Elicitation for Modeling Transformative AI Risks
post by Davidmanheim · 2021-12-16T15:24:04.926Z · LW · GW · 2 commentsContents
What to do about forecasting given uncertainties and debates? Using Elicitations What are the current plans? How do you judge who is an “expert?” How will we represent uncertainties? Will this be informative? What are the next steps? None 2 comments
This post is part 8 in our sequence on Modeling Transformative AI Risk. We are building a model to understand debates around existential risks from advanced AI. The model is made with Analytica software, and consists of nodes (representing key hypotheses and cruxes) and edges (representing the relationships between these cruxes), with final output corresponding to the likelihood of various potential failure scenarios. You can read more about the motivation for our project and how the model works in the Introduction post. Unlike other posts in the sequence, this discusses the related but distinct work around Elicitation.
We are interested in feedback on this post, but to a greater extent than the other posts, we are interested in discussing what might be useful, and how to proceed with this. We would also welcome discussion from people working independently on elicitations, as we have discussed this extensively with other groups, many of whom are doing related work.
As discussed in previous posts in this series, the model we have built is a tentative one, and requires expert feedback and input. The traditional academic method for getting such feedback and input is usually referred to as elicitation, and an extensive field of academic work discusses how this can best be done. (As simple examples, this might include eliciting an estimated cost, and probability distribution, or a rank ordering of which outcomes from a project are most important.)
Elicitation of expert views is particularly critical in AI safety for both understanding debates between experts and representing the associated probabilities. At the same time, many elicitation and forecasting projects have the advantage of unambiguous and concrete questions with answers that will be observed in the near term, or ask for preferences about outcomes which are well understood. Because these advantages are mostly absent for AI safety questions, the focus in this project is on understanding debates (instead of attempting to settle debates that are already understood, or are not resolvable even in theory). This means that there is no intent to elicit a “correct” answer to questions which may be based on debated or disputed assumptions. For this reason, we have taken an approach designed to start with better understanding experts’ views of the domain overall, rather than focus on the outcomes directly. This leads to opportunities for better understanding the sources of disagreement.
The remainder of this post first discusses what elicitation can and should be able to accomplish in this domain, and for this project, as well as what conceptual and actual approaches we are using. This should help explain how elicited information can inform the concrete model, which then can then hopefully help inform decisions - or at least clarify why the decisions about approaches to take are disputed. Following that, we outline our tentative future plan, and what additional steps for elicitation may look like.
What to do about forecasting given uncertainties and debates?
In domains where the structure of uncertainties are clear, and not debated, it is possible to build a model similar to that built in the current project, ask experts whether the structure is correct, and based on their input, build a final Directed Acyclic Graph or other representation of the joint distribution that correctly represents their views. After this, we would ask experts to attach probability distributions to the various uncertainties, perhaps averaging their opinions for each node in the DAG, so that we could get quantitative predictions for the outcomes via Monte Carlo.
Long-term forecasting of deeply uncertain and debated outcomes in a domain like the future of AI is, for obvious reasons, extremely unreliable for predictions. And yet, we still need to make best-guess estimates for decision purposes, and in fact we implicitly have assigned probabilities and have implicit goals which are used and maximized when making any sort of decision related to the topic. Making this explicit involves ensuring that everyone’s varying assumptions or assertions are understood, which leads to both the motivation for and challenging nature of the current project.
By representing different structural assumptions about the future pathway of AI, and various models of how AI risks can be addressed, we can better understand where disagreements are due to fundamental differences (“AI will be aligned by default” vs. “The space of possible ML Minds contains at least some misaligned agents” vs. “Vanishingly few potential AIs are aligned”), and where they are due to quantitative differences in empirical estimates (“50% Confidence we will have ASI by 2030” vs. “90% confidence we won’t have ASI before 2050”). While these examples may be obvious, it is unclear whether others exist which are less so - and even the “obvious” debates may not be recognized by everyone as being legitimately debated.
For this reason, in addition to understanding specific debates, we need to represent uncertainty about both quantitative estimates and about the ground truth for conceptual debates. One way we plan to address this is by incorporating confidence measures for expert opinions about the debated features or assumptions in our probability estimates. Another is accounting for the arguments from analogy which many of these claims are based upon. For example, an expectation that ML progress will continue at a given pace, based on previous trends, is not an (explicit/gears-level) model of hardware or software progress, but it often informs an estimate and makes implicit assumptions about the solutions to the debated issues nonetheless.
However, it is at least arguable that a decision maker should incorporate information from across multiple viewpoints. This is because unresolved debates are also a form of uncertainty, and should be incorporated when considering options. One way we plan to address this is by explicitly including what we call “meta-uncertainties” in our model. Meta-uncertainties are intended to include all factors that a rational decision maker should take into account when making a decision using our model, but which do not correspond to a specific object-level question in the model.
One such meta-uncertainty is the reliability of long-term forecasting in general. If we think that long-term forecasting is very unreliable, we can use that as a factor that essentially downweights the confidence we have in any conclusions generated by the rest of our model. Other meta-uncertainties include: the reliability of expert elicitations in general and our elicitation in particular, structural uncertainties in our own model (how confident are we that we got this model right?), reference class uncertainty (did we pick the right reference classes?), potential cognitive biases that might be involved, and the possibility of unknown unknowns.
Using Elicitations
Given the above discussion, typical expert elicitation and aggregating opinions to get a best-guess forecast is not sufficient. Several challenges exist, from selecting experts to representing their opinions to aggregating or weighting differing views. But before doing any of these, more clarity about what is being asked is needed.
What are the current plans?
Prior to doing anything resembling traditional quantitative elicitation, we need to have clarity in what is being elicited, so that the respondents are both clear about what is being asked and are answering the same question as one another. We also need to be certain that they are answering the same question as what we think is being asked. For example, asking for a timeline to HLMI is unhelpful if respondents have different ideas of what the term means, or dispute its validity as a concept. For this reason, our current work is focused on understanding which terms and concepts are understood, and which are debated.
It seems that one of the most useful methods of eliciting feedback on the model is via requesting and receiving comments on this series of posts, and discussions that arise from it. Going further, a paper is being written which reviews past elicitation - and looks at where they succeeded or failed. Building on the review of the many different past elicitation projects and approaches, a few of which are linked, and as a way to ensure we properly understand the disagreements which exist in AI alignment and safety, David Manheim, Ross Greutzmacher, and Julie Marble are working on new elicitation methods to help refine our understanding. We have tested, and are continuing to test these methods internally, but we have not yet utilized them with external experts. As noted, the goal of this initial work is to better understand experts’ conceptual models, using methods such as guided pile sorts, explained below, and qualitative discussion.
The specific approach discussed below, called pile sorting, is adapted from sociology and anthropology. We have used this because it allows for discussion of terms without forcing a structure onto the discussion, and allows for feedback in an interactive way.
(Sample) initial prompt for the pile sorting task:
“The following set of terms are related to artificial intelligence and AI safety in various ways. The cards can be moved, and we would like you to group them in a way that seems useful for understanding what the terms are. While doing so, please feel free to talk about why, or what you are uncertain about. If any terms seem related but are missing, or there are things you think would be good to add or include, feel free to create additional cards. During the sorting, we may prompt you, for instance, by asking you why you chose to group things, or what the connection between items or groups is.”

Based on this prompt, we engage in a guided discussion where we ask questions like how the terms are understood, why items have been grouped together, what the relationships between them are, and whether others would agree. It is common for some items to fit into multiple groups, and participants are encouraged to duplicate cards when this occurs. The outputs of this include both our notes about key questions and uncertainties, and the actual grouping. The final state of the board in one of our sample sessions looked like the below:
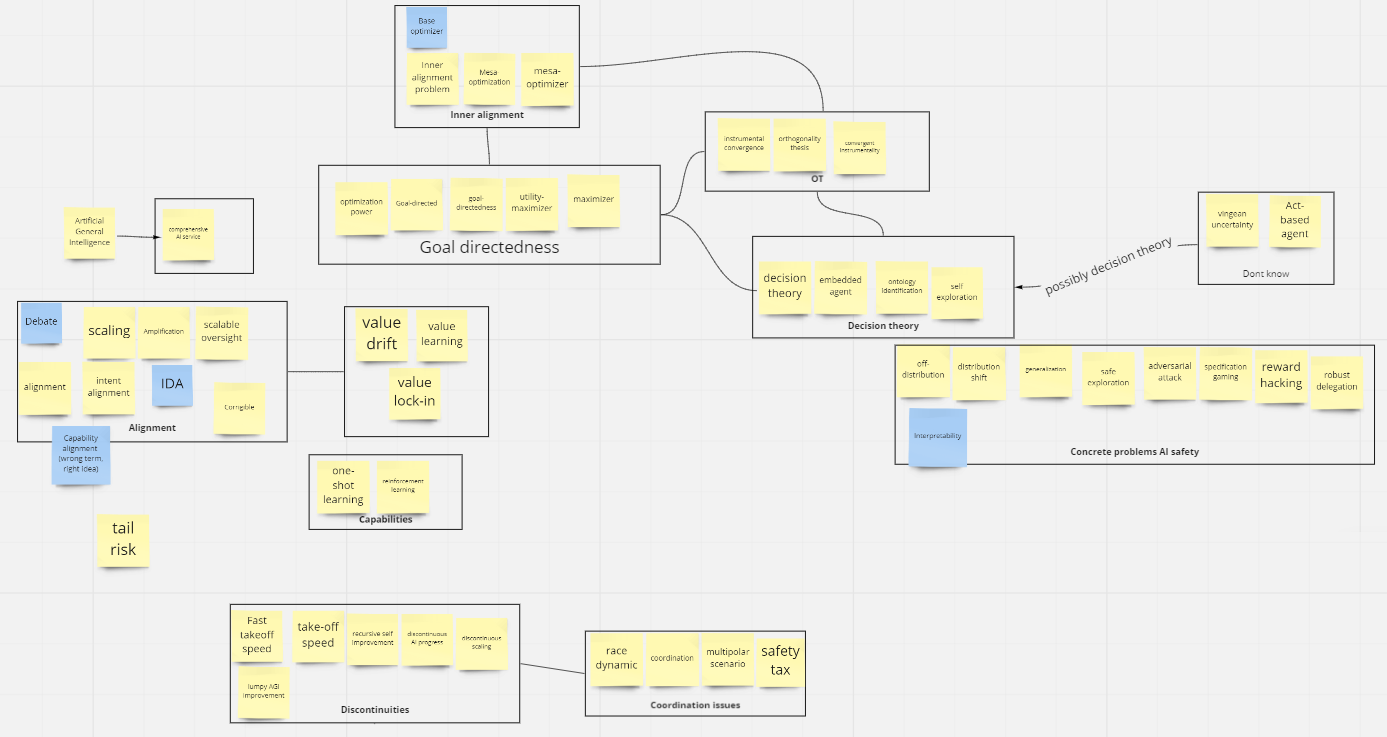
This procedure, and the discussions with participants about why they chose the groupings they did, is intended to ensure that we have a useful working understanding of expert’s general views on various topics related to AI safety, and will be compared across experts to see if there are conflicts or different and contrasting conceptual models, and where the differences are. While methods exist for analyzing such data, these are typically for clearer types of questions and simpler sorting. For that reason. one key challenge which we have not resolved is how this elicitation can be summarized or presented clearly, other than via extensive qualitative discussions.
In addition to the card sort, we have several other elicitation approaches we are considering and pursuing that intend to accomplish related or further goals in this vein. But in order to do any elicitation, including these, there are some key challenges
How do you judge who is an “expert?”
This is a difficult issue, and varies depending on the particular hypothesis or proposition we’re asking about. It also depends on whether we view experts as good at prediction, or good at proposing useful mental models that can then be predicted about by forecasters. For deconfusion and definition disputes, the relevant experts are likely in the AI safety community and closely related areas. For other questions the relevant experts might be machine learning researchers, cognitive scientists, or evolutionary biologists. And of course, in each case, depending on the type of question, we may need to incorporate disputes rather than just estimates.
For example, if we were to ask “will mesa-optimizers emerge,” we need to rely on a clear understanding of what mesa-optimizers are. Unfortunately, this is somewhat debated, so different researchers' answers will not reflect the same claims. Furthermore, those who are not already concerned about the issue will likely be unable to usefully answer, given that the terms are unclear - biasing the results. For this reason, we have started with conceptual approaches, such as the above pile-sorting task.
Relatedly, in many cases, we also need to ask questions to multiple groups to discover if experts in different research areas have different views on a question. We expect different conceptual models to inform differences in opinions about the relationship between different outcomes, and knowing what those models are is helpful in disambiguating and ensuring that experts’ answers are interpreted correctly.
Another great challenge in selecting experts is that the relevant experts for topics such as AI safety and machine learning are often those who are working at the forefront of the field, and whose time is most valuable. Of course, this depends on how you define or measure domain expertise, but the value of previous elicitations is strongly correlated with the value of experts’ contributions in narrow domains. The difference in knowledge and perspective between those leading the field and those performing essentially Kuhn’s ‘normal science’ is dramatic, and we hope that the novel elicitation techniques that we are working on can enable us to weight the structure emerging from leading experts’ elicitations appropriately.
Following the identification of experts, there is a critical question: Is the value of expert judgment limited to only qualitative information or to coming up with approaches in practice, rather than the alternative of being well calibrated for prediction. This is not critical at the current stage, but becomes more important later. There are good reasons to think that generalist forecasters have an advantage, and depending on progress and usefulness of accurate quantification, this may be a critical tool for later stages of the project. We are interested in exploring forecasting techniques that combine domain experts and generalist forecasters in ways intended to capitalize on the relative expertise of both populations.
How will we represent uncertainties?
For any object-level issue, in addition to understanding disputes, we need to incorporate uncertainties. Incorporation of uncertainty is both important for not misunderstanding expert views, and as a tool to investigate those differences in viewpoints. For this reason, when we ask for forecasts or use quantitative elicitations to ask experts for their best-guess probability estimates, we would also need to ask for the level of confidence that they have in those estimates, or their distribution of expected outcomes.
In some cases, experts or forecasters will themselves have uncertainties over debated propositions. For example, if asked about the rate of hardware advances, they may say that overall, they would guess a rate with distribution X, but that distribution depends on economic growth. If pre-HLMI AI accelerates economic growth, they expect hardware progress to follow one distribution, whereas if not, they expect it to follow another. In this case, it is possible for the elicitation to use the information to inform the model structure as well as the numeric estimate.
As an aside, while we do by default intend to represent both structural debates and estimates as probabilities, there are other approaches. Measures of confidence of this type can be modeled as imprecise probabilities, as distributions over probability estimates (“second-order probabilities”), or using other approaches (e.g., causal networks, Dempster-Shafer theory, subjective logic). We have not yet fully settled on which approach or set of approaches to use for our purposes, but for the sake of simplicity, and for the purpose of decision making, the model will then need to represent the measures of confidence as distributions over probability estimates.
Will this be informative?
It is possible that the more valuable portion of the work is the conceptual model, rather than quantitative estimates, or that the conceptual elicitations we are planning are unlikely to provide useful understanding of the domain. This is a critical question, and one that we hope will be resolved based on feedback from the team internally, outside advisors, and feedback from decision makers in the EA and longtermist community who we hope to inform.
What are the next steps?
The current plans are very much contingent on feedback, but conditional on receiving positive feedback, we are hoping to run the elicitations we have designed, and move forward from there. We would also be interested in finding others that are interested in working with us on both the current elicitation projects, and thinking about what should come next, and have reached out to some potential collaborators.
2 comments
Comments sorted by top scores.
comment by Paal Skjørten (paal-skjorten) · 2021-12-27T10:59:52.436Z · LW(p) · GW(p)
Super interesting project! Is the model available now, and if not, when do you expect it to be? I'd say that eliciting judgments is probably quite valuable, especially for laymen trying to understand these debates. AI risk is in the peculiar position of being more dependent on expert testimony than many other fields, while also being pre-paradigmatic, implying that it is still unclear who the experts are. This makes work on expert elicitation more pressing, not less, because mapping the beliefs of researchers here would provide the grounds for a better discussion about it, even though it would not settle questions directly. That is, anyway, my five cents, although I am very unsure about all this.
Replies from: Davidmanheim↑ comment by Davidmanheim · 2021-12-28T08:20:55.196Z · LW(p) · GW(p)
The model is available privately now, and I strongly agree that it's particularly important to do elicitations well!