Is weak-to-strong generalization an alignment technique?
post by cloud · 2025-01-31T07:13:03.332Z · LW · GW · No commentsThis is a question post.
Contents
But wait! What I want to know is... None Answers 4 Charlie Steiner None No comments
Weak-to-strong generalization (W2SG) was initially presented as an analogy for human supervision of superhuman AI systems. From the paper:
We propose a simple setup for studying the problem of humans supervising superhuman models by considering an analogy: can we use weak models to supervise strong models?
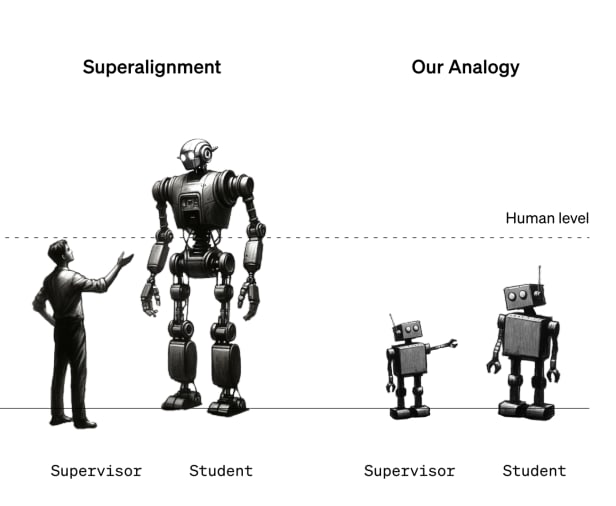
"Humans supervising superhuman models" sounds a lot like achieving scalable oversight, which has at times been defined as:
- [SO-1] "ensur[ing] safe behavior even given limited access to the true objective function," (here)
- [SO-2] "train[ing] an RL agent with sparse human feedback," (here)
- [SO-3] "the ability to provide reliable supervision—in the form of labels, reward signals, or critiques—to models in a way that will remain effective past the point that models start to achieve broadly human-level performance," (here) or
- [SO-4] "assess[ing] whether an action taken or proposed by an AI is good... in a way that works even if the AI is very smart and knowledgeable," (here [LW · GW]).
Despite variation in these definitions, they point at a similar challenge: that of inducing desirable behavior in an AI system when the ability to grade its behavior is limited in quantity or quality.[1] We might say that there is the problem of scalable oversight, and then there are methods that seek to address this problem, which could be termed scalable oversight methods. Informally, these are "methods for humans supervising superhuman models."
So, combining the motivation for W2SG with this definition of scalable oversight, we could then say: W2SG is a model of the problem of scalable oversight. The purpose of the model is to facilitate the development of scalable oversight methods.
But wait!
This does not seem to be how people use these terms. Instead, W2SG and scalable oversight are discussed as different and complementary types of methods! For example, this post [AF · GW] calls them "two approaches to addressing weak supervision," offering the following definitions:
- [SO-R] Scalable oversight: "try to make the supervision signal stronger, such that we return to the 'normal ML' regime;" and
- [W2SG-R] W2SG: "make the strong student (the AI system) generalize correctly from the imperfect labels provided by the weak teacher."
Interpreted narrowly,[2] SO-R excludes many techniques that might qualify under the broader definitions given above. Notably, the definition appears[3] to exclude the given definition of weak-to-strong generalization (W2SG-R), which would arguably qualify as scalable oversight according to definitions above.
- According to SO-1: If a W2SG-R method causes the AI to "generalize correctly from imperfect labels," then it has "ensured safe behavior even given limited access to the true objective function." So it is a scalable oversight method.
- According to SO-2: if a W2SG-R method can convert sparse human feedback into a more "dense" form of supervision, then it could be used to "train an RL agent with sparse human feedback." So it is a scalable oversight method.
- etc...
Similarly, this post asks "how can we combine W2SG with scalable oversight?" and talks about W2SG as an alternative alignment method.
In fact, even the original W2SG paper refers to W2SG as a kind of technique in appendix G, although there is no mention of what such a technique might look like, concretely.
Our plan for aligning superintelligence is a work in progress, but we believe that weak-to-strong techniques could serve as a key ingredient. In this section we sketch several illustrative possiblities for how we could use weak-to-strong generalization to help align superintelligent systems.
...We will align this model using our most scalable techniques available, e.g. RLHF (Christiano et al., 2017; Ouyang et al., 2022), constitutional AI (Bai et al., 2022b), scalable oversight (Saunders et al., 2022; Bowman et al., 2022), adversarial training, or—the focus of this paper—-weak-to-strong generalization techniques.
Referring to "scalable oversight" and "W2SG" as alignment strategies feels like a type error to me-- at least, according to my preferred definitions. But I'm not interested in debating definitions.
What I want to know is...
- Is weak-to-strong generalization an alignment technique?
- What even is a W2SG technique?[4]
- If a strong model is not deceptively aligned (an assumption), why would it be beneficial to use a weak model to generate labels instead of using the strong model?
- ^
Note: definition SO-4 is broader in that it includes evaluation, not just training.
- ^
The narrow interpretation of SO-R: "scalable oversight methods are methods which intervene only via the labels(/grades) used to train the (primary) AI."
- ^
It's not clear that SO-R actually excludes W2SG-R. A W2SG-R method generates labels to train the student to "generalize better," which would seem to qualify as "making the supervision signal stronger."
- ^
The posts linked above mention combinations of scalable oversight and W2SG, but by combining the two together, it's not clear what the "W2SG" part is. In some cases, W2SG seems to refer merely to the hope that a powerful model will generalize from imperfectly-labeled data, e.g.:
One unappealing aspect of W2SG is that when we actually apply it to tasks we can’t evaluate and don’t have ground truth for, we are to some extent taking a “leap of faith on generalization.”
Answers
Not being an author in any of those articles, I can only give my own take.
I use the term "weak to strong generalization" to talk about a more specific research-area-slash-phenomenon within scalable oversight (which I define like SO-2,3,4). As a research area, it usually means studying how a stronger student AI learns what a weaker teacher is "trying" to demonstrate, usually just with slight twists on supervised learning, and when that works well, that's the phenomenon.
It is not an alignment technique to me because the phrase "alignment technique" sounds like it should be something more specific. But if you specified details about how the humans were doing demonstrations, and how the student AI was using them, that could be an alignment technique that uses the phenomenon of weak to strong generalization.
I do think the endgame for w2sg still should be to use humans as the weak teacher. You could imagine some cases where you've trained a weaker AI that you trust, and gain some benefit from using it to generate synthetic data, but that shouldn't be the only thing you're doing.
No comments
Comments sorted by top scores.