Architecture-aware optimisation: train ImageNet and more without hyperparameters
post by Chris Mingard · 2023-04-22T21:50:49.795Z · LW · GW · 2 commentsContents
2 comments
A deep learning system is composed of lots of interrelated components: architecture, data, loss function and gradients. There is a structure in the way these components interact - however, the most popular optimisers (e.g. Adam and SGD) do not utilise this information. This means there are leftover degrees of freedom in the optimisation process - which we currently have to take care of via manually tuning their hyperparameters (most importantly, the learning rate). If we could characterise these interactions perfectly, we could remove all degrees of freedom, and thus remove the need for hyperparameters.
Second-order methods characterise the sensitivity of the objective to weight perturbations using implicit architectural information via the Hessian, and remove degrees of freedom that way. However, such methods can be computationally intensive and thus not practical for large models.
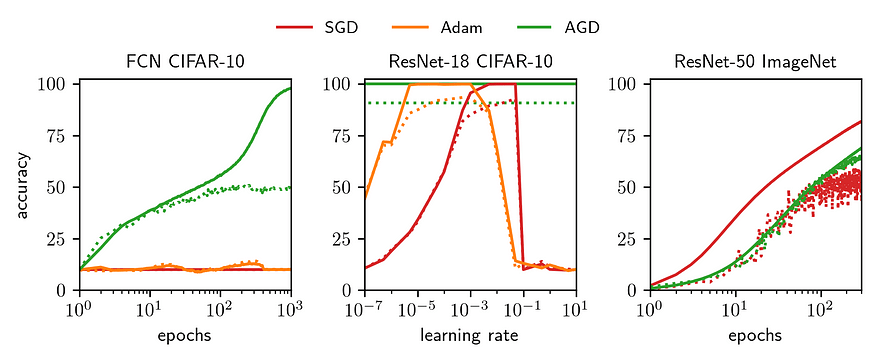
I worked with Jeremy Bernstein on leveraging explicit architectural information to produce a new first-order optimisation algorithm: Automatic Gradient Descent (AGD). With computational complexity no greater than SGD, AGD trained all architectures and datasets we threw at it without needing any hyperparameters: from a 2-layer FCN on CIFAR10 to ResNet50 on ImageNet. Where tested, AGD achieved comparable test accuracy to tuned Adam and SGD.
Anyone interested in the derivation, PyTorch code, or experiments might be interested in any of the following links, or the summary figure below.
- Here is a link to a blog post I wrote summarising the paper.
- Here is a link to the paper
- Here is a link to the official GitHub
- Here is a link to an experimental GitHub where we test AGD on systems not yet in the paper (including language models).
Hopefully, the ideas in the paper will form the basis of a more complete understanding of optimisation in neural networks - as discussed in the paper, there are a few applications that need to be fully fleshed out. The derivation relies on an architectural perturbation bound (bounding the sensitivity of the function to changes in weights) based on a fully connected network with linear activations and no bias terms - however, empirically it works extremely well. Our experiments therefore did not use bias terms, nor affine parameters.
However, the version of AGD in the experimental GitHub supports 1D parameters like bias terms and affine parameters (implemented in the most obvious way, although requiring further theoretical justification), and preliminary experiments indicate good performance. Preliminary experiments on GPT2-scale language models on OpenWebText2 are also promising.
If anyone has any feedback or suggestions, please let me know!
2 comments
Comments sorted by top scores.
comment by gwern · 2023-04-23T21:39:46.266Z · LW(p) · GW(p)
So, this is another learning-rate tuner. What are the prospects for the many other kinds of hyperparameters? Even stuff like arch size still require the equivalent of hyperparameter tuning to decide on the compute-optimal scaling.
Replies from: Chris Mingard↑ comment by Chris Mingard · 2023-04-24T15:50:54.887Z · LW(p) · GW(p)
AGD can train any architecture, dataset and batch size combination (as far as we have tested), out-of-the-box. I would argue that this is a qualitative change to the current methods, where you have to find the right learning rate for every batch size, architecture and dataset combination, in order to converge in an optimal or near-optimal time. I think this is a reasonable interpretation of "train ImageNet without hyperparameters". That said, there is a stronger sense of "hyperparameter-free" where the optimum batch size and architecture size would decide on the compute-optimal scaling. And, an even stronger sense where the architecture type is selected.
In other words, we have the following hierarchy of lack of hyperparameterness,
- learning rate must be selected, sometimes with schedulers etc. or via heuristics, to guarantee convergence for any architecture, dataset, batch size ...
- pick and architecture, dataset and batch size and it will converge (hopefully) in a near-optimal time
- compute-optimal batch size and architecture size is automatically found for a dataset
- given a dataset, we are given the best architecture type (e.g. resnet, CNN etc.)
I would argue that we currently are in stage 1. If AGD (or similar optimisers) do actually work like we think, we're now in stage 2. In my mind, this is a qualitative change.
So, I think calling it "another learning-rate tuner" is a little disingenuous - incorporating information about the architecture seems to move in a direction of eliminating a hyperparameter by removing a degree of freedom, rather than a "learning rate tuner" whichI think of as a heuristic method usually involving trial-and-error, without any explanation for why that learning rate is best. However, if there are similar papers out there already that you think do something similar, or you think I'm wrong in any way, please send them over, or let me know!