Compression Moves for Prediction
post by adamShimi · 2024-09-14T17:51:12.004Z · LW · GW · 0 commentsThis is a link post for https://epistemologicalfascinations.substack.com/p/compression-moves-for-prediction
Contents
Summarization: Taming The Ocean of Data Reduction: Going Beyond Existing Settings Precomputation: Taming Fundamental Calculations Conclusion None No comments
Imagine that you want to predict the behavior of some system -- the weather, a computer program, a real-world language... However you go about it, I bet you will do some compression: you'll find simple and minimal and concrete ways to think about the vast complexity of your system that helps you predict what you want to predict.
At a fundamental level, prediction is compression.
Yet what does compression looks like in practice? Are all compressions done in the same way, with the same goals, considering the same tradeoffs?
No. In fact, there are distinct forms of compressions for different problem setups, different compression moves for solving different issues. The ones I want to discuss today are summarization, reduction, and precomputation:
- When you are drowning in data, you need summarization
- When you want to extend your model to different settings, you need reduction
- When you are swamped by the computational difficulties of applying your model, you need precomputation.
Note that this post focuses exclusively on cases where we're predicting a system over which we have no control. This is the usual set up for natural sciences such as physics, chemistry, biology, or historical ones such as geology and historical linguistics. But note that in other settings, such as economics or engineering sciences, your ability to constrain the system unlocks a whole new range of moves to make the system easier to predict.[1]
Summarization: Taming The Ocean of Data
In many predictive endeavors, your first problem is the overabundance of data.[2]
Imagine massive tables and charts with eye watering rows of numbers after numbers.They could represent various temperature measurements, or the weights of a neural network, or the different versions of the the same word across language in a family...
How do you make sense of that? How do you even start to think about it with a human's small and puny brain?
Well, you summarize.
Instead of keeping all the data, you find some thread, some regularity, some pattern in them that you leverage for prediction. Such summaries can take many different forms.
The most well-know one, due to physics' cultural hegemony, are the quantitative regularities: relating core factors/components of your data into an equation. The list includes the gas laws relating pressure, volume, and temperature in gases; large scale macroeconometric models capturing relations between many different economic variables like inflation rate, interest rate, and GDP; and the Weber-Fechner law describing the logarithmic scale underlying our comparative sensations.
But summaries don't need to be quantitative. For example, the sound laws in historical linguistics capture how sounds evolve through time: they highlight things like dropping of phonemes, contractions, replacements...[3]
Another class of summaries are the classifications: putting data into different categories, potentially related together. The most famous example is the Linnaean taxonomy of species, but you can also find this in the classification of finite simple groups in maths or the classification of functional groups in chemistry.
Last but not least, some summaries are algorithmic: they link conditions and results through if-then patterns. We use such algorithmic summaries constantly with the machines in our everyday lives: fridges, computers, washing machines, phones... Unless you are a trained engineer in the underlying fields, your model of how such machines work is a partial algorithmic summary based on what you tried, what worked, and maybe some informations that you got here and there.[4]
When we think about the summarization move, what's essential to keep in mind is that a summary doesn't try to find the "true" or "correct"or "exact"description of the data.
Yes, it needs to fit the data, but falling for the correspondence theory of truth would make us miss all the conceptual engineering that goes into the summarization move. Notably, each of the examples above is expressed in terms of concepts that are specific to the relevant field, concepts which often came into being to allow these very summaries.
Even more importantly, a good summary highlights what you need for your application. This means the quality of a summary depends on what you want to make of it. Not only will you remove what you consider as noise, but you might simplify parts of the data that don't serve your need.
My favorite example there is the boiling point of water. You might think that it's 100°C, without any subtlety, but boiling is actually a complex and intricate processes with multiple stages. It can continue beyond 100°C when performed under specific conditions (removing trapped air bubbles which provide a starting point for boiling).
Yet for most day to day and even scientific usage, the summary that water boils at 100°C (at 1 bar) is the right level of summarization and simplification.
This is not the case if you are studying superheating, or if you are a cook caring about the different levels of boils (simmer vs full boil).
So let's not confuse the summary for the underlying truth of the matter. It's instead a tool meant for a specific goal, and we are free to update it for an alternative one (that still captures the data) when we need.
Reduction: Going Beyond Existing Settings
Say you know a great bakery close by. From experience, you can predict that the bread is good, the croissants are amazing, but the strawberry cakes are subpar. That's a summary you came with from years of going to this bakery.
Now, what happens to that prediction if the lead baker changes?
Unfortunately, your summary doesn't generalize cleanly. For you didn't model the underlying reason why the bread and cake and pastries were as they were. So it might be because of the lead baker's touch, in which case your predictive summary is now garbage; or it could be the recipes or the ingredients, in which case your prediction probably still holds.
So purely descriptive summaries make it hard to know how your predictions should change in new settings.[5]
This is the essence of the Lucas critique: according to Lucas, macroeconomics models (which are quite summarization heavy) predict outcomes for policies, but implementing these policies then change the factors which made the summary correct in the first place, leading to invalid prediction. Basically, by following the prediction, you end up changing the causes, and thus the result is different than the one predicted.[6]
The Reduction Move is how we address this problem: by reducing our current models to some deeper one that accounts for changes across settings and intervention, we can generalize our current predictions to new realms.
By far the most common kind of reduction is the causal one — it’s basically what reduction means for most people: finding underlying causal factors, about getting in more details, going down a level of abstraction.
This is obviously the case in many physics examples: statistical mechanics aims to reduce thermodynamics; general relativity aims to reduce classical mechanics; quantum mechanics aims to reduce a whole lot of phenomena across classical physics.[7]
My favorite example of reduction that I learned recently is the Mental Number Line from the field of numerical cognition. In order to explain a host of summaries about how people process numbers and do mental arithmetic (notably the facts that even for symbolic numbers, as you increase the size of numbers, you need to increase their relative distance to maintain similar performance in addition), the researchers built a model of a line with natural numbers, going from left to right, where as you move to the right, the successive numbers get closer and closer together. In addition, they add some form of noise when trying to retrieve the result of some operation: the "activation"will spill in a gaussian way around the number, which leads to error when the two numbers to add are too close on the line.
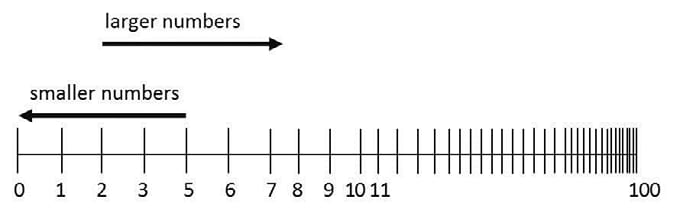
Taken together, this helps explain the need for increasing the relative difference to get same performance, and it even captures some spatial effects of number tasks (for example the SNARC effect).
Yet reductions don’t need to be causal. The alternative, despite being less known, abounds in physics: principles.
If you keep seeing the same pattern appear across summaries, you can posit that the patterns always holds, or more conservatively, that it holds in a large variety of settings, beyond your initial cases.
In physics, classical examples are the constant value of the speed of light (posited by Einstein in Special Relativity) and the various conservation laws (notably conservation of energy).[8]
These reductions do generalize, but in different ways to the causal ones: instead of integrating some underlying causal factors, they reveal constraints that transcend the initial summaries, and can be assumed in far more settings.
Lastly, before we leave reductions behind, it’s important to realize that they don’t explain literally everything in the original model — it's often fine to reduce just enough for our purpose.
In the bakery example, you could look for a fundamental model which explains everything in terms of the physics, chemistry, and biology of bread and complex psychology of genius; or you focus on what you care about (predicting what to order) based on a few high-level factors like the impact of the baker's skill, the recipes, the ingredients...
A classical example of this kind of early stopping in reduction is Darwin: he had no way of figuring out the actual mechanism of inheritance, but he could capture a lot of its functional role: so even if he conjectured some (incorrect) implementations, he mostly treated inheritance as a black box, with the success we know.[9]
Precomputation: Taming Fundamental Calculations
If successful, reduction eventually leads to deep and far reaching theories that apply in many contexts.[10]
Yet this ever widening of reach comes at a computational cost: you need to spend more and more effort in order to go from your fundamental model to the special case that interests you.
Chemistry is a great example: Dirac is known to have written that
The underlying physical laws necessary for the mathematical theory of a large part of physics and the whole of chemistry are thus completely known […]
But what is rarely quoted is the follow up:
[…] and the difficulty is only that the exact application of these laws leads to equations much too complicated to be soluble. It therefore becomes desirable that approximate practical methods of applying quantum mechanics should be developed, which can lead to an explanation of the main features of complex atomic systems without too much computation.
This means that even after we get as powerful reduction as quantum mechanics, there is still some need for compression — computational ones.
Molecular orbital theory provides a case in point.
Using quantum chemistry, pioneer physicists and chemists where able to compute the electron orbitals of basic atoms. But the wavefunction calculations very quickly became almost impossible and impractical as the atoms became bigger, and they seemed inaccessible for even the simple molecules.
Yet there is a simple abstraction (orbitals) built on top of this fundamental model, with different orbitals classified by their shapes and phases, and simple laws to combine them. It can then be easily taught to chemistry students and applied broadly, by caching out the computational burden of the fundamental computations from quantum mechanics.
Another example that I love is Richard Feynman's war work at Los Alamos: as analyzed by Peter Galison[11], a huge part of Feynman's job was to boil down the incredibly intricate computations of nuclear physics into small, modular, simple methods that could be used without context by less experts physicists, chemists, and engineers.
Similarly, Feynman's Nobel Prize-winning contribution to Quantum Electrodynamics, his eponymous diagrams, allowed physicists to compress and simplify the intractable equations of QED through precomputation.[12]
Conclusion
We saw three compression moves that help to improve predictive ability:
- Summarization lets you throw away most of the data to only keep the regularities you need.
- Reduction lets you generalize to new settings, either by finding an underlying causal model or by discovering general principles.
- Precomputation lets you shortcut the application of your fundamental model to new situations by caching the translation into a cognitive tool
Clearly, these are not the only compression moves available. As mentioned in the introduction, in historical sciences, the lack of data requires a lot of cross referencing to reverse engineering things like the sounds of an extinct language.
They're also not always as cleanly delineated as I made them look in this post. For example, the reformulations of Newtonian Mechanics into Lagrangian and Hamiltonian Mechanics were mostly about precomputation, but they introduced concepts such as the potential, which then led to a whole new reduction of classical physics, and physics as a whole.
Still, I expect that these 3 compression move play a huge part in the epistemological arsenal of theory and paradigm builders, and so are a worthwhile starting point.
- ^
See My Model of Epistemology for general discussion.
- ^
Notable exceptions are the historical sciences, where sparse data requires much more ingenuity and criss-crossing to extract all the evidence juice of it, rather than compression. See Rock, Bone, and Ruin by Adrian Currie for a great treatment of this case.
- ^
In this case, despite the name of “laws”, it’s important to understand that sound laws are really summaries of a specific historical sound change, or series of such, such as The Great Vowel Shift.
- ^
Donald Norman calls this the system image in The Design of Everyday Things, and Daniel Jackson extends it further to software under the name of "concepts" in The Essence of Software.
- ^
And if you ever wondered why the Law of Equal and Opposite Advice matters, it's basically a caveat built on this idea: most advice are proposed as summaries of actions and interventions that worked for some people, but without a deep enough model of the underlying factor to predict exactly in which settings it helps. So sometimes they’re the exact opposite of what you need.
- ^
As Eliezer Yudkowsky mentions multiple times, this is also a crux of the Foom debate: Robin Hanson argues for applying well-worn economic models to the post AGI/superintelligence world, but Yudkowsky answers that this doesn't make sense, because AGI/superintelligence significantly alters the underlying dynamics which make these economic models work.
- ^
I say aim because it’s quite debated whether any of these reduction succeed. See for example Physics and Chance by Lawrence Sklar for the question of reducing Thermodynamics to Statistical Mechanics.
- ^
Note that conservation laws can be rederived from symmetries through Noether’s theorem, but that’s a further reduction that is unifying the laws mostly after they were posited.
- ^
For a great treatment of the value of voluntarily stopping at some level of reduction, see Black Boxes by Marco J. Nathan.
- ^
I generally prefer to bring examples from a wider set of fields than just physics and chemistry, but the advanced requirements of precomputation (a global, successful, reductive theory) makes it much harder to find examples in other fields. I expect that active inference might have some interesting cases of precomputation, but I don't know enough about that field to incorporate it into this post.
- ^
In his great paper Feynman’s War.
- ^
This specific compression device worked out so well that it spread to many other branches of physics. See Drawing Theories Apart by David Kaiser for a history.
0 comments
Comments sorted by top scores.