Tiny Mech Interp Projects: Emergent Positional Embeddings of Words
post by Neel Nanda (neel-nanda-1) · 2023-07-18T21:24:41.990Z · LW · GW · 1 commentsContents
Introduction Experiments Conceptual Subtleties + Commentary What are the limitations of my experiment Next Steps Natural next experiments to run Finding a circuit! Appendix: Technical details of the experiment None 1 comment
This post was written in a rush and represents a few hours of research on a thing I was curious about, and is an exercise in being less of a perfectionist. I'd love to see someone build on this work! Thanks a lot to Wes Gurnee for pairing with me on this

Introduction
A particularly notable observation in interpretability in the wild is that part of the studied circuit moves around information about whether the indirect object of the sentence is the first or second name in the sentence. The natural guess is that heads are moving around the absolute position of the correct name. But even in prompt formats where the first and second names are in the different absolute positions, they find that the informations conveyed by these heads are exactly the same, and can be patched between prompt templates! (credit to Alexandre Variengien for making this point to me).
This raises the possibility that the model has learned what I call emergent positional embeddings - rather than representing "this is the token in position 5" it may represent "this token is the second name in the sentence" or "this token is the fourth word in the sentence" or "this is the third sentence in the paragraph" etc. Intuitively, models will often want to do things like attend to the previous word, or the corresponding word in the previous sentence, etc - there are lots of things it will plausibly want to do that are natural in some emergent coordinate scheme that are unnatural in the actual token coordinate scheme.
I was curious about this, and spent an afternoon poking around with Wes Gurnee at whether I could convince myself that these emergent positional embeddings were a thing. This post is an experiment: I'm speedrunning a rough write-up on a few hours of hacky experiments, because this seemed more interesting to write-up than not to, and I was never going to do the high-effort version. Please take all this with a mountain of salt, and I'd love to see anyone build on my incredibly rough results - code here.
Experiments
You can see some terrible code for these experiments here. See the Appendix for technical details
I wanted to come up with the dumbest experiment I could that could shed light on whether this was a thing. One thing that models should really care about is the ability to attend to tokens in the previous word. Words can commonly range from 1 to 3 tokens (and maybe much longer for rare or mispelt words) so this is naturally done with an emergent scheme saying which word a token is part of.
My experiment: I took prompts with a fixed prefix of 19 tokens and then seven random lowercase English words of varying token length, like token|izer| help| apple| dram|at|isation| architecture| sick| al|p|aca. I ran GPT-2 Small on this, look the residual stream after layer 3 (33% of the way through the model) and then trained a logistic regression probe on the residual stream of the token at the end of each word to predict which word it was in.
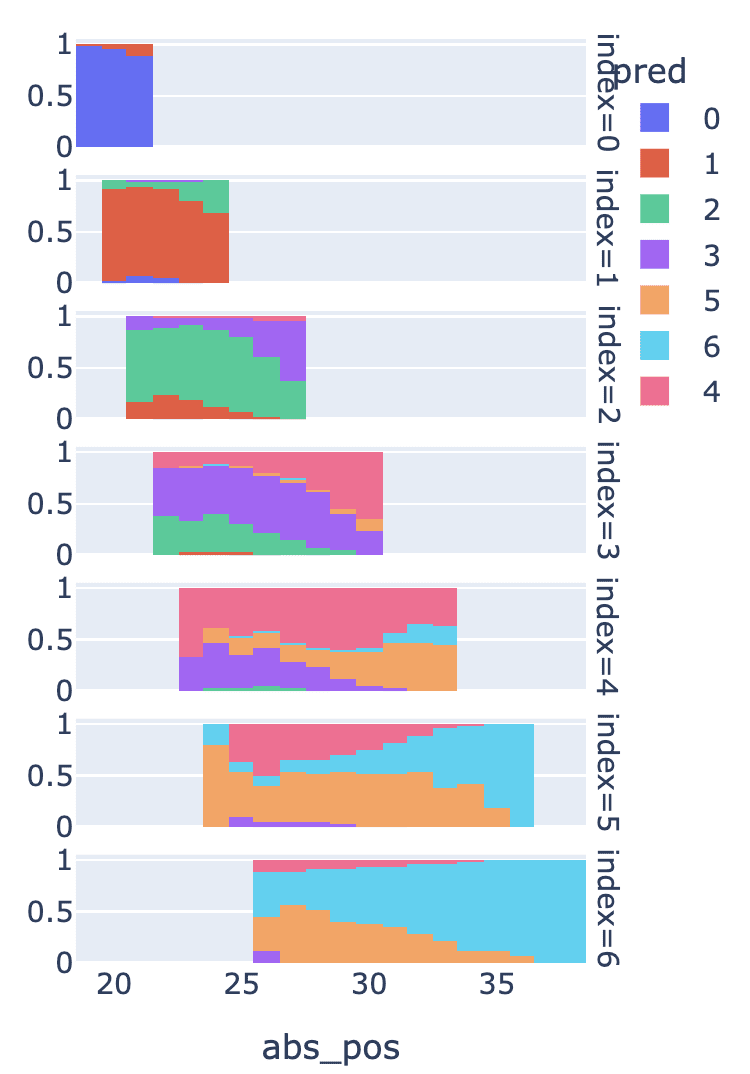
This is the key plot, though it takes a bit of time to get your head around. The x axis is the absolute position of the token in the prompt and the row is the ground truth of the word index. The bar for each absolute position and row shows the distribution of guesses given on the probe validation set. The colours correspond to the seven possible indices (note that the legend is not in numerical order, sigh).
For example: take the third bar in the second row (index=1, abs_pos=22). This is mostly red (index = 1, correct!), with a bit of blue at the bottom (index = 0, incorrect) and a bit of green at the top (index = 2, incorrect). In contrast, the bar in the row below (second bar in the third row, index=2, abs_pos=23) is mostly green, showing that despite having the same absolute position, the probe can tell that it's mostly index=2, with a bit of red error (index=1) and purple error (index=3)
Key observations from this plot:
- The probe works at all! The model tracks this feature!
- I forgot to write down the actual probe accuracy lol (and banned myself from running code while writing this post), but eyeballing the graph makes pretty clear that the probe can do this!
- This is not just absolute position! You can see this on any fixed column - despite absolute position being the same, the distribution of word index guesses is strongly skewed towards the correct word index.
- This is clearest in early words, where eg word two vs word three is extremely clear at any column!
- The feature is much weaker and harder to pick up on for later words (or corrupted by the correlation with absolute position), and performance is much worse.
- It's still visibly much better than random, but definitely messy, discussed more in the limitations section
Conceptual Subtleties + Commentary
Why might models care about emergent positional embeddings at all? One of the weirdnesses of transformers is that, from the perspective of attention, every previous token position looks similar regardless of how far back it is - they're just as easy to attend to! The standard way of dealing with this is various hacks to hard-code knowledge of positional info, like rotary, or absolute positional embeddings. But tokens are a pretty weird format, different things of the same conceptual "length" can get split into wildly varying numbers of tokens, eg " Alexander" -> " Alexander" while " Neel" -> " Ne" "el" (apparently Neel isn't as popular a name :'( ).
It's also plausible that being able to move around creative positional schemes is just much more efficient than actual token values. In indirect object identification part of the circuit tracks the position of the indirect object (two possible values, 1 bit) and the token value (hundreds to thousands of possible names!), the position just seems vastly more efficient!
Why should we care if this happens? Honestly I mostly think that this would just be cool! But it seems pretty important to understand if it does occur, since I expect this to be a sizable part of what models are doing internally - moving these around in creative ways, and computing more complex emergent positional schemes. If we don't understand the features inside the model or the common motifs, it seems much harder to understand what's actually going on. And it's plausible to me that quite a lot of sophisticated attention head circuitry looks like creative forms of passing around emergent positional embeddings. Also, just, this was not a hypothesis I think I would have easily naturally thought of on my own, and it's useful to know what you're looking for when doing weird alien neuroscience.
Models are probably bad at counting: One observation is that my probe performance gets much worse as we get to later words. I'm not confident in why, but my weak intuition is that counting in this organic, emergent way is just pretty hard! In particular, I'd guess that heads need an "anchor" nearby like a full stop or newline or comma such that they count from there onwards. Eg they have attn score 3 to the full stop and then 1 to each token beginning with a space, -inf to everything else. And the OV just accumulates things beginning with a space. This creates big difference for early words but washes out later on.
This hypothesis predicts that models do not do anything like tracking "I am word 98" etc, but rather "I am the third word in the fifth sentence" etc. Since I imagine models mostly care about local attention to recent words/sentences/etc this kind of nearby counting seems maybe sufficient.
What are the limitations of my experiment
- I didn't balance absolute position between the classes, so the probes should partially pick up on absolute position
- The probes may also pick up on "begins with a space" - this implies that it's a one token word (as I gave in the last token) which implies that it's a later word index for a fixed absolute position, and is an easy to detect linear feature.
- I didn't show that the probe directions were at all used by the model, or even that it uses these absolute positional embeddings at all
- An alternate hypothesis: There's a direction for tokens beginning with a space. There are heads that attend strongly to the most recent full-stop and with a small constant-ish amount to all tokens in the sentence (which are used in unrelated circuitry), such that the probe can just detect the strength of the "begins with space" direction to compute the embedding
- Though this doesn't explain why the probe can correctly predict intermediate word positions rather than just 0 or 6
- The obvious idea would be looking for attention heads whose patterns respond to word-level structure, eg attending to the first or last token of the previous word, and seeing if ablating the probe directions changes the attention patterns of the heads
- An alternate hypothesis: There's a direction for tokens beginning with a space. There are heads that attend strongly to the most recent full-stop and with a small constant-ish amount to all tokens in the sentence (which are used in unrelated circuitry), such that the probe can just detect the strength of the "begins with space" direction to compute the embedding
- I used a fairly dumb and arbitrary prefix, and also proceeded to not change it. I'm interested in what happens if you repeat this experiment with a much longer or shorter prefix, or what happens if you apply the probe
- I arbitrary chose layer 3 and only looked at that lol.
Next Steps
Natural next experiments to run
- Making a dataset balanced for absolute position (maybe also absolute position in the current line/sentence), eg probing for third vs fourth word for things at absolute position 25
- Fixing various rough edges in my work, like varying the prefix
- Do the results look the same if you just give it a random sequence of tokens that do/don't begin with a space, but aren't words at all? What if you make the "words" extremely long?
- What is probe performance at different layers? What's the earliest layer where it works?
- What do these directions mean in general? If we take arbitrary text and visualise the probe outputs by token, do we see any clear patterns?
- Can we find other reference schemes? Eg tracking the nth subject or name or adjective in a sentence? The nth item in a list? The nth sentence in a paragraph? The nth newline in code? etc.
- Looking for heads that have attention patterns implying some emergent scheme: heads that attend to the first token of the current word, first/last token of the previous word, most recent full stop, full stop of the previous sentence, etc.
- Note that there are alternate hypotheses for these, and you'd need follow-up work. Eg, "attending to the first token of the current word" could be done by strongly attending to any token beginning with a space, and have a strong positional decay that penalises far away tokens.
- If you find anything that uses them, using this as a spring board to try to understand a circuit using them would be great!
- Try resample ablating the probe directions on general text and see if anything happens.
- The heads in the previous point may be good places to look.
Finding a circuit!
- The core thing I'd be excited about is trying to figure out the circuit that computes these!
- My guess: The embedding has a direction saying "this token begins with a space". The model uses certain attention heads to attend to all recent tokens beginning with a space, in eg the current sentence. There's a high score on the newline/full stop at the start of the sentence, a small score on space prepended tokens, and -inf on everything else. The head's OV circuit only picks up on the "I have a space" direction and gets nothing from the newline. For small numbers of words, the head's output will be in a fixed direction with magnitude proportional to the number of words, and an MLP layer can be used to "sharpen" that into orthogonal directions for each word index.
- My angle of attack for circuit finding:
- Find the earliest layer where the probe works and focus there
- Find some case study where I can do activation patching in a nice and token aligned way, eg a 3|1 setting vs a 1|2|1 setting and patching between activations on the fourth token to see why the second vs third word probe work in the two cases.
- Note that I'd be doing activation patching to just understand the circuit in the first few layers. The "patching metric" would be the difference in probe logits between the second and third word index, and would have nothing to do with the model logits.
- Do linear attribution to the probe direction - which heads/neurons/MLP layers most contribute to the probe direction? (the same idea as direct logit attribution).
- This might be important/common enough to get dedicated neurons, which would be very cool!
- Resample/mean ablate heads and MLP layers to see which ones matter.
- Look at the attention patterns of the key heads and see if they have anything like the pattern predicted
Appendix: Technical details of the experiment
Meta - I was optimising for moving fast and gettingsomeresults, which is why the below are extremely hacky. See my terrible code for more.
- This is on layer 3 of GPT-2 Small (it was a small model but probably smart enough for this task, and 'early-mid' layers felt right like the right place to look)
- The probes are trained on 10,000 data points, and validated on 2560 * 7 data points (one for each word index)
- I used the scikit-learn logistic regression implementation, with default hyperparameters
- I gave it a dictionary of common english words, all fed in as lower case strings preceded by a space (for a nice consistent format) for lengths 1 to 3 tokens. I uniformly chose the token length and then uniformly chose a token of that length. I couldn't be bothered to filter for eg "length 3 words are not repeated in this prompt" or "these words actually make sense together"
- I didn't bother to do further filtering for balanced absolute position, so absolute position will correlate with the correct answer
- I took 80% of the dictionary to generate prompts in my probe training set, and the other 20% of the dictionary to generate prompts in my probe validation set, just to further reduce confounders
- I gave the 19-ish token prefix: "The United States Declaration of Independence received its first formal public reading, in Philadelphia.\nWhen".
- I wanted some generic filler text because early positions are often weird, followed by a newline to reset
- I wanted a single token to start the sentence that did not begin with a space and had a capital, so that the rest of the tokens could all begin with a space and be lowercase
- The token lengths are uniformly chosen, so for given word index the absolute position is binomially distributed - this means that there's high sample size in the middle and tiny at the ends.
- I trained my probe on the last token of each word. I predict this doesn't matter, but didn't check.
- Note the subtlety that the first token begins with a space and is obviously a new word, while identifying the last token is less obvious - maybe the next token is part of the same word! Thus I guessed that doing the last token is harder, especially for earlier words, and so more impressive.
1 comments
Comments sorted by top scores.
comment by Bary Levy (bary-levi) · 2023-07-20T01:19:38.684Z · LW(p) · GW(p)
I want to generally encourage this kind of experiment-and-publish-quickly project. This might require a post of its own, but as someone with a background in both hacking and entrepreneurship, this kind of quick feedback loop is, in my opinion, an incredible strength of both, and I hope can be used to accelerate scientific progress, which is exactly what we need in alignment.