Self Supervised Learning (SSL)
post by Varshul Gupta · 2023-08-10T17:43:36.469Z · LW · GW · 1 commentsThis is a link post for https://dubverseblack.substack.com/p/ba889fa6-29c5-4fd2-b8c3-6ab26d02d243
Contents
Self Supervised Learning (SSL) "Unlocking Powerful Representations: The Frontier of Self-Supervised Learning" The Idea Behind SSL How to SSL NLP Speech Vision AutoEncoders: VAE: Conclusion: None 1 comment
Self Supervised Learning (SSL)
"Unlocking Powerful Representations: The Frontier of Self-Supervised Learning"

AUG 9, 2023
With all that’s been happening in the AI/ML industry for the past few weeks, it is important we address the elephant in the room.
The Idea Behind SSL
SSL comes under the umbrella of Unsupervised Learning. One thing that worked for NNs is that they are able to fit a curated dataset with ease given they have labels to optimize for (Supervised Learning), but this dataset may not be large enough, instead, it would be very expensive or impossible to create such a dataset. Once NNs have good representations of the task-related work they can learn a new task even more rapidly when shown how to do it only once (Zero-shot).
But what if we can create synthetic Labels from the data?
they don’t need to be highly curated. They can be thought of as corrupting the data. we can use these labels to train NNs and in the process, these NNs learn a powerful representation (depending upon the data and compute) of the Data that can be fine-tuned with a handful of data to produce quality results.
How to SSL
The main goal of SSL is to generate labels out of the dataset itself, without much human effort. The basic idea is to corrupt the data or either do a lossy compression to predict the same data back from the Model. Let’s discuss some ways in which researchers have used this technique in different domains:
NLP
While training a Language Model you can do SSL in two ways:
MLM: Masking some words of the text (Corrupt) and letting the model train on getting these masked tokens correctly. Research Paper
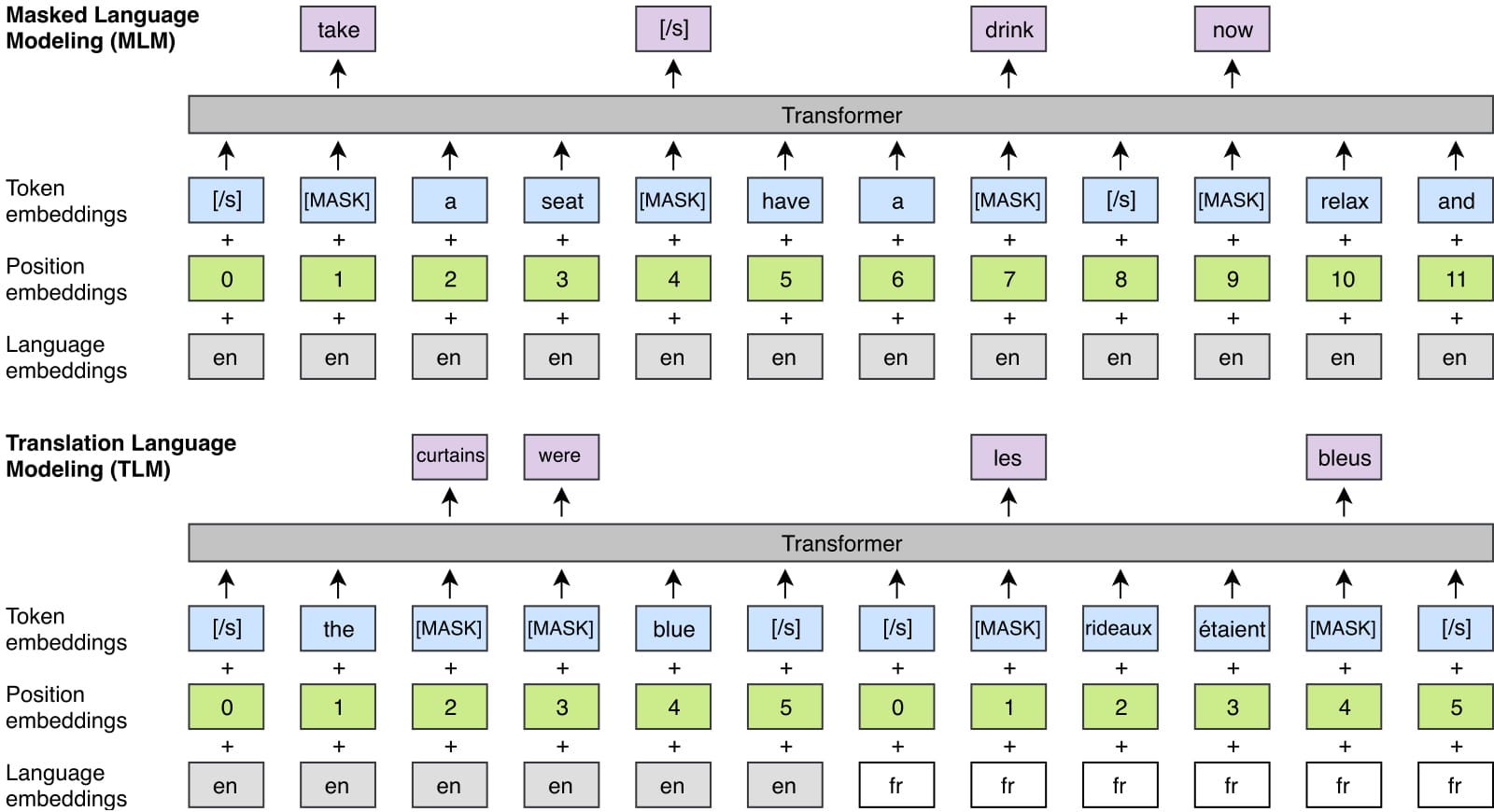
LM: given some context let the Model predict the rest of the text, one token at a time. Research Paper
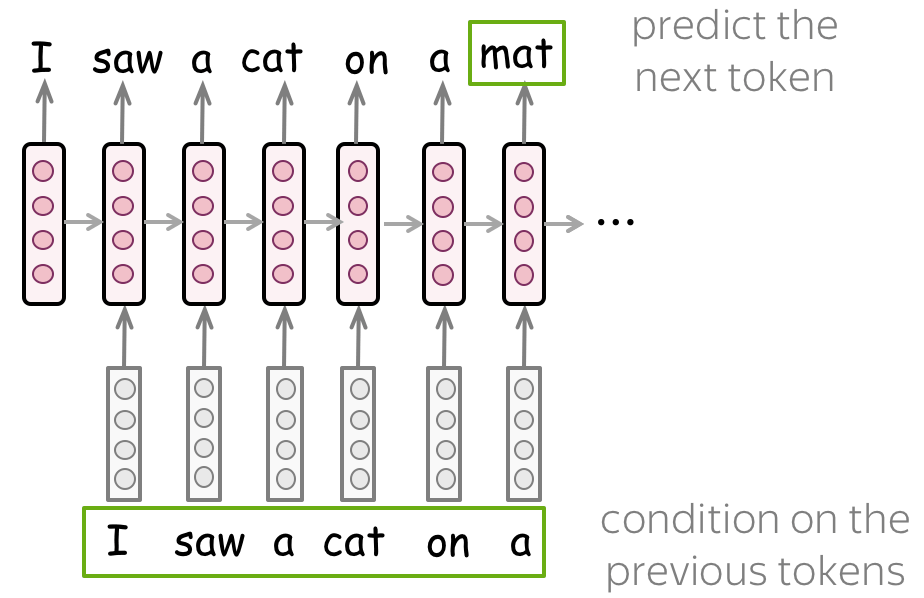
These approaches are part of contrastive training: in short, you train the model to differentiate between the different classes, during training you want the model to give a high probability to the ground truth and near zero probability to the rest of the labels.
Speech
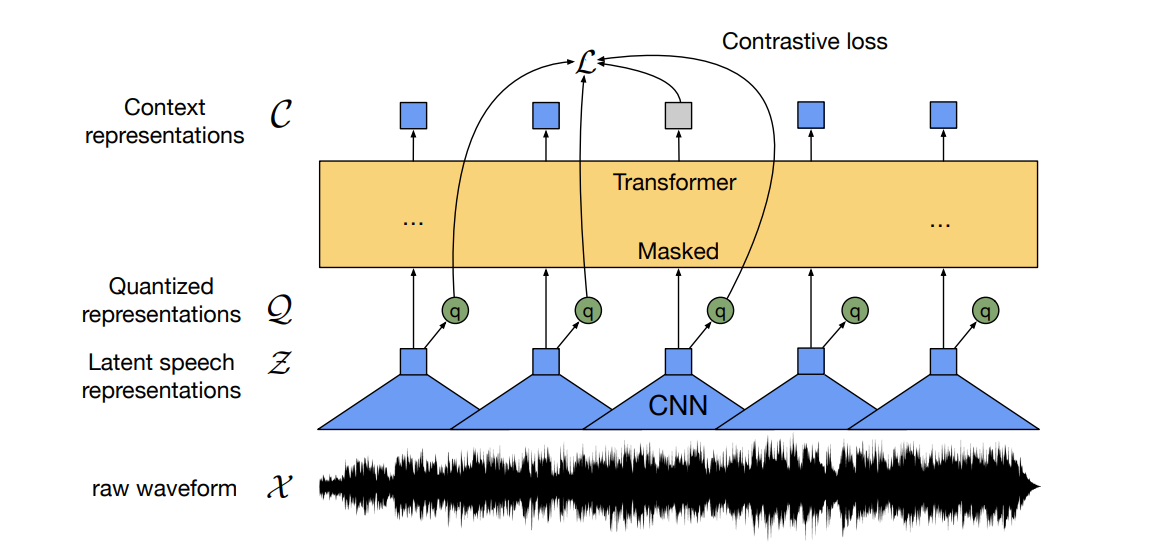
Wav2Vec 2.0 model: The Idea is similar to MLM, Using CNN Layers to create quantized representations and then doing MLM on top of it. Research Paper
Vision
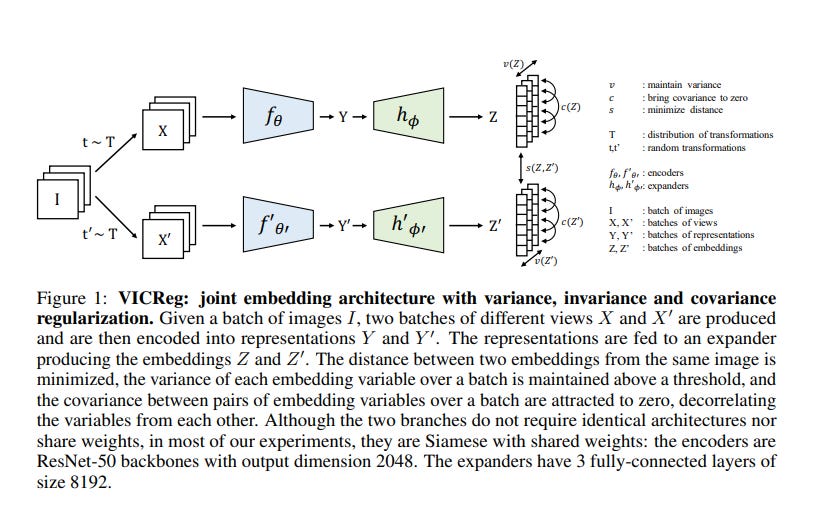
VicReg: This training paradigm is based on regularization rather than a contrastive approach Research Paper
The model is given two augmented version of the same image (SSL) and the distance between these embeddings need to be close. There are no negative pair as in contrastive learning and hence model can collapse by simply giving the same embedding for every image.
The regularization comes from applying different constraints/loss (which makes the embedding not be same) on the embeddings given by the model.
AutoEncoders:
The autoencoders are also regularized way of training by creating a bottleneck in the model itself, so it learns the meaningful representation from the data. The Model is trained to predict the same input, mostly trained with a noise version of the input, and tries to predict the input without the noise. Research Paper
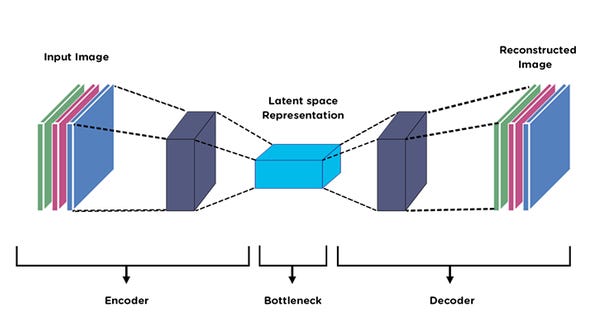
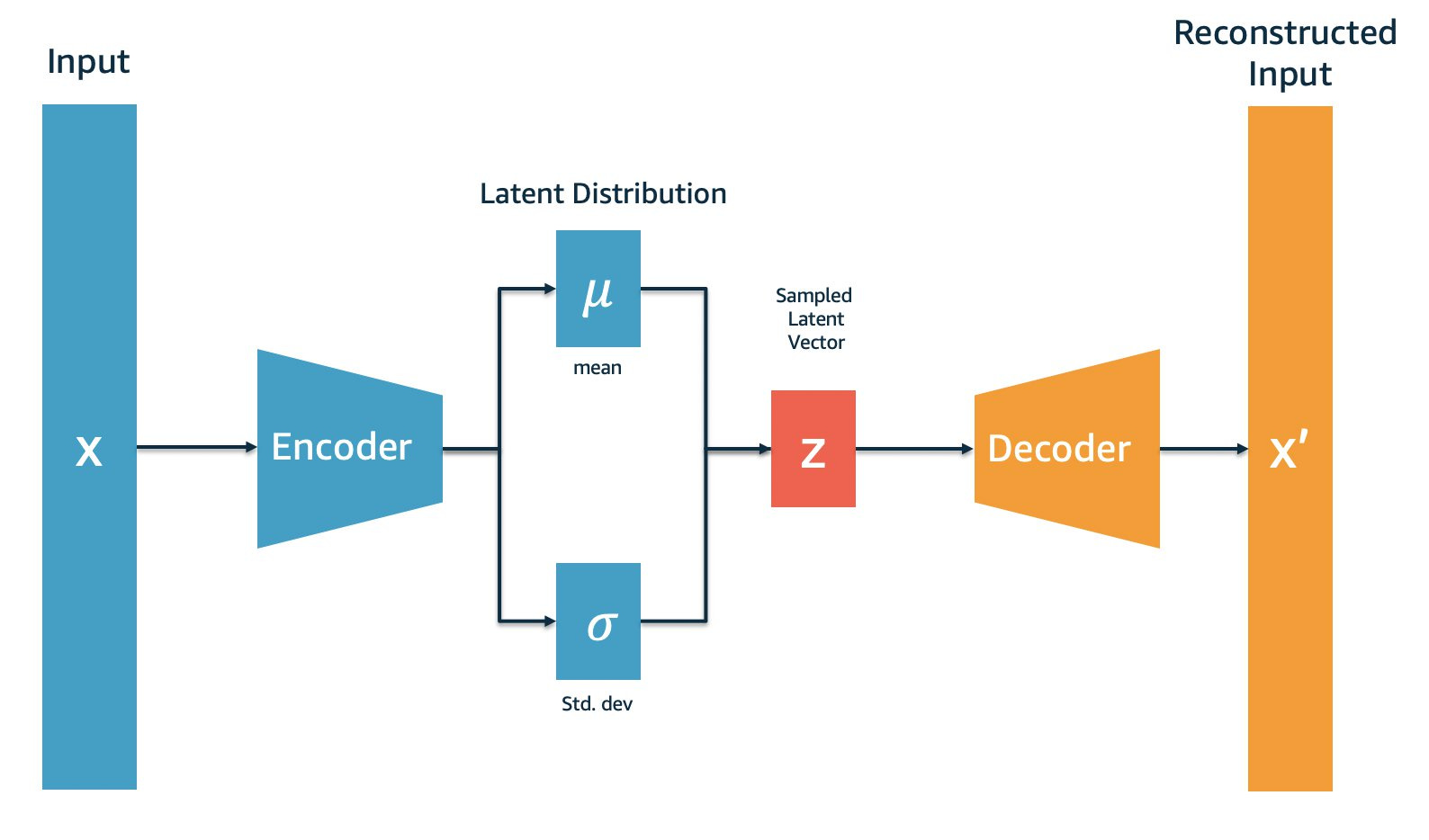
VAE:
VAE introduces the bottleneck to be a Gaussian Distribution. VAE are one of my favorite models to work with, they also have good proof of working in mathematics. would highly suggest reading more about these. Diffusion models are a class of Markovian Hierarchical VAE. Research Paper
Conclusion:
SSL enables the model to learn powerful representations of the data in an inexpensive manner. The representations are then can be used for transfer learning, fine-tuning, etc. When trained on large data with large compute the resulting representation is generalized enough to do zero-shot stuff as in the case of GPT-3.
Thanks for reading Dubverse Black! Subscribe for free to receive one tech blog per week (:
Subscribe
We are actively hiring interns for Research Engineering at Dubverse.ai, do apply at Careers page!
Until next time,
Jaskaran
1 comments
Comments sorted by top scores.
comment by Capybasilisk · 2023-08-11T15:40:14.261Z · LW(p) · GW(p)
Is it the case the one kind of SSL is more effective for a particular modality, than another? E.g., is masked modeling better for text-based learning, and noise-based learning more suited for vision?