Takeoff speeds presentation at Anthropic
post by Tom Davidson (tom-davidson-1) · 2024-06-04T22:46:35.448Z · LW · GW · 0 commentsContents
Summary:
Intro
Software improvements have been a significant fraction of recent AI progress
Efficiency improvements in pre-training algorithms are a significant driver of AI progress
Post-training enhancements are significant drivers of AI progress
Post-training enhancements can often be developed without significant computational experiments
AGI might significantly accelerate the pace of AI software progress
AI is beginning to accelerate AI progress.
AGI will enable abundant cognitive labour for AI R&D.
We don't know how abundant cognitive labour would affect the pace of AI progress
AGI might enable 10X faster software progress, which would be very dramatic
Bottlenecks might prevent AGI from significantly accelerating software progress
Diminishing returns to finding software improvements might slow down progress
Retraining AI models from scratch will slow down the pace of progress
Running computationally expensive ML experiments may be a significant bottleneck to rapid software progress
If AGI makes software progress much faster, than would be very risky
Extremely dangerous capabilities might emerge rapidly
Alignment solutions might break down rapidly
It may be difficult to coordinate to slow down, if that is needed
Labs should measure for early warning signs of AI accelerating the pace of AI progress
Warning sign #1: AI doubles the pace of software progress
Warning sign #2: AI completes wide-ranging and difficult AI R&D tasks
Labs should put protective measures in place by the time they observe these warning signs
None
No comments
This is a lightly edited transcript of a presentation about the risks of a fast takeoff that I (Tom Davidson) gave at Anthropic in September 2023. See also the video recording, or the slides.
None of the content necessarily reflects the views of Anthropic or anyone who works there.
Summary:
- Software progress – improvements in pre-training algorithms, data quality, prompting strategies, tooling, scaffolding, and all other sources of AI progress other than compute – has been a major driver of AI progress in recent years. I guess it’s driven about half of total progress in the last 5 years.
- When we have “AGI” (=AI that could fully automate AI R&D), the pace of software progress might increase dramatically (e.g. by a factor of ten).
- Bottlenecks might prevent this – e.g. diminishing returns to finding software innovations, retraining new AI models from scratch, or computationally expensive experiments for finding better algorithms. But no bottleneck is decisive, and there’s a real possibility that there is a period of dramatically faster capabilities progress despite all of the bottlenecks.
- This period of accelerated progress might happen just when new extremely dangerous capabilities are emerging and previously-effective alignment techniques stop working.
- A period of accelerated progress like this could significantly exacerbate risks from misuse, societal disruption, concentration of power, and loss of control.
- To reduce these risks, labs should monitor for early warning signs of AI accelerating AI progress. In particular they can: track the pace of software progress to see if it's accelerating; run evals of whether AI systems can autonomously complete challenging AI R&D tasks; and measure the productivity gains to employees who use AI systems in their work via surveys and RCTs.
- Labs should implement protective measures by the time these warning signs occur, including external oversight and info security.
Intro
Hi everyone, really great to be here. My name’s Tom Davidson. I work at Open Philanthropy as a Senior Research Analyst and a lot of my work over the last couple of years has been around AI take-off speeds and the possibility that AI systems themselves could accelerate AI capabilities progress. In this talk I’m going to talk a little bit about that research, and then also about some steps that I think labs could take to reduce the risks caused by AI accelerating AI progress.

Ok, so here is the brief plan. I'm going to quickly go through some recent drivers of AI progress, which will set the scene to discuss how much AI progress might accelerate when we get AGI. Then the bulk of the talk will be focused on what risks there might be if AGI does significantly accelerate AI progress - which I think is a real possibility - and how labs can reduce those risks.

Software improvements have been a significant fraction of recent AI progress
So drivers of progress.
It’s probably very familiar to many people that the compute used to train the most powerful AI models has increased very quickly over recent years. According to Epoch’s accounting, about 4X increase per year.
Efficiency improvements in pre-training algorithms are a significant driver of AI progress
What I want to highlight from this slide is that algorithmic efficiency improvements - improved algorithms that allow you to train equally capable models with less compute than before - have also played a kind of comparably important role. According to Epoch’s accounting, these algorithmic efficiency improvements account for more than half of the gains from compute. That's going to be important later because when we’re talking about how much the pace of progress might accelerate, today’s fast algorithmic progress will make it more plausible that we could get scarily fast amounts of algorithmic progress once we have AGI.
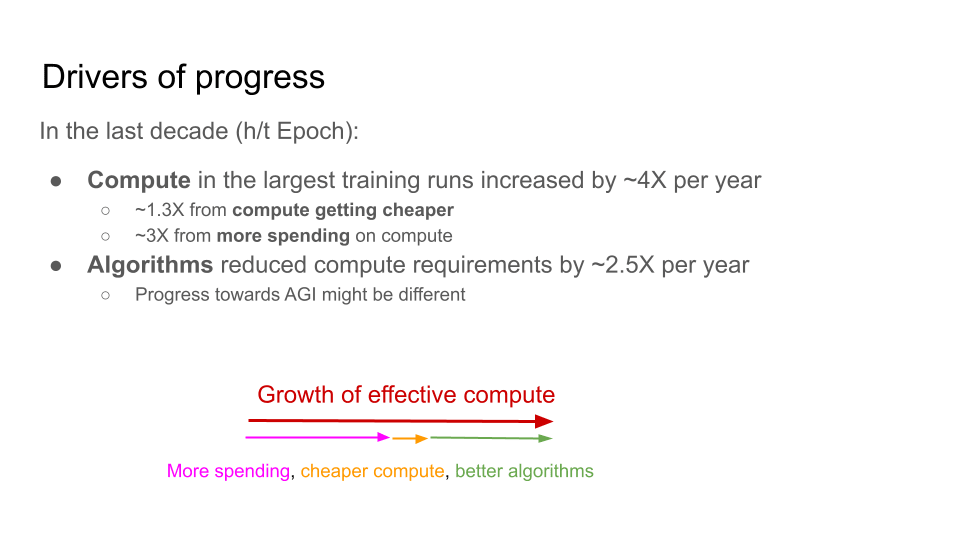
Post-training enhancements are significant drivers of AI progress
What about other drivers of progress? Beyond compute and pre-training algorithms, we've got fine tuning, prompting, tool-use, scaffolding, and various runtime efficiency improvements that allow you to run pretty much the same system with pretty much the same performance but for less compute. These are important drivers of progress.
Some work that I've been involved with shows that these individual improvements in prompting or fine tuning or scaffolding can often improve performance in a certain domain by more than increasing amount of training compute by a factor of 5, sometimes by more than a factor of 20. So that's just reinforcing that these kinds of drivers of progress on this slide can be pretty significant.
If the post-training software improvements on this slide are, taken together, as important as the improvements in pre-training algorithms discussed on the last slide, then total software improvements (in pre-training and post-training) have been responsible for slightly more progress overall than compute increases.
Post-training enhancements can often be developed without significant computational experiments
The thing I want to highlight about these types of improvements is that you do not need to do large computational experiments to develop them. For many of them, the main input to development is just smart researchers thinking about new tips and tricks to get more out of existing systems, and so these sources of progress could potentially accelerate quite a lot if we had abundant cognitive labour from AGI, even if we're not simultaneously massively increasing the amount of compute that we have to do computational experiments. So these “post training enhancements” are going to play an important role in the possibility of AGI driving scarily fast AI progress.

Ok, those are the recent drivers of progress. That sets us up to discuss how much AGI might accelerate AI progress.

AGI might significantly accelerate the pace of AI software progress
AI is beginning to accelerate AI progress.
This is already beginning to happen. It's in its pretty early stages, but we are having frontier AI models power things like CoPilot, Constitutional AI, chip design and other parts of the AI workflow. We are already beginning to get some minor acceleration from those AI systems and my expectation is that future AI systems will accelerate things by a greater amount.
In the long run, we can imagine an endpoint, which I’m calling “AGI”, which in this talk I am using to refer to AI that can fully automate all of the cognitive work that researchers do at organisations like Anthropic and other AI Labs.
AGI will enable abundant cognitive labour for AI R&D.
The main thing that changes once we have AGI in terms of the AI development process is that there's probably going to be an abundant amount of cognitive labour. A quick argument you can use to support this point as you can make estimates about the amount of compute that it might take to train AGI, how much compute it might take to run it for one forward pass, and how long (in months) the training run might take. Then you can deduce how many forward passes per second you could run just using the computer chips that you use for training.
I've got a toy example calculation on the screen, where the conclusion is you can get 40 million forward passes per second just by using the training compute to run copies of the system. Now that's a very large number of forward passes per second, compared to the mere hundreds of people that work at AI labs advancing their state of the art AI systems.
A caveat here is that when we first develop AGI, it's possible that you'll have to run it for loads and loads of forward passes in order to get work that's as good as current human researchers can produce quickly, for example maybe it has to think through step by step for a thousand forward passes before it gets output that’s as good as just one second of human work. I do think that's a possibility, but there are two replies. Firstly, even with a 1000X discount, we're still talking about a pretty dramatic increase in cognitive labour. Secondly, at some point we will have AI systems that do a few forward passes and match the output of a human expert thinking for a second or so. Intuitively, these are AI systems that are about “as good” at AI research as human experts. When we get to that point, then this argument about abundant cognitive labour will apply. So while it’s possible that the argument doesn’t apply when we first get AI that can fully automate AI R&D, it will apply by the time we have AI systems that match human AI experts. At that point - which is intuitively a point where AI is kind of as smart as AI researchers - things look pretty crazy in terms of the amount of cognitive labour that frontier AI labs will be able to throw at improving AI systems if they choose to.

We don't know how abundant cognitive labour would affect the pace of AI progress
What would be the effect of this abundant cognitive labour? I really want to highlight that I don't think that anyone knows all the answers here, and I think the right attitude to take is one of uncertainty, so I want to present two contrasting perspectives. One is a quite intuitive, flat-footed perspective which is: if you've got more inputs to the research process (way more cognitive labour), then you get more outputs of the research process (more new algorithms discovered, more innovations discovered), and there'll be a big acceleration of progress. A toy calculation on the slide suggests that if you increase the amount of cognitive labour by just 10x then you could significantly increase the pace of AI progress.
But a different perspective which you will hear a lot from economists (and I've chatted to lots of economist over the last few years) is that bottlenecks from something that isn't cognitive labour will arise, and you won't get as big an acceleration as you might naively think when you just imagine those millions of automated AI researchers driving forward AI capabilities’ progress. One bottleneck that I'll discuss later is computational experiments. I do think that that's going to be an important bottleneck to some extent and then there's a question of how much you can use abundant cognitive labour to get around that. Other bottlenecks could be humans just wanting to stay in the loop in some capacity: if humans are still approving certain AI decisions, e.g. relating to ethics or safety or legality, then that could bottleneck AI progress even if there's abundant AI labour thinking 100x human speed coming up with the ideas. A big hope of mine is that we're going to want to go safely and cautiously (and I'll discuss that later in the talk), and that could be a very sensible bottleneck to progress. An extreme version of this bottleneck view would say that no matter how much cognitive labour you had, you can't get more than a 2X or 3X increase in the pace of progress.
What's going to be unusual about this particular scenario, is that the amount of cognitive labour is going up very very rapidly but other inputs to progress - like the amount of compute for experiments might initially not be rising nearly as rapidly. So, one of multiple inputs has suddenly gone through the roof. Without observing previous instances where this has happened, it's pretty hard to confidently predict exactly what will happen.

I think we don't know what perspective is right because we haven't had many examples where a huge amount of cognitive labour has been dumped on a scientific field and other inputs to progress have remained constant and we've accurately measured how much overall progress in that field accelerates. (Edit: though this comment [EA(p) · GW(p)] suggests some interesting examples.)
AGI might enable 10X faster software progress, which would be very dramatic
But I do think that there is a real possibility of a very scary scenario. That is a scenario where software progress is 10X faster than it is today. By software progress, I don't just mean the algorithmic efficiency improvements that I mentioned earlier, but also the post-training enhancements (fine tuning techniques, better prompting, scaffolding, tool-use, flash attention, better data) - all sources of progress other than using more compute. I think there is a possibility that once we have AGI, that software progress becomes 10X faster than it is today, enabling very rapid progress even without additional compute.
What would that mean? One thing it would mean is that the efficiency of our training algorithms could improve by four orders of magnitude in just one year. Epoch finds that you're getting 0.4 orders of magnitude improvement per year over the last decade, so if we got ten years of progress squeezed into one year, that's going to be four orders of magnitude improvement.
That would be a pretty scary thing to happen (and I'll talk about why it's scary a bit more later) in just one year. It would be like going from GPT-2 level system to an almost GPT-4 level system in just one year – that’s a massive jump in capabilities. And it’s scarier for the fact that the initial system is able to fully automate all of the work done by the smartest people at leading AI Labs, and so the final system will be much more capable than that, much more capable than the smartest humans. And all of this happening just from software increases, without needing to access additional compute resources. I think that this would be a pretty scary situation for the world to find itself in, with multiple labs potentially able to make that kind of progress in a year.
As well as improving the efficiency of training algorithms, they'll be possible to improve runtime efficiency (so running the same quality of AI, but running more copies, by using less runtime compute per copy). It's worth noting that this is going to be a lot more of a scary thing to happen once we have AGI than it is today. Like if you managed to run Claude 2 10X faster, that's kind of cool, and you get more copies and can charge less on the API. But those copies can only do a fairly limited number of tasks and so the actual overall effect is fairly minor. If we have AGI and you get a 10X runtime improvement, that's like increasing the size of the entire workforce by a factor of ten. That’s like going from 30 million workers to 300 million, like going from a workforce the size of a small European country to the workforce the size of the US. It represents a really significant gain in power just from a runtime efficiency improvement.
10X faster software progress would not only mean the two things I've discussed (GPT-2 -> GPT-4 and rapid gains in runtime efficiency) but also ten years worth of gains from all the other sources of non-compute progress like scaffolding, better fine-tuning, prompting and tool-use. I think this would be a pretty extreme scenario and I'll discuss a later exactly why I think it's so scary.

Bottlenecks might prevent AGI from significantly accelerating software progress
Before I do that though, I do want to cover a few very reasonable objections to whether this is really going to happen. For each of these objections, I think the objection may well apply but the objection doesn't make me confident in saying that this scenario could not happen. My reaction is typically “yeah, maybe the objection applies but also there's plausibly ways around that bottleneck” and I think we really should be very open to this 10X faster software progress in spite of all these objections.

Diminishing returns to finding software improvements might slow down progress
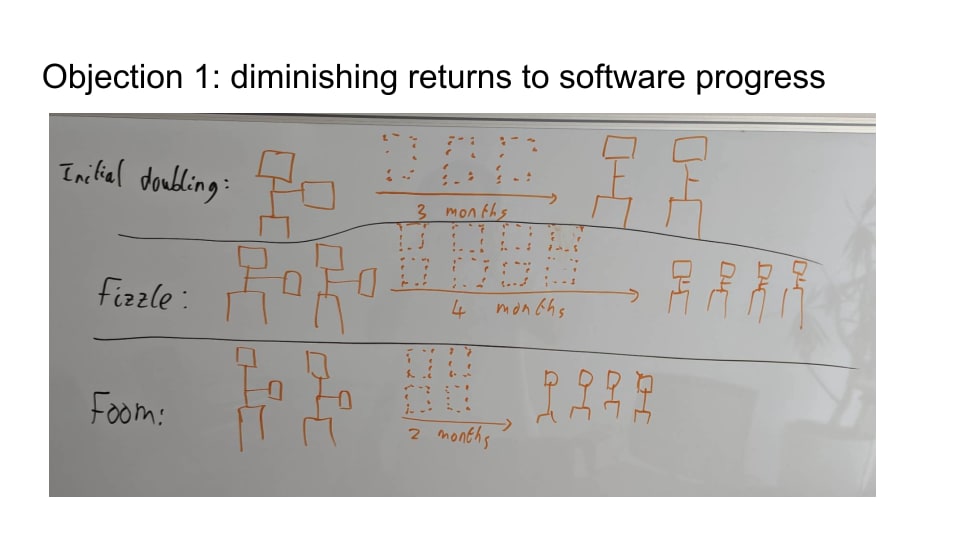
The first objection is diminishing returns. That's the idea that if we're keeping the amount of compute fixed (that the lab has access to), then each additional software improvement is going to get harder and harder to find over time. That means that progress is going to slow down. So rather than maintaining a 10X speed up, you maybe get a temporary 10X speed up but then you quickly run into really steep diminishing returns on finding additional improvements and the pace of progress returns back to normal.
I just want to highlight that this is an empirical question. So to demonstrate that I put a toy example on the screen. Initially, in the top left, I have a little picture of one AGI worker - just to simplify things, we're pretending there's just one AGI at this point. The one AGI worker is writing research papers, you can see it's got a little notepad that it’s writing on, and it takes it three months to write three research papers. And once it's written those three research papers, it's able to double the efficiency in which it can run its own algorithm, so it's only doing things like quantization that increase runtime efficiency (for this toy example). So the AGI works for three months, writes those three research papers and at the end of that there's now two AGIs, you can run twice as many on the same hardware.
Now the meaning of diminishing returns is that doubling the efficiency of those algorithms again is going to take more effort than it took the first time. Rather than taking just another three research papers, it’s going to take more than three papers.
I want to point out that even if that's the case, progress doesn’t necessarily slow down. In fact, you can get accelerating progress, what I’m calling “Foom”, even if there’s diminishing returns. See the scenario at the bottom. What we have in the bottom is that to double algorithms the second time it takes four research papers rather than three. But because you now have twice as many AGIs working on doing this research, they actually are able to get a second efficiency doubling in just two months rather than in the original three months. So actually the rate of algorithmic progress in the Foom scenario is accelerating over time because even though there are diminishing returns to software programs, they're not diminishing that quickly. The second doubling of algorithmic progress takes more effort but it doesn't take more than twice as much effort as the first, and so the diminishing returns are overcome by the fact you now have twice as many AGIs doing the research. So this Foom scenario is possible, and compatible with diminishing returns.
Also possible is the Fizzle scenario, which is where I'm the second doubling of algorithmic efficiency takes eight research papers, more than twice as much as the original three papers. In that case progress does slow over time. I want to upfront highlight that there's an empirical question here of whether diminishing returns are going to block a very scary scenario like this. To block Foom, we need the diminishing returns to be steep enough that each doubling of efficiency takes more than twice as much effort as the previous one.
Importantly, even if there is a Fizzle, we could still have a temporary period of 10X faster progress, which is still pretty scary.
This question of Fizzle or Foom in the last slide is not just a matter of conjecture, you can look at empirical evidence. You can say okay “How much effort was needed to double the efficiency of ImageNet algorithms between 2012 and 2014?” and then “How much more effort was needed to double them a second time from 2014 to 2016?”. If the 2014-16 doubling took more than twice as much effort as the 2012-14 doubling, that suggests Fizzle; otherwise it suggests Foom. Epoch has recently been digging into this evidence and it looks like it's pretty borderline. It looks like, at least with ImageNet, it took slightly less than double the effort to double the algorithmic efficiency the second time compared with the first time. I.e. it looked like from their analysis like we are very slightly in the Foom world.
There's obviously loads of massive question marks with this kind of empirical analysis. This is about ImageNet in particular, but we're concerned with the efficiency of AGI algorithms more generally, so the result could easily not translate over. And the data is super noisy. But I think it is worth noting that the empirical evidence that we do have is unclear between whether we're in the Fizzle world of the Foom world and so I don't think we should be confident that diminishing returns to software progress is going to prevent the scary scenario that I outlined a few slides ago.

Retraining AI models from scratch will slow down the pace of progress
A second objection is that you’re going to have to retrain your systems from scratch to incorporate new algorithmic ideas and that's going to take many many months. So you're never going to get a really large amount of capabilities improvement in just a year or in just a few months as you’ll be sitting around waiting on these long training runs. I think that this will slow down progress a lot, if we stay within the current paradigm. I think labs will occasionally retrain their systems from scratch after they get AGI and that that will take time, but I don't think this is a decisive objection to the scenario I laid out.
Firstly, if you're able to run your AGIs and generate say 4 orders of magnitude of software improvements (10,000X), then rather than retraining for a full three months and getting 4 OOMs of improvement, you could advance more quickly by just retraining for one month and getting just 3.5 OOMs of improvement (3,333X). In other words you lose 3X effective compute but complete training 3X faster. If you are in a place where you are very rapidly generating orders of magnitude of algorithmic improvements, then you can then use those improvements to get around this training time delay.
Secondly, many of the sources of software improvement that we're discussing here do not require retraining from scratch: fine-tuning often done on less than 1% of the initial training compute; things like scaffolding and prompting often don't require retraining at all; similarly with things like quantization, you do not have to treat retrain the model from scratch. So getting around this bottleneck could look like exploiting the sources of progress that don't require retraining from scratch as much as is possible, and then using all of those improvements to to make loads of software progress and loads of algorithmic progress so that then you can reduce your training time to a month or less. So that’s why I don’t find the second objection decisive.

Running computationally expensive ML experiments may be a significant bottleneck to rapid software progress
A third objection, which in my opinion is the strongest objection but is still not decisive by any means, is that a large part of software progress requires large computational experiments which can take weeks or months. ML is experimental. Abundant cognitive labour won’t help is you’re waiting on the results of experiments that take many weeks.
Again, I think there's like multiple plausible routes around this bottleneck and so I'm not at all confident - and I don't think anyone should be confident - that in a world with millions of AGIs looking for ways around these bottlenecks, that there won't be one.
Let me go through some potential ways that abundant cognitive labour could get around this computational bottleneck:
- Subtle bugs. Firstly, as you probably know, not every experiment that AI Labs run is perfectly planned, sometimes you realise there's a subtle bug in the code, sometimes you realise there this thing happened which meant the experiment wasn't really investigating the thing we wanted to investigate and we probably could have realised that in advance if only we’d really thought through the dynamics of the training run more.
- Stop experiments early. Secondly, experiments are sometimes run for longer than they would absolutely have to be run if there was someone constantly babysitting the experiment and looking at the interim results and terminating it as soon as they had the information that they were looking for.
- Carefully analyse experimental results. Thirdly, you could get more from each experiment if you really spend weeks and months really analysing the experimental results and incorporating it with all the other knowledge of all the other experiments at Anthropic.
- Prioritse experiments holistically. Fourth, you might get big gains in efficiency, if rather than each team planning their own experiments you had a more holistic optimization of what the biggest experimental needs and uncertainties that the lab as a whole is facing; you designed a portfolio of experiments which, collectively, optimally target those uncertainties.
- Design better experiments. Fifth, I think there's just a lot of room, if you had truly abundant amounts of cognitive labour, to make the way that these experiments are designed and executed a lot more efficient. Compare the best designed experiment you’ve ever heard of to the median experiment; cognitive labour might allow every experiment to be as good as the former.
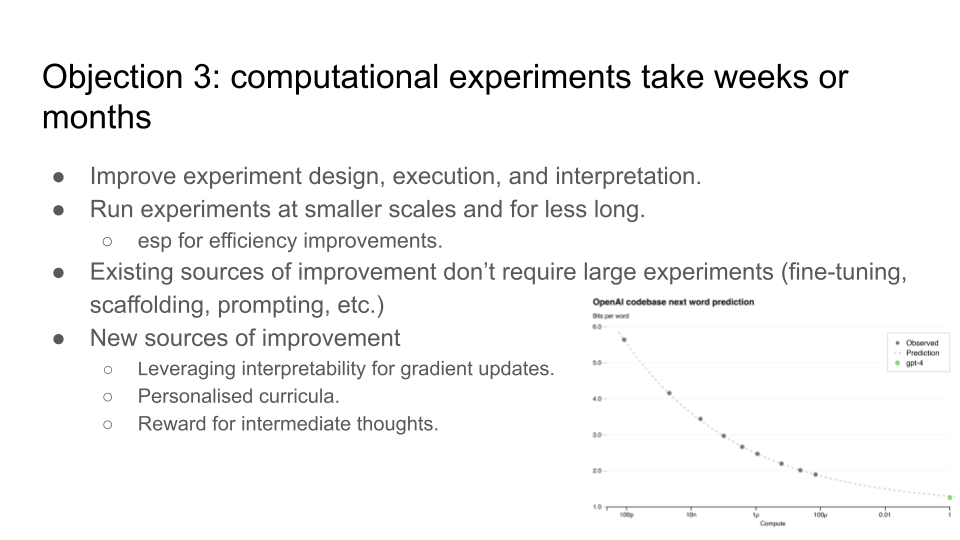
- Run experiments at smaller scales. Sixth, you could run huge numbers of experiments at smaller scales. On the slide, the graph shows that OpenAI was able to predict GPT’s performance from experiments using four orders of magnitude less compute. So running huge numbers of experiments at smaller scales and developing a new science to extrapolate the results to large scales.
- Use existing source of progress that don't require computational experiments. Seventh, many sources of software improvement do not require large experiments – scaffolding, prompting, lower-precision, LoRA fine-tuning, etc..
- Discover new sources of AI progress. Lastly, in a world with abundant cognitive labour, we might expect new sources of AI progress to emerge that make use of that abundant cognitive labour. Currently, cognitive labour is very expensive, so we haven't been exploring ways to improve AI that really leverage abundant cognitive labour because it isn't abundant. But in a world where cognitive labour is abundant, you might imagine that new avenues for improving AI arise that do really take advantage of what is now a plentiful resource. I've just got some very rough ideas jotted down on the slide.
So I think it's plausible that 10X faster software progress is possible despite the computational experiments bottleneck.
So overall, what I’ve argued so far in this talk is that recent AI progress has been driven by compute but also significantly driven by algorithmic efficiency improvements and other types of software improvement like scaffolding and prompting. I've argued that because of that it is possible - by no means guaranteed but a very real possibility - that progress will accelerate dramatically when we have AGI. We could get maybe ten times faster software progress than we have today. The rest of the talk is going to be about the risks that that could pose and how labs like Anthropic can reduce those risks.
If AGI makes software progress much faster, than would be very risky
I think that we should proceed very cautiously and plausibly very slowly around when we're developing AGI (= AI that can fully automate AI R&D).
There’s a dangerous capabilities angle and alignment angle.
Extremely dangerous capabilities might emerge rapidly
On the dangerous capability side, it's hard to predict the specific dangerous capabilities that new models will have. There's this thing about emerging capabilities where we're pre-training on next-word prediction but then that gives rise to various downstream capabilities in a way that it's hard to systematically test for and comprehensively predict. In general, more capable models have the potential to be more dangerous: if I'm trying to plan a bio attack or I'm trying to commit wide-spread scamming I would much rather have Claude 2 to help me do that than Claude 1. I expect that trend to continue.
I expect that as we develop increasingly capable models, as we develop AGI and then as we surpass AGI, I expect systems to have dangerous capabilities that are increasingly extreme. I think when we're talking about superhuman AI systems the dangerous capabilities could be very extreme indeed. They could be things like ability to coordinate with other AI systems in ways that humans wouldn't have anticipated, to be super-persuaders with unseen manipulation capabilities, to design entirely new weapons that human designers wouldn't be able to design, and probably lots of other scary things that we haven't thought of. My claim is around the time we're developing AGI, a lot of dangerous capabilities - extremely dangerous ones - will be cropping up, we're not sure exactly what they're going to be. That’s the dangerous capabilities side of the equation.
Alignment solutions might break down rapidly
On the alignment side, we can't reliably control today’s systems (e.g. jailbreaks, bias) and we don't have a scalable alignment system solution. In addition, there are theoretical reasons to expect that new and significant alignment challenges will emerge just as AI systems become more capable than today's systems and so just around the time we're developing AGI (e.g. humans can no longer understand and effectively oversee the actions of AI systems).
In other words, the time when this massive acceleration in the pace of capabilities progress might occur is exactly the time that some extremely dangerous capabilities might be emerging, and exactly the time that the alignment solutions which seem to be working might begin to break down. This would be a very scary time for labs to be racing ahead with capabilities progress. It's very imaginable that if they do that, that they end up with AI systems with extremely dangerous capabilities that are not aligned.

It may be difficult to coordinate to slow down, if that is needed
This dynamic that I've been discussing - the possibility of significant acceleration in the pace of capabilities progress - could make it really hard to proceed cautiously at this crucial time. There's a few ways that this could play out.
There could be a lab that is irresponsible, it says “Yeah, we're just going to do this really fast progress, we're excited about it”, and they might go ahead despite not being adequately safe. Or a lab might worry that some other lab is could massively accelerate their software progress and they might think “Well that other lab is less responsible than us, so we’ve got to plough ahead because we're not sure if they're going to do it and we can’t let them get their first”.
And one thing that makes this dynamic particularly scary is that software progress is very hard to observe. So right now Anthropic can see roughly how much compute OpenAI is expecting to get at what times, and so it can roughly know how OpenAI’s capabilities are going to be changing over time, and it’s going to use that to inform its own strategy. If we do get to this scenario where very, very rapid software progress is possible, that dynamic could fall apart entirely. Anthropic might not know how rapid OpenAI’s software progress is; they might suspect that maybe OpenAI is about to be able to froom just through software improvements. That could be enough to make Anthropic less cautious. So I think there's going to be a big coordination problem here as well.
A third possibility is that a bad actor steals the weights and then they use that AI to massively accelerate their own AI progress. And again, if there's just one actor that has AI that can massively accelerate AI research and has bad infosecurity, then all the other actors could be worried that this lab is going to get hacked and then someone else that is irresponsible is going to do this scarily fast AI progress.
In general, this dynamic can be hugely destabilising if responsible actors are trying to go slowly: it's a combination of very fast progress, hard to observe progress (compared to today), and at a time when is it particularly important to go safely and cautiously (due to new alignment challenges and extremely dangerous capabilities emerging).

Here are some types of threat models, very briefly sketched.
- Misuse. You could get a bad actor that develops super-human AI and then creates some kind of dangerous bio weapon.
- Loss of control. You could get an irresponsible lab that hasn't solved scalable alignment, plowing ahead anyway, developing a super intelligence system which they can't control which then leads to a catastrophe.
- Extreme concentration of power. You could have a lab that’s really good at safety, and they actually develop aligned super-intelligence, and they end up with a god-like AI that they can use to do anything they want and they've got a decisive strategic advantage over the rest of the world without and are not looping in other important stakeholders. I think that would be wrong. I don't think one private actor has legitimacy to do something as huge and consequential as develop super intelligence and put themselves in the position to, for example, do a coup in a large country if they chose to. I think that that would be unethical behaviour and labs should be srtongly committing not to do that kind of thing. I think that's worth highlighting because even for people that are not worried about alignment, this third bullet point provides them with a strong argument to say: we need you to be taking precautions to show the rest of the world that you're not going to suddenly get massively fast AI progress.
- Societal disruption. Another possibility is that AI progress is just too fast for broader society. Like even if it's controlled and even if there's no problematic power dynamics, it may just be that if you suddenly introduce superintelligence systems into society then that is just very destabilising; now everyone has access to an AI that can super-persuade other humans and we haven't got institutions to deal with that. Maybe the way the world needs to navigate this transition is by going much more slowly than is technologically possible. A general theme here is that I don't think that individual private actors should be making the judgement call about whether to do this massive global transition to superintelligence in a year versus in ten years, I think this is a conversation that the whole world deserves to be a part of.

Labs should measure for early warning signs of AI accelerating the pace of AI progress
If this scenario (with the potential for very fast AI software progress) happens, there are potentially many different risks. How can labs reduce them?

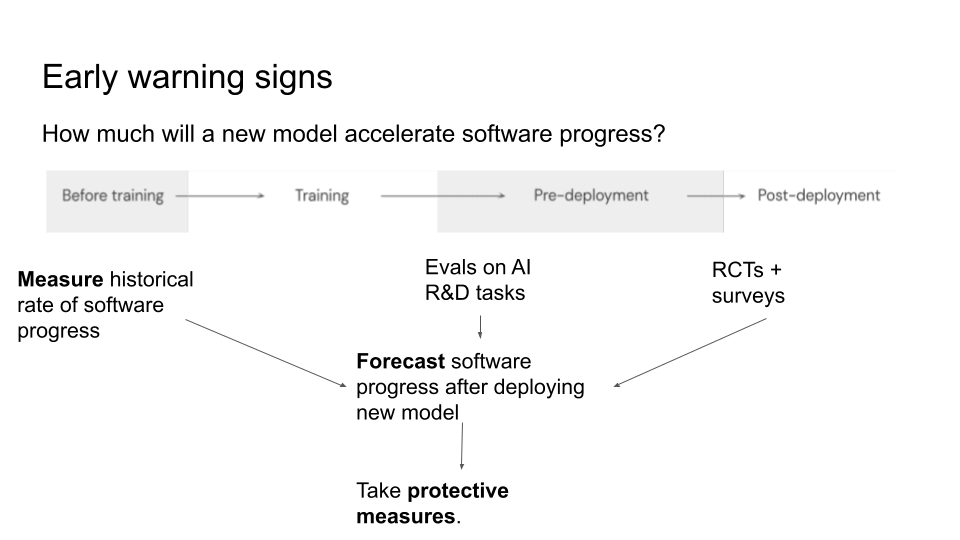
How can labs predict the amount of acceleration that they might get from future AI systems? On the slide we've got the lifecycle of training: before training, during training, after training but before deployment, and then during deployment. There are different methods labs can use to predict this risk during each stage.
Measure the pace of software progress. Before you even train a new system, you can be, in an ongoing way, measuring your pace of software progress: how much more efficient are your training algorithms becoming each year; how much are prompting and scaffolding techniques improving your performance on a range of downstream benchmarks, including agentic benchmarks where AI systems take long sequences of actions. You can use that historical measurement of software progress to forecast how fast software progress will be after deploying this new model. Maybe you find that software progress is getting a little bit faster each time you deploy a new model and then you can use that to roughly predict that after this next model is deployed it’s going to get faster still, maybe by roughly the same amount.
Do capability evaluations on hard AI R&D tasks. Once you've done your training, you can do evals on example AI R&D tasks. You can give an AI agent a suite of typical tasks that AI researchers do at Anthropic and you can see how well it does at those tasks. And you can use that as another way to predict whether this AI could significantly accelerate AI progress. If the AI system is aceing all the R&D tasks (but the previous systems did very badly), that gives you a strong indicator that this new AI system (if you deploy it widely throughout your organisation) might massively accelerate your AI capabilities progress.
Measure productivity gains to lab employees who use new AI systems. As you start to deploy your new system, maybe only to a small number of people at first internally, and then to the full organisation if it's safe, you can do RCTs and surveys of employees who are using the new AI system to say how much it is improving productivity.
Those are the basic tools you can use to predict AI acceleration. All these three things (measuring the rate of software progress, evals on AI R&D tasks, RCTs+surveys of employees using the new systems) feed into forecasting the pace of software progress after widely deploying a new model.
I have a proposal about exactly what early warning signs labs should use to decide “Okay, we need to pause if we haven’t got our protective measures in order”. I propose stopping if you see one of two early warning signs.
Warning sign #1: AI doubles the pace of software progress
The first is that you're observing from your ongoing software measurements that AI has already doubled the pace of software progress. More specifically that in less than 18 months, you get three years worth of software progress at the rate of 2020-2023. You can simply just measure the pace of software progress to get this. RCTs and surveys can then provide an additional guarantee that this increasing progress is not just a random blip, it's actually the systematic result of AI systems increasing people's productivity.
Warning sign #2: AI completes wide-ranging and difficult AI R&D tasks
This first warning sign is going to give us an adequate warning in worlds where there is a gradual acceleration of AI progress - which is my basic expectation. But there is a chance that AI acceleration happens quite suddenly, that a new model can do a wide range of R&D tasks and then you go from very little acceleration to a scary amount of acceleration. That's what the second warning sign is meant to catch. The second warning sign is that your AI systems can autonomously perform a wide range of difficult AI R&D tasks. These tasks are designed to resemble real-world AI R&D as closely as possible, so that AI completing them is good evidence it might be able to automate large amounts of AI R&D work.
My proposal is that if we see either these two warning signs, then labs should pause unless they have certain protective measures in place. If there is ambiguity even after seeing one of these warning signs, I propose deploying the new model to a very small fraction of employees and doing surveys and RCTs on its productivity effects.

Labs should put protective measures in place by the time they observe these warning signs
So those are the warning signs I think labs should use to detect this risk in advance. By the time the lab observes these warning signs, there are several protective measures I think they should have in place.
External oversight. The first key protective measure is external oversight. I've talked about how destabilising this situation could be and I think it's really important that all labs that are approaching this situation have to get sign-off on very high stakes decisions from a third party that is globally highly-regarded, responsible and making decisions in the public interest. That would mean that Anthropic is no longer worried that OpenAI is about to surge ahead because they know that OpenAI has to get sign-off from a responsible US government agency that is specifically looking for whether they're going to be advancing their AI capabilities dangerously quickly.
Info-security. Secondly, you need infosecurity that is robust to state actors. If you don't have that, then a state actor could steal your AI and then advance recklessly quickly. If there’s ever a need to pause or significantly slow, that will be much harder if a rogue state has stolen the weights an AI that can significantly accelerate the pace of capabilities advancement.
Alignment, boxing and internal monitoring. Thirdly, protections against AI poisoning the development process. A big worry with AI accelerating AI capabilities progress is that AI systems are actually slightly misaligned and they purposely poison the AI development process to ensure that subsequent generations are also misaligned. That way you can end up with superintelligent misaligned AI. So I think really good alignment techniques, boxing techniques (e.g. not giving your AI access to the internet, only allowing it to execute code in a sandbox) and internal monitoring (e.g. having a human check the AI’s output for malicious actions) that together guarantees that your AI is not able to poison that development process is required.
Prioritise reducing risks from AI. Fourthly, a commitment to use abundant AI labour to reduce AI risk. I think a big factor on how well this whole AI superintelligence dynamic goes is to what extent the leading actors use their abundant cognitive labour to reduce risks on the one hand versus advance their own capabilities on the other hand. I think some kind of commitment to prioritising reducing risks rather than increasing your own capabilities is important as a signal to other labs that you're being responsible.
Measure the pace of software progress. Fifth is better measurement of the pace of ongoing acceleration of AI progress so we can better anticipate the upcoming risks from AI acceleration that lie ahead. At the moment I think labs are doing a little bit of measurement but not nearly enough.
AI development speed limits. The last protective measure is AI development speed limits. I don't have a strong view on what these speed limits should be, but I believe that labs as AI acceleration becomes plausible, labs should include in their RSP an explicit discussion of how quickly they could advance AI capabilities while still doing so safely, with their current protective measures and processes for detecting emerging risks. This speed limit can increase as the lab’s processes for identifying and mitigating risks improve. But with their current governance set-ups and risk mitigation processes, I don’t think any lab is ready to handle 10X progress. My proposal is that labs explicitly state how fast they believe they can safely go with their current practices, and open themselves up for critique.

To sum up, what should labs be doing today? Firstly, I think labs should just explicitly acknowledge that this is a risk: that if AI systems can significantly accelerate AI progress then that could be really dangerous. Secondly, they should be monitoring for the two early warning signs that I discussed earlier (measuring the pace of ongoing software progress and building an eval for whether AI can autonomously perform a wide range of AI R&D tasks). Thirdly, they should prepare the protective measures (that I discussed on the last slide) so that when they do see either of those early warning signs, they can continue advancing safely. Lastly, I think that labs should commit to pausing if they see these warning signs before they have the protective measures in place. These four asks are summarised in this document.


0 comments
Comments sorted by top scores.