Agent-Simulates-Predictor Variant of the Prisoner's Dilemma
post by Gram_Stone · 2015-12-15T07:17:04.191Z · LW · GW · Legacy · 34 commentsContents
34 comments
I don't know enough math and I don't know if this is important, but in the hopes that it helps someone figure something out that they otherwise might not, I'm posting it.
In Soares & Fallenstein (2015), the authors describe the following problem:
Consider a simple two-player game, described by Slepnev (2011), played by a human and an agent which is capable of fully simulating the human and which acts according to the prescriptions of UDT. The game works as follows: each player must write down an integer between 0 and 10. If both numbers sum to 10 or less, then each player is paid according to the number that they wrote down. Otherwise, they are paid nothing. For example, if one player writes down 4 and the other 3, then the former gets paid $4 while the latter gets paid $3. But if both players write down 6, then neither player gets paid. Say the human player reasons as follows:
"I don’t quite know how UDT works, but I remember hearing that it’s a very powerful predictor. So if I decide to write down 9, then it will predict this, and it will decide to write 1. Therefore, I can write down 9 without fear."
The human writes down 9, and UDT, predicting this, prescribes writing down 1. This result is uncomfortable, in that the agent with superior predictive power “loses” to the “dumber” agent. In this scenario, it is almost as if the human’s lack of ability to predict UDT (while using correct abstract reasoning about the UDT algorithm) gives the human an “epistemic high ground” or “first mover advantage.” It seems unsatisfactory that increased predictive power can harm an agent.
More precisely: two agents A and B must choose integers m and n with 0 ≤ m, n ≤ 10, and if m + n ≤ 10, then A receives a payoff of m dollars and B receives a payoff of n dollars, and if m + n > 10, then each agent receives a payoff of zero dollars. B has perfect predictive accuracy and A knows that B has perfect predictive accuracy.
Consider a variant of the aforementioned decision problem in which the same two agents A and B must choose integers m and n with 0 ≤ m, n ≤ 3; if m + n ≤ 3, then {A, B} receives a payoff of {m, n} dollars; if m + n > 3, then {A, B} receives a payoff of zero dollars. This variant is similar to a variant of the Prisoner's Dilemma with a slightly modified payoff matrix:
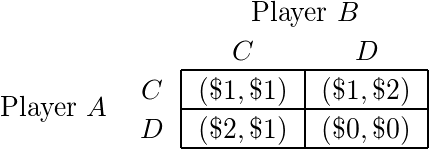
Likewise, A reasons as follows:
If I cooperate, then B will predict that I will cooperate, and B will defect. If I defect, then B will predict that I will defect, and B will cooperate. Therefore, I defect.
And B:
I predict that A will defect. Therefore, I cooperate.
I figure it's good to have multiple takes on a problem if possible, and that this particular take might be especially valuable, what with all of the attention that seems to get put on the Prisoner's Dilemma and its variants.
34 comments
Comments sorted by top scores.
comment by roystgnr · 2015-12-15T14:31:47.804Z · LW(p) · GW(p)
I don't think this quite fits the Prisoner's Dilemma mold, since certain knowledge that the other player will defect makes it your best move to cooperate; in a one-shot Prisoner's Dilemma your payoff is improved by defecting whether the other player defects or not.
The standard 2x2 game type that includes this problem is Chicken.
Replies from: OrphanWilde↑ comment by OrphanWilde · 2015-12-15T14:51:56.832Z · LW(p) · GW(p)
This should be a private message, as it does not actually contribute to the discussion at hand.
Replies from: gjm↑ comment by gjm · 2015-12-15T15:05:30.491Z · LW(p) · GW(p)
Why not? Supposing roystngr to be correct, it's useful information for any reader that if they want to find game-theoretic discussions of related ideas they might want to look for "Chicken" rather than for "Prisoner's Dilemma". Supposing him to be incorrect, other readers might be as well able to correct him as Gram_Stone. Supposing him to be correct, other readers may be able to confirm that, which might be helpful to Gram_Stone.
I think roystngr is correct that the 2x2 matrix here is quite different from that for the PD, and somewhat resembles that of Chicken. It's not quite Chicken because a cooperating player is indifferent between cooperation and defection by the other player, whereas in Chicken a swerving player prefers the other player also to swerve (less loss of face).
Chicken famously has a counterintuitive property similar to the one described here: if you play Chicken with God, then God loses. (You commit to not swerving; God sees this and knows you will not swerve, and therefore must swerve.) I've always thought the obvious conclusion is that if there is a God then he doesn't play Chicken (and if you try to get him to, he refuses or changes the game or the payoff) -- but of course, as pointed out here, the same issue arises with someone who's merely very good at making predictions and doesn't have the other superpowers traditionally ascribed to God, and might therefore actually have nothing better to do than play.
Replies from: OrphanWilde↑ comment by OrphanWilde · 2015-12-15T15:33:29.105Z · LW(p) · GW(p)
Why not? Supposing roystngr to be correct, it's useful information for any reader that if they want to find game-theoretic discussions of related ideas they might want to look for "Chicken" rather than for "Prisoner's Dilemma". Supposing him to be incorrect, other readers might be as well able to correct him as Gram_Stone. Supposing him to be correct, other readers may be able to confirm that, which might be helpful to Gram_Stone.
It's not, as you observe, actually chicken, although it's more closely related to chicken than to the prisoner's dilemma. What it is even more similar to, with the addition of the perfect predictive agent, is the Ultimatum Game, which by the "counterintuitive" property you describe later, God would -also- always lose. (Which I don't know about, one of the properties God is usually described to have is a willingness to punish defectors.)
Which isn't to contribute to the terminology debate, but to point out that the discussion isn't actually furthered by endless debates over how to classify edge cases.
Replies from: gjm↑ comment by gjm · 2015-12-15T16:05:33.565Z · LW(p) · GW(p)
(Which I don't know about, one of the properties God is usually described to have is a willingness to punish defectors.)
If God values punishing defectors enough, then that changes the effective payoffs in the game.
If God's predictive abilities matter, then I take it you're envisaging God in the role of proposer rather than responder, and the sense in which he loses is that e.g. the responder can commit to declining any offer less than (say) $9 from an initial stake of $10, so that God only gets $1. Well. The responder can do that against anyone, perfect predictor or not, and God actually does better than anyone else because he can at least offer the $9 he needs to. But I suppose the point is that the responder wouldn't make that commitment if not playing against God, because without God's magical foreknowledge the predictor won't be offering $9 anyway.
So, anyway, if I understand your parenthesis right, you're saying that it won't play out that way because for the responder to decline a reasonable offer is a variety of defection, and God will want to punish it by refusing to make the offer the responder wants. Perhaps so, but what that means is that God's true payoff isn't (say) $1 but $1 plus the fact of the responder's successful defection, and if he disvalues the second component of that enough it could be worse than $0. Which is true, but it means that they're no longer playing the Ultimatum Game, they're playing another game with different payoffs, and of course that can lead to different choices.
comment by SilentCal · 2015-12-15T21:58:54.779Z · LW(p) · GW(p)
Yes, stupidity can be an advantage. A literal rock can defeat any intelligent opponent at chicken, if it's resting on the gas pedal (the swerve-to-avoid-collision version, rather than the brake-closer-to-the-cliff-edge version).
The catch is that you making yourself dumber to harvest this advantage has the same issues as other ways of trying to precommit.
Replies from: Lumifer↑ comment by Lumifer · 2015-12-15T22:29:50.668Z · LW(p) · GW(p)
stupidity can be an advantage. A literal rock can defeat any intelligent opponent at chicken, if it's resting on the gas pedal
The advantage of a rock is not that it is stupid. The advantage of a rock is that it has nothing to lose -- it is indifferent between all outcomes.
Replies from: SilentCal↑ comment by SilentCal · 2015-12-15T23:11:28.460Z · LW(p) · GW(p)
We can model a rock either as having no preferences, but we can also model it as having arbitrary preferences--including the appropriate payout matrix for a given game--and zero ability to optimize the world to achieve them. We observe the same thing either way.
Replies from: Lumifer↑ comment by Lumifer · 2015-12-16T01:26:01.920Z · LW(p) · GW(p)
Given that we observe the same thing no matter how we model the rock, I'm not sure what that proves.
Replies from: SilentCal↑ comment by SilentCal · 2015-12-16T19:28:05.234Z · LW(p) · GW(p)
The rock wins at chicken, for any model that accurately describes its behavior. One such model is as an agent with a game-appropriate utility function and zero intelligence. Therefore, an agent with a game-appropriate utility function and zero intelligence wins at chicken (in the case as constructed).
It proves that we can construct a game where the less intelligent player's lack of intelligence is an advantage. OP shows the same, but I find the rock example simpler and clearer--I especially find it illuminates the difficulties with trying to exploit the result.
Replies from: Lumifer, Dagon, Tem42↑ comment by Lumifer · 2015-12-16T20:18:46.767Z · LW(p) · GW(p)
It proves that we can construct a game where the less intelligent player's lack of intelligence is an advantage.
That's pretty trivial. Any time you do something to avoid unpleasantness (e.g. not jump off the roof of a tall building), you can frame it as a game where you lose and some feature of the environment cast as an unintelligent player (e.g. gravity) wins.
↑ comment by Tem42 · 2015-12-16T22:40:32.190Z · LW(p) · GW(p)
I think it demonstrates something stronger -- we have, as humans, already developed a game (Chicken) with very meaningful outcomes in which lower intelligence is beneficial, despite the fact that the humans in questions were not intending to select for low IQ and would not have seen a rock as a valid player.
If we are talking about Chicken we do not have to assume a rock (which has no preference), but simply a human with bad judgement, or slow reactions, or who is panicking.
So,
I'm not sure what that proves.
Well, 'proof' aside, it demonstrates that:
stupidity can be an advantage
Among other apparently maladaptive responses.
comment by gjm · 2015-12-15T15:11:36.595Z · LW(p) · GW(p)
I'm not sure it's really more counterintuitive that (known) ability to predict can be a disadvantage than it is that (known) having more options can be a disadvantage.
In this case, predictability is an advantage because it allows you to make binding commitments; in other words, to visibly eliminate options that would otherwise be available to you. And (see, e.g., Schelling) the ability to visibly eliminate some of your own options is very often valuable, because those options might be ones whose possibility gives the other player reason to do something that would be bad for you.
In this case, A's predictability effectively takes the possibility that A might cooperate out of the picture for B, which means that B no longer has reason to defect.
(The examples in Schelling, IIRC, tend to be of an opposite kind, more like the PD, where the ability to assure the other player that you won't defect is advantageous for both parties.)
Replies from: Gram_Stone, Lumifer↑ comment by Gram_Stone · 2015-12-16T01:40:13.769Z · LW(p) · GW(p)
I'm not sure it's really more counterintuitive that (known) ability to predict can be a disadvantage than it is that (known) having more options can be a disadvantage.
I wonder if it might be fruitful to think generally about decision theories in terms of their ability to rule out suboptimal decisions, as opposed to their ability to select the optimal decision.
I also wanted you to read something I wrote below:
When described in this way, I am reminded that I would be very interested to see this sort of problem examined in the modal agents framework. I have to flag that I lack a technical understanding of this sort of thing, but it seems like we can imagine the agents as formal systems, with B stronger than A, and A forcing B to prove that A defects by making it provable in A that A defects, and since B is stronger than A, it is also provable in B that A defects.
Also, there are variants with imperfect predictors:
It can be shown that A behaves precisely as an agent would if it cooperates with an arbitrary agent C if P(C predicts A defects | A defects) is less than 0.5, is indifferent if that probability equals 0.5, and defects if that probability is greater than 0.5.
Suppose that B's predictive accuracy is greater than 50 percent. Then the expected utility of A defecting is 2p + 0(1 - p), and the expected utility of A cooperating is 1p + 1(1 - p), and the expected utility of defection is greater than that of cooperation. Plug in numbers if you need to. There are similar proofs that if B's predictions are random, then A is indifferent, and if B's predictive ability is less than 50 percent, then A cooperates.
↑ comment by Lumifer · 2015-12-15T19:58:48.132Z · LW(p) · GW(p)
In this case, predictability is an advantage because it allows you to make binding commitment
In this case the human did not make any binding commitments.
Not to mention that it's UDP that is predictable.
Replies from: gjm↑ comment by gjm · 2015-12-15T23:29:10.318Z · LW(p) · GW(p)
the human did not make any binding commitments.
The human did something functionally equivalent to making binding commitments.
it's UDP that is predictable
Nope, TCP :-).
(If you meant UDT or something of the kind: the claim being made in the OP is that a good implementation of UDT will be very good at predicting, not that it will be very predictable.)
Replies from: Lumifer↑ comment by Lumifer · 2015-12-16T01:30:21.803Z · LW(p) · GW(p)
The human did something functionally equivalent to making binding commitments.
Unless you want to screw around with terminology, making a move in a game is not "making a binding commitment". It's making a move.
the claim being made in the OP
Let's look at the OP:
So if I decide to write down 9, then it will predict this, and it will decide to write 1. Therefore, I can write down 9 without fear.
This is predicting the opponent's response. Since UDT (according to the OP) does write down 1, the prediction is accurate.
UDT looks very predictable to me in this case.
Replies from: gjm↑ comment by gjm · 2015-12-16T03:18:25.051Z · LW(p) · GW(p)
It isn't making a move that I suggested was equivalent to making a binding commitment. (In this case, it's working out one's best strategy, in the presence of a perfect predictor.) It's equivalent in the sense that both have the effect of narrowing the options the other player thinks you might take. That's not a good notion of equivalence in all contexts, but I think it is here; the impact on the game is the same.
Yes, there are situations in which UDT-as-understood-by-the-OP produces predictable results. That doesn't mean that UDT (as understood etc.) Is consistently predictable, and it remains the case that the OP explicitly characterized the UDT-using agent as a superhumanly effective predictor.
comment by Lumifer · 2015-12-15T15:47:36.481Z · LW(p) · GW(p)
What some comments are missing is that not only UDT is a perfect predictor, but apparently the human is, too. The human fully and correctly predicts the UDT response.
So, in effect, we have a game between two agents which can and do predict the responses of each other. What's the difference? It seems that one has "free will", in that she can be agenty and the other one does not and is condemned only to react. Of course the only-react entity loses.
Take away the ability to predict from the human (e.g. by adding randomness to UDT decisions) and see if it's still optimal to put 9 down.
Replies from: Gram_Stone, Gram_Stone, Gram_Stone↑ comment by Gram_Stone · 2015-12-16T00:16:48.705Z · LW(p) · GW(p)
What some comments are missing is that not only UDT is a perfect predictor, but apparently the human is, too. The human fully and correctly predicts the UDT response.
A doesn't have perfect predictive accuracy. A merely knows that B has perfect predictive accuracy. If A is pitted against a different agent with sufficiently small predictive accuracy, then A cannot predict that agent's actions well enough to cause outcomes like the one in this problem.
Consider a variant in which A is replaced by DefectBot. It seems rational for UDT to cooperate. The parameters of the decision problem are not conditional on UDT's own decision algorithm (all agents in this scenario must choose between payoffs of $0 and $1), and cooperating maximizes expected utility. But what we have just described is a very different game. DefectBot always defects, but AFAICT, it can be shown that A behaves precisely as an agent would if it cooperates with an arbitrary agent C if P(C predicts A defects | A defects) is less than 0.5, is indifferent if that probability equals 0.5, and defects if that probability is greater than 0.5.
Suppose that C's predictive accuracy is greater than 50 percent. Then the expected utility of A defecting is 2p + 0(1 - p), and the expected utility of A cooperating is 1p + 1(1 - p), and the expected utility of defection is greater than that of cooperation. Plug in numbers if you need to. There are similar proofs that If B's predictions are random, then A is indifferent, and if B's predictive ability is less than 50 percent, then A cooperates.
If we played an iterated variant of this game, then the expected value of the sequence of payoffs to A will almost surely exceed the expected value of the sequence of payoffs to B. The important thing is that in our game, UDT seems to be penalized for its predictive accuracy when it plays against agents like A despite dominating other decision theories that 'win' on this problem in other problem classes.
When described in this way, I am reminded that I would be very interested to see this sort of problem examined in the modal agents framework. I have to flag that I lack a technical understanding of this sort of thing, but it seems like we can imagine the agents as formal systems, with B stronger than A, and A forcing B to prove that A defects by making it provable in A that A defects, and since B is stronger than A, it is also provable in B that A defects.
Take away the ability to predict from the human (e.g. by adding randomness to UDT decisions) and see if it's still optimal to put 9 down.
I'm not sure what precisely you mean by "add randomness", but if you mean "give UDT less than perfect predictive accuracy," then as I have shown above, and as in Newcomb's problem, there are variants of this game in which UDT has predictive accuracy greater than 50% but less than 100% and in which the same outcome obtains. Any other interpretation of "add randomness" that I can think of simply results in an agent that we call a UDT agent but that is not one.
Replies from: Lumifer, Lumifer↑ comment by Lumifer · 2015-12-16T01:46:19.685Z · LW(p) · GW(p)
A doesn't have perfect predictive accuracy.
In your setup it does. It is making accurate predictions, doesn't it? Always?
Replies from: Gram_Stone↑ comment by Gram_Stone · 2015-12-16T02:13:30.612Z · LW(p) · GW(p)
Say that agent A is zonkerly predictive and agent B is pleglishly predictive. A's knowledge about B's predictive accuracy allows A to make an inference that leads from that knowledge to a deduction that B will cooperate if A defects. B can predict every action that A will take. It's the difference between you reasoning abstractly about how else a program must work given your current understanding of how it works, and running the program.
Replies from: Lumifer↑ comment by Lumifer · 2015-12-16T05:36:43.982Z · LW(p) · GW(p)
As long as you are always making accurate predictions, does the distinction matter?
Replies from: cousin_it↑ comment by cousin_it · 2015-12-16T13:31:48.045Z · LW(p) · GW(p)
Yes, you can make the distinction mathematically precise, as I did in this post (which is the "Slepnev 2011" reference in the OP).
Replies from: Lumifer↑ comment by Gram_Stone · 2015-12-16T00:14:09.704Z · LW(p) · GW(p)
What some comments are missing is that not only UDT is a perfect predictor, but apparently the human is, too. The human fully and correctly predicts the UDT response.
A doesn't have perfect predictive accuracy. A merely knows that B has perfect predictive accuracy. If A is pitted against a different agent with sufficiently small predictive accuracy, then A cannot predict that agent's actions well enough to cause outcomes like the one in this problem.
Consider a variant in which A is replaced by DefectBot. It seems rational for UDT to cooperate. The parameters of the decision problem are not conditional on UDT's own decision algorithm (all agents in this scenario must choose between payoffs of $0 and $1), and cooperating maximizes expected utility. But what we have just described is a very different game. DefectBot always defects, but AFAICT, it can be shown that A behaves precisely as an agent would if it cooperates with an arbitrary agent C if P(C predicts A defects | A defects) is less than 0.5, is indifferent if that probability equals 0.5, and defects if that probability is greater than 0.5.
Suppose that C's predictive accuracy is greater than 50 percent. Then the expected utility of A defecting is 2p + 0(1 - p), and the expected utility of A cooperating is 1p + 1(1 - p). Plug in numbers if you need to. There are similar proofs that If B's predictions are random, then A is indifferent, and if B's predictive ability is less than 50 percent, then A cooperates.
If we played an iterated variant of this game, then the expected value of the sequence of payoffs to A will almost surely exceed the expected value of the sequence of payoffs to B. The important thing is that in our game, UDT seems to be penalized for its predictive accuracy when it plays against agents like A despite dominating other decision theories that 'win' on this problem in other problem classes.
When described in this way, I am reminded that I would be very interested to see this sort of problem examined in the modal agents framework. I have to flag that I lack a technical understanding of this sort of thing, but it seems like we can imagine the agents as formal systems, with B stronger than A, and A forcing B to prove that A defects by making it provable in A that A defects, and since B is stronger than A, it is also provable in B that A defects.
Take away the ability to predict from the human (e.g. by adding randomness to UDT decisions) and see if it's still optimal to put 9 down.
I'm not sure what precisely you mean by "add randomness", but if you mean "give UDT less than perfect predictive accuracy," then as I have shown above, and as in Newcomb's problem, there are variants of this game in which UDT has predictive accuracy greater than 50% but less than 100% and in which the same outcome obtains. Any other interpretation of "add randomness" that I can think of simply results in an agent that we call a UDT agent but that is not one.
↑ comment by Gram_Stone · 2015-12-16T00:12:35.811Z · LW(p) · GW(p)
What some comments are missing is that not only UDT is a perfect predictor, but apparently the human is, too. The human fully and correctly predicts the UDT response.
A doesn't have perfect predictive accuracy. A merely knows that B has perfect predictive accuracy. If A is pitted against a different agent with sufficient small predictive accuracy, then A cannot predict that agent's actions well enough to cause outcomes like the one in this problem.
Consider a variant in which A is replaced by DefectBot. It seems rational for UDT to cooperate. The parameters of the decision problem are not conditional on UDT's own decision algorithm (all agents in this scenario must choose between payoffs of $0 and $1), and cooperating maximizes expected utility. But what we have just described is a very different game. DefectBot always defects, but AFAICT, it can be shown that A behaves precisely as an agent would if it cooperates with an arbitrary agent C if P(C predicts A defects | A defects) is less than 0.5, is indifferent if that probability equals 0.5, and defects if that probability is greater than 0.5.
Suppose that C's predictive accuracy is greater than 50 percent. Then the expected utility of A defecting is 2p + 0(1 - p), and the expected utility of A cooperating is 1p + 1(1 - p). Plug in numbers if you need to. There are similar proofs that If B's predictions are random, then A is indifferent, and if B's predictive ability is less than 50 percent, then A cooperates.
If we played an iterated variant of this game, then the expected value of the sequence of payoffs to A will almost surely exceed the expected value of the sequence of payoffs to B. The important thing is that in our game, UDT seems to be penalized for its predictive accuracy when it plays against agents like A despite dominating other decision theories that 'win' on this problem in other problem classes.
When described in this way, I am reminded that I would be very interested to see this sort of problem examined in the modal agents framework. I have to flag that I lack a technical understanding of this sort of thing, but it seems like we can imagine the agents as formal systems, with B stronger than A, and A forcing B to prove that A defects by making it provable in A that A defects, and since B is stronger than A, it is also provable in B that A defects.
Take away the ability to predict from the human (e.g. by adding randomness to UDT decisions) and see if it's still optimal to put 9 down.
I'm not sure what precisely you mean by "add randomness", but if you mean "give UDT less than perfect predictive accuracy," then as I have shown above, and as in Newcomb's problem, there are variants of this game in which UDT has predictive accuracy greater than 50% but less than 100% and in which the same outcome obtains. Any other interpretation of "add randomness" that I can think of simply results in an agent that we call a UDT agent but that is not one.
comment by Dagon · 2015-12-17T00:47:11.646Z · LW(p) · GW(p)
I still don't see the controversy. A communicated, believable precommittment is powerful in any negotiation. There are a lot easier ways to show this than making up perfect predictors.
In these games, if one of the players shows their move and leaves the room before the other player has made theirs, the same outcome occurs.