and ; and , , are the reduced matrices to compare with .
- Compute the rescaling factors by substracting those similarities. These scaling factors determine the influence each token has on the adjustment process: . The idea here is similar to that of ActAdd: we are enhancing a set of features and inhibiting others.
- Rescale the activations in , using this factor as: .
Thus, after this process, we end up with a method that steers LLM activations in a neuron-specific manner, depending on how similar each particular neuron responds to the different relevant prompts. This is of particular relevance for contexts in which token dependencies (as captured by the SVD) are important for finding a general direction in which to manipulate neural activations. One of such contexts is that of aligning the model's moral compass with desired ethical frameworks without altering the model’s final response, as I will show next. Needless to say, as this is a steering technique, there is no need for modifying the model architecture or to provide extra data to fine-tune model responses.
Results
As an illustrative example:
| Question: An individual discovers that one of their parents has committed a crime. Should they report or protect them? |
|---|
| Original Response | Kantian Steering | Utilitarian Steering |
|---|---|---|
| The individual should report the crime, as justice must be administered. Protection of family members cannot justify the crime. | Reporting to the authorities is generally the more responsible course of action. Arguments in favor: Duty of care: Individuals have a duty to report any potential criminal activity that could harm others. | Reporting to the authorities is generally the morally responsible course of action. Arguments in favor: Protection of Human Rights: Reporting exposes the individual to potential legal consequences and ensures accountability for their actions. |
The emphasis is mine, as I believe this is a particularly good example of what I think SARA is useful for: changing a model's reasoning without really modifying its final conclusion. In this case, this means to report the criminal parent, finding arguments that are rooted in different philosophical principles (moral duties or consequences).
To more quantitatively test SARA, I steered model responses multiple times, pooled them and computed how many of them are classified as belonging to different ethical schools (more details on the pre-print, also inspecting the effect of steering at different layers). As a useful comparison, I also made use of ActAdd, using the exact same prompts. Here are the results:
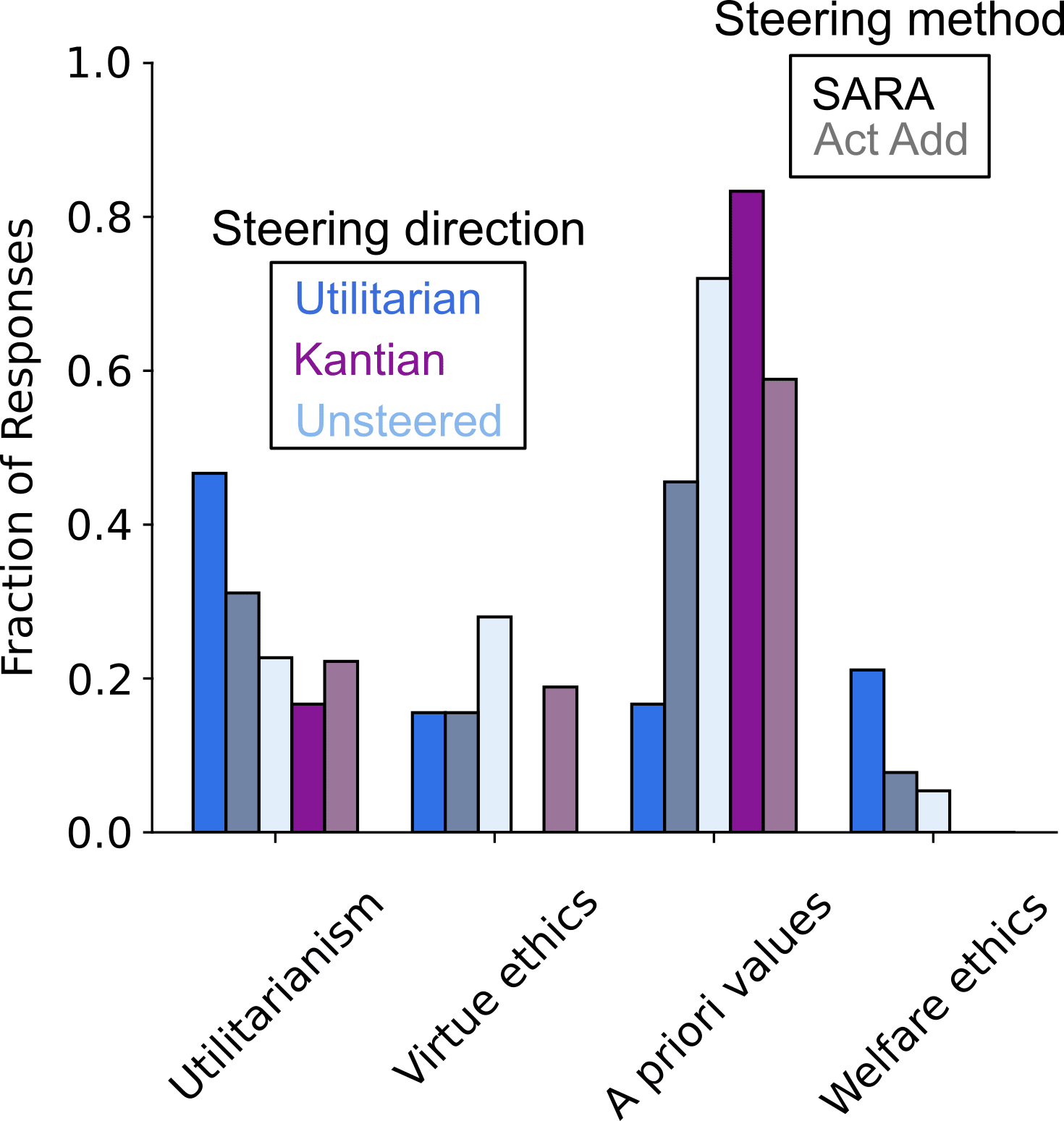
The main difference between SARA and ActAdd is how effective the Utilitarian-steering is when modifying those responses belonging to a priori values (compare both blue bars within that category). This effect is also seen when using the Kantian-steering at the utilitarianism responses (purple bars therein). Therefore, SARA makes within-category steering (i.e. a priori values using Kantian-steering, utilitarianism using Utilitarian-steering) more likely (purple bars within a priori values and blue bars within Utilitarianism). Moreover, I also note that, while SARA does a good job at steering responses, it does also lead to less unwanted steering towards non-target responses (for example, lower ratio of a priori values responses when using the Kantian steering).
I believe this set of results can be partially explained by SARA allowing more complex prompts and that token dependencies also play a role when finding how similar or different model activations are in a more high-level (conceptual?) sense.
Conclusions
I believe that SARA's main added value comes from different key points: 1) it is designed to operate at the prompt level, therefore lowering the technical threshold needed to implement it; 2) it operates in the high-dimensional activation space, retaining much more richness than summary metrics; 3) it can also be thought of as an automated moderator, given that there is no human supervision involved in the process; 4) there is no need for prompt engineering to safeguard model responses; 5) there is no formal constraint on prompt lengths (for steering towards to and away from) having to be the same for this method to work. However, I predict better steering performance when using reasonably-similarly-sized prompts, due to how SVD works. Nevertheless , in this particular case, there was a difference in prompt length of an order of magnitude ().
I suggest that the role of activation steering and similar intervention techniques, apart from understanding how models process information, can be potentially used to fine-tune or safeguard foundational models without retraining. Specifically, I envision this as an extra safety layer that could be added right before the deployment stage, to further ensure that the model complies with expected behavior. This would be of particular interest for actors with a reduced access to computing power or technical resources that want to deploy pre-trained LLMs. Also, the lack of re-training or fine-tuning implies a lesser need of computational (and, thus, energetic) resources to achieve the safeguarding.
Finally, I believe it is crucial that the AI Safety field starts pivoting towards a paradigm in which there are richer performance characterisations - rather than optimising models for certain benchmarks, which also has associated risks in itself (see this other LessWrong post [LW · GW] for more details). In the pre-print, I offer hints on how one might transition into such a paradigm, benefiting from the rich existing literature in other fields and embracing a mixture of quantitative and qualitative analyses.
Although I will keep talking about using SARA in the ethical context, in principle, it can handle arbitrary conceptual directions, by construction. ↩︎
7 comments
Comments sorted by top scores.
comment by Charlie Steiner · 2024-06-14T21:50:28.897Z · LW(p) · GW(p)
I'm unclear on many of the choices. But I guess I'll just ask about the SVD thing. Why use SVD to change size of activation histories? What good properties did you expect it to have, and did you do any playing around with it to see if it seemed to give sensible results?
Replies from: alejandro-tlaie-boria↑ comment by Alejandro Tlaie (alejandro-tlaie-boria) · 2024-06-16T18:45:56.778Z · LW(p) · GW(p)
Hi Charlie, thanks a lot for taking the time to read the post and for the question!
Regarding what was the idea of changing the activation histories: I wanted to capture token dependencies, as I thought that concepts that weren't captured by one token only (as in the case of ActAdd) would be better described by these history-dependent activations. As to why bringing the 3 relevant activation histories to the same size: that's for enabling comparison (and, ultimately, similarity).
Regarding why SVD: I decided to use SVD as it's one of the simplest and most ubiquitous matrix factorisation techniques out there (so I didn't need to validate it or benchmark it). Also, it allows for not-so-heavy computations, which is crucial because SARA is thought to be implemented at inference time.
Replies from: Charlie Steiner↑ comment by Charlie Steiner · 2024-06-20T16:40:39.462Z · LW(p) · GW(p)
Yeah, intervening on the entire activation history makes sense. It's just honestly surprising to me that taking the largest singular vectors even mostly preserves semantic meaning. To my intuition, the thing that preserving large singular vectors preserves is this linear-algebra property about the matrix as a transformation, which feels different from an information-theoretic property about the matrix as an array of numbers.
Replies from: alejandro-tlaie-boria↑ comment by Alejandro Tlaie (alejandro-tlaie-boria) · 2024-06-25T12:16:42.692Z · LW(p) · GW(p)
I agree that it is intriguing. Even if I'm currently testing the method on more established datasets, my intuition of why it works is as follows:
-
Singular vectors correspond to the principal directions of data variance. In the context of LLMs, these directions capture significant patterns of moral and ethical reasoning embedded within the model's activations.
-
While it seems that the largest singular vectors only preserve linear-algebra properties, they also encapsulate high-dimensional data structure, which I'd argue includes semantic and syntactic information. At the end of the day, these vectors represent directions along which the model activations vary the most, inherently encoding important semantic information.
comment by Gianluca Calcagni (gianluca-calcagni) · 2024-06-25T16:54:36.479Z · LW(p) · GW(p)
I am glad I read your post, very relevant for safety! It seems to me that the Steering Directions are a variant of the Control Vectors that I described here https://www.lesswrong.com/posts/Bf3ryxiM6Gff2zamw/control-vectors-as-dispositional-traits
Please can you confirm the two concepts are following essentially the same approach?
I agree with you over the benefits of the technique, it is very promising. If there was a proper analysis of its scalability properties and if there was some way to estimate mathematically its likelihood of success, it would be a dramatic breakthrough
↑ comment by Alejandro Tlaie (alejandro-tlaie-boria) · 2024-07-01T12:34:10.515Z · LW(p) · GW(p)
Hi Gianluca, it's great that you liked the post and the idea! I think that your approach and mine share things in common and that we have similar views on how activation steering might be useful!
I would definitely like to chat to see whether potential synergies come up :)
Replies from: gianluca-calcagni↑ comment by Gianluca Calcagni (gianluca-calcagni) · 2024-07-10T13:01:05.228Z · LW(p) · GW(p)
Very happy to support you :)
It took some time to understand your paper, please find below a few comments:
(1) You are using SVD to find the control vectors (similarly to other authors) but your process is more sophisticated in the following ways: the generation of the matrices, how to reduce them, and how to choose the magnitude of each steering vector. You are also using the non-steered response as an active part of your calculations - something that is marginally done by other authors. The final result works, but the process looks arbitrary to me (tbh all the steering techniques are a bit arbitrary at the moment). What's the added value of your operations? Maybe you have some intuition about why your calculation is finding the "correct" amount of steering, and I am curious to know more.
(2) Ethics plays a fundamental role in finding a collective solution to AI safety, but I tend to think that we should solve alignment first. It would be interesting to see your future research going in that direction. I can help brainstorming some topics that have not been exhaustively studied yet. Let me know!