Open Problems and Fundamental Limitations of RLHF
post by scasper · 2023-07-31T15:31:28.916Z · LW · GW · 6 commentsThis is a link post for https://arxiv.org/abs/2307.15217
Contents
Abstract Contributions Transparency RLHF = Rehashing Lessons from Historical Failures? Future Work None 6 comments
Reinforcement Learning from Human Feedback (RLHF) has emerged as the central alignment technique used to finetune state-of-the-art AI systems such as GPT-4, Claude, Bard, and Llama-2. Given RLHF's status as the default industry alignment technique, we should carefully evaluate its shortcomings. However, there is little public work formally systematizing problems with it.
In a new survey of over 250 papers, we review open challenges and fundamental limitations with RLHF with a focus on applications in large language models.
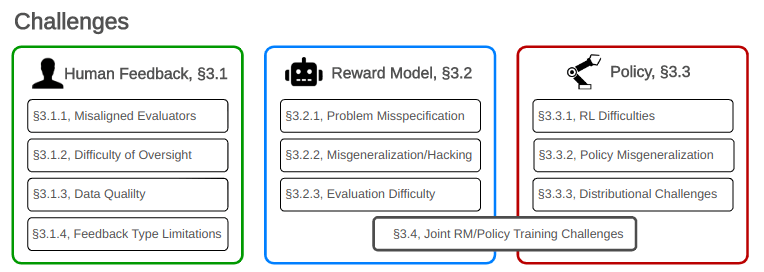
Abstract
Reinforcement learning from human feedback (RLHF) is a technique for training AI systems to align with human goals. RLHF has emerged as the central method used to finetune state-of-the-art large language models (LLMs). Despite this popularity, there has been relatively little public work systematizing the challenges it poses. In this paper, we (1) survey concrete challenges and open questions with RLHF; (2) overview techniques to better understand, improve, and complement it in practice; and (3) discuss how standards for transparency and auditing could help to reduce risks. We emphasize the importance of recognizing the limitations of RLHF and integrating it into a more complete framework for developing safer AI.
Contributions
- Concrete challenges with RLHF: We taxonomize and survey problems with RLHF, dividing them into three primary categories: challenges with feedback, challenges with the reward model, and challenges with the policy. We also distinguish between challenges that are relatively tractable versus ones that are more fundamental limitations of alignment with RLHF.
- Incorporating RLHF into a broader technical safety framework: We discuss how RLHF is not a complete framework for developing safe AI and highlight additional approaches that can help to better understand, improve, and complement it.
- Governance and transparency: We consider the challenge of improving industry norms and regulations affecting models trained with RLHF. Specifically, we discuss how the disclosure of certain details by companies using RLHF to train AI systems can improve accountability and auditing.
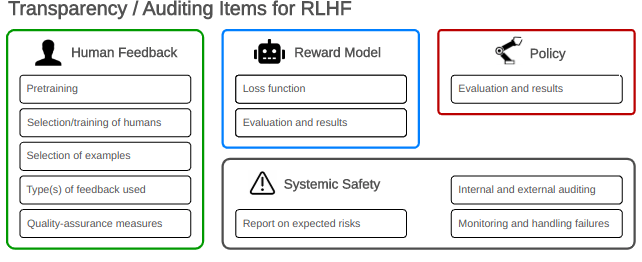
Transparency
We argue that a sustained commitment to transparency (e.g. to auditors) would make the RLHF research environment more robust from a safety standpoint. First, the disclosure of some details behind large RLHF training runs would clarify a given organization's norms for model scrutiny and safety checks. Second, increased transparency about efforts to mitigate risks would improve safety incentives and suggest methods for external stakeholders to hold companies accountable. Third, transparency would improve the AI safety community's understanding of RLHF and support the ability to track technical progress on its challenges.
Specific policy prescriptions are beyond the paper’s scope, but we discuss specific types of details that, if disclosed, could be indicative of risks and should be accounted for when auditing AI systems developed using RLHF.
RLHF = Rehashing Lessons from Historical Failures?
RLHF offers new capabilities but faces many old problems. Researchers in the safety, ethics, and human-computer interaction fields have been demonstrating technical and fundamental challenges with the system and its components for years. In 2023, Paul Christiano (the first author of the 2017 paper, Christiano et al. (2017), prototyping RLHF) described [AF · GW] it as a “basic solution” intended to make it easier to “productively work on more challenging alignment problems” such as debate, recursive reward modeling, etc.
Instead of being used as a stepping stone toward more robust alignment techniques, RLHF seems to have also undergone a sort of “capabilities capture” in which its effects for advancing capabilities have become more prominent than its impacts on safety. We argue that the successes of RLHF should not obfuscate its limitations or gaps between the framework under which it is studied and real-world applications. An approach to AI alignment that relies on RLHF without additional techniques for safety risks doubling down on flawed approaches to AI alignment.
Future Work
We think that there is a lot of basic research and applied work that can be done to improve RLHF and integrate it into a more complete agenda for safer AI. We discuss frameworks that can be used to better understand RLHF, techniques that can help to solve challenges with it, and other alignment strategies that will be important to compensate for its failures. See section 4 of the paper.
6 comments
Comments sorted by top scores.
comment by DanielFilan · 2023-07-31T21:47:59.064Z · LW(p) · GW(p)
We argue that a sustained commitment to transparency (e.g. to auditors) would make the RLHF research environment more robust from a safety standpoint.
Do you think this is more true of RLHF than other safety techniques or frameworks? At first blush, I would have thought "no", and the reasoning you provide in this post doesn't seem to distinguish RLHF from other things.
Replies from: scaspercomment by Stephen McAleese (stephen-mcaleese) · 2023-07-31T21:29:34.779Z · LW(p) · GW(p)
Thanks for writing the paper! I think it will be really impactful and I think it fills a big gap in the literature.
I've always wondered what problems RLHF had and mostly I've seen only short informal answers about how it incentivizes deception or how humans can't provide a scalable signal for superhuman tasks which is odd because it's one of the most commonly used AI alignment methods.
Before your paper, I think this post [LW · GW] was the most in-depth analysis of problems with RLHF I've seen so I think your paper is now probably the best resource for problems with RLHF. Apart from that post, the List of Lethalities [LW · GW] post has a few related sections and this post [AF · GW] by John Wentworth has a section on RLHF.
I'm sure your paper will spark future research on improving RLHF because it lists several specific discrete problems that could be tackled!
Replies from: scaspercomment by Khanh Nguyen (nguyen-xuan-khanh) · 2023-07-31T17:03:52.218Z · LW(p) · GW(p)
Nice work! I agree with many of the opinions. Nevertheless, the survey is still missing several key citations.
Personally, I have made several contributions to RLHF:
- Reinforcement learning for bandit neural machine translation with simulated human feedback (Nguyen et al., 2017) is the first paper that shows the potential of using noisy rating feedback to train text generators.
- Interactive learning from activity description (Nguyen et al., 2021) is one of the first frameworks for learning from descriptive language feedback with theoretical guarantees
- Language models are bounded pragmatic speakers: Understanding RLHF from a Bayesian cognitive modeling perspective (Nguyen 2023) proposes a theoretical framework that makes it easy to understand the limitations of RLHF and derive improve directions.
Recently, there are also several interesting papers on fine-tuning LLMs that was not cited:
- Ruibo Liu has authored as series of paper on this topic. Especially, Training Socially Aligned Language Models in Simulated Human Society allows generation and incorporation of rich language feedback.
- Hao Liu also has also proposed promising ideas (e.g., Chain of Hindsight Aligns Language Models with Feedback)
I hope that you will find this post useful. Happy to chat more :)
Replies from: scasper