Theories of Change for AI Auditing
post by Lee Sharkey (Lee_Sharkey), beren, Marius Hobbhahn (marius-hobbhahn) · 2023-11-13T19:33:43.928Z · LW · GW · 0 commentsThis is a link post for https://www.apolloresearch.ai/blog/theories-of-change-for-ai-auditing
Contents
Executive summary Introduction The roles of auditors in AI Affordances available to AI systems Absolute capabilities and propensities of AI systems Mechanistic structure of the AI system during and after training Learning Effective compute and training data content Security Deployment design Training-experiment design Governance and institutions Miscellaneous roles Theory of Change 1) AI system evaluations 2) Training-experiment design audits 3) Deployment audits 4) Security audits 5) Governance audits Theories of change for auditors in general Theories of change for external auditors in particular Limits of auditing Assumptions for impact of auditing Contributions None No comments
Executive summary
Our mission at Apollo Research is to reduce catastrophic risks from AI by auditing advanced AI systems for misalignment and dangerous capabilities, with an initial focus on deceptive alignment.
In our announcement post [AF · GW], we presented a brief theory of change of our organization which explains why we expect AI auditing to be strongly positive for reducing catastrophic risk from advanced AI systems.
In this post, we present a theory of change for how AI auditing could improve the safety of advanced AI systems. We describe what AI auditing organizations would do; why we expect this to be an important pathway to reducing catastrophic risk; and explore the limitations and potential failure modes of such auditing approaches.
We want to emphasize that this is our current perspective and, given that the field is still young, could change in the future.
As presented in ‘A Causal Framework for AI Regulation and Auditing’, one of the ways to think about auditing is that auditors act at different steps of the causal chain that leads to AI systems’ effects on the world. This chain can be broken down into different components (see figure in main text), and we describe auditors’ potential roles at each stage. Having defined these roles, we identify and outline five categories of audits and their theories of change:
- AI system evaluations assess the capabilities and alignment of AI systems through behavioral tests and interpretability methods. They can directly identify risks, improve safety research by converting alignment from a “one-shot” problem to a "many-shot problem" and provide evidence to motivate governance.
- Training design audits assess training data content, effective compute, and training-experiment design. They aim to reduce risks by shaping the AI system development process and privilege safety over capabilities in frontier AI development.
- Deployment audits assess the risks from permitting particular categories of people (such as lab employees, external auditors, or the public) to use the AI systems in particular ways.
- Security audits evaluate the security of organizations and AI systems to prevent accidents and misuse. They constrain AI system affordances and proliferation risks.
- Governance audits evaluate institutions developing, regulating, auditing, and interacting with frontier AI systems. They help ensure responsible AI development and use.
In general, external auditors provide defence-in-depth (overlapping audits are more likely to catch more risks before they’re realized); AI safety-expertise sharing; transparency of labs to regulators; public accountability of AI development; and policy guidance.
But audits have limitations which may include risks of false confidence or safety washing; overfitting to audits; and lack of safety guarantees from behavioral AI system evaluations.
The recommendations of auditors need to be backed by regulatory authority in order to ensure that they improve safety. It will be important for safety to build a robust AI auditing ecosystem and to research improved evaluation methods.
Introduction
Frontier AI labs are training and deploying AI systems that are increasingly capable of interacting intelligently with their environment. It is therefore ever more important to evaluate and manage risks resulting from these AI systems. One step to help reduce these risks is AI auditing, which aims to assess whether AI systems and the processes by which they are developed are safe.
At Apollo Research, we aim to serve as external AI auditors (as opposed to internal auditors situated within the labs building frontier AI). Here we discuss Apollo Research's theories of change, i.e. the pathways by which auditing hopefully improves outcomes from advanced AI.
We discuss the potential activities of auditors (both internal and external) and the importance of external auditors in frontier AI development. We also delve into the limitations of auditing and some of the assumptions underlying our theory of change.
The roles of auditors in AI
The primary goal of auditing is to identify and therefore reduce risks from AI. This involves looking at AI systems and the processes by which they are developed in order to gain assurance that the effects that AI systems have on the world are safe.
To exert control over AI systems’ effects on the world, we need to act on the causal chain that leads to them.
We have developed a framework for auditing that centers on this causal chain in ‘A Causal Framework for AI Regulation and Auditing’ (Sharkey et al., 2023). For full definitions of each step, see the Framework. Here, we briefly describe what auditors could concretely do at each step in the chain. Later, we’ll examine the theory of change of those actions.
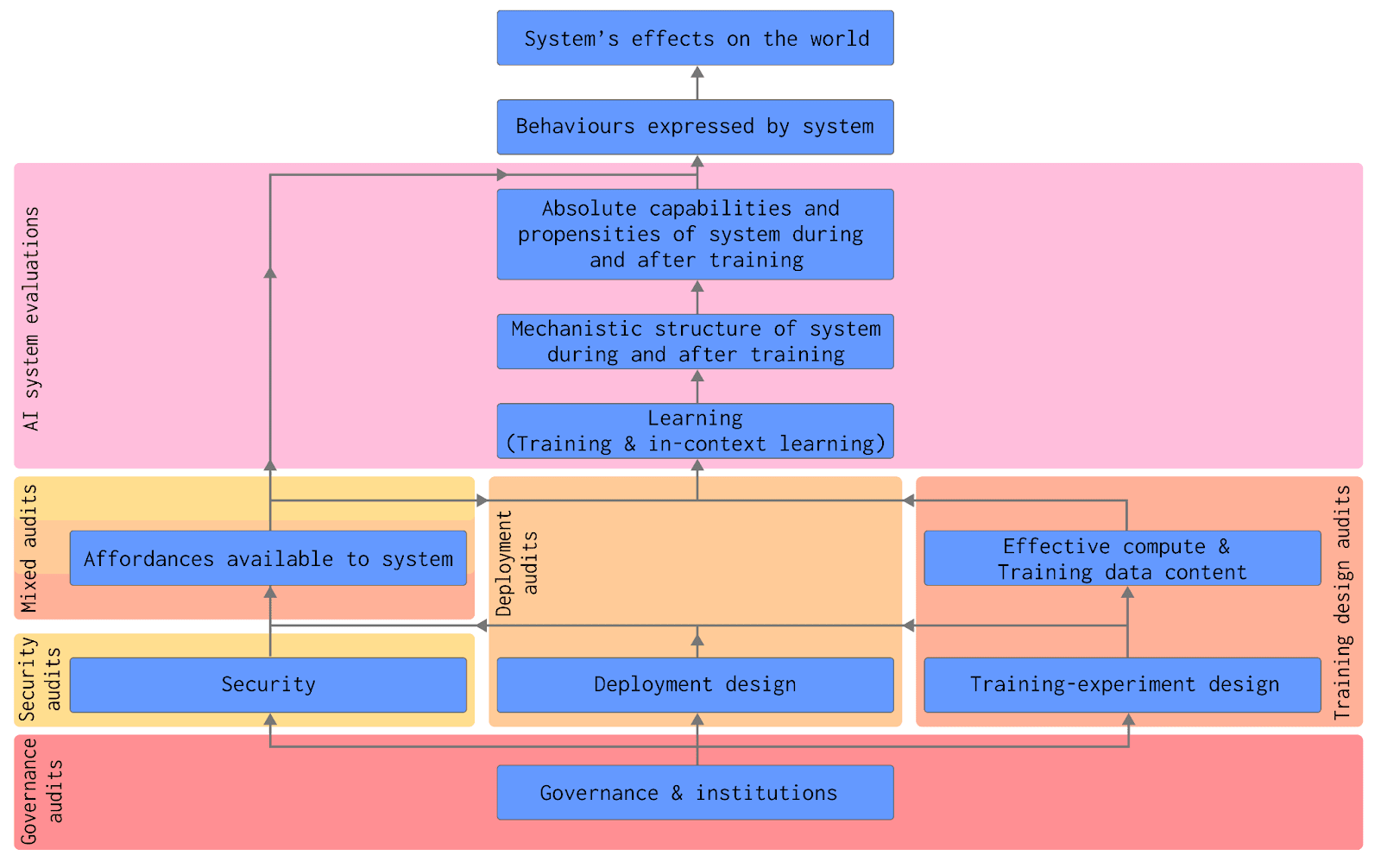
Affordances available to AI systems
- Definition: The environmental resources and opportunities for influencing the world that are available to an AI system. They define which capabilities an AI system has the opportunity to express in its current situation.
- What auditors can do: For each proposed change in the affordances available to an AI system (such as deployment of the AI system to the public, to researchers, or internally; giving the AI system access to the internet or to tools; open sourcing a AI system), auditors can perform risk assessments to get assurances that the change is safe. They can also ensure that AI systems have sufficient guardrails to constrain the affordances available to them.
Absolute capabilities and propensities of AI systems
- Definition: The full set of potential capabilities of an AI system and its tendency to use them.
- What auditors can do: Auditors can perform AI system evaluations to assess the dangerous capabilities and propensities of AI systems. They can do this during or after training. They may perform gain of function research in order to determine the risks that AI systems may pose when they are deployed broadly or if they proliferate through exfiltration. Auditors can also perform risk assessments prior to experiments that would give AI systems additional capabilities or change their propensities. Auditors can also be involved in ensuring that there exist adequate action plans in the event of concerning AI system evaluations.
Mechanistic structure of the AI system during and after training
- Definition: The structure of the function that the AI system implements, comprising architecture, parameters, and inputs.
- What auditors can do: Auditors can perform research to incorporate interpretability into AI system evaluations (both capabilities and alignment evaluations) as soon as possible. Such mechanistic explanations give better guarantees about AI system behavior both inside and outside of the evaluation distribution.
Learning
- Definition: The processes by which AI systems develop mechanistic structures that are able to exhibit intelligent-seeming behavior.
- What auditors can do: Auditors can evaluate risks of AI systems before, during, and after pre-training and fine-tuning training-experiments. Auditors could potentially perform incentive analyses and other assessments to evaluate how AI systems’ propensities might change during training. Auditors can help assess the adequacy of input filters of AI systems to help avoid dangerous in-context learning. They can also help filter retrieval databases. Filters for inputs or retrieval databases may help prevent AI systems being taught potentially dangerous capabilities through in-context learning.
Effective compute and training data content
- Definition: Effective compute is the product of the amount of compute used during learning and the efficiency of learning; training data content is the content of the data used to train an AI system.
- What auditors can do:
- Effective compute: Auditors can help to ensure that labs are compliant with compute controls, if they are in place. Auditors can also conduct risk assessments concerning the scaling up of AI systems, perhaps based on evaluations of smaller AI systems in the same class. Open publication of algorithmic efficiencies may lead to proliferation of effective compute; being technically informed independent experts, auditors could help regulators assess whether certain dual-use scientific results should be made publicly available.
- Training data content: Auditors can ensure that training data don’t contain potentially dangerous or sensitive content.
Security
- Definition:
- Security from attackers: Information security, physical security, and incident response protocols in the organizations developing and hosting AI systems.
- Preventing misuse of AI systems from AI system vulnerabilities: Resistance of AI systems to prompt injection attacks, jailbreaking, and malicious use.
- What auditors can do:
- Security from attackers: Auditors can evaluate and test the security of organizations interacting with AI systems and the computer systems they run on. They can help ensure compliance with information security standards through reviews and perform red-teaming. Given the security requirements of a potentially strategically valuable dual-use technology, military-grade security, espionage protection, and penetration testing may be required. Maximal security necessitates government involvement in security audits. Auditors can also assess that actors with access to AI systems have appropriate levels of access and no more (e.g. through assessing API security or know-your-customer protocols). Auditors may also be involved in research efforts that develop security-relevant infrastructure such as structured access APIs or hardware that ensures compliance with compute regulations and safety standards. Furthermore, they can assess the adequacy of institutions' incident response plans and whistleblower protections.
- Preventing misuse of AI systems through AI system vulnerabilities: Auditors can help assess the adequacy of AI systems’ (and filters’) resistance to prompt injection, jailbreaking, or malicious use through red-teaming to identify vulnerabilities. Auditors can work with other actors to establish bug bounties for finding and reporting vulnerabilities and dangerous capabilities.
Deployment design
- Definition: Deployment designs are the plans made for deploying certain AI systems. They determine who has access?; when do they get access?; and what do they have access to?
- What auditors can do: Auditors can assess risks from different modes of deployment for each AI system to be deployed and ensure that any regulation regarding deployment is upheld.
Training-experiment design
- Definition: A training-experiment is the technical procedure by which an AI system is developed. Design decisions for the training-experiment include data selection and filtering; model architecture and hyperparameters; choice of deep learning framework; hardware choices; the amount of compute that will be used; the algorithms used; evaluation procedures; safety procedures; the affordances made available to the AI system during training; the properties of different phases of pre-training and fine-tuning; whether to train online or offline; etc.
- What auditors can do: Auditors can perform risk assessments on the design decisions for training-experiments. These may be performed prior to training, fine-tuning, or inference (as applicable to the experiment). Auditors can also be involved in assessing the adequacy of labs’ alignment plans to ensure they are in line with public safety.
Governance and institutions
- Definition: The governance landscape in which including AI training-experiment, deployment, and security decisions are made, including institutions, regulations, and norms.
- What auditors can do: Auditors can map the roles and responsibilities of different actors involved in frontier AI development, assess the adequacy of incentive structures, and make recommendations to regulators regarding governance landscape structure.
Miscellaneous roles
Beyond roles of auditors relating directly to the above causal chain, additional general functions of auditors include:
- Establish technical standards and guidelines: Working together, auditors and labs may be better placed to establish safety-oriented standards and guidelines for deployment or training-experiment design than either party alone. This is partly because external auditors don’t have a direct profit incentive to further AI progress as fast as possible and are thus relatively more incentivised toward safety than e.g. frontier AI labs. Furthermore, external auditors have insights into many different AI efforts, whereas labs typically have access only to their own. Auditors may therefore be able to provide a more holistic picture.
- Education and outreach: The technical expertise of external auditors can be used to assist policymakers, researchers in capabilities labs, and the general public. For instance, they could inform policy makers on risks from particular dangerous capabilities or developers how to build agents with protective guardrails.
- Research: Because AI systems, institutions, practices, and other factors are continuously changing, auditors may need to constantly research new methods to gain assurances of safety.
It seems desirable that different auditing organizations specialize in different functions. For instance, security audits may best be handled by cybersecurity firms or even intelligence agencies. However, it is important for safety that auditing tasks are done by multiple actors simultaneously to reduce risks as much as possible.
Theory of Change
Different kinds of audits could examine different parts of the causal chain leading to AI systems’ effects on the world. We identify five categories of audits: 1) AI system evaluations; 2) Training-experiment design audits; 3) Deployment audits; 4) Security audits; and 5) Governance audits. Each category of audit has different theories of change:
1) AI system evaluations
AI system evaluations look at behaviors expressed by the AI system; capabilities and propensities of AI systems (during and after training); the mechanistic structure of AI systems; and what the AI system has learned and can learn.
We assess AI system evaluations as having direct effects; indirect effects on safety research; and indirect effects on AI governance.
Direct effects: If successful, AI system evaluations would identify misaligned systems and systems with dangerous capabilities, thus helping to reduce the risk that such systems would be given affordances that let them have damaging effects on the world (e.g. deployment). Notably, audits do not need to be 100% successful to be worthwhile; finding some, even if not all, flaws already decreases risk (though see section Limits of auditing). Beyond behavioral AI system evaluations, Apollo Research also performs interpretability research in order to improve evaluations in future. Interpretability also has additional theories of change [LW · GW].
Indirect effects on safety research: Adequate AI system evaluations would convert alignment from a ‘single-shot’ problem into a ‘many-shot’ problem. In a world without extensive evaluations, there is a higher chance that a frontier AI lab deploys a misaligned AI system without realizing it and thus causes an accident, potentially a catastrophic one. In this case, the first “shot” has to be successful. By contrast, in a world with effective evaluations, labs can catch misaligned AI systems during training or before deployment; we would therefore get multiple “shots” at successfully aligning frontier AI AI systems. For instance, reliable AI system evaluations may give us evidence if any specific alignment technique succeeds in reducing a AI systems’ propensity to be deceptive. This would have important implications for the tractability of the alignment problem, since it would enable us to gather empirical evidence about the successes or failures of alignment techniques in dangerous AI systems without undue risk. Ultimately, successful AI system evaluations would let us iteratively solve the alignment problem like we would most other scientific or engineering problems.
Indirect effects on AI governance: AI system evaluations could provide compelling empirical evidence of AI system misalignment ‘in the wild’ in a way that is convincing to AI system developers, policymakers, and the general public. For example, AI system evaluations could be used to demonstrate that an AI system has superhuman hacking capabilities or is able to manipulate its users to gather relevant amounts of money. Such demonstrations could encourage these stakeholders to understand the gravity of the alignment problem and may convince them to propose regulation mandating safety measures or generally slowing down AI progress. Auditors likely have a good understanding of what frontier AI systems are capable of and can use their more neutral position to inform regulators.
Indirect effects on distribution of AI benefits: In order to reap the potential benefits from AI, it must be (safely) deployed. Assuming audits can be done effectively, auditing derisks investments, potentially leading to more investments in the area and thus greater benefits. By catching failures before they happen, auditing may be able to avoid accident scenarios, which have harmed public confidence in nuclear technology. Effective audits may also increase public trust in the technology, leading to wider spread use.
2) Training-experiment design audits
AI system development audits look at effective compute, training data content, and training-experiment design decisions. They also look at the design of AI system training-experiments, which help determine the previous factors.
The primary means of impact of AI system development audits is that they reduce the risk of dangerous AI systems coming into existence in the first place and reduce the danger posed by AI systems. They aim to achieve this by controlling which capabilities AI systems have (to avoid dangerous ones), the extent of their capabilities, and their propensities to use dangerous capabilities. By embedding safety into the AI system development process, AI system development audits may help place safety at the center of labs’ work rather than as an afterthought to increasing capabilities.
3) Deployment audits
Deployment audits concern proposals for the deployment of particular AI systems.
The overall means of impact is that they should prevent systems from being deployed in ways that contravene regulations or that are deemed too risky. Note that these pathways are separate from AI system evaluations. The results of AI system evaluations should inform risk assessments in deployment audits. They should aim to assess risks from giving particular kinds of AI system access (e.g. access to inference; access to fine-tuning; access to weights) to particular kinds of people (e.g. deployment to the public; internal deployment; deployment in certain countries). They should also assess risks from making particular kinds of affordances available to AI systems, for instance internet access or access to particular kinds of software.
Deployment audits aim to ensure that AI systems are not intentionally given excessive available affordances; by contrast, security audits aim to reduce the risk that they are given excessive available affordances unintentionally.
4) Security audits
Security audits assess the security of AI systems and the security of the organizations developing, hosting, and interacting with them. The overall purpose is to limit the affordances made available to highly capable AI systems unintentionally, thus reducing accident and misuse risks, both of which are extremely important for such a transformative and dual-use technology. They reduce the risk of AI system proliferation either through accidental leaks or exfiltration, either by internal or external actors. By assessing how well AI systems have been ‘boxed’, they also reduce the risk of AI systems exfiltrating themselves. They also aim to assess the adequacy of damage control measures in the event of security or safety failures.
5) Governance audits
Governance audits look at the structure of the institutions developing, regulating, and auditing AI systems (and the interactions between those institutions) to ensure that they are conducive to safety.
They aim to ensure that organizations have proper mechanisms in place to make informed, ethical, and responsible decisions regarding the development and deployment of AI systems. While other audits aim to ensure that AI systems are aligned or that they’re used for aligned purposes, governance audits aim to ensure that alignment with human values extends to the institutions wielding and managing these AI systems. Their path to impact is that they can identify problems in the governance landscape, thus making it possible to rectify them.
Theories of change for auditors in general
In addition to theories of change for each individual category of audit, there are also multiple theories of change for auditing in general:
- Buying time for safety research: Auditing might delay the deployment of existing AI systems and potentially prevent or delay the beginning of training of new ones. This could lead to more time for other alignment research. This would buy time for research that is applicable to more and more capable AI systems.
- Instilling safety norms in AI development: If an AI lab knows that they’re going to be audited and potentially pay a cost (financial, reputational, or otherwise) if they fail the audit, they might be more incentivised to instill stronger safety norms and be more cautious around training and deploying new AI systems. Potentially, the existence of auditors alone may already increase safety slightly.
- Public messaging about safety risks: Companies choosing to or being required to be audited sends a clear message that this technology is potentially dangerous.
Theories of change for external auditors in particular
External auditors, as opposed to internal auditors at the labs developing frontier AI, have additional pathways to impact:
- Incentives are more aligned with the public benefit: External auditors are more independent than lab-internal audits and have less conflicting incentives (although there are some perverse incentives, which we hope to discuss in a future post). Even when labs are well-intentioned, social dynamics might reduce the efficacy of internal audits. For example, internal auditors may show anticipatory obedience or be more lenient because they don’t want to be perceived as slowing down their colleagues.
- Defense in depth: Multiple independent audits help reduce the probability of failure. In general, the more uncorrelated methods of risk reduction we can use on the problem the better.
- Subsidizing research: Depending on the funding landscape for AI auditing, if the auditing industry is profitable then profits can be used to fund research on improved audits and other alignment research. Since audits are their primary purpose, external auditors have a greater incentive to conduct such research relative to capabilities compared with labs developing frontier AI.
- Increasing transparency: External auditors can potentially be more transparent about their own governance or their standards when auditing than lab-internal auditors. For instance, external auditors may be able to publish general details of their auditing process and methods which larger labs, perceiving themselves to be in a greater competition with other labs, may not be incentivised or feel able to do.
- Sharing expertise and tools: Independent organizations, such as auditors and regulators, can pool best practices, standards, expertise, and tests across different centers of expertise. Due to competition and antitrust concerns, each lab’s internal auditing team can likely only work with their own AI systems while an external auditor can get a bird’s eye view and gets significantly more experience from working with AI systems of multiple labs. Furthermore, an external organization can specialize in AI auditing and thus build scalable tools that can then be applied to many AI systems. Additionally, if auditors summarize and share (nonsensitive) safety-relevant information between labs, it will likely disincentivize race dynamics by drawing attention to common safety issues and making it apparent to labs that others aren’t racing ahead irresponsibly.
- Monitoring behaviors across labs: Since external auditors may interact with multiple labs, they can compare the safety culture and norms between them. In case a lab has an irresponsible safety culture, this can be flagged with that lab’s leadership and regulators.
- Collaboration with regulators: A healthy auditing ecosystem with multiple competent auditors can assist regulators with technical expertise and allows regulations and standards to be quickly designed and implemented
- Lobbying for good regulation: An external auditor is also an independently interested player in pushing for and setting regulation on labs and for policy work while internal audit teams are likely to be much more controlled by the policy interests of their host labs. This comes with risks, too: A potential incentive of an auditing organization is to lobby for more regulation rather than good regulation. We think currently, however, there is a large undersupply of regulation in AI and so this is likely to be a net positive for the foreseeable future.
- Information sharing: Trusted external auditors can get a bird's eye view of progress, risks and good practices across AI labs. If they summarize and share (nonsensitive) parts of this publicly, it will likely disincentivize race dynamics by drawing attention to common safety issues.
Limits of auditing
We are aware of some of the limits of AI auditing, as well as the perverse incentives of auditing organizations that could both serve to reduce the positive impact that auditing efforts might have.
- False confidence and safety-washing: It is possible that audits may be net-negative by providing false confidence in the safety of AI systems. This may be due to accidental misjudgement about the extent of the assurance that particular evaluations can provide. False confidence may also arise due to frontier AI developers intentionally using audits as fig leaves for the risks posed by AI systems, i.e. safety-washing. We believe that by careful communication from auditors and improving evaluation methods (e.g. interpretability), these risks can be minimized and auditing will be strongly net positive. Licensing of auditors may also mitigate the risk of lax auditors awarding undeserved seals of approval.
- Using auditors as excuses to absolve labs from safety responsibilities: One plausible outcome of auditing is that labs may feel licensed to neglect their duties from doing their own safety work. In the event of accidents, they may be able to use auditors as legal shields to protect themselves from liability. The very existence of auditors may make labs feel like they need to do less work on making their AI systems safe, since they can rely on auditors to catch issues. Establishing where responsibility and liability should fall will require more consideration.
- No strong guarantees for behavioral AI system evaluations: Current AI system evaluation methods are primarily behavioral because existing interpretability tools are very limited. Therefore, it seems that, at best, auditing methods can currently only prove the presence of dangerous capabilities rather than their absence. As such, current audits cannot make strong guarantees of safety beyond probabilistic statements about how hard it is to elicit specific behaviors. With more research and understanding of how deep networks function internally, it may be possible to get stronger guarantees.
- Goodhart’s law: When auditors use a range of tests to ensure an AI system’s safety, these tests themselves become a target, i.e. either directly or indirectly labs will train their AI systems to pass these tests. This can be partly mitigated by withholding information about some audits from auditees.
- Overfitting to audits: Even without directly training on audits, there is a natural selection process where the AI systems that pass all tests are potentially especially competent at deception and thus more dangerous. Hopefully, extensive and robust AI system evaluation suites will be able to reduce this problem but, in principle, this evolutionary process will always remain.
- Limited constructive solutions at present: Until the state of AI system evaluations research improves, AI auditors likely won’t be able to provide solutions to problems concerning the safety of AI systems, i.e. they can say that a AI system should not be deployed because it has demonstrated unsafe properties, but they can’t immediately tell the lab how to solve that problem. However, we think good auditing likely requires an understanding of the processes that generated the problem. Thus, we expect that auditors may eventually be able to provide constructive recommendations.
- Audit recommendations need authority: For auditing to be effective, it is necessary that the recommendations of auditors have the ability to meaningfully stop a AI system from being deployed in case they find evidence of dangerous capabilities. Currently, auditors can only make non-binding recommendations and the frontier AI labs ultimately decide whether to act on them or not. In the long run, when more capable AI systems can produce catastrophically bad outcomes, regulators (acting on the recommendations of auditors) should have the ability to enforce compliance of safety standards in labs.
- Perverse incentives: Auditing as a field has perverse incentives that can distort and manipulate the auditing process. For example, if auditing organizations depend on a few major customers (which is likely the case for frontier AI risks since there are only a handful of leading labs), there is a clear incentive to become sycophantic to these labs out of fear that they lose a large chunk of their revenue. Similar dynamics could be seen in the financial auditing industry before the 2008 financial crisis. We believe that this problem can largely be mitigated by auditing regimes where labs do not choose their auditors, but instead regulators do.
Assumptions for impact of auditing
Our theory of change makes some assumptions about AI threat models and how the future is likely to play out. If these assumptions are incorrect, then it is not clear that auditing will be a good marginal investment of talent and time, or else the auditing strategy will have to change significantly:
- Regulations demand external, independent audits: Currently we see that there is general goodwill inside leading frontier AI labs towards AI safety audits. As AI systems become more capable and risky, they both become potentially more profitable to deploy while simultaneously becoming potentially riskier. This establishes a basis for friction between frontier AI labs, who are more strongly incentivised to deploy, and auditors, who are more incentivised to mitigate risks. In the long term, if frontier AI labs get to choose their own auditors, then incentives drive a race to the bottom in terms of auditing costs, which by proxy means a race to the bottom in terms of safety. This race to the bottom can mostly be avoided by ensuring that frontier AI labs are not responsible for selecting their own auditors. It may also be mitigated through consensus on auditing standards and auditing regulations that are enforced.
- Regulations demand actions following concerning evaluations: If the recommendations of auditors don’t lead to interventions that improve safety, there is not much point in doing audits. To avoid uncooperative frontier AI development labs proceeding unsafely, auditing should have regulatory backing and there should be specific interventions that are enacted following particular evaluation results.
- Prosaic AI alignment is possible: The path to impact of auditing assumes that working with current AI systems, detecting and evaluating their failure modes, and pursuing research directions such as interpretability and human preference-learning for large AI systems are productive and useful directions to solve alignment. If there is either some fundamental impossibility to align frontier AI or there are large, sudden, unpredictable jumps in capabilities that yield AI systems that can fool all auditing techniques at once, then auditing will not be effective.
- Auditing is not prohibitively expensive: First, if auditing turns out to be expensive and slow, then, unless forced to by regulation, most frontier AI labs are unlikely to engage in the practice in a meaningful way. In the long run, we expect that auditing and AI system evaluations will have to be very extensive but it is worth paying the cost because the AI will be deployed in large parts of the economy. Second, we suspect future AI systems might have much better online learning capabilities. This means that, in addition to audits before deployment, we might also have to regularly audit AIs during deployment. If the changes in capabilities between deployment audits are too drastic and fast, auditing can’t provide a practical solution. Third, auditing organizations need to be sufficiently well resourced in order to carry out their audits, including potentially to pay legal costs surrounding safety audits that are controversial with AI development companies. Overall, to address this concern, we suggest that safety-aligned auditor funding mechanisms be an urgent policy research area.
- There is a safe environment for developing AI systems prior to auditing: If audits only occur once the base model has been trained, then for audits to be effective it would need to be the case that the AI system cannot exfiltrate itself during the training process.
- Relatively centralized access to AI system: If the most powerful AI systems can only be created by a handful of organizations, auditing them is relatively easy. In a world where everyone can train their own AI systems or strongly modify existing AI systems with little effort, it will be much harder (but not impossible) to effectively audit all of them. Preventing catastrophic risk in such a world will likely require very strong regulatory backing.
- Progress in interpretability: We think good interpretability tools would allow us to make much stronger statements about the safety of AI systems because they give us a better understanding of the internal reasons for a given behavior. However, current interpretability tools seem insufficient to allow for the needed level of explainability for convincing guarantees of safety. More progress is needed, which is why Apollo Research is investing in fundamental interpretability research.
- We do not train against the audits: If all AI system evaluations are made public, then there might be pressure to directly train or indirectly optimize (i.e. through selection effects) AI systems to pass audits, even though they could still be unsafe. Potential solutions would be to keep ‘test sets’ of AI system evaluations that are not known to AI system developers. We would not want to use these test sets frequently, since frequent use may establish another optimization process from population-level selection effects.
Contributions
Lee Sharkey led the project and edited the final version. Marius Hobbhahn contributed significantly to all parts other than “The roles of auditors in AI” section. Beren Millidge contributed to an early draft of the post. Dan Braun, Jeremy Scheurer, Mikita Balesni, Lucius Bushnaq, Charlotte Stix, and Clíodhna Ní Ghuidhir provided feedback and discussion.
0 comments
Comments sorted by top scores.