Doomsday Argument Map
post by turchin · 2015-09-14T15:04:15.728Z · LW · GW · Legacy · 32 commentsContents
Meta-DA Reference class DA and medium life expectancy Anthropic shadow and fragility of our environment Thermodynamic version of the DA Previous posts with maps: None 32 comments
The Doomsday argument (DA) is controversial idea that humanity has a higher probability of extinction based purely on probabilistic arguments. The DA is based on the proposition that I will most likely find myself somewhere in the middle of humanity's time in existence (but not in its early time based on the expectation that humanity may exist a very long time on Earth.)
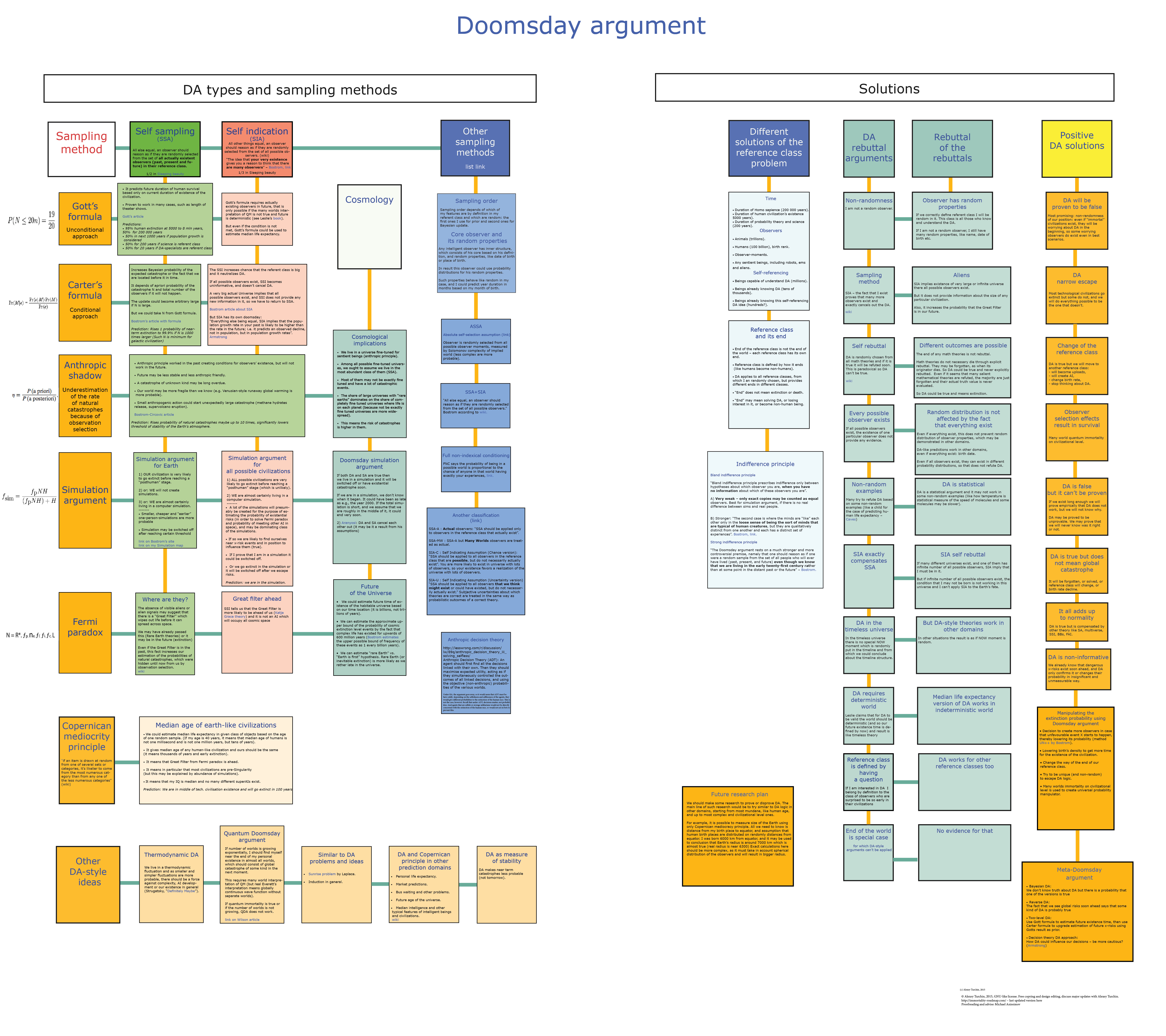
There were many different definitions of the DA and methods of calculating it, as well as rebuttals. As a result we have developed a complex group of ideas, and the goal of the map is to try to bring some order to it. The map consists of various authors' ideas. I think that I haven't caught all existing ideas, and the map could be improved significantly – but some feedback is needed on this stage.
The map has the following structure: the horizontal axis consists of various sampling methods (notably SIA and SSA), and the vertical axis has various approaches to the DA, mostly Gott's (unconditional) and Carters’s (update of probability of existing risk). But many important ideas can’t fit in this scheme precisely, and these have been added on the right hand side.
In the lower rows the link between the DA and similar arguments is shown, namely the Fermi paradox, Simulation argument and Anthropic shadow, which is a change in the probability assessment of natural catastrophes based on observer selection effects.
On the right part of the map different ways of DA rebuttal are listed and also a vertical raw of possible positive solutions.
I think that the DA is mostly true but may not mean inevitable extinction.
Several interesting ideas may need additional clarification and they will also put light on the basis of my position on DA.
Meta-DA
The first of these ideas is that the most reasonable version of the DA at our current stage of knowledge is something that may be called the meta-DA, which presents our uncertainty about the correctness of any DA-style theories and our worry that the DA may indeed be true.
The meta-DA is a Bayesian superstructure built upon the field of DA theories. The meta-DA tells us that we should attribute non-zero Bayesian probability to one or several DA-theories (at least until they are disproved in a generally accepted way) and since the DA itself is a probabilistic argument, then these probabilities should be combined.
As a result the Meta-DA means an increase of total existential risks until we disprove (or prove) all versions of the DA, which may be not easy. We should anticipate such an increase in risk as a demand to be more precautious but not in a fatalist “doom imminent” way.
Reference class
The second idea concerns the so-called problem of reference class that is the problem of which class of observer I belong to in the light of question of the DA. Am I randomly chosen from all animals, humans, scientists or observer-moments?
The proposed solution is that the DA is true for any referent class from which I am randomly chosen, but the mere definition of the referent class is defining the type it will end as; it should not be global catastrophe. In short, any referent class has its own end. For example, if I am randomly chosen from the class of all humans, than the end of the class may mean not an extinction but a creation of the beginning of the class of superhumans.
But any suitable candidate for the DA-logic referent class must provide the randomness of my position in it. In that case I can’t be a random example of the class of mammals, because I am able to think about the DA and a zebra can’t.
As a result the most natural (i.e. providing a truly random distribution of observers) referent class is a class of observers who know about and can think about DA. The ability to understand the DA is the real difference between conscious and unconscious observers.
But this class is small and young. It started in 1983 with the works of Carter and now includes perhaps several thousand observers. If I am in the middle of it, there will be just several thousand more DA-aware observers and there will only be several decades more before the class ends (which unpleasantly will coincide with the expected “Singularity” and other x-risks). (This idea was clear to Carter and also is used in so called in so-called Self-referencing doomsday argument rebuttal https://en.wikipedia.org/wiki/Self-referencing_doomsday_argument_rebuttal)
This may not necessarily mean the end of the global catastrophe, but it may mean that there will soon be a DA rebuttal. (And we could probably choose how to fulfill the DA prophecy by manipulating of the number of observers in the referent class.)
DA and medium life expectancy
DA is not unnatural way to see in the future as it seems to be. The more natural way to understand the DA is to see it as an instrument to estimate medium life expectancy in the certain group.
For example, I think that I can estimate medium human life expectancy based on your age. If you are X years old, human medium life expectancy is around 2X. “Around” here is very vague term as it more like order of magnitude. For example if you are 25 years old, I could think that medium human life expectancy is several decades years and independently I know its true (but not 10 millisecond or 1 million years). And as medium life expectancy is also may be applied to the person in question it may mean that he will also most probably live the same time (if we will not do something serious about life extension). So there is no magic or inevitable fate in DA.
But if we apply the same logic to civilization existence, and will count only a civilization capable to self-destruction, e.g. roughly after 1945, or 70 years old, it would provide medium life expectancy of technological civilizations around 140 years, which extremely short compare to our estimation that we may exist millions of years and colonize the Galaxy.
Anthropic shadow and fragility of our environment
|t its core is the idea that as a result of natural selection we have more chances to find ourselves in the world, which is in the meta-stable condition on the border of existential catastrophe, because some catastrophe may be long overdue. (Also because universal human minds may require constantly changing natural conditions in order to make useful adaptations, which implies an unstable climate – and we live in period of ice ages)
In such a world, even small human actions could result in global catastrophe. For example if we pierce a overpressured ball with a needle.
The most plausible candidates for such metastable conditions are processes that must have happened a long time ago in most worlds, but we can only find ourselves in the world where they are not. For the Earth it may be sudden change of the atmosphere to a Venusian subtype (runaway global warming). This means that small human actions could have a much stronger result for atmospheric stability (probably because the largest accumulation of methane hydrates in earth's history resides on the Arctic Ocean floor, which is capable of a sudden release: see https://en.wikipedia.org/wiki/Clathrate_gun_hypothesis). Another option for meta-stability is provoking a strong supervolcane eruption via some kind of earth crust penetration (see “Geoingineering gone awry” http://arxiv.org/abs/physics/0308058)
Thermodynamic version of the DA
Also for the western reader is probably unknown thermodynamic version of DA suggested in Strugatsky’s novel “Definitely maybe” (Originally named “A Billion years before the end of the world”). It suggests that we live in thermodynamic fluctuation and as smaller and simpler fluctuations are more probable, there should be a force against complexity, AI development or our existence in general. Plot of the novel is circled around pseudo magical force, which distract best scientists from work using girls, money or crime. After long investigation they found that it is impersonal force against complexity.
This map is a sub-map for the planned map “Probability of global catastrophe” and its parallel maps are a “Simulation argument map” and a “Fermi paradox map” (both are in early drafts).
PDF of the map: http://immortality-roadmap.com/DAmap.pdf
Previous posts with maps:
A map: AI failures modes and levels
A Roadmap: How to Survive the End of the Universe
A map: Typology of human extinction risks
Roadmap: Plan of Action to Prevent Human Extinction Risks
32 comments
Comments sorted by top scores.
comment by Avo · 2015-09-17T01:09:18.885Z · LW(p) · GW(p)
I've been doing some more reading on DA, and I now believe that the definitive argument against it was given by Dennis Dieks in his 2007 paper "Reasoning about the future: Doom and Beauty". See sections 3 and 4. The paper is available at http://www.jstor.org/stable/27653528 or, in preprint form, at http://www.cl.cam.ac.uk/~rf10/doomrev.pdf Dieks shows that a consistent application of DA, in which you use the argument that you are equally likely to be any human who will ever live, requires you to first adjust the prior for doom that you would have used (knowing that you live now). Then, inserting the adjusted prior into the usual DA formula simply gives back your original prior! Brilliant, and (to me) utterly convincing.
Replies from: turchin↑ comment by turchin · 2015-09-17T10:43:41.354Z · LW(p) · GW(p)
Thanks for the link. Does it work on toy models of DA in other domains?
For example, if I ask your age and you will say "30 years old" (guessing), I can conclude from it that medium human life expectancy is around several decades years with 50 per cent confidence, and that it is less than 1000 years with 95 per cent confidence.
Which priors I am using here?
Replies from: Avo↑ comment by Avo · 2015-09-17T17:00:13.167Z · LW(p) · GW(p)
For a general analysis along the same lines of life expectancies of various phenomena, see Carl Caves, "Predicting future duration from present age: Revisiting a critical assessment of Gott's rule", http://arxiv.org/abs/0806.3538 . Caves shows (like Dieks) that the original priors are the correct ones. In my example of the biologist and the the bacterium, the biologist is correct.
Replies from: turchin↑ comment by turchin · 2015-09-17T19:24:42.139Z · LW(p) · GW(p)
I know the paper, read it and found a mistake. The mistake is that while illustrating his disproval of DA, he creates special non random case, something like 1 month child for estimation of median life expectancy. It means that he don't understand the main idea of DA logic, that is we should use one random sample to estimate total set size.
Replies from: Avo↑ comment by Avo · 2015-09-17T23:20:43.619Z · LW(p) · GW(p)
Why is that case "non random"? A randomly selected person could well turn out to be a 1 month old child. If you know in advance that this is not typical, then you already know something about median life expectancy, and that is what you are using to make your estimate, not the age of the selected person.
Do you have a criticism of Caves' detailed mathematical analysis? It seems definitive to me.
And: to the person who keeps downvoting me. Are you treating my "arguments as soldiers", or do you have a rational argument of your own to offer?
Replies from: turchin, turchin↑ comment by turchin · 2015-09-17T23:38:53.173Z · LW(p) · GW(p)
In Cave case this argument was nonrandom, because he knew that median life expectancy was 80 years, and deliberately choose extremely young person. So he was cheating. If he would need really random person he should apply to him self or reader. It will be real experiment. I decided not to search math errors in his calculations, because I don't agree this his notion of "randomness".
Replies from: gjm↑ comment by gjm · 2015-09-18T16:26:05.567Z · LW(p) · GW(p)
I don't see how this is cheating. Cave's central claim is this (paraphrased rather than quoted): "If you wish to predict how long something will last on the basis of how long it has existed so far, and you have any further information about relevant time scales, then the DA will give bad predictions because it implicitly uses a prior that's invariant under temporal scaling."
He agrees that if you take a thousand random people and proclaim that half of them are in the first halves of their lives, you will probably be about right. But he disagrees with any version of the DA that says that for each of those people you should assign a 0.5 probability that they're in the first half of their life -- because you have some further information about human lifespans that you should be taking into account.
Cases in which the DA is applied usually have vaguer information about relevant timescales; e.g., if you want to predict how long the US will continue to exist as a nation, there are all kinds of relevant facts but none of them quite takes the form "we have a huge sample of nations similar to the US, and here's how their lifetimes were distributed". But usually there are some grounds for thinking some lifetimes more credible than others in advance of discovering how long the thing has lasted so far (e.g., even if you had no idea when the US came into existence you would be pretty surprised to find it lasting less than a week or more than a million years). And, says Caves, in that situation your posterior distribution for the total lifespan (after discovering how long the thing has existed so far) should not be the one provided by the DA.
So the examples he should be looking at are exactly ones where you have some prior information about lifespan; and the divergence between the "correct" posterior and the DA posterior, if Caves is right, should be greatest for examples whose current age is quite different from half the typical lifespan. So how's it cheating to look at such examples?
Replies from: turchin, Avo↑ comment by turchin · 2015-09-19T20:42:10.327Z · LW(p) · GW(p)
Basically, there is nothing do disagree here: DA is working, but gives weaker predictions, than actual information about distributions. That is why we should try to use DA in domains where we don't have initial distribution, just to get order of magnitude estimation.
The more interesting question is how to combine situations where we have some incomplete information about actual distribution and the age of one random object. It seems that Caves suggest to ignore DA in this case. (But there is also Carter's approach to DA, where DA inference is used to update information about known future x-risks, based on fact that we are before it.)
In some cases DA may be stronger than incomplete information provided by other sources. For example, if one extraterrestrial knows for sure, that any mammal life expectancy is less than 1 million years, and than he finds one human being with age 60 years, DA gives him that medium human life expectancy is less than 1000 years. In this case DA is much stronger than prior.
↑ comment by Avo · 2015-09-18T18:37:01.963Z · LW(p) · GW(p)
That's a very good summary of Caves' argument, thanks for providing it.
EDIT: I upvoted you, but now I see someone else has downvoted you. As with me, no reason was given.
I am new here at LW. I thought it would be a place for rational discussion. Apparently, however, this is not a universally held belief here.
Replies from: gjm↑ comment by gjm · 2015-09-18T21:11:27.613Z · LW(p) · GW(p)
There's a pretty good level of rational discussion here, better than in most online fora I know of.
Some people are pretty trigger-happy with the downvotes (and some get so worked up over political disagreements that they will go back and downvote many random unrelated comments of yours from the past -- but that's near-universally agreed to be bad and tends to get them banned eventually) but nowhere's perfect. And I think the majority of downvotes are genuinely deserved, though I can't see how anything in this thread deserves them.
↑ comment by turchin · 2015-09-20T14:05:40.155Z · LW(p) · GW(p)
Look, some one may say: "A fair coin could fail heads 20 times in row and you will win million dollar". And it is true. But this does not disprove more general statement that: "playing coin for money has zero expected money win".
The same situation is this Caves and DA.
We could imagine situation there DA is wrong, but its is true in most situations (where it is applyable)
See also my large comment about Caves to gjm.
comment by entirelyuseless · 2015-09-14T16:21:13.852Z · LW(p) · GW(p)
While you didn't make any assumption like this in the post, it's a bit weird to talk about "Doomsday Argument" and "Solutions", as if we know in principle that the argument is wrong and we just have to find out why.
In other words, whether it is right or wrong, there isn't any special reason for the argument to be wrong just because people would like it to be wrong. Trying to get rid of the argument by looking for "solutions" is kind of like going out of your way to look for proofs for the existence of God, just because you want that to be true.
Replies from: turchin↑ comment by turchin · 2015-09-14T17:52:01.113Z · LW(p) · GW(p)
Solution are not only about research if DA is wrong, but about how we should live if it is true.
Personally I think that it is true and the doom is almost inevitable.
We should make some research to prove or disprove DA. The main line of such research would be to try similar to DA logic in other domains, starting from most mundane, like human age, and up to most complex and civilizational level ones.
For example, it is possible to measure size of the Earth using only Copernican mediocracy principle. All we need to know is distance from my birth place to equator, and assumption that human birth places are distributed on randomly distances from equator. I was born 6000 km from equator, and it may be used to conclusion that Earth's radius is around 7000 km which is almost true (real radius is near 6300) Exact calculations here should be more complex, as it must take in account spherical distribution of the observers and will result in bigger (edited) radius.
Replies from: Avo, Lumifer↑ comment by Avo · 2015-09-14T21:04:27.839Z · LW(p) · GW(p)
I think it is an excellent idea to try DA logic in other domains.
Example: A a biologist prepares a petri dish with some nutrients, and implants a small colony of bacteria. The question is: will this colony grow exponentially under these conditions? According to DA logic (with a reference class of all bacteria that will ever live in that petri dish), the biologist does not need to bother doing the experiment, since it is very unlikely that the colony will grow exponentially, because then the current bacteria would be atypical.
To the best of my knowledge, this sort of DA logic is never used by scientists to analyze experiments of this sort (or to decide which experiments to perform). I believe this casts severe doubt on the validity of DA.
Replies from: turchin↑ comment by turchin · 2015-09-14T21:11:44.190Z · LW(p) · GW(p)
Your example is not DA-style, because observer is not self-sampled here. Observer is not bacteria in this experiment. (By the way, most from all existing bacteria is not starters of exponential colonies)
I may suggest another experiment: you tell me your age and I will tell your life expectancy based on DA-logic.
Replies from: Avo↑ comment by Avo · 2015-09-14T21:24:12.769Z · LW(p) · GW(p)
I claim that self-sampling plays no essential role in DA logic.
If you think that self-sampling is essential, then you still must allow one of the bacteria in the petri dish to use DA logic about its own future. If you do not allow the biologist to use DA logic, then the bacterium and the biologist will make different predictions about the likely future. One of them must be more accurate than the other (as revealed by future events). If it is the bacterium that is more accurate, what prevents the biologist from adopting the bacterium's reasoning? I argue that nothing prevents it. And since, in the real world, biologists (and scientists of all fields) do not adopt DA logic, I claim that the most compelling reason for this is the invalidity of DA logic from the get-go.
Replies from: turchin↑ comment by turchin · 2015-09-14T21:57:09.473Z · LW(p) · GW(p)
(I did not downvote you)
Look, we could replace "self sampling" with "random". Random bacteria (from all existing bacteria on Earth) will not start exponential growth. Infinitely small subset of all bacteria will start it. There is no difference between prediction of statistic and biologist in this case. DA is statistical argument. It just say that most of random bacteria will not start exponential growth. The same may be true for young civilizations: most of them will not start exponential growth in the universe. But some may be.
Replies from: Avo↑ comment by Avo · 2015-09-14T22:24:54.876Z · LW(p) · GW(p)
So do you agree with me that, in the experiment I described (a biologist sets up a petri dish with a specific set of initial conditions, and wants to find out if a small bacteria colony will grow exponentially under those conditions), DA logic cannot be applied (by either the biologist or the bacterium) to judge the probable outcome?
Replies from: turchin↑ comment by turchin · 2015-09-14T22:44:56.520Z · LW(p) · GW(p)
DA should be applied to the situation where we know our position in the set, but do not know any other evidence. Of course if we have another source of information about the set size it could overweight DA-logic. If in this experiment the substrate is designed to support bacterial growth, it have is very strong posteriory evidence for future exponential growth.
But if you put random bacteria on random substrate it most likely will not grow. In this case DA works. DA here says that 1 bacteria most likely will have only several off springs, and it is true for most random bacteria on random substrates.
So, will DA works here or not depends of details of the experiment with you did not provide.
Replies from: Avo↑ comment by Avo · 2015-09-14T22:57:32.156Z · LW(p) · GW(p)
OK, let me rephrase the question.
The biologist has never heard of DA. He sets up the initial conditions in such a way that his expectation (based on all his prior knowledge of biology) is that the probability of exponential growth is 50%.
Now the biologist is informed of DA. Should his probability estimate change?
Replies from: turchin↑ comment by turchin · 2015-09-14T23:12:44.745Z · LW(p) · GW(p)
Probably, not, as he has a lot of information about the subject. DA is helpful in case if you don't have any other information about the subject. Also DA is statistical argument thereby it could not be disproved by counterexample. It is always possible to construct a situation where it will not work. Like some molecules in the air are not moving, despite the fact that median velocity is very high.
It may be used in such problems as bus waiting problem (variant of Laplace sunrise problem). If last bus was 5 minutes ago, want is the probability that it will come in next 1 millisecond, next 5 minutes? next 1 year?
Replies from: Avo↑ comment by Avo · 2015-09-15T06:14:20.996Z · LW(p) · GW(p)
At least some DA proponents claim that there should always be a change in the probability estimate, so I am pleased to see that you agree that there are situations where DA conveys no new information.
Replies from: turchin↑ comment by turchin · 2015-09-15T08:25:58.289Z · LW(p) · GW(p)
The situation would change, if I were Adam, first man in the world, and a priory will be able to start exponential human growth with P= 50 per cent probability (or think so). After finding that I am Adam, I would have to update this probability to lower. The way I update depends of sampling method - SSA or SIA but both result in early doom. SSA says that I am in short world. SSI said that my apriory estimation of universal distribution of short and long civilization may be wrong. It would be especially clear if apriory P would not 50 percent, but say 90 per cent.
↑ comment by Lumifer · 2015-09-14T18:25:17.024Z · LW(p) · GW(p)
and assumption that human birth places are distributed on randomly distances from equator.
Which is a pretty silly assumption that happens to be not true in real life.
Replies from: turchin↑ comment by turchin · 2015-09-14T19:03:33.978Z · LW(p) · GW(p)
It's clear that this assumption may be refined in two ways: accounting for spherical geometry and accounting for agriculture conditions, both of which will result in higher density near equator and thus larger Earth radius in this calculation. But if we are interesting to estimate Earth's radius just up to order of magnitude, it will still work.
The main idea was to present another DA-style calculation and check if DA-logic works. It works.
Replies from: Lumifer↑ comment by Lumifer · 2015-09-14T19:34:50.072Z · LW(p) · GW(p)
Before accounting for agricultural conditions you probably should account for the distribution of land masses... But anyway, how is this a "DA-style calculation"?
Replies from: turchin↑ comment by turchin · 2015-09-14T19:42:35.420Z · LW(p) · GW(p)
DA-style here means that my position is some set is used to estimate total size of the set, assuming that I random observer from this set. DA-style is also means that we ignore other available information about me, Earth etc, but use only my position in the set to get very rough estimate of total size of the set. The study of such DA-style predictions in known domains could help us estimate validity of DA in unknown domains.
Replies from: Lumifercomment by selylindi · 2015-10-17T02:48:41.393Z · LW(p) · GW(p)
This is probably the wrong place to ask, but I'm confused by one point in the DA.
For reference, here's Wikipedia's current version:
Denoting by N the total number of humans who were ever or will ever be born, the Copernican principle suggests that humans are equally likely (along with the other N − 1 humans) to find themselves at any position n of the total population N, so humans assume that our fractional position f = n/N is uniformly distributed on the interval [0, 1] prior to learning our absolute position.
f is uniformly distributed on (0, 1) even after learning of the absolute position n. That is, for example, there is a 95% chance that f is in the interval (0.05, 1), that is f > 0.05. In other words we could assume that we could be 95% certain that we would be within the last 95% of all the humans ever to be born. If we know our absolute position n, this implies[dubious – discuss] an upper bound for N obtained by rearranging n/N > 0.05 to give N < 20n.
My question is: What is supposed to be special about the interval (0.05, 1)?
If I instead choose the interval (0, 0.95), then I end up 95% certain that I'm within the first 95% of all humans ever to be born. If I choose (0.025, 0.975), then I end up 95% certain that I'm within the middle 95% of all humans ever to be born. If I choose the union of the intervals (0, 0.475) & (0.525, 1), then I end up 95% certain that I'm within the 95% of humans closer to either the beginning or the end.
As far as I can tell, I could have chosen any interval or any union of intervals containing X% of humanity and then reasonably declared myself X% likely to be in that set. And sure enough, I'll be right X% of the time if I make all those claims or a representative sample of them.
I guess another way to put my question is: Is there some reason - other than drama - that makes it special for us to zero in on the final 95% as our hypothesis of interest? And if there isn't a special-making reason, then shouldn't we discount the evidential weight of the DA in proportion to how much we arbitrarily zero in on our hypothesis, thereby canceling out the DA?
Yes, yes, given that there's so much literature on the topic, I'm probably missing some key insight into how the DA works. Please enlighten.
Replies from: Vaniver, turchin↑ comment by Vaniver · 2015-10-17T07:07:28.161Z · LW(p) · GW(p)
If I instead choose the interval (0, 0.95), then I end up 95% certain that I'm within the first 95% of all humans ever to be born.
What would this imply about the total number of humans? If you knew that you were the 50th percentile human, for example, that would give you the total number of humans, and the same is true for all percentiles.
I think the 'continuous' approach to the DA, which does not rely on the 'naturalness' of 1/20th, goes like the following:
Suppose across all of time there are a finite number of humans, and that we can order them by time of birth.
To normalize the birth orders, we can divide each person's position in the ordering by the total number of people, meaning each person corresponds to a fractile between 0.0 and 1.0.
My prior should be that my fractile is uniformly distributed between 0.0 and 1.0.
Upon observing that I am human number 108 billion, I can now combine this with my prior on the fractile to compute the estimated human population.
There is a 1% chance that my fractile is between 0.99 and 1.0, which would imply there is a 1% chance the total number of humans is between 109B and 108B. (The larger number is earlier because it corresponds to being the 99th percentile human instead of the 100th percentile human.) We now add this up for all possible fractiles, to get a distribution and a mean.
This is a tool for integration. If I'm number N and my fractile is f, then the total number of humans is N/f. So we integrate
, which... does not converge. The expected number of future humans is infinite!
But while the expectation diverges, that doesn't mean the most likely value is infinite humans. The median value is determined by f=0.5, where there are only 108B more humans. In fact, for any finite number of humans, one can calculate the probability that there will be that many or fewer humans--which is why the last 95% of humans is relevant. Those are the ones where the extinction numbers are soonest.
Any real resolution of the Doomsday Argument needs to replace the basic structure of "assume uniform prior on fractile distribution, combine with number of observed humans" with "assume uniform prior on fractile distribution, update fractile distribution based on modeled trajectory of history, combine with number of observed humans." For example, one could look at human history and the future and say "look, extinction in the near future seems very likely, and growth to immense numbers seems very likely, but exactly 100B more humans looks very unlikely. We need to replace our Beta(1,1) distribution with something like a Beta(0.5,0.5) distribution."