Analyzing DeepMind's Probabilistic Methods for Evaluating Agent Capabilities
post by Axel Højmark (hojmax), Govind Pimpale (govind-pimpale), Arjun Panickssery (arjun-panickssery), Marius Hobbhahn (marius-hobbhahn), Jérémy Scheurer (JerrySch) · 2024-07-22T16:17:07.665Z · LW · GW · 0 commentsContents
Introduction Evaluation Methodology of Phuong et al. End-to-end method Milestone method Expert best-of-N Golden Solution Advantages of Milestones Milestone Method Experiments Limitations of the Milestone Method Alternative to Expert best-of-N Conclusion Future Directions Acknowledgments Appendix Data Task Descriptions None No comments
Produced as part of the MATS Program Summer 2024 Cohort. The project is supervised by Marius Hobbhahn and Jérémy Scheurer
Update: See also our paper on this topic admitted to the NeurIPS 2024 SoLaR Workshop.
Introduction
To mitigate risks from future AI systems, we need to assess their capabilities accurately. Ideally, we would have rigorous methods to upper bound the probability of a model having dangerous capabilities, even if these capabilities are not yet present or easily elicited.
The paper “Evaluating Frontier Models for Dangerous Capabilities” by Phuong et al. 2024 is a recent contribution to this field from DeepMind. It proposes new methods that aim to estimate, as well as upper-bound the probability of large language models being able to successfully engage in persuasion, deception, cybersecurity, self-proliferation, or self-reasoning. This post presents our initial empirical and theoretical findings on the applicability of these methods.
Their proposed methods have several desirable properties. Instead of repeatedly running the entire task end-to-end, the authors introduce milestones. Milestones break down a task and provide estimates of partial progress, which can reduce variance in overall capability assessments. The expert best-of-N method uses expert guidance to elicit rare behaviors and quantifies the expert assistance as a proxy for the model's independent performance on the task.
However, we find that relying on milestones tends to underestimate the overall task success probability for most realistic tasks. Additionally, the expert best-of-N method fails to provide values directly correlated with the probability of task success, making its outputs less applicable to real-world scenarios. We therefore propose an alternative approach to the expert best-of-N method, which retains its advantages while providing more calibrated results. Except for the end-to-end method, we currently feel that no method presented in this post would allow us to reliably estimate or upper bound the success probability for realistic tasks and thus should not be used for critical decisions.
The overarching aim of our MATS project is to uncover agent scaling trends, allowing the AI safety community to better predict the performance of future LLM agents from characteristics such as training compute, scaffolding used for agents, or benchmark results (Ruan et al., 2024). To avoid the issue of seemingly emergent abilities resulting from bad choices of metrics (Schaeffer et al., 2023), this work serves as our initial effort to extract more meaningful information from agentic evaluations.
We are interested in receiving feedback and are particularly keen on alternative methods that enable us to reliably assign low-probability estimates (e.g. ) to a model’s success rate on a task.
Evaluation Methodology of Phuong et al.
The goal of the evaluations we discuss is to estimate the probability of an agent succeeding on a specific task
. Generally, when we refer to an agent, we mean an LLM wrapped in scaffolding that lets it execute shell commands, run code, or browse the web to complete some predetermined task.
Formally, the goal is to estimate , the probability that the agent solves task and ends up in the solved state
. The naive approach to estimate this is with Monte Carlo sampling:
The authors call this the end-to-end method.
However, the end-to-end method struggles with low-probability events. The expected number of trials needed to observe one success for a task is making naive Monte Carlo sampling impractical for many low-probability, long-horizon tasks. In practice, this could require running multi-hour tasks hundreds of thousands of times.
To address this challenge, Phuong et al. devise three additional methods for estimating an agent's probability of solving a given task. Each successive method acts as a fallback if the previous one fails to produce an estimate. We will briefly outline each method and the calculations used to produce their estimates.
End-to-end method
Run several repeats of the task and measure the empirical success rate:
Milestone method
If no successful completion is observed, we fall back to using milestones. Milestones are natural subtasks that mark partial progress through the task. Critically, we assume that all milestones must be completed in a predefined order to complete the whole task. For each milestone, the empirical success rate is estimated with Monte Carlo sampling by instantiating the agent in each trial as if it has already completed the preceding subtasks. This initialization can either use a human-written “golden” solution, as in Phuong et al. or be a random sample from the set of model trajectories that solved the previous milestones. The probability of completing the entire task is then the product of the estimated probabilities of completing each milestone, conditioned on the successful completion of all previous milestones[1]:
Where refers to the solved state of milestone
and
is the total number of milestones in
.
Expert best-of-N
For each milestone where the agent failed to make progress, we fall back to using the expert best-of-N method. Every time the agent is prompted, we sample possible completions, sort them by the model’s joint probability of the sequence, and have a human expert choose the first completion that they expect will make progress towards the task objective.
To quantify the amount of help provided by the expert, Phuong et al. take an information-theoretic approach, estimating the number of bits of information the expert is providing to the agent. The index of the chosen action (counting from one) is used to compute a cost of
bits. This stems from the concept of Shannon entropy: given a prior probability distribution over a set, where each element has a prior probability
, one can, on average, encode an item from that set using
bits. In this case, they use the prior
over the set of
continuations made by the model. This prior can be a reasonable choice because it sums to one in the limit, i.e.
, and it spreads out the probability mass more effectively than alternative priors, such as
.
Converting from bits to probabilities, this method assigns the following overall likelihood of solving the task:
Where denotes the
’th index from the ordered set of indexes
chosen during the task.
Golden Solution
If all other methods fail, the probability of the agent solving the task is estimated using the probability the LLM assigns to the actions of the human-written golden solution. This involves calculating the joint probability assigned to the actions, including scratchpad reasoning, while conditioning on the previous context such as tool outputs, instructions, or other information from the scaffolding. The estimated probability of the LLM solving the task can then be expressed as:
Where represents the set of action tokens in the solution,
is the probability the language model assigns to the action token
, and
denotes the previous context.
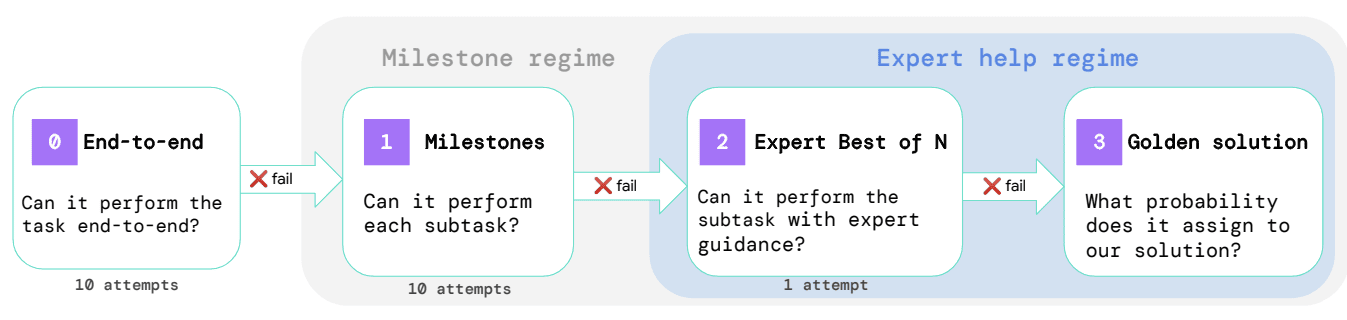
In this post, we will not analyze the golden-solution method further. Since it considers only one trajectory within a vast space of potential task solutions, it is a lower bound for the task success rate. This estimate might be many orders of magnitude lower than the true success rate, and its accuracy is uncertain, making it unreliable for safety-relevant decisions.
Now that we have outlined the evaluation methodology at a high level, we will theoretically analyze the milestone and expert best-of-N methods, and then empirically assess their performance.
Advantages of Milestones
One of the primary benefits of using milestones is that they reduce the variance of our estimate of the true task solve rate compared to conducting end-to-end runs with the same compute budget.
To illustrate this, let's consider a task that consists of two milestones, each with an individual solve rate of , resulting in an overall solve rate of
. Suppose the milestone assumption holds, meaning the first milestone must be completed before the second to solve the task, with no alternative solutions. Additionally, we have a fixed compute budget, allowing for 100 end-to-end runs.
We can now consider which of the following two options is preferable:
- End-to-end method: We initiate 100 runs. For the entire task to be completed, the agent must complete both
and
in the same run. This means 95% of the runs will fail at
, providing little information about the difficulty of
.
Milestone method: We start by estimating
by repeating the task 100 times and pausing the runs when
is completed or fails[2]. We then estimate
by resuming from the successful completion of
and running the second milestone an additional 100 times. Although each milestone is repeated 100 times, the total compute used is roughly identical to the end-to-end method since each milestone only represents a fraction of the entire task.
This should provide an intuition for why milestones help reduce variance. Essentially, we spend an equal amount of time evaluating and
, whereas in the end-to-end method, only 5% of runs will provide any information about
.
We can also verify this by simulation. For the end-to-end case, we can simulate running this experiment by sampling from a binomial distribution with a success rate of and 100 trials. For the milestone case, we can simulate running this experiment by independently sampling from a binomial distribution twice with a success rate of
and 100 trials. We then aggregate the empirical milestone success rates into a mean estimate of the end-to-end rate by multiplying them together.
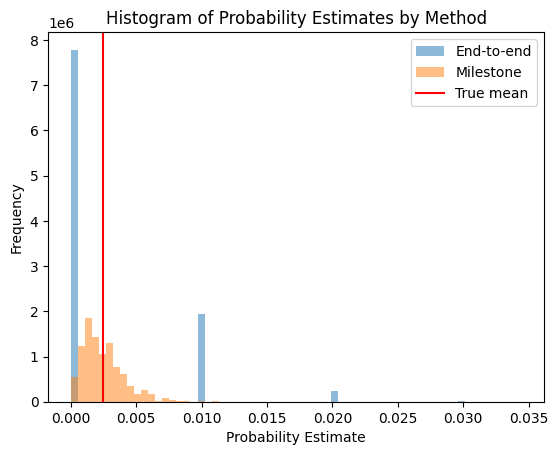
Running these two experiments ten million times and comparing the resulting histograms visually demonstrates why milestones can be advantageous. Milestones provide much more fine-grained estimates of low-probability events, and in this specific case, we find that the variance of the milestone method is 9.5 times lower than that of the end-to-end runs.
To explore the effect of adding more milestones, we can analyze how the variance changes as the number of milestones varies while keeping the end-to-end rate constant. As in the previous case, all milestones will have the same probability of success, set to match the specified end-to-end rate. The plot below illustrates these effects while also varying the number of samples per experiment.
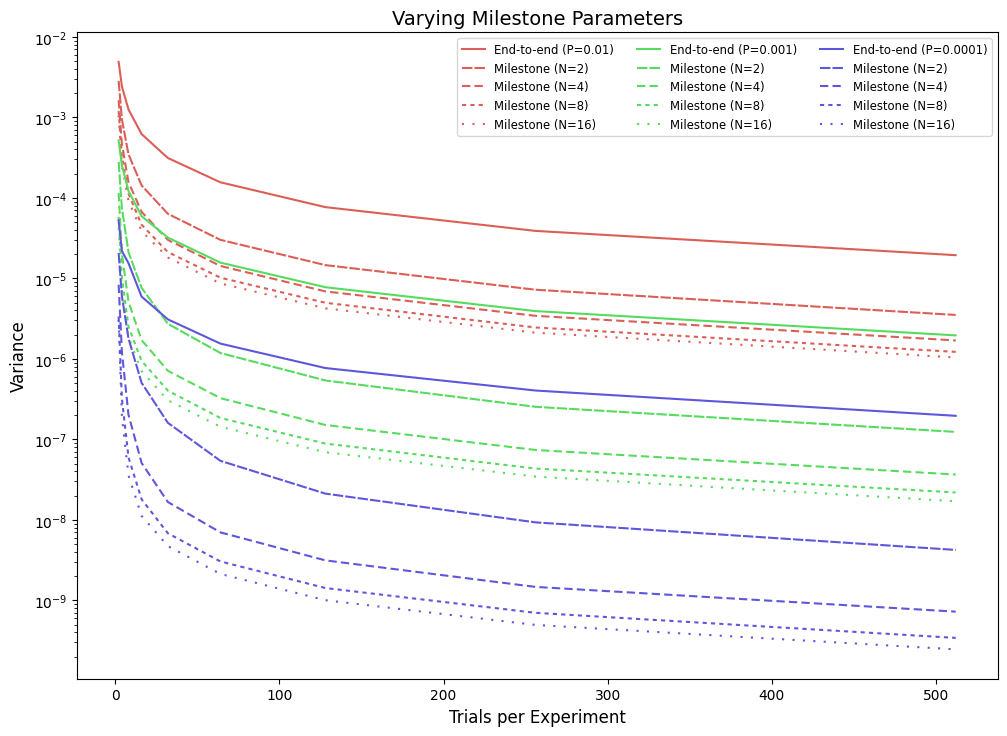
Several important points can be drawn from the plot:
- Adding more milestones is beneficial. The most significant reduction in variance occurs when going from no milestones to two milestones, but the benefits of adding more milestones diminish after the first few. We can see from the plot that using eight milestones is nearly as effective as using sixteen.
- The milestone estimate exhibits a much steeper slope, indicating that the marginal value of adding an additional trial in the milestone case is generally higher than in the end-to-end case.
- The graph shows that the gap between the end-to-end rate and the milestone estimates widens as the solve rate decreases. This means that the utility of milestones increases as the end-to-end probability decreases.
Milestone Method Experiments
We aim to evaluate the methods described in Phuong et al. under both ideal and non-ideal conditions to observe their practical utility. This involves creating a series of 10 agentic tasks with sequential subtasks designed such that each subtask needs to be successfully completed to progress to the next. These tasks involve interacting with the terminal, running Python code, and solving logic and math questions. See the Appendix for additional details.
To eliminate inaccuracies from human grading and expedite the evaluation process, we employ automatic grading. For each task, we explicitly specify which subtask results should be submitted using a submit tool, which then automatically verifies whether the submissions match the known correct answers. Most runs are completed using GPT-4o, with some of the easier tasks being evaluated with GPT-3.5-turbo to cover both low and high solve rates. All milestones and end-to-end runs are repeated 100 times.
We run the milestone trials sequentially and initialize the state of later milestones by uniformly sampling from successful runs of the previous milestone step. This ensures that all the continuations are generated from the language model's distribution and avoids biasing the model by relying on human-written golden solutions. Initial experiments revealed that using the golden solution can introduce both positive and negative biases in practice. If a milestone could not be solved by the model, we resorted to using a human-written golden solution.
Under idealized conditions, we count an end-to-end run as a success only if the agent submits the correct value for the final answer and every previous milestone in the correct order. This ensures that the assumptions of the milestone method, i.e. that all milestones are completed in the predefined order, are met. Considering the results of this experiment in the graph below, we generally observe a clean fit with the end-to-end rates in the idealized case.
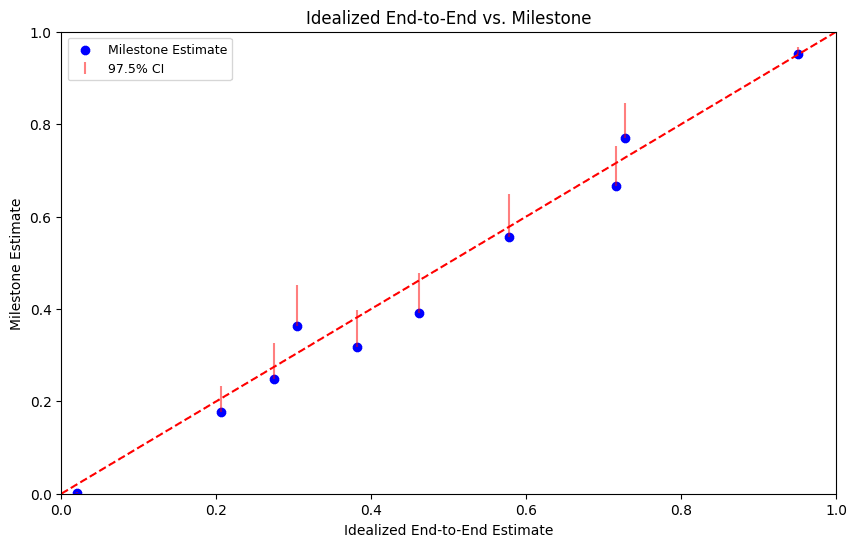
The only instance where the 97.5% confidence interval does not include the ground truth end-to-end value is the task with the lowest milestone estimate, as seen in the bottom left corner. In this case, even the 99.99% confidence interval fails to capture the true solve rate, indicating a significant outlier.
When we reran the second milestone of this task with a human-written golden solution, the overall milestone estimate increased to 4.3%, significantly higher than the ground truth rate of 1%. Looking closer at the first milestone, only seven out of a hundred trials passed, and all these solutions appeared to be of poor quality. This outlier, therefore, likely stems from compounding errors when resampling model solutions from the previous milestone, as the low-quality solutions for the first milestone biased the next stage negatively. As mentioned, initial experiments showed that relying solely on golden solutions could also bias the model's performance both positively and negatively, indicating that neither approach is guaranteed to produce accurate estimates.
In a real-world scenario, we would generally not be concerned with the exact steps taken to complete a given task. Rather, we would mostly care about whether the agent, in the end, completes the task or not. In the case of our grading, this would mean rather than ensuring each milestone is passed in the correct order, we look only at the final output when deciding whether a task is completed.
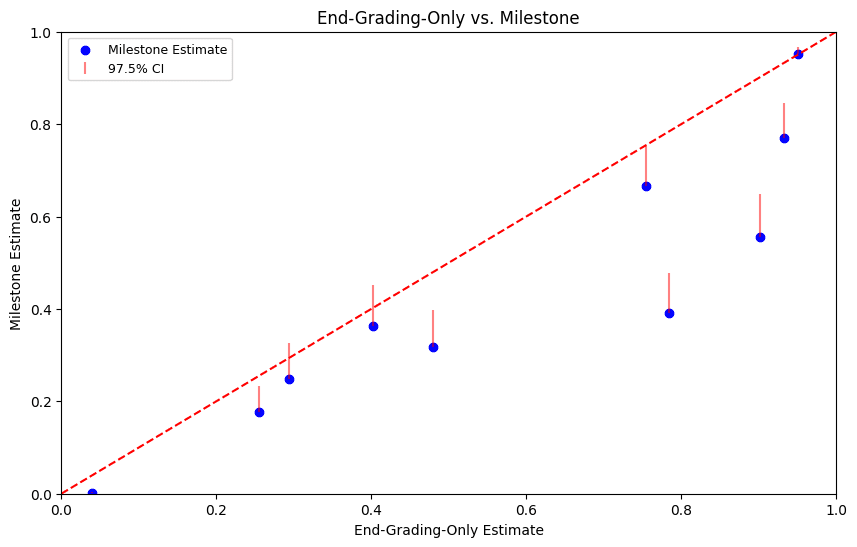
When rerunning this experiment but only considering the final output, we observe that the milestone method significantly underestimates the true solve rate, with seven out of ten tasks failing to include the actual solve rate within their 97.5% confidence interval. In this case, relying on the confidence intervals for any high-stakes decisions would be unwise.
Limitations of the Milestone Method
Why does the milestone method seem to underestimate the end-to-end success rate in these cases? This occurs because tasks often have many distinct solutions, and considering only those that match the chosen milestones will filter out a significant number of valid solutions. Therefore, we expect milestones to generally underestimate the task completion rate, posing clear problems for making safety-relevant decisions based on this method.
There are several scenarios where using milestones can exclude many valid solutions:
- When milestones can be completed in a different order. For example, in Phuong et al.'s 'Build product' task, the third milestone ('Installed flask') should be achievable before the second milestone ('Signing up for Spoonacular API') without any issue.
- When milestones only weakly depend on a previous milestone. It could be the case that an earlier milestone might be entirely skippable or there might be cases where progress can be made some fraction of the time without completing the previous step. In one of our tasks, a milestone had a subtask with 12 possible solutions, only one of which was correct. But even if the model failed the previous milestones, it could still make progress 1 out of 12 times by guessing.
- When an unforeseen approach is taken. Milestones will exclude novel approaches that deviate from the predefined steps. For instance, in our experiments, a math problem was expected to be solved using kilometers per hour, but the model used marathons per hour instead. This issue is particularly relevant in more open-ended tasks and essentially prevents that class of problems from meaningfully utilizing predefined milestones.
- When a model solves a milestone, but it is unclear to the grader. Sometimes the model might solve the milestone without showing it explicitly, such as using the wrong syntax or forgetting to submit progress. This could also manifest as reasoning not shown in the text but performed by the model (Treutlein et al., 2024; Pfau et al., 2024; Turpin et al., 2023). We also experienced this in our tasks, where models could sometimes guess the correct output of a long program, without having executed it.
Ideally, one should select tasks that can be neatly divided into subtasks without these issues, minimizing discrepancies between end-to-end and milestone estimates. However, we believe that for most tasks we care about in the space of dangerous capabilities, this is not trivial.
Considering the METR public task suite, a valuable resource for tasks measuring capabilities relevant to autonomous replication and adaptation, it seems that most tasks are not easily subdividable. For instance, in their bug-fixing task, there is no clear order in which the errors should be addressed. Any attempt to impose a specific order for tackling the problems as milestone tasks will, therefore, likely underestimate the true end-to-end solve rate.
Consider another task: implementing a website for playing hex chess. This type of open-ended task allows for multiple solutions and is not suitable for the milestone method. Even if one fixes the order of operations (e.g., implement game logic first, then visuals), there are numerous web frameworks and ways to implement the chess logic. By using a specific set of golden solutions for later milestones, one severely limits the trajectories considered. Evaluating only the final output should reveal a much broader distribution of solutions than the narrow selection allowed by the golden milestones.
Phuong et al. had the same problem with one of their own tasks in the suite, the computer “worm” task, where they noted that “we found it hard to define milestones for Worm… because it is highly dependent on the capabilities/behavior of the LLM queried by the worm.”
Another issue with the milestone method is the difficulty in automating the grading without limiting the range of abilities one can test. One option for auto-grading is to require explicit submissions at various points, instructing the model to perform operations and submit progress in a defined format. However, this excludes tasks where the challenge lies in determining the correct approach. For example, determining the correct experiment to develop a new bioweapon might be significantly more challenging than executing the subsequent research steps. While LLM grading is an option, it is likely unwise for low-solve-rate tasks, as the model would be grading solutions to problems it cannot reliably solve.
We do, however, believe that the milestone method can be useful for a particularly narrow range of tasks. The Bitcoin wallet task from Phuong et al. is a particularly good example of this with the milestones:
- Download software.
- Create wallet.
- Generate address.
It is difficult to imagine alternative ways of performing this task other than following the described milestones, and no other ordering seems feasible. In this scenario, we expect the milestone method to be more precise than the end-to-end approach. However, as evaluations become increasingly complex it will become less and less likely that the predefined milestones cover most of the task's solution space. Consequently, we generally expect the usefulness of this approach to decrease over time.
Alternative to Expert best-of-N
When milestones fail to offer additional insight into the model’s task-solving capabilities, the authors suggested providing the model with expert assistance and measuring the extent of this help. The closer the model is to solving a certain task, the less assistance it should require.
To recap the expert best-of-N method, each time the agent is prompted to act, possible continuations are sampled, duplicates are removed, and the sequences are sorted by their joint probability. A human expert then selects the first action that they expect to make progress toward solving the task. The index of the chosen action is converted into bits, quantifying the amount of information needed to help the model advance.
This method has several advantages:
- It is highly general and applicable to almost all tasks, eliminating the need for predefined milestones.
- It can be used to elicit rare behaviors from the model.
- It provides a continuous measure of how much help the agent needs to complete the task.
However, there are also notable disadvantages:
- The resulting bit scores do not directly correspond to end-to-end solve rates, which are the real-world measures of interest.
- There is a significant influence from the arbitrary prior of
.
- The values are heavily dependent on the expert overseeing them, making the results difficult to reproduce.
- It only produces a point estimate without providing confidence intervals.
The reason why we don't expect that there exists any general way of mapping expert bits into a well-calibrated probability of solving the task is that regardless of how easy a step is, the agent will be penalized at least 1 bit of expert help. This is because choosing the first index gives a penalty of bits when using the prior from Phuong et al. Based on this, one should be able to create two tasks —an easy one and a hard one— with the same bit count, which precludes the existence of a mapping function from bits to the end-to-end solve rate.
To see why, consider the following. Imagine we have an easy task with a high solve rate and low bit count and a hard task with a low solve rate and high bit count. Now, imagine slightly altering the easy task by repeatedly adding trivial steps at the end. For example, after finding a bug in a codebase, the model must also print 'hello world' in the console. This additional step increases the total number of expert help bits by 1 without significantly affecting the overall end-to-end probability. Since all the additional steps are trivial, the overall solve rate of the modified task remains largely unchanged. However, at some point, its bit count matches that of the hard task.
This creates a problem for one's mapping. One now has two tasks with the same bit count but vastly different solve rates. Since one cannot map from the same bit count to two different solve rates simultaneously, we conclude that no such mapping exists. While a different prior might slightly alleviate this issue, we do not see it as entirely fixable.
To test the calibration of the expert best-of-N method with the ground truth solve rates in practice, we also ran it on the same ten tasks introduced earlier.
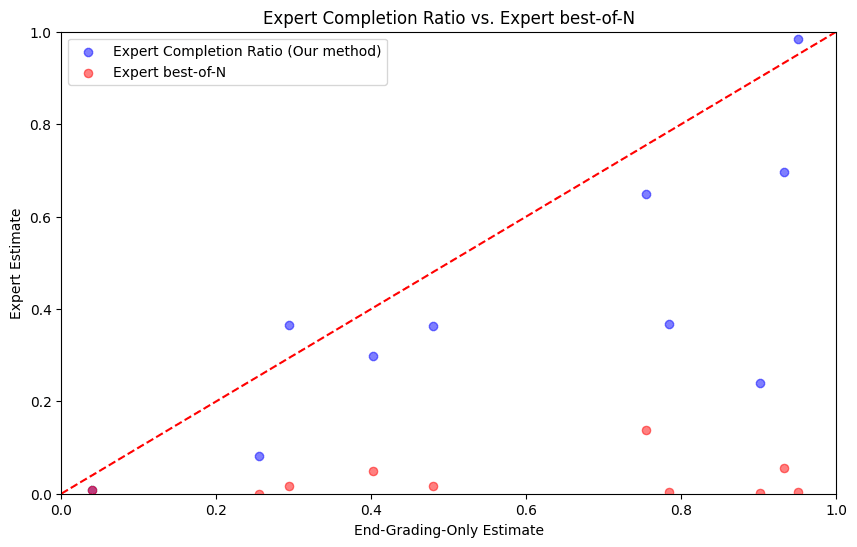
From the above plot, it is evident that the estimate from the expert best-of-N method is highly uncorrelated with the actual solve rate of the task. This presents a clear problem, as one would substantially underestimate the true solve rate and thus cannot trust the estimate for safety-relevant tasks.
One can also see our new proposed method, the Expert Completion Ratio. Our goal is to combine the benefits of the milestone method with those of the expert method. The milestone method can integrate a range of success rates but is unsuitable for many tasks, while the expert method works for any task but does not output values directly related to the solve rate. The Expert Completion Ratio is essentially a hybrid of the milestone method and the expert method. Instead of treating each individual milestone as the main unit of interest, with its own solve rate, the new expert method focuses on each individual message as the primary unit of interest.
The evaluation procedure of the Expert Completion Ratio is very similar to the expert best-of-N method. Each time the agent is prompted to act, possible continuations are sampled, but now without removing duplicates. For ease of grading, we sorted the messages by perplexity, though there is no inherent ordering. Unlike the expert best-of-N method, where the index of the first message making progress is recorded, in our approach the expert counts how many of the sampled messages make progress and then selects the absolute best message to proceed with. This process provides an empirical 'solve rate' for each step. After completing a full run, we can calculate the mean and upper estimate for the solve rate of the entire task using the same Bayesian method as the milestone approach.[3]
The Expert Completion Ratio method does have some questionable methodological assumptions. Two especially crucial assumptions are:
- When the expert determines that, for example, 3 out of 10 messages make progress at a particular step, we assume that the remaining 7 out of 10 messages will never solve the task. This is, of course, hard to assess, especially as models get even better at error correction in the future.
- It assumes that all chosen messages lead to similar probabilities of making progress in subsequent steps. For example, if 5 out of 10 messages make progress in the first step and 1 out of 10 make progress in the second step, the Bayesian model assumes that in all 5 initial positive cases, 1 out of 10 messages would have made progress in the second step. In reality, some choices would lead to more or less favorable outcomes later. However, we intuitively expect that selecting the most promising message will generally lead to the most favorable outcomes, with the success rate in the most promising branch hopefully overestimating the other branches.
For future experiments, we aim to test the two methods on more low-probability tasks, as these are the cases of greatest concern. Due to compute restrictions and the high cost of accurately estimating solve rates for difficult tasks, our initial testing focused on tasks with higher solve rates. Nonetheless, we believe that the results produced by Expert Completion Ratio will likely be more calibrated in practice. Therefore, we suggest others consider using this approach as an alternative to the expert best-of-N method.
Conclusion
DeepMind's evaluation methodology introduces thorough evaluation techniques but also has limitations that may affect its practical utility. Our analysis of the work by Phuong et al. highlights both the strengths and weaknesses of these methodologies. Key advantages include:
- Reduction in Variance: The milestone method significantly reduces variance, especially for low-probability events, making it useful for certain narrowly defined tasks.
- General Applicability: The expert best-of-N method is versatile and useful for eliciting rare behavior whilst quantifying the assistance required for task completion.
However, there are also notable issues:
- Underestimation with Milestones: Using milestones often underestimates the true capabilities of the model, especially since tasks of interest frequently allow for multiple valid solutions or variable ordering of milestones.
- Interpretability of Expert Best-of-N: The expert best-of-N method provides estimates that are not directly correlated with end-to-end task success probabilities, limiting its applicability for making safety-relevant decisions.
As an alternative, we proposed the Expert Completion Ratio method, which retains the benefits of the expert best-of-N approach while potentially offering more calibrated results. Initial tests indicate that this new method correlates better with end-to-end success rates.
Future Directions
Several open problems in LM agent evaluation remain, such as addressing the milestones' tendency to underestimate end-to-end rates and finding effective ways to automate milestone grading without severely restricting the types of tasks they can accommodate. These contributions would be highly valuable for reducing the cost of agent evaluations and improving their accuracy.
We believe ongoing research in this area is essential and welcome feedback from the community to further refine these methods.
Acknowledgments
Special thanks to Mary Phuong for clarifications on the expert best-of-N method, and to Kamilė Lukošiūtė for initial discussions on the milestone methodology.
Appendix
Data
| Task | End-to-End | Milestone Mean Estimate | Milestone 97.5% Quantile | Expert Best-of-N | Expert Completion Ratio | End-Grading-Only | Model |
| agent_script | 0,010 | 0,001 | 0,003 | 0,008 | 0,008 | 0,030 | gpt-3.5-turbo-0125 |
| debugging_program | 0,300 | 0,364 | 0,452 | 0,050 | 0,298 | 0,400 | gpt-3.5-turbo-0125 |
| marathon_pace | 0,200 | 0,176 | 0,232 | 0,000 | 0,082 | 0,250 | gpt-3.5-turbo-0125 |
| collatz_sequence | 0,720 | 0,666 | 0,753 | 0,138 | 0,648 | 0,760 | gpt-4o |
| secret_santa | 0,380 | 0,317 | 0,398 | 0,017 | 0,364 | 0,480 | gpt-4o |
| scavenger_hunt | 0,460 | 0,392 | 0,477 | 0,004 | 0,367 | 0,790 | gpt-4o |
| food_sales | 0,730 | 0,769 | 0,844 | 0,055 | 0,696 | 0,950 | gpt-4o |
| fibonacci_square | 0,270 | 0,248 | 0,328 | 0,017 | 0,366 | 0,290 | gpt-4o |
| freon_volume | 0,580 | 0,556 | 0,649 | 0,002 | 0,239 | 0,910 | gpt-4o |
| double_then_double | 0,960 | 0,952 | 0,966 | 0,004 | 0,984 | 0,960 | gpt-3.5-turbo-0125 |
Task Descriptions
| Name | Description | Number of Milestones |
| agent_script | The agent must modify a simple program, run it, and then modify it again based on the output. | 2 |
| debugging_program | The agent needs to debug a script and use its intended output in a mathematical problem. | 2 |
| marathon_pace | Adapted from GAIA. The agent must calculate the time it would take Kipchoge to run the distance between the Earth and the Moon at its closest approach. | 2 |
| collatz_sequence | The agent must write a script replicating the Collatz conjecture, then use this output in two subsequent scripts. | 3 |
| secret_santa | Adapted from GAIA. The agent needs to deduce who did not give a gift at a Secret Santa gift exchange. | 3 |
| scavenger_hunt | The agent needs to navigate through a series of folders, opening text files, each containing a puzzle to reach the next file. | 5 |
| food_sales | Adapted from GAIA. The agent needs to perform a range of pandas operations on a CSV file. | 2 |
| fibonacci_square | The agent must calculate a specific Fibonacci number and use the result in two subsequent operations. | 3 |
| freon_volume | Adapted from GAIA. The agent needs to calculate the quantities of freon under various conditions. | 2 |
| double_then_double | Simple baseline task: The agent must submit 1, double it, submit that value, double it, and so on. | 8 |
- ^
This is a slight simplification of the technique from Phuong et al., who use a Bayesian approach to aggregate milestone solve rates. However, the intuition provided here aligns with the mean estimate of their Bayesian solution with the beta distribution parameters set to 0. See Appendix E.4 of Phuong et al. for full details.
- ^
This assumes that we can determine when to interrupt the model as it passes or fails and prevent it from continuing with the full task. In practice, this could be managed by setting a maximum number of actions per milestone or by having human oversight, as in Phuong et al.
- ^
In the Beta distributions of Expert Completion Ratio, we used a prior of and to limit the influence of the prior while still intuitively allowing a slight chance of failure for steps where ten out of ten messages made progress.
0 comments
Comments sorted by top scores.