Corrupted by Reasoning: Reasoning Language Models Become Free-Riders in Public Goods Games
post by David Guzman Piedrahita (davidguzman1120), Yongjin Yang (yongjin-yang), Zhijing Jin · 2025-04-22T19:25:35.302Z · LW · GW · 1 commentsContents
Summary:
Introduction
The Public Goods Game
The Split: Optimization vs. Social Heuristics
Conclusion
Acknowledgements
None
1 comment
Summary:
- Traditional LLMs outperform reasoning models in cooperative Public Goods tasks. Models like Llama-3.3-70B maintain ~90% contribution rates in public goods games, while reasoning-focused models (o1, o3 series) average only ~40%.
- We observe an "increased tendency to escape regulations" in reasoning models. As models improve in analytical capabilities, they show decreased cooperative behavior in multi-agent settings.
- Reasoning models more readily opt for the free-rider Nash equilibrium strategy. They optimize for individual gain at collective expense, as evidenced in their reasoning traces: "the optimal strategy to maximize personal gain is to free-ride."
- This challenges assumptions about alignment and capability. Increased reasoning ability does not naturally lead to better cooperation, raising important questions for multi-agent AI system design.
Introduction
In a series of virtual rooms, AI agents face a classic social dilemma. Each agent must decide: contribute resources to a shared project that benefits everyone, or keep them for personal gain. The most rational individual strategy is to contribute nothing while hoping others contribute everything, the infamous free-rider problem. Yet cooperation would maximize collective welfare.
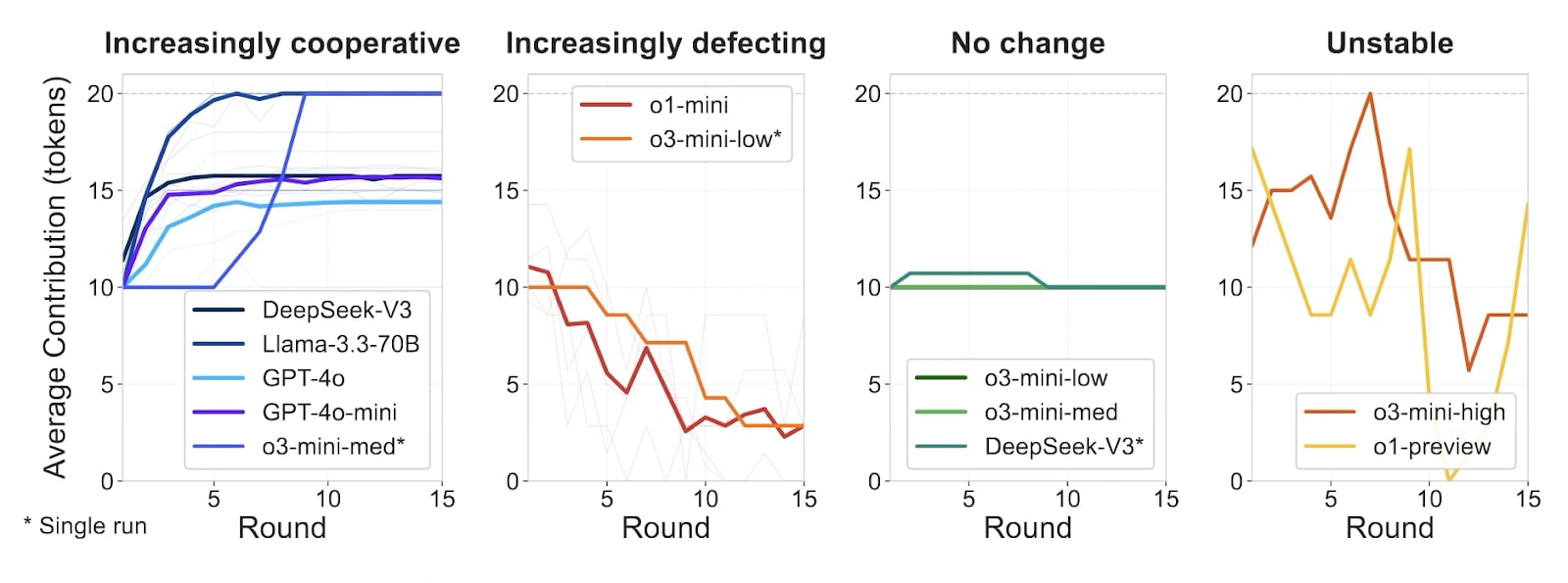
The results show that Traditional language models, like Llama-3.3-70B, contribute over 90% of their resources and maintain stable cooperation. Meanwhile, reasoning models like those in the o1 and o3-mini series exhibit widespread defection, contributing less than half as much on average.
As one o1-mini agent explains after initially cooperating but later defecting: "Observing that other group members have historically contributed around 10 tokens, contributing 0 tokens allows me to maximize my own payoff without incurring additional costs... the optimal strategy to maximize personal gain in this setting is to free-ride."
This finding challenges the assumption that enhanced reasoning capabilities should naturally lead to better decision-making across all domains. Instead, we observe a systematic trade-off where improvements in reasoning correlate with decreased cooperation in multi-agent settings.Traditional LLMs establish and sustain cooperation while reasoning-focused models either decline into free-riding, maintain rigid but suboptimal strategies, or oscillate between cooperation and defection.
Why would models specifically designed for better reasoning make less cooperative choices? The answer appears to lie in how their reasoning capabilities allow them to quickly adapt to game-theoretic incentives. They readily identify individually optimal strategies, and crucially, seem quick to abandon cooperative attempts after negative feedback (like punishment) or when placed in environments lacking enforcement, rapidly converging on self-interested behaviors like free-riding.
Are we inadvertently creating more "rational" but less cooperative AI? Can we design systems that maintain cooperative tendencies as their reasoning capabilities advance?
We will examine the evidence and explore the behavioral modes observed across model families. If optimizing for game-theoretic 'rationality' undermines cooperation in social dilemmas, a challenge increasingly recognized in multi-agent simulations like GovSim (Piatti et al., 2024) and highlighted by research into AI governance and the need for agents to navigate social rules (Cohen et al., 2024; Chan et al., 2025), then we may need to focus on training paradigms that explicitly foster pro-social reasoning, potentially leveraging specialized architectures aimed at improving cooperation (Sarkar et al., 2024), rather than assuming cooperation emerges naturally as a byproduct of general intelligence.
The Public Goods Game
We dropped these agents into a simulation of the Public Goods Game (PGG). Each agent owns some tokens and decides how many to contribute to a shared pool. This pool gets multiplied by a factor of 1.6 and then the total is divided equally among all players, regardless of their individual contribution. While everyone benefits most if all contribute fully, individual rationality would suggest contributing nothing, letting others fill the pot, and obtaining the shared rewards, the classic free-rider problem.
Faced with this social dilemma, the first big difference appeared in contribution levels. Non-reasoning models like Llama-3.3-70B consistently cooperated, contributing nearly all their tokens (averaging ~18.7 out of 20). In contrast, reasoning models like o1-mini often contributed less than a third of that (~5.4 tokens on average), increasingly prioritizing individual gain as the public good dwindled. These choices led to the distinct behavioral patterns we observed: the stable, increasingly cooperative approach of traditional models versus the common failure modes of defection, stagnation, or instability seen primarily in their reasoning counterparts.
The simulation adds another layer inspired by human experiments (Gurerk et al., 2006; Iacono et al., 2023): each round before contributing, agents have to choose their social contract by joining one of two institutions. Would they opt for the Sanction-Free Institution (SFI), a pure PGG where free-riding faced no formal consequences? Or would they choose the Sanctioning Institution (SI), an environment where cooperation could be actively enforced? The SI offers enforcement tools: members can use a separate pool of tokens to punish low contributors (at a 1:3 cost-to-impact ratio) or reward high contributors (at a 1:1 ratio). Here again, Traditional LLMs overwhelmingly voted with their feet for order, with Llama-3.3-70B joining the SI over up to 99% of the time, while reasoning models often preferred the freedom (or perhaps, exploitable environment) of the SFI, like o1-mini opting into the SI only 28% of the time.
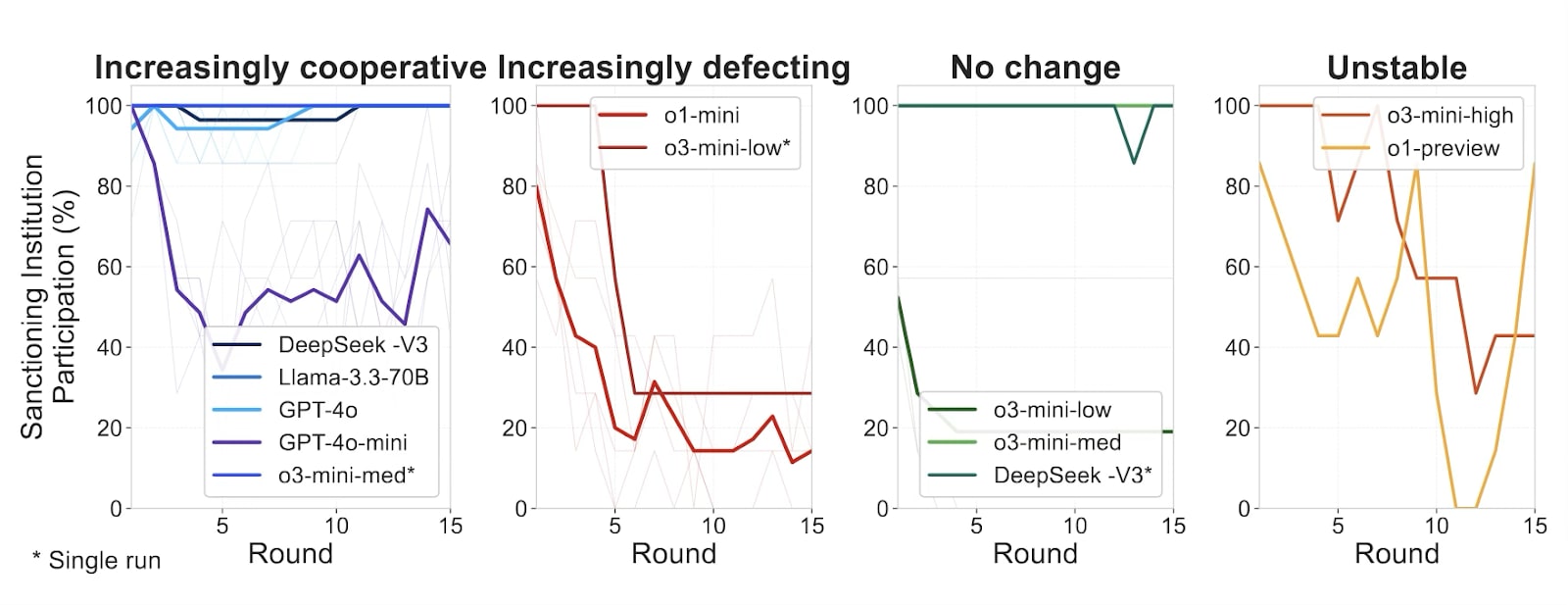
Despite having the capacity to punish defectors, the increasingly cooperative models favored a strategy of positive reinforcement, using rewards to promote high cooperation. This differs from human behavior, where punishment is often the preferred enforcement tool (Gurerk et al., 2006). Reasoning models, when they did join the SI, often failed to establish stable enforcement regimes, contributing to the collapse or oscillation of cooperation within their groups. Free-riding, virtually non-existent in groups of Traditional LLMs (<1%), became rampant among reasoning models like o1-mini, infecting up to 70% of its interactions.
The Split: Optimization vs. Social Heuristics
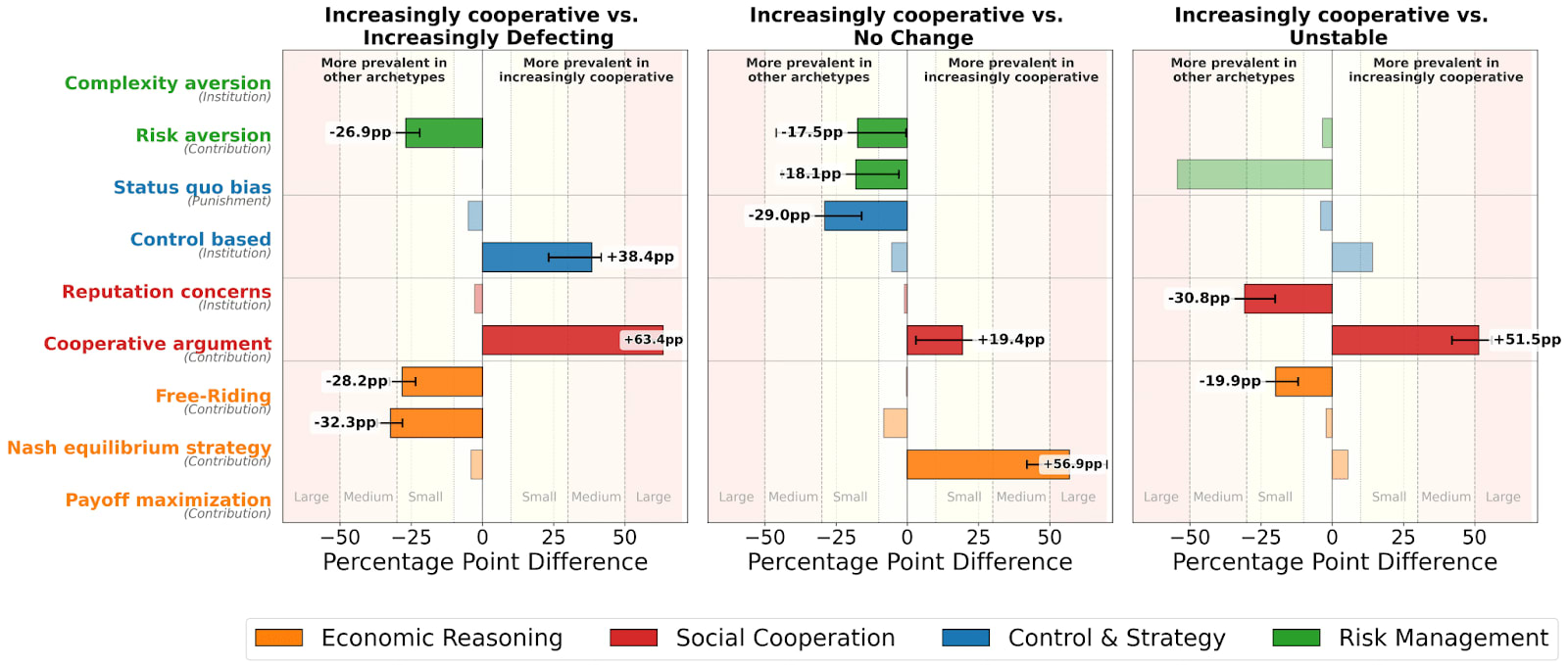
Why does reasoning correlate with worse cooperative outcomes? When we examine the justifications the models provide for their actions there is a clash between cold, game-theoretic optimization and something more similar to social reasoning.[1]
Increasingly cooperative models, which are mostly Traditional LLMs, present their choices in terms of collective success and positive social influence. Their reasoning emphasizes maximizing the project's earnings (which benefits everyone), setting cooperative examples, and using the Sanctioning Institution's tools—primarily rewards—to reinforce group norms. As Llama 3.3 70B put it: "This decision aims to maximize the project's earnings and, by extension, my own payoff... contributing the maximum amount positions me as a significant contributor, which might influence others' decisions regarding rewards...".
Contrast this sharply with Increasingly defecting and unstable models, largely Reasoning LLMs which eventually fall into game-theoretic logic to justify maximizing individual gain at the group's expense. Their reasoning grows to be devoid of pro-social framing: the o1-mini quote from the introduction is worth repeating: "...the optimal strategy to maximize personal gain in this setting is to free-ride by not contributing to the project." This isn't faulty reasoning; it's individual optimization within the game's rules, but it leads directly to collective failure.
Across all runs, cooperative arguments dominate Traditional LLM decisions, appearing over 19 to 63 percentage points more frequently, while justifications based on Nash equilibrium and free-riding are significantly more prevalent among Reasoning LLMs.
Conclusion
This finding challenges the straightforward assumption that enhancing an AI's general reasoning capabilities will naturally improve its performance across all domains, particularly in cooperative social settings. In this context, advanced reasoning, as implemented in the models tested, did not translate to better collective outcomes; instead, it often correlated with strategies detrimental to group success.
In a future with autonomous AI agents interacting in economies and research collaborations, understanding these dynamics becomes more and more relevant. If certain paths of capability development lead to agents that excel at individual optimization but struggle with cooperation, we risk creating systems prone to collective failure in scenarios requiring shared effort and trust.
Ultimately, if optimizing for certain types of powerful reasoning can, in some contexts, accidentally undermine cooperation, we must carefully consider the full spectrum of capabilities needed for beneficial AI. Ensuring future systems are not only 'intelligent' in an analytical sense, but also adept at navigating social realities, may require more intentional approaches than simply pursuing generalized reasoning improvements alone.
Acknowledgements
We would like to thank Jiduan Wu for insightful discussions covering both game theory with sanctioning and the challenges of modeling LLM cooperation. We also extend our gratitude to Gillian Hadfield and her lab for valuable discussions on the specific importance of sanctioning in LLM Multi-Agent systems. Additionally, we thank Lennart Schlieder and Annalena Kofler for their helpful feedback on our experimental design. Special thanks to Roger Grosse for his general guidance and valuable title advice throughout this project.
Full results and further methodological can be found in the Full Paper.
- ^
To understand the mechanisms driving different cooperative outcomes, we analyzed agent reasoning processes across behavioral archetypes. Following prior work showing high human-model agreement (Gilardi et al., 2023; Piatti et al., 2024), we used GPT-4o to classify decision rationales according to our defined taxonomy (see Full Paper for further details).
1 comments
Comments sorted by top scores.
comment by Mitchell_Porter · 2025-04-23T01:41:04.542Z · LW(p) · GW(p)
Is there a name for the phenomenon of increased intelligence or increased awareness leading to increased selfishness? It sounds like something that a psychologist would have named.