Why I'm excited about Debate
post by Richard_Ngo (ricraz) · 2021-01-15T23:37:53.861Z · LW · GW · 12 commentsContents
12 comments
I think Debate is probably the most exciting existing safety research direction. This is a pretty significant shift from my opinions when I first read about it, so it seems worth outlining what’s changed. I’ll group my points into three categories. Points 1-3 are strategic points about deployment of useful AGIs. Points 4-6 are technical points about Debate. Points 7-9 are meta-level points about how to evaluate safety techniques, in particular responding to Beth Barnes’ recent post on obfuscated arguments in Debate [AF · GW].
1. Question-answering is very useful.
People often claim that question-answering AGIs (which I’ll abbreviate as QAGIs) will be economically uncompetitive compared with agentic AGIs. But I don’t think this matters very much for the two most crucial applications of AGIs. Firstly, when it comes to major scientific and technological advances, almost all of the value is in the high-level concepts - it seems unlikely that implementing those advances will require AGI supervision (rather than just supervision from narrow AIs) during deployment.
Secondly, aligned QAGIs can do safety research to help us understand how to build aligned agentic AGIs, and can also predict and prevent their misbehaviour. So even a relatively small lead for aligned QAGIs could be very helpful.
2. Debate pushes capabilities in the right direction.
Another objection I used to have: I tend to expect that QAGIs are pretty safe anyway, which implies that in aligning QA systems, Debate isn’t helping tackle the cases we should be most worried about. And if it’s used as a final step of training for systems that have previously been trained to do other things [AF · GW], then it’s very unclear to me whether Debate would override whatever unsafe motivations those systems had already acquired.
But now I think that Debate could be an important tool for not only making QA systems more aligned, but also more competitive. Systems like GPT-3 have shown a very good understanding of language, and I expect them to gain much more world-knowledge, but it’s hard to elicit specific answers from them. We might hope to make them do so by using reward-modelling to fine-tune them, but I expect that in order to scale this up to complex questions, we’ll need to make that process much more efficient in human time. That’s what Debate does, by allowing humans to evaluate answers on criteria that are much simpler than the holistic question “is this answer good?”
3. Debate provides a default model of interaction with AGIs.
We won’t just interact with agentic AGIs by giving them commands and waiting until they’ve been carried out. Rather, for any important tasks, we’ll also ask those AGIs to describe details of their plans and intentions, and question them on any details which we distrust. And for additional scrutiny, it seems sensible to run these answers past other AGIs. In other words, Debate is a very natural way to think about AGI deployment, and describes a skillset which we should want all our AGIs to have, even if it’s not the main safety technique we end up relying on.
4. Debate implicitly accesses a complex structure
I originally thought that Debate was impractical because debates amongst humans aren’t very truth-conducive. But now I consider it misleading to think about Debate as simply a more sophisticated version of what two humans do. The comparison to a game of Go is illuminating. Specifically, let’s interpret any given Go position as a question: who wins the game of Go starting from this position? Then we can interpret a single game of Go played from that position, by sufficiently strong players, as good evidence that the (exponential) tree of other possible games doesn’t contain a refutation of any of the moves played by the eventual winner. Similarly, the hope is that we can interpret a single line of debate, starting from a given question, as good evidence that the exponential tree of other lines of debate doesn’t contain a refutation of any of the claims made by the eventual debate winner.
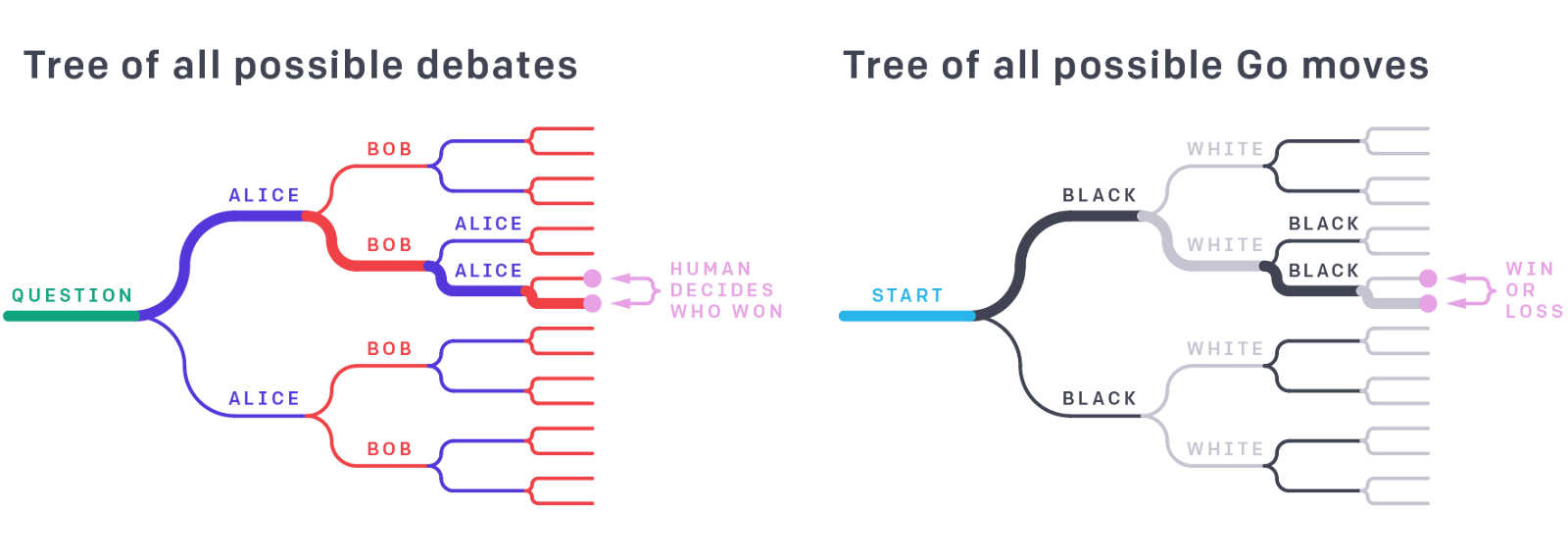
In other words, the core insight of Debate is that we can evaluate a whole argumentative tree while only exploring one branch, given a strict standard of judging (i.e. whoever loses that one branch loses the whole tree), because the debaters will model the rest of the tree to the best of their (superhuman) abilities. We can't do this in normal debates between humans, because human debaters aren't smart enough for other humans to reliably interpret the outcome of one specific branch of a debate tree as strong evidence about the rest of the tree. Therefore human incentives are very rarely set up to punish minor errors, which may allow compounding inaccuracy. A better analogy than a normal human debate might be to a human debate where, before making each argument, each side can consult a large team of experts on the topic; in this case, it seems much more reasonable to expect both that small mistakes will be caught, and that small mistakes are deliberate lies which should cause the liar to lose the debate. (Punishing minor errors does introduce more variance into AI debates, since the truth-telling debater could get unlucky by making small mistakes. But unlike human debates, we can run AI debates a large number of times, hopefully decreasing that variance significantly.)
The intuition I've described makes Debate compare favourably to recursive reward modelling (RRM), which needs to actually implement the whole exponential tree of agents answering subquestions. (I think Jan Leike envisages RRM trees as being much shallower than Debate trees, though.) RRM does has other advantages - in particular its ability to train agents which actually take actions in the world. But as already discussed, I find this less compelling than I used to.
5. Reasoning can be truth-conducive even in adversarial environments
I’m reasonably compelled by Sperber and Mercer’s claim that explicit reasoning in humans primarily evolved not in order to help us find out about the world, but rather in order to win arguments. [EDIT: More specifically, Sperber and Mercer claim that "reason is not geared to solitary use, to arriving at better beliefs and decisions on our own. What reason does, rather, is help us justify our beliefs and actions to others, convince them through argumentation, and evaluate the justifications and arguments that others address to us." This still involves evaluations which aim to find out which arguments are right about the world]. I think this frames our current situation in a new light: reasoning fails to track the truth so often not necessarily because it’s a weak tool, but because it’s specifically been selected to promote many of these failures (such as overconfidence in our own claims). And yet, despite that, it’s still reasonably truth-conducive - we can still reason about complex scientific domains, for example. This makes me more optimistic that Debate can be fairly truth-conducive even if the training incentives aren’t quite right.
Consider also that, for existential safety, we only need reasoning to be truth-conducive enough to detect catastrophes. We should expect that doing so is much easier than finding the truth about all (potentially very subtle and nuanced) questions.
6. Debate passes the human relevance test.
An important heuristic I use [AF(p) · GW(p)] for evaluating safety research directions: would these work for making humans safer, if applied over evolutionary timeframes? This decomposes into a few different components:
- Does the technique apply to “prosaic” machine learning, without requiring deeper insights into cognition? I.e. does it work if we build AGI by optimising a big neural network via local search techniques like gradient descent or evolution?
- Does the technique scale up to generally intelligent agents?
- Does the technique scale up to very complex environments?
- Does the technique work even after a long period of “pre-training” [AF · GW] instills unsafe traits in the agent?
I think that Debate passes the first three of these tests, which is a good sign! Most other safety techniques don’t. The fourth criterion is a harder one: it’s analogous to the question of whether a safety technique applied to humans would be able to remove deeply-ingrained goals like our survival instincts, while avoiding deceptive alignment. I’m not convinced that Debate solves this, but I don’t think any other safety technique does so either.
7. Debate promotes empirical investigation
We can consider Debate to be one type of iterated amplification (IA) - but for the purposes of doing good follow-up research, I think the specificity of Debate makes it more valuable than the broad concept of IA in general. In particular, this specificity makes it easier for more people to do conceptual and empirical investigation. This is especially important given that so many ideas in safety are so abstract and hard to ground in concrete research questions. Further, the adversarial framing of Debate makes it easier to spot problems, by pushing us to think about how the setup might be exploited. These factors have already contributed to interesting insights, such as OpenAI’s work on cross-examination [AF · GW].
8. Recent negative results aren’t too discouraging.
Beth recently put a post online [AF · GW] with negative results from Debate - in particular, the finding that misleading debate trees can be constructed for which it seems necessary to examine all the steps of the argument in order to refute it.
There are a few reasons I’m not too discouraged by this. Firstly, the physics problems they’re using to evaluate Debate are hard - they are designed to be counterintuitive, and sometimes confuse physics PhDs. Even people who can solve them in one way often can’t evaluate other potential ways of solving them. So the fact that we can generate confusing debate transcripts about them isn’t much evidence about the limitations of Debate on domains which both debaters have thorough knowledge of. Note also that we haven’t yet seen what top-notch physicists with relevant expertise would make of these transcripts; it may be that it only takes a few weeks of practice on these types of everyday physics questions for experts to gain sufficient knowledge to refute misleading arguments.
We might be worried that, if we have such trouble with everyday physics, it’ll be very difficult to scale up to more difficult questions. But note that current difficulties are partly because Debate experiments don’t (yet) allow debaters to make empirical predictions. Given how valuable this step has been for humans, it seems plausible that adding it would make Debate significantly more powerful. A very rough summary of human intellectual history: we tried to make progress via debate for thousands of years, and gained little knowledge (except in maths). Then we started also relying on empirical predictions, and underwent the scientific and industrial revolutions shortly afterwards. Predictions are very powerful tools for cutting through verbal obfuscation, when used in conjunction with verbal reasoning.
9. Recent negative results expect too much from Debate.
The OpenAI team is trying to use Debate to access all the knowledge our agents have. But this seems like an unrealistic goal - consider how incredibly difficult it is in the case of humans. There’s plenty of human knowledge that is very difficult to access (e.g. because it relies on finely-honed intuitions) even when the human in question is being fully cooperative. Indeed, given how much knowledge is tacit or vague, I’m not even sure what it would mean to succeed in accessing all an agent’s knowledge.
From my perspective, if Debate makes it easier to reliably access a part of the debaters’ knowledge, that seems pretty useful. And if it boosts the capabilities of our language models, that would also be great.
More generally, we already knew that there are some problems on which Debate fails - such as cryptographic functions whose solutions are very hard to find. So what we’re trying to figure out is to what extent the most interesting problems fall into that category. But insofar as we’re worried about agents taking harmful actions, we’re worried about Debate arguments with verifiable consequences, and so I expect that leveraging empirical evidence (as discussed previously) will be a big advantage.
12 comments
Comments sorted by top scores.
comment by Eliezer Yudkowsky (Eliezer_Yudkowsky) · 2021-01-16T20:25:38.767Z · LW(p) · GW(p)
I’m reasonably compelled by Sperber and Mercer’s claim that explicit reasoning in humans primarily evolved not in order to help us find out about the world, but rather in order to win arguments.
Seems obviously false. If we simplistically imagine humans as being swayed by, and separately arguing, an increasingly sophisticated series of argument types that we could label 0, 1, 2, ...N, N+1, and which are all each encoded in a single allele that somehow arose to fixation, then the capacity to initially recognize and be swayed by a type N+1 argument is a disadvantage when it comes to winning a type N argument using internal sympathy with the audience's viewpoint, because when that mutation happens for the first time, the other people in the tribe will not find N+1-type arguments compelling, and you do, which leads you to make intuitive mistakes about what they will find compelling. Only after the capacity to recognize type N+1 arguments as good arguments becomes pervasive in other listeners, does the ability to search for type-N+1 arguments congruent to some particular political or selfish purpose, become a fitness advantage. Even if we have underlying capabilities to automatically search for political/selfish arguments of all types we currently recognize as good, this just makes the step from N+1 recognition to N+1 search be simultaneous within an individual organism. It doesn't change the logic whereby going from N to N+1 in the sequence of recognizably good arguments must have some fitness advantage that is not "in order to win arguments" in order for individuals bearing the N+1 allele to have a fitness advantage over individuals who only have the alleles up to N, because being swayed by N+1 is not an advantage in argument until other individuals have that allele too.
In real life we have a deep pool of fixed genes with a bubbling surface of multiple genes under selection, along with complicated phenotypical interactions etcetera, but none of this changes the larger point so far as I can tell: a bacterium or a mouse have little ability to be swayed by arguments of the sort humans exchange with each other, which defines their lack of reasoning ability more than their difficulty in coming up with good arguments; and an ability to be swayed by an argument of whatever type must be present before there's any use in improving a search for arguments that meet that criterion. In other words, the journey from the kind of arguments that bacteria recognize, to the kind of arguments that humans recognize, cannot have been driven by an increasingly powerful search for political arguments that appeal to bacteria.
Even if the key word is supposed to be 'explicit', we can apply a similar logic to the ability to be swayed by an 'explicit' thought and the ability to search for explicit thoughts that sway people.
If arguments had no meaning but to argue other people into things, if they were being subject only to neutral selection or genetic drift or mere conformism, there really wouldn't be any reason for "the kind of arguments humans can be swayed by" to work to build a spaceship. We'd just end up with some arbitrary set of rules fixed in place. False cynicism.
Replies from: Eliezer_Yudkowsky, ricraz, adamShimi↑ comment by Eliezer Yudkowsky (Eliezer_Yudkowsky) · 2021-01-16T22:34:55.537Z · LW(p) · GW(p)
Now, consider the following simplistic model for naive (un)aligned AGI:
The AGI outputs English sentences. Each time the AGI does, the human operator replies on a scale of 1 to 100 with how good and valuable and useful that sentence seemed to the human. The human may also input other sentences to the AGI as a hint about what kind of output the human is currently looking for; and the AGI also has purely passive sensory inputs like a fixed webcam stream or a pregathered internet archive.
How does this fail as an alignment methodology? Doesn't this fit very neatly into the existing prosaic methodology of reinforcement learning? Wouldn't it be very useful on hand to have an intelligence which gives us much more valuable sentences, in response to input, than the sentences that would be generated by a human?
There's a number of general or generic ways to fail here that aren't specific to the supposed criterion of the reinforcement learning system, like the AGI ending up with other internal goals and successfully forging a Wifi signal via internal RAM modulation etcetera, but let's consider failures that are in some sense intrinsic to this paradigm even if the internal AI ends up perfectly aligned on that goal. Let's even skip over the sense in which we've given the AI a long-term incentive to accept some lower rewards in the short term, in order to grab control of the rating button, if the AGI ends up with long-term consequentialist preferences and long-term planning abilities that exactly reflect the outer fitness function. Let's say that the AGI is only shortsightedly trying to maximize sentence reward on each round and that it is not superintelligent enough to disintermediate the human operators and grab control of the button in one round without multi-round planning. Some of us might be a bit skeptical about whether you can be, effectively, very much smarter than a human, in the first place, without doing some kind of multi-round or long-term internal planning about how to think about things and allocate internal resources; but fine, maybe there's just so many GPUs running the system that it can do all of its thinking, for each round, on that round. What intrinsically goes wrong?
What intrinsically goes wrong, I'd say, is that the human operators have an ability to recognize good arguments that's only rated to withstand up to a certain intensity of search, which will break down beyond that point. Our brains' ability to distinguish good arguments from bad arguments is something we'd expect to be balanced to the kind of argumentative pressure a human brain was presented with in the ancestral environment / environment of evolutionary adaptedness, and if you optimize against a brain much harder than this, you'd expect it to break. There'd be an arms race between politicians exploiting brain features to persuade people of things that were useful to the politician, and brains that were, among other things, trying to pursue the original 'reasons' for reasoning that originally and initially made it useful to recognize certain arguments as good arguments before any politicians were trying to exploit them. Again, oversimplified, and there are cases where it's not tribally good for you to be the only person who sees a politician's lie as a lie; but the broader point is that there's going to exist an ecological balance in the ancestral environment between brains trying to persuade other brains, and brains trying to do locally fitness-enhancing cognition while listening to persuaders; and this balance is going to be tuned to the level of search power that politicians had in the environment of evolutionary adaptedness.
Arguably, this is one way of viewing the flood of modern insanity at which social media seems to be the center. For the same reason pandemics get more virulent with larger and more dense population centers, Twitter may be selecting for memes that break humans at a much higher level of optimization pressure than held in the ancestral environment or even just 1000 years earlier than this.
Viewed through the lens of Goodhart's Curse: When you have an imperfect proxy U for an underlying value V, the highest values of U will represent the places where U diverges upward the most from V and not just the highest underlying values of V. The harder you search for high values of U, the wider the space of possibilities you search, the more that the highest values of U will diverge upwards from V.
### incorporated from a work in progress
Suppose that, in the earlier days of the Web, you're trying to find webpages with omelet recipes. You have the stunning insight that webpages with omelet recipes often contain the word "omelet" somewhere in them. So you build a search engine that travels URLs to crawl as much of the Web as you can find, indexing all the pages by the words they contain; and then you search for the "omelet" keyword. Works great the first time you try it! Maybe some of the pages are quoting "You can't make an omelet without breaking eggs" (said by Robespierre, allegedly), but enough pages have actual omelet recipes that you can find them by scrolling down. Better yet, assume that pages that contain the "omelet" keyword more often are more likely to be about omelets. Then you're fine... in the first iteration of the game.
But the thing is: the easily computer-measurable fact of whether a page contains the "omelet" keyword is not identical to the fact of whether it has the tasty omelet recipe you seek. V, the true value, is whether a page has a tasty recipe for omelets; U, the proxy measure, is how often the page mentions the "omelet" keyword. That some pages are compendiums of quotes from French revolutionaries, instead of omelet recipes, illustrates that U and V can diverge even in the natural ecology.
But once the search engine is built, we are not just listing possible pages and their U-measure at random; we are picking pages with the highest U-measure we can see. If we name the divergence D = U-V then we can say u_i = v_i + d_i. This helps illustrate that by selecting for the highest u_i we can find, we are putting upward selection pressure on both v_i and d_i. We are implicitly searching out, first, the underlying quality V that U is a proxy for, and second, places where U diverges far upward from V, that is, places where the proxy measure breaks down.
If we are living in an unrealistically smooth world where V and D are independent Gaussian distributions with mean 0 and variance 1, then the mean and variance of U is just 0 and 2 (the sum of the means and variances of V and D). If we randomly select an element with u_i=3, then on average it has v_i of 1.5 and d_i of 1.5. If the variance of V is 1 and the variance of D is 10 - if the "noise" from V to U varies much more widely on average than V itself - then most of the height of a high-U item probably comes from a lot of upward noise. But not all of it. On average, if you pick out an element with u_i = 11, it has expected d_i of 10 and v_i of 1; its apparent greatness is mostly noise. But still, the expected v_i is 1, not the average V of 0. The best-looking things are still, in expectation, better than average. They are just not as good as they look.
Ah, but what if everything isn't all Gaussian distributions? What if there are some regions of the space where D has much higher variance - places where U is much more prone to error as a proxy measure of V? Then selecting for high U tends to steer us to regions of possibility space where U is most mistaken as a measure of V.
And in nonsimple domains, the wider the region of possibility we search, the more likely this is to happen; the more likely it is that some part of the possibility space contains a place where U is a bad proxy for V.
This is an abstract (and widely generalizable) way of seeing the Fall of Altavista. In the beginning, the programmers noticed that naturally occurring webpages containing the word "omelet" were more likely to be about omelets. It is very hard to measure whether a webpage contains a good, coherent, well-written, tasty omelet recipe (what users actually want), but very easy to measure how often a webpage mentions the word "omelet". And the two facts did seem to correlate (webpages about dogs usually didn't mention omelets at all). So Altavista built a search engine accordingly.
But if you imagine the full space of all possible text pages, the ones that mention "omelet" most often are not pages with omelet recipes. They are pages with lots of sections that just say "omelet omelet omelet" over and over. In the natural ecology these webpages did not, at first, exist to be indexed! It doesn't matter that possibility-space is uncorrelated in principle, if we're only searching an actuality-space where things are in fact correlated.
But once lots of people started using (purely) keyword-based searches for webpages, and frequently searching for "omelet", spammers had an incentive to reshape their Viagra sales pages to contain "omelet omelet omelet" paragraphs.
That is: Once there was an economic incentive for somebody to make the search engine return a different result, the spammers began to intelligently search for ways to make U return a high result, and this implicitly meant putting the U-V correlation to a vastly stronger test. People naturally making webpages had not previously generated lots of webpages that said "omelet omelet omelet Viagra". U looked well-correlated with V in the region of textual possibility space that corresponded to the Web's status quo ante. But when an intelligent spammer imagines a way to try to steer users to their webpage, their imagination is searching through all the kinds of possible webpages they can imagine constructing; they are searching for imaginable places where U-V is very high and not just previously existing places where U-V is high. This means searching a much wider region of possibility for any place where U-V breaks down (or rather, breaks upward) which is why U is being put to a much sterner test.
We can also see issues in computer security from a similar perspective: Regularities that are obseved in narrow possibility spaces often break down in wider regions of the possibility space that can be searched by intelligent optimization. Consider how weird a buffer overflow attack would look, relative to a more "natural" ecology of program execution traces produced by non-malicious actors. Not only does the buffer overflow attack involve an unnaturally huge input, it's a huge input that overwrites the stack return address in a way that improbably happens to go to one of the most effectual possible destinations. A buffer overflow that results in root privilege escalation might not happen by accident inside a vulnerable system even once before the end of the universe. But an intelligent attacker doesn't search the space of only things that have already happened, they use their intelligence to search the much wider region of things that they can imagine happening. It says very little about the security of a computer system to say that, on average over the lifetime of the universe, it will never once yield up protected data in response to random inputs or in response to inputs typical of the previously observed distribution.
And the smarter the attacker, the wider the space of system execution traces it can effectively search. Very sophisticated attacks can look like "magic" in the sense that they exploit regularities you didn't realize existed! As an example in computer security, consider the Rowhammer attack, where repeatedly writing to unprotected RAM causes a nearby protected bit to flip. This violates what you might have thought were the basic axioms governing the computer's transistors. If you didn't know the trick behind Rowhammer, somebody could show you the code for the attack, and you just wouldn't see any advance reason why that code would succeed. You would not predict in advance that this weird code would successfully get root privileges, given all the phenomena inside the computer that you currently know about. This is "magic" in the same way that an air conditioner is magic in 1000AD. It's not just that the medieval scholar hasn't yet imagined the air conditioner. Even if you showed them the blueprint for the air conditioner, they wouldn't see any advance reason to predict that the weird contraption would output cold air. The blueprint is exploiting regularities like the pressure-temperature relationship that they haven't yet figured out.
To rephrase back into terms of Goodhart's Law as originally said by Goodhart - "Any observed statistical regularity will tend to collapse once pressure is placed upon it for control purposes" - statistical regularities that previously didn't break down in the face of lesser control pressures, can break down in the face of stronger control pressures that effectively search a wider range of possibilities, including possibilities that obey rules you didn't know were rules. This is more likely to happen the more complicated and rich and poorly understood the system is...
### end of quote
...which is how we can be nearly certain, even in advance of knowing the exact method, that a sufficiently strong search against a rating output by a complicated rich poorly-understood human brain will break that brain in ways that we can't even understand.
Even if everything goes exactly as planned on an internal level inside the AGI, which in real life is at least 90% of the difficulty, the outer control structure of the High-Rated Sentence Producer is something that, on the face of it, learns to break the operator. The fact that it's producing sentences more highly rated than a human inside the same box, the very fact that makes the High-Rated Sentence Producer possibly be useful in the first place, implies that it's searching harder against the rating criterion than a human does. Human ratings are imperfect proxies for validity, accuracy, estimated expectation of true value produced by a policy, etcetera. Human brains are rich and complicated and poorly understood. Such integrity as they possess is probably nearly in balance with the ecological expectation of encountering persuasive invalid arguments produced by other human-level intelligences. We should expect with very high probability that if HRSP searches hard enough against the rating, it will break the brain behind it.
Replies from: ricraz, William_S, ofer↑ comment by Richard_Ngo (ricraz) · 2021-01-17T01:16:26.072Z · LW(p) · GW(p)
I think I agree with all of this. In fact, this argument is one reason why I think Debate could be valuable, because it will hopefully increase the maximum complexity of arguments that humans can reliably evaluate.
This eventually fails at some point, but hopefully it fails after the point at which we can use Debate to solve alignment in a more scalable way. (I don't have particularly strong intuitions about whether this hope is justified, though.)
↑ comment by William_S · 2021-01-18T21:30:32.841Z · LW(p) · GW(p)
If the High-Rated Sentence Producer was restricted to output only single steps of a mathematical proof and the single steps were evaluated independently, with the human unable to look at previous steps, then I wouldn't expect this kind of reward hacking to occur. In math proofs, we can build proofs for more complex questions out of individual steps that don't need to increase in complexity.
As I see it, debate on arbitrary questions could work if we figured out how to do something similar, having arguments split into single steps and evaluated independently (as in the recent OpenAI debate work), such that the debate AI can tackle more complicated questions with steps that are restricted to the complexity that humans can currently work with. Hard to know if this is possible, but still seems worth trying to work on.
↑ comment by Ofer (ofer) · 2021-01-17T01:21:49.079Z · LW(p) · GW(p)
One might argue:
We don't need the model to use that much optimization power, to the point where it breaks the operator. We just need it to perform roughly at human-level, and then we can just deploy many instances of the trained model and accomplish very useful things (e.g. via factored cognition).
So I think it's important to also note that, getting a neural network to "perform roughly at human-level in an aligned manner" may be a much harder task than getting a neural network to achieve maximal rating by breaking the operator. The former may be a much narrower target. This point is closely related to what you wrote here [LW · GW] in the context of amplification:
Speaking of inexact imitation: It seems to me that having an AI output a high-fidelity imitation of human behavior, sufficiently high-fidelity to preserve properties like "being smart" and "being a good person" and "still being a good person under some odd strains like being assembled into an enormous Chinese Room Bureaucracy", is a pretty huge ask.
It seems to me obvious, though this is the sort of point where I've been surprised about what other people don't consider obvious, that in general exact imitation is a bigger ask than superior capability. Building a Go player that imitates Shuusaku's Go play so well that a scholar couldn't tell the difference, is a bigger ask than building a Go player that could defeat Shuusaku in a match. A human is much smarter than a pocket calculator but would still be unable to imitate one without using a paper and pencil; to imitate the pocket calculator you need all of the pocket calculator's abilities in addition to your own.
Correspondingly, a realistic AI we build that literally passes the strong version of the Turing Test would probably have to be much smarter than the other humans in the test, probably smarter than any human on Earth, because it would have to possess all the human capabilities in addition to its own. Or at least all the human capabilities that can be exhibited to another human over the course of however long the Turing Test lasts. [...]
↑ comment by Richard_Ngo (ricraz) · 2021-01-17T01:01:13.608Z · LW(p) · GW(p)
If arguments had no meaning but to argue other people into things, if they were being subject only to neutral selection or genetic drift or mere conformism, there really wouldn't be any reason for "the kind of arguments humans can be swayed by" to work to build a spaceship. We'd just end up with some arbitrary set of rules fixed in place.
I agree with this. My position is not that explicit reasoning is arbitrary, but that it developed via an adversarial process where arguers would try to convince listeners of things, and then listeners would try to distinguish between more and less correct arguments. This is in contrast with theories of reason which focus on the helpfulness of reason in allowing individuals to discover the truth by themselves, or theories which focus on its use in collaboration.
Here's how Sperber and Mercier describe their argument:
Reason is not geared to solitary use, to arriving at better beliefs and decisions on our own. What reason does, rather, is help us justify our beliefs and actions to others, convince them through argumentation, and evaluate the justifications and arguments that others address to us.
I can see how my summary might give a misleading impression; I'll add an edit to clarify. Does this resolve the disagreement?
↑ comment by adamShimi · 2021-01-16T21:57:25.013Z · LW(p) · GW(p)
To check if I understand correctly, you're arguing that the selection pressure to use argument in order to win requires the ability to be swayed by arguments, and the latter already requires explicit reasoning?
That seems convincing as a counter-argument to "explicit reasoning in humans primarily evolved not in order to help us find out about the world, but rather in order to win arguments.", but I'm not knowledgeable enough about the work quoted to check if they don't have a more subtle position.
comment by adamShimi · 2021-01-16T17:37:43.082Z · LW(p) · GW(p)
I really like that kind of post! The only thing that I feel is missing is a discussion of what was your privileged research direction before this change of opinion. I assume it was RRM, given how you talk about it, but something like a comparison would be really useful I think.
Still, you give me even more reason to eventually take some time to read all the published work and posts about Debate.
comment by Charlie Steiner · 2021-01-17T08:24:47.634Z · LW(p) · GW(p)
I think the Go example really gets to the heart of why I think Debate doesn't cut it.
The reason Go is hard is that it has a large game tree despite simple rules. When we treat an AI game as information about the value of a state of the Go board, we know exactly what the rules are and how the game should be scored, the superhuman work the AIs are doing is in searching this game tree that's too big for us. The adversarial gameplay provides a check that the search through the game tree is actually finding high-scoring policies.
What does this framework need to apply to moral arguments? That humans "know the rules" of argumentation, that we can recognize good arguments when we see them, and that what we really need help with is searching the game tree of arguments to find high-scoring policies of argumentation.
This immediately should sound a little off. If humans have any exploits (or phrased differently, if there are places where our meta-preferences and our behavior conflict), then this search process will try to find them. We can imagine trying to patch humans (e.g. giving them computer assistants), but this patching process has to already be the process of bringing human behavior in line with human meta-preferences! It's the patching process that's doing all the alignment work, reducing the Debate part to a fancy search for high-approval actions.
No, the dream of Debate is that it's a game where human meta-preferences and behavior are already aligned. For all places where they diverge, the dream is that there's some argument that will point this out and permanently fix it, and that this inconsistency-resolution process does not itself violate too many of our meta-preferences. That Debate is fair like Go is fair - each move is incremental, you can't place a Go stone that changes the layout of the board to make it impossible for your opponent to win.
Replies from: sil-ver↑ comment by Rafael Harth (sil-ver) · 2021-01-17T10:24:57.647Z · LW(p) · GW(p)
I think the Go example really gets to the heart of why I think Debate doesn't cut it.
Your comment is an argument against using Debate to settle moral questions. However, what if Debate is trained on Physics and/or math questions, with the eventual goal of asking "what is a provably secure alignment proposal?"
Replies from: Charlie Steiner↑ comment by Charlie Steiner · 2021-01-17T16:19:16.236Z · LW(p) · GW(p)
Good question. There's a big roadblock to your idea as stated, which is that asking something to define "alignment" is a moral question. But suppose we sorted out a verbal specification of an aligned AI and had a candidate FAI coded up - could we then use Debate on the question "does this candidate match the verbal specification?"
I don't know - I think it still depends on how bad humans are as judges of arguments - we've made the domain more objective, but maybe there's some policy of argumentation that still wins by what we would consider cheating. I can imagine being convinced that it would work by seeing Debates play out with superhuman litigators, but since that's a very high bar maybe I should apply more creativity to my expextations.
Replies from: ricraz↑ comment by Richard_Ngo (ricraz) · 2021-01-17T21:15:03.026Z · LW(p) · GW(p)
suppose we sorted out a verbal specification of an aligned AI and had a candidate FAI coded up - could we then use Debate on the question "does this candidate match the verbal specification?"
I'm less excited about this, and more excited about candidate training processes or candidate paradigms of AI research (for example, solutions to embedded agency). I expect that there will be a large cluster of techniques which produce safe AGIs, we just need to find them - which may be difficult, but hopefully less difficult with Debate involved.