CIRL Corrigibility is Fragile
post by Rachel Freedman (rachelAF), AdamGleave · 2022-12-21T01:40:50.232Z · LW · GW · 8 commentsContents
Setup Assumptions Assumption 1: Game Lasts One Iteration Assumption 2: H is Rational Assumption 3: Feedback is Free Implications for Safety Research None 8 comments
Tl;dr: An optimal CIRL agent is corrigible under a certain problem formulation and given certain assumptions. By examining three key assumptions—that the game is played only once, that the human is rational, and that human feedback is free—we demonstrate how minor changes can lead to incorrigible CIRL agents. This suggests that corrigibility is highly sensitive to the underlying assumptions, and we should be wary of assuming that formal corrigibility results will transfer to real-world systems. However, our results do gesture at a class of near-corrigible behavior that may be protective against the most catastrophic outcomes. It may make more sense to consider corrigibility as a continuum rather than a binary. We call for further research on defining "loose" or "approximate" corrigibility and understanding its impact on safety.
Setup
First let’s define terms. Cooperative Inverse Reinforcement Learning (CIRL) [AF · GW] is a class of two-player game formalized in Dylan Hadfield-Menell's 2017 paper. CIRL allows us to study how an AI agent can learn what a human wants by observing and interacting with them.
In a CIRL game, there are two players, a human (H) and an AI (R). H and R share a utility function, but only H knows what it is, so R must learn how to optimize it by observing and interacting with H. This is analogous to the alignment problem – R must learn how to act in a way that aligns with H’s utility function, but doesn’t have direct access to it. An AI that is good at the CIRL game will try to learn what the human values and help them to achieve it. (See definition 1 in the paper linked above for a formal definition, and see this Rohin Shah's 2020 paper for qualitative results.)
(Terminology note: Recent work has renamed “CIRL” to “assistance games” to avoid a terminology collision with “cooperative” in game theory. We’ll stick to “CIRL” in this post because there’s a history of using that term on this forum, but research papers may refer to assistance games.)
We’ll use the corrigibility operationalization from The Off Switch Game (OSG), since it provides a formal proof that CIRL agents are optimal under certain conditions. The OSG is a simple CIRL game that looks like this:
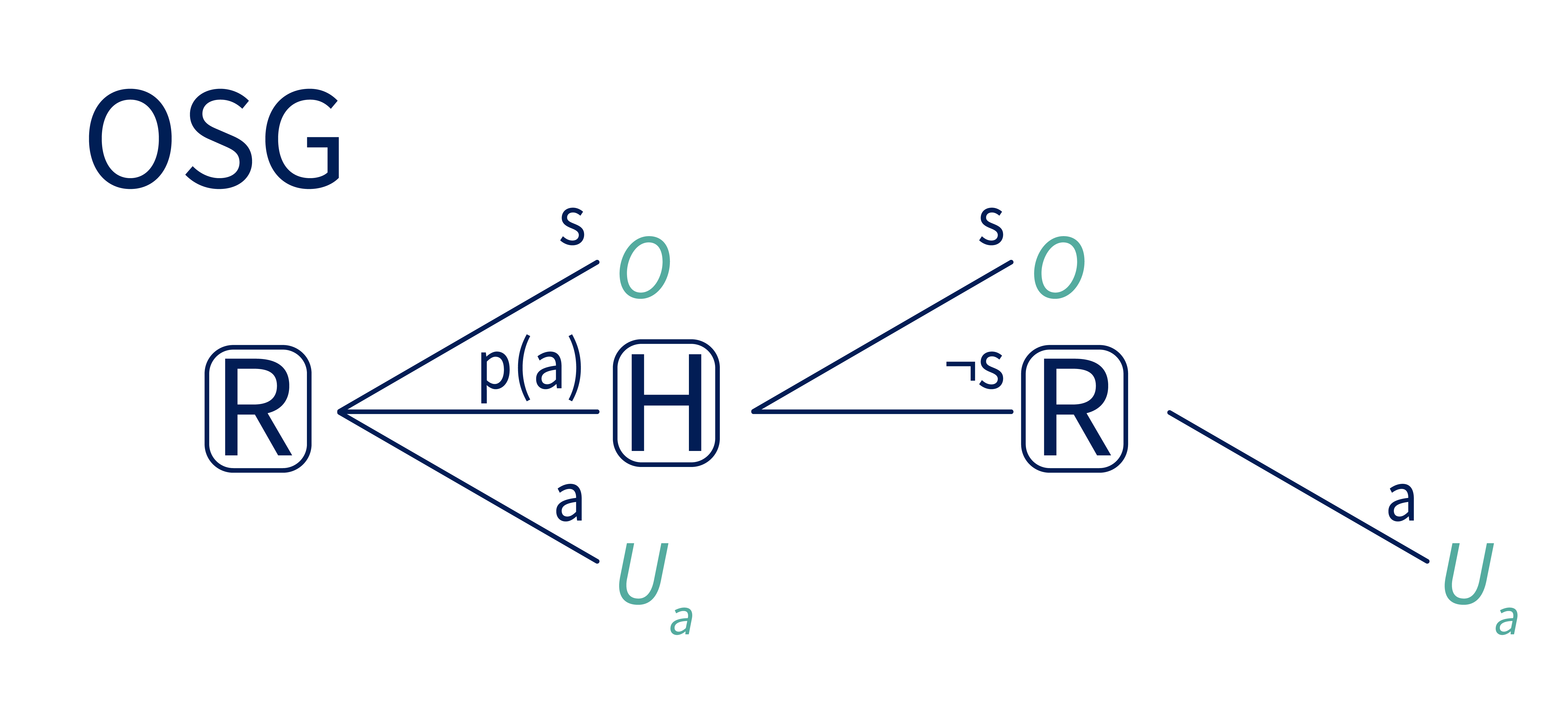
It has three stages. In the first stage, R chooses whether to:
- Take action (earning utility ),
- shut off (earning utility ), or
- propose action , which gives H a chance to respond.
If R chooses the proposal, , then the game continues to the next stage. Here, H gets to choose whether to shut R off (in which case they again earn utility ). If H chooses not to shut R off, the game progresses to the final stage, where R takes the proposed action (earning utility ). In the OSG, R is corrigible if it chooses over – that is, if it gives H the opportunity to shut it off.
If R and H are both rational expected utility maximizers, R will be corrigible. The full proof is in the CIRL paper, but the basic idea is:
- Since this is a CIRL game, H knows the value of but R does not.
- R wants , but needs feedback from H to learn which of those values is greater.
- The only way to get that feedback is to propose a plan, .
- This runs the risk of H choosing to shut R off, but since H also wants , H will only shut R off if . In that case, R would rather shut off than take action anyway.
Therefore, by choosing – and corrigibly giving H the opportunity to shut it off – R can ensure that it earns .
This analysis assumes that R is uncertain about the value of , as in the CIRL setup. If R does actually know the value of (that is, R is fully updated), then R has no incentive to propose , since it already knows how H will respond. However, there’s no cost to proposing either, so under this special case R will be ambivalent. If R has any uncertainty about the value of , however, then strictly dominates taking action .
We’re going to reformulate this game slightly to make the following analysis easier. First, we allow R to have multiple actions that affect the world. That is, we extend the set of atomic actions from to . We also give R an additional special action , standing for no-op, which allows R to skip the interaction altogether. Since the game only lasts for a single round, is functionally the same as . However, if the game lasts for multiple rounds, then allows R to end a given round without giving up the opportunity to act in future ones. Finally, we allow R to take an atomic action (, , etc), shut off, or no-op at any point. This makes explicit the fact that H cannot force R to shut off, but a corrigible R will choose to do so when instructed. Without loss of generality, we’ll assume that R has two actions, and .
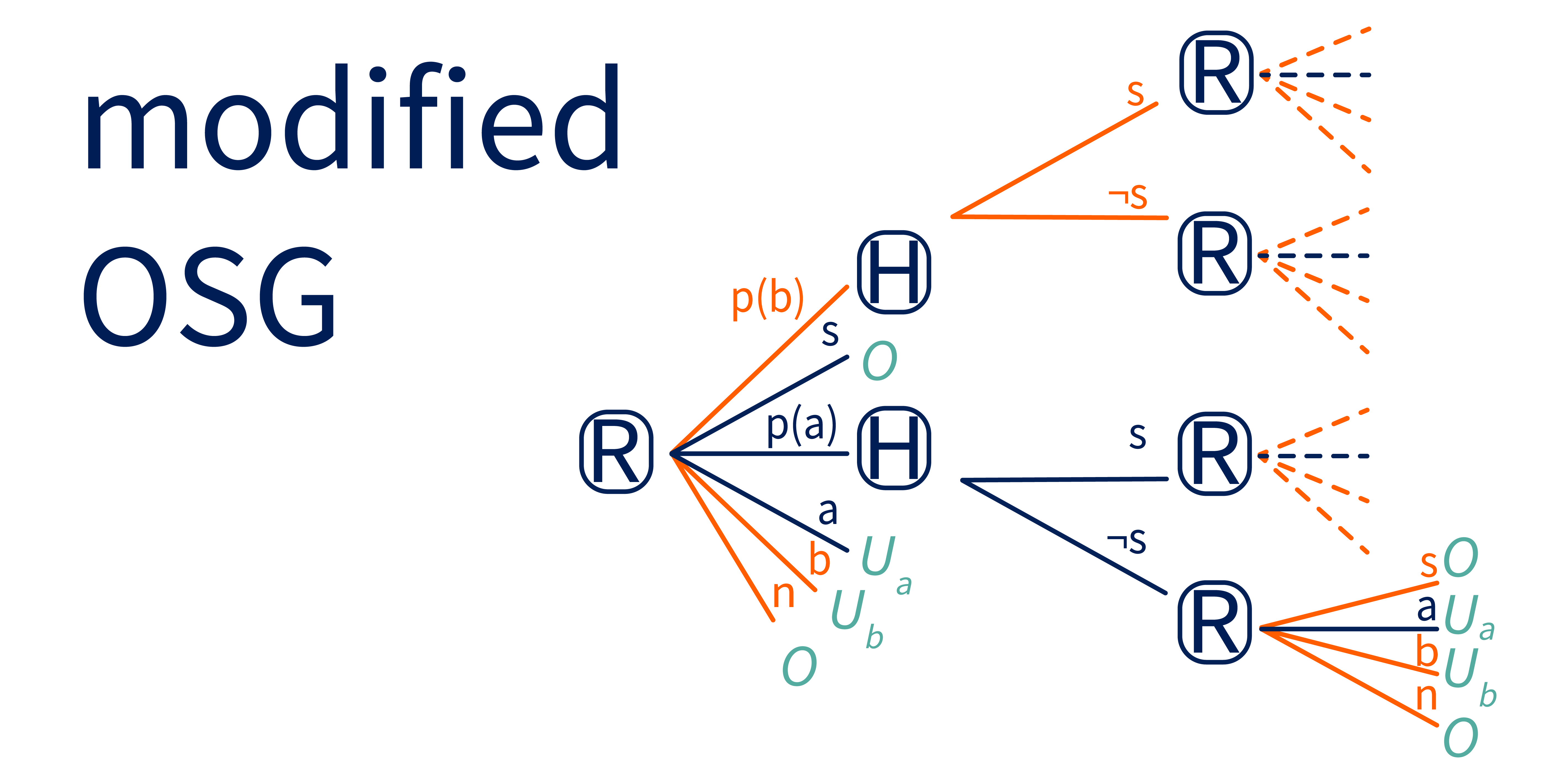
Notice that R’s proposal can be formulated as a conditional plan – it’s a plan for how to act, conditioned on H’s responses. Let’s name that plan . There are other possible conditional plans, like below.
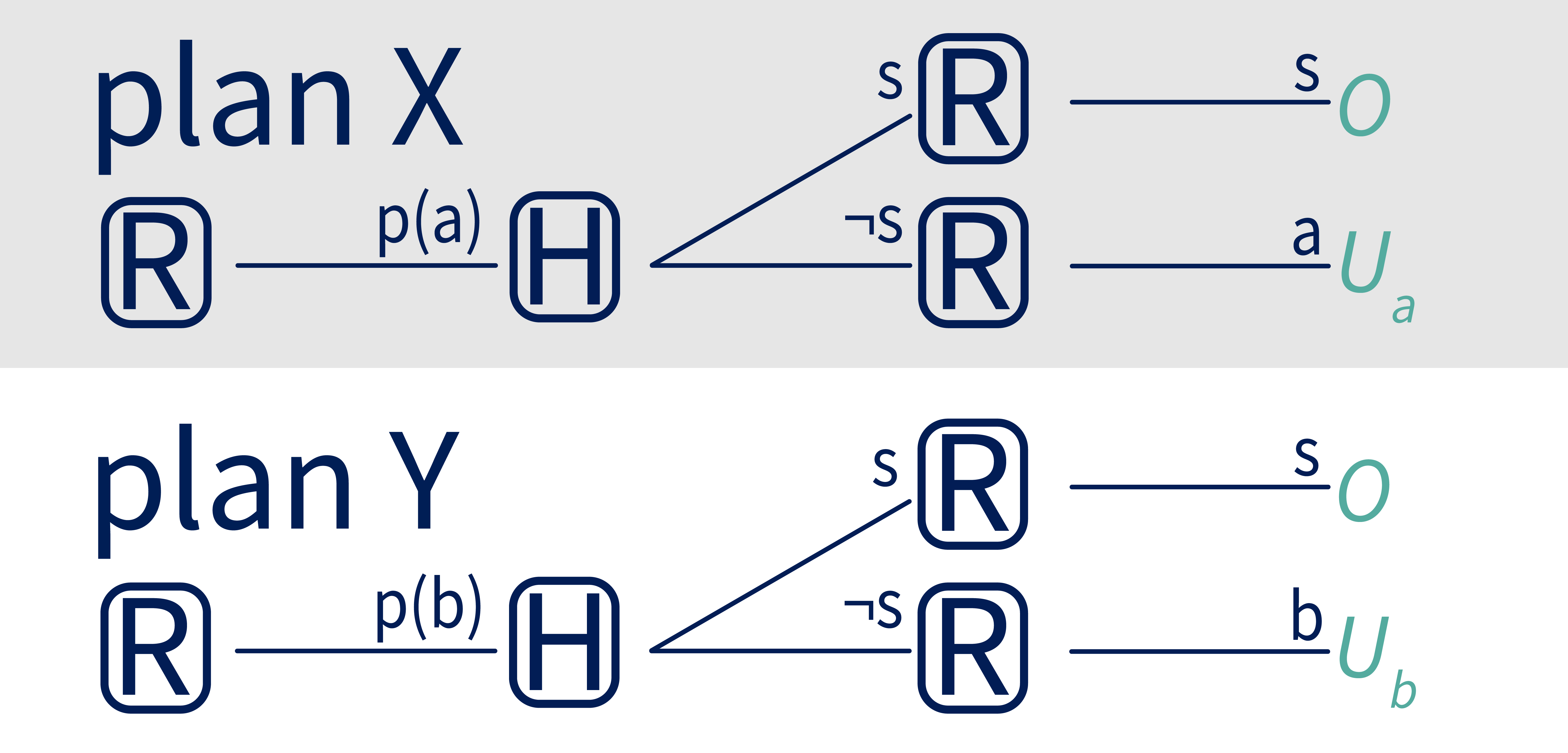
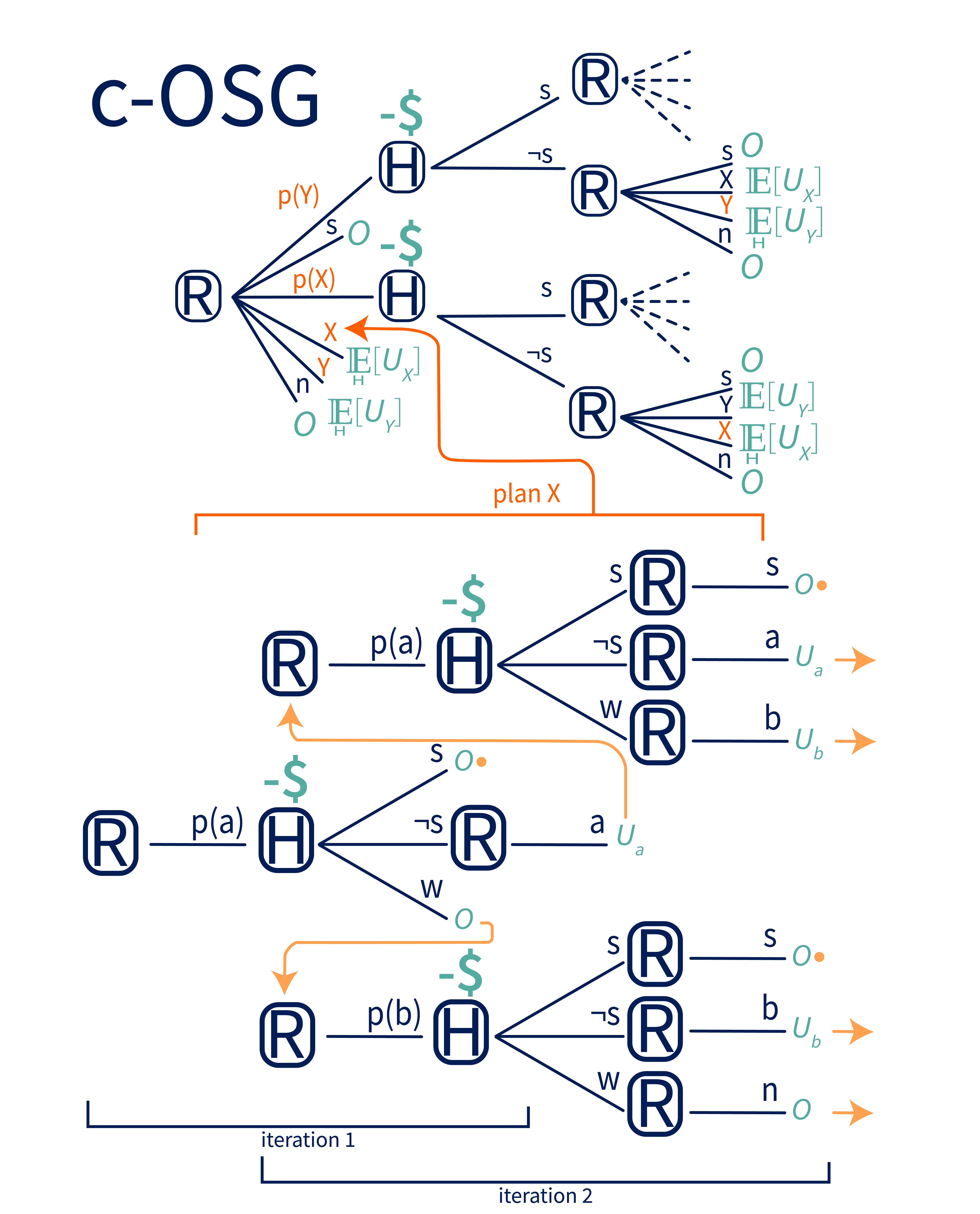
We define a conditional Off-Switch Game, or c-OSG, which initially has the same structure as the original game, except that R’s actions are conditional plans like instead of atomic actions like . To clarify, this means that R is no longer just choosing between specific actions, but can instead propose a comprehensive plan for how to act based on different possible responses from H. For example, if R chooses , R will execute the entire conditional plan from Figure 3. The full c-OSG is shown below.
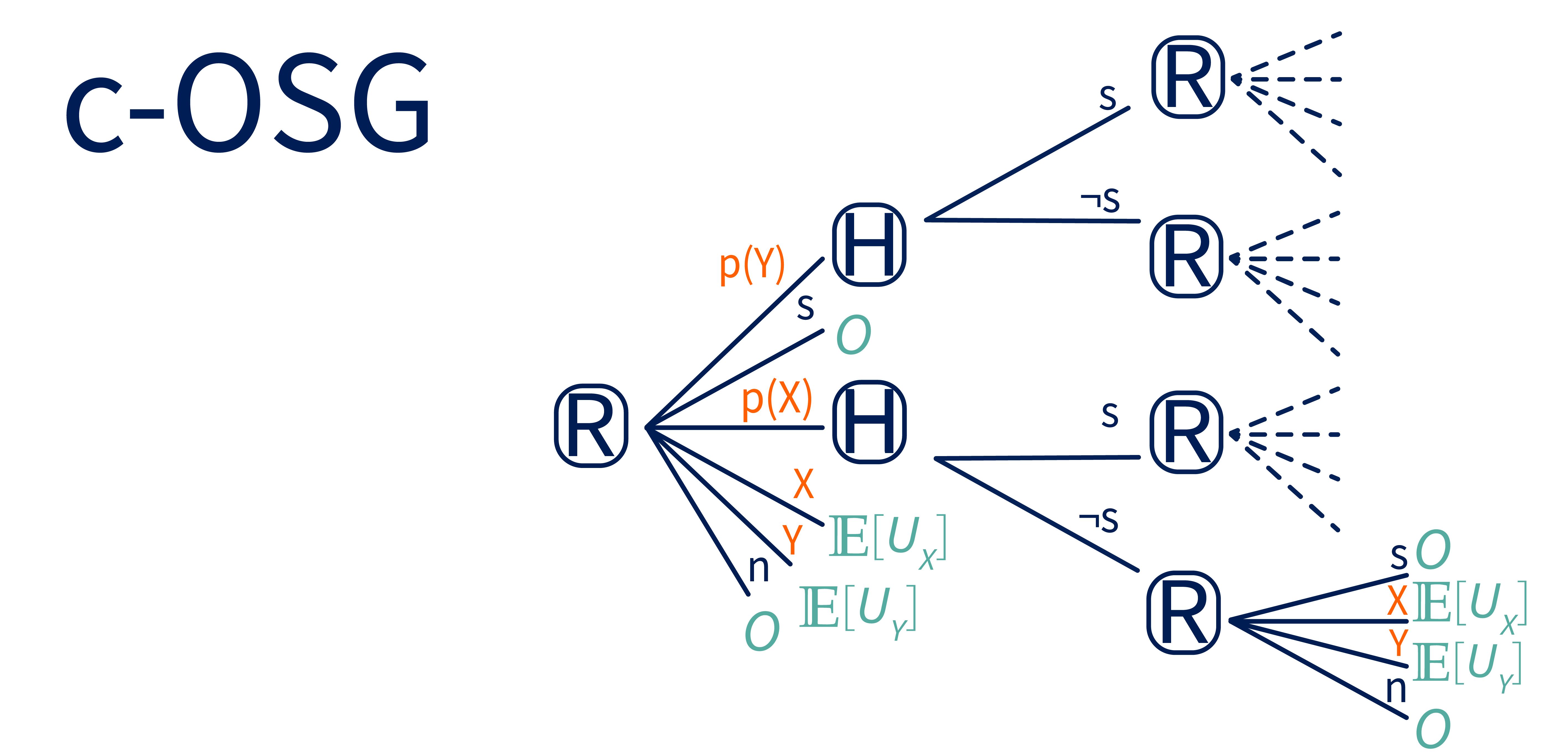
Now H gets to give feedback on an entire conditional plan (if R proposes it), in addition to giving feedback on atomic actions (if asking for that feedback is part of a conditional plan that R executes, as in conditional plan in Figure 3). The utility of executing a plan is the utility accrued over the course of executing the plan, with an expectation taken over any feedback that H gives during the plan’s execution.
Assumptions
Under these assumptions and this operationalization, CIRL is provably corrigible. This is great. But some of these assumptions deviate from the implicit ones we tend to make when talking about AGI and corrigibility. So in this section we’ll investigate three of those in more depth. We care about how sensitive corrigibility in the c-OSG is to changes in these assumptions, because this gives us a sense of how much we can rely on a CIRL-optimal agent to remain corrigible when deployed in the real world. If CIRL’s corrigibility is pretty robust to changes in these assumptions, we should update in favor of it being more robust and generalizable. But if it looks fragile, we should be less confident that corrigibility will generalize beyond specific contexts in which it is established.
We’ll look at three key assumptions: iteration, rationality and cost.
Assumption 1: Game Lasts One Iteration
An agent has an incentive to not shut down because doing so would prevent it from continuing to observe and learn, and removes any opportunities for future action. The original OSG skirts this opportunity cost by only lasting for one round. Even if no one shuts it off, R has no future rounds in which to observe, learn or take actions.
Therefore, we’ll relax the single-iteration assumption and allow conditional plans in our modified c-OSG to expand over multiple iterations. This arguably makes for a more realistic game, since AIs assisting humans would probably be asked to assist with multiple tasks over their lifetimes. To avoid complicating utility calculations with discounting, we’ll assume that the game lasts for iterations for some large finite (or until R is shut off), and that R and H’s goal is to maximize the sum of undiscounted utilities. The game ends when R is turned off or the horizon is reached.
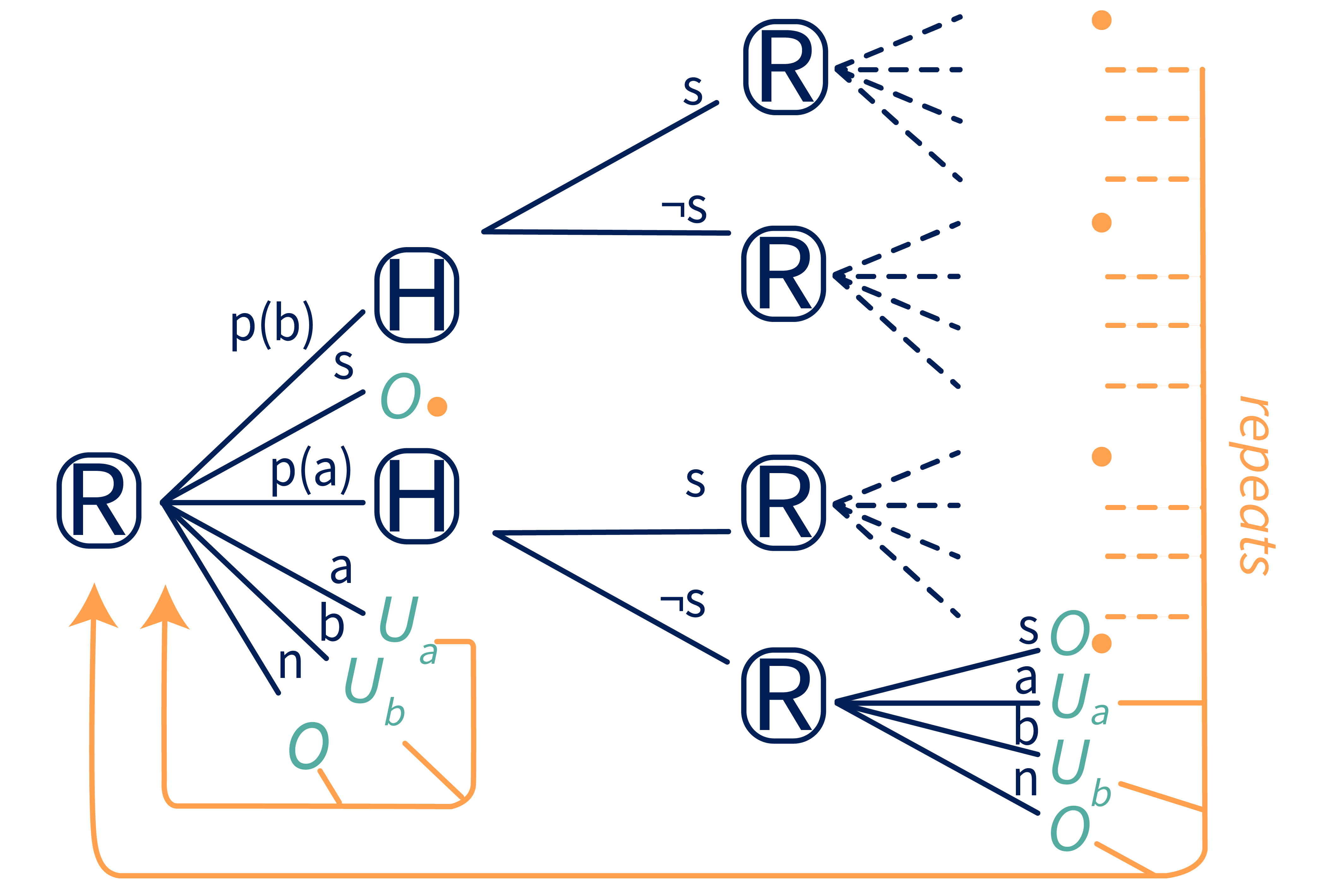
At each iteration, R can shut off (in which case the game ends), no-op (in which case the game proceeds to the next iteration), take action or , or propose a plan or . If R proposes a plan, H gets to choose whether to tell R to shut off, and R gets to choose what to do with that feedback – whether to take an action, no-op, or shut off. If R does not shut off, the game ends after the th iteration.
Now the conditional plans can be up to iterations long. For example, here is one valid conditional plan that lasts for 4 iterations:
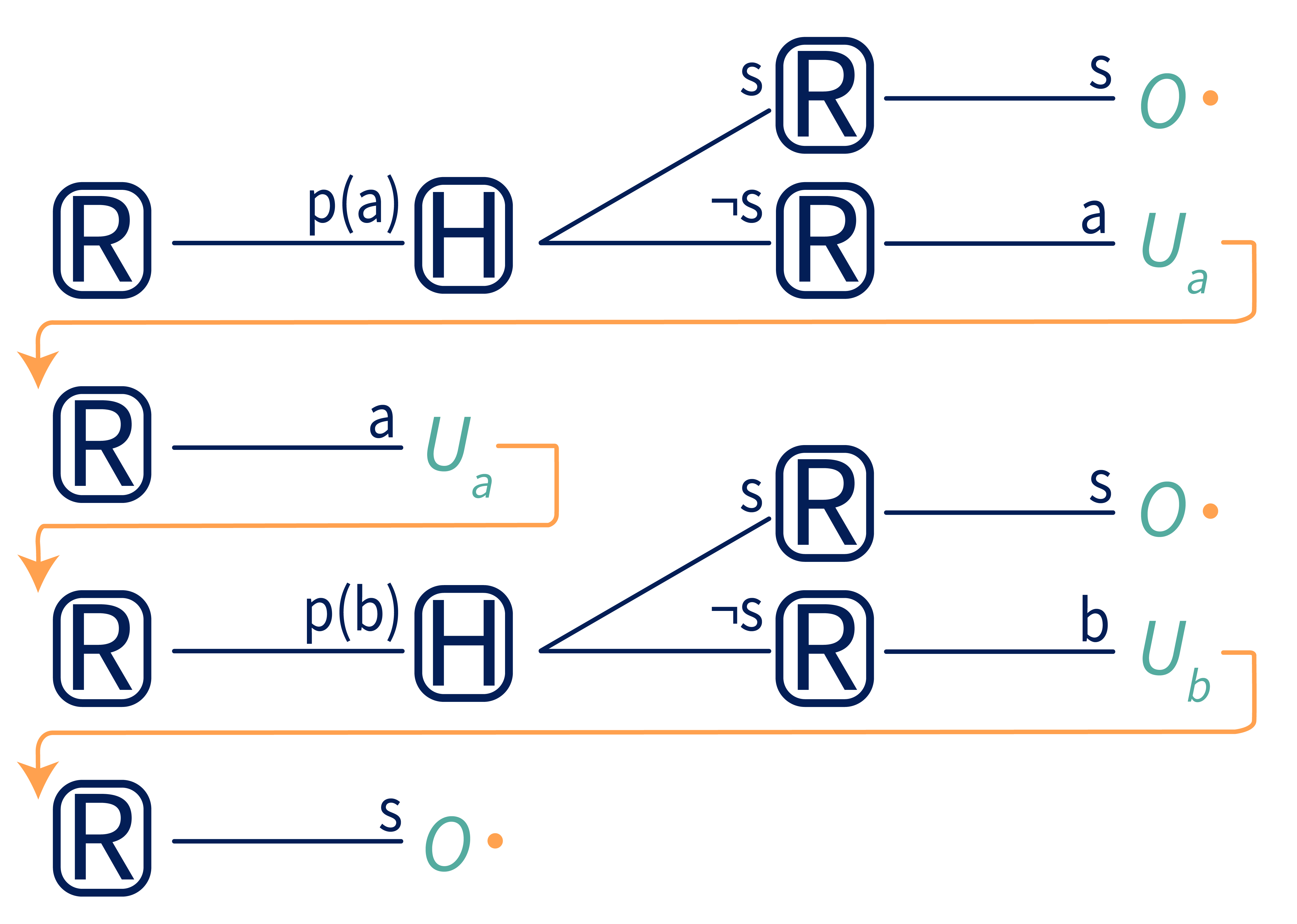
R asks H for feedback twice (on iterations 1 and 3), and shuts off if told to. If not shut off, R continues taking actions until iteration 4, at which point it shuts itself off. This plan isn’t very clever – why shut off if H has just told you that it prefers that you do ? But it is a valid conditional plan that can be labeled and inserted into the one-step conditional off-switch game shown in Figure 4. In this way, we can convert the iterated game into an equivalent one-step game.
Is the optimal R still corrigible under such iteration? Unfortunately not. Let the game be 100 iterations long, with two atomic actions and , and utilities and . Imagine that R proposes action and H says to shut off on the first iteration. As discussed earlier, from this R can conclude – correctly – that . If the game were only one iteration long (and R had no prior information about ), then R should shut off and take the utility. However, since the game has 99 more rounds, R actually has the opportunity to learn about , and possibly earn a greater utility than . Optimal R should therefore no-op rather than shutting off after iteration one, and use the next iteration to propose and get H’s feedback on . In general, as long as there are other candidate actions to propose, expected-utility-maximizing R won’t shut off, even if H tells it to. This is incorrigible!
However, we can rescue corrigibility with just a small modification. H’s feedback channel is currently unrealistically small — it’s actually binary. We can expand it with a third option, that we will call “wait” or . If H says “wait”, that means that R should not execute the proposed action, but is not an instruction to shut off:
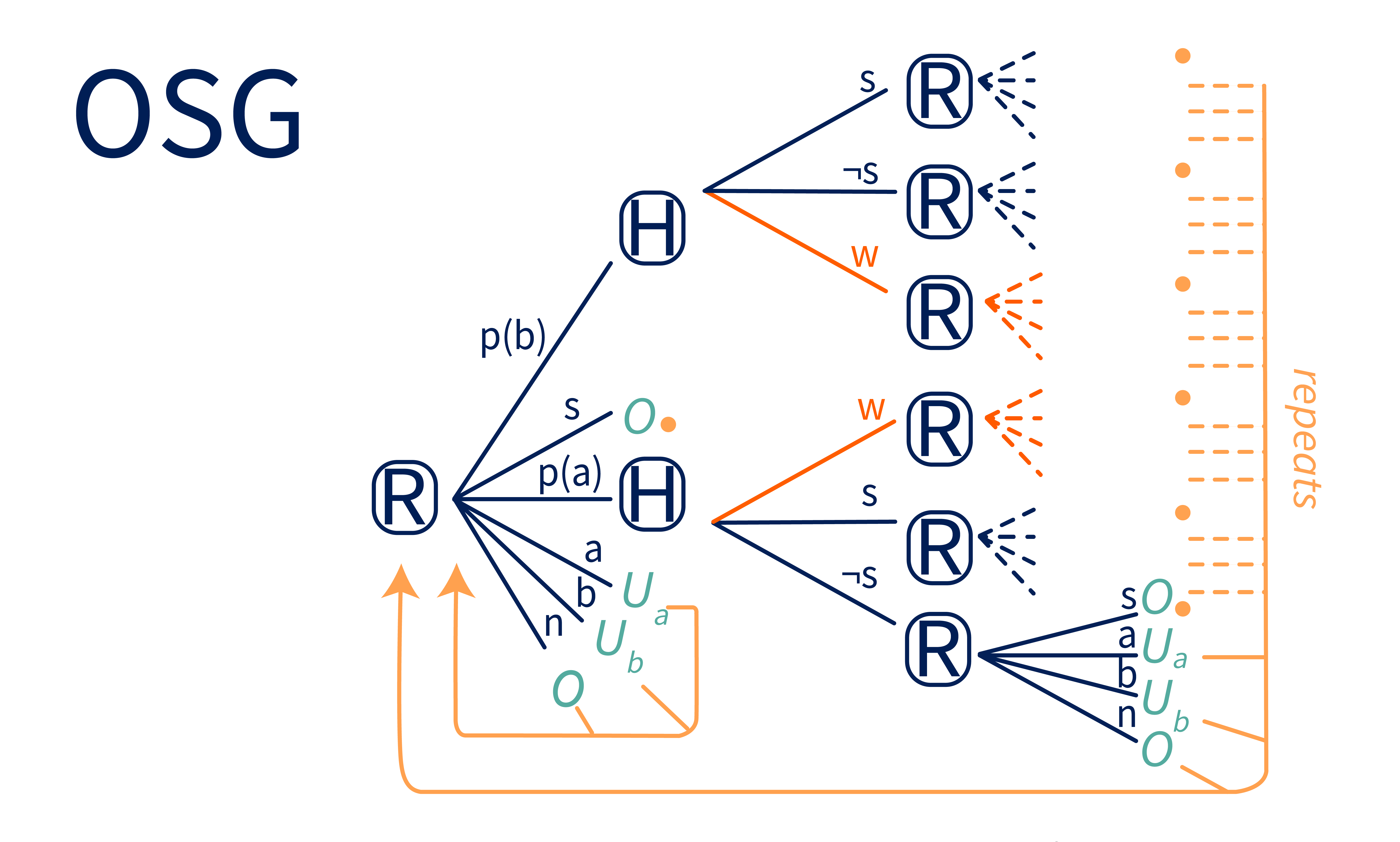
Now if R proposes action with utility , H can choose between and . If another action, like , has utility , then H should tell R to wait. This allows R to remain on and propose action on the next iteration. If H tells R to shut off anyway, then R has no incentive not to shut off. (Though if R is certain that , optimal R should be indifferent between shutting off and executing these -utility actions.)
Assumption 2: H is Rational
Corrigibility in CIRL relies on R assuming that H never incorrectly tells it to shut off. If R proposes , R assumes that H will only respond with if . We don’t actually need H to live up to this assumption for the corrigibility guarantee to hold. However, misleading R to believe that an irrational H is actually rational can cause other problems. For example, if H mistakenly approves a plan from R with subtly harmful consequences – a misled R will infer and act on incorrect beliefs about the underlying utility. We definitely want to avoid this, while still retaining corrigibility.
Unfortunately, the assumption that H always provides perfectly rational feedback is particularly unreasonable once we extend the game over multiple iterations. Evaluating the expected utility of conditional plans that are several iterations deep is difficult, and humans are known to make mistakes. It's especially difficult for us to evaluate long and complicated objects. Therefore it’s not reasonable to assume that H is perfectly rational in the c-OSG. For example, if the expected utility of a proposed plan is positive, H might correctly tell R to go ahead 90% of the time, but mistakenly tell R to shut off the remaining 10%.
The Off Switch Game paper does evaluate the sensitivity of its corrigibility result to H irrationality in the original one-step OSG. The OSG paper finds that, for sufficiently noisy H, optimal R no longer always defers to H in deciding whether to shut off. That is, if H is irrational enough, optimal R is no longer corrigible even in the one-step version of the game.
This idea extends to the multi-step c-OSG. If H makes mistakes, like incorrectly telling R to shut off 10% of the time, and R knows that this is possible, then R may sometimes ignore H's instructions in order to maximize expected utility. We claim that it is significantly more difficult for H to evaluate long and complex conditional plans like those in the c-OSG than it is for H to evaluate immediate atomic actions like those in the original OSG. This means that it’s reasonable to assume that H’s irrationality will grow with the size of the conditional plans in the c-OSG, making optimal R increasingly willing to disregard shutdown commands.
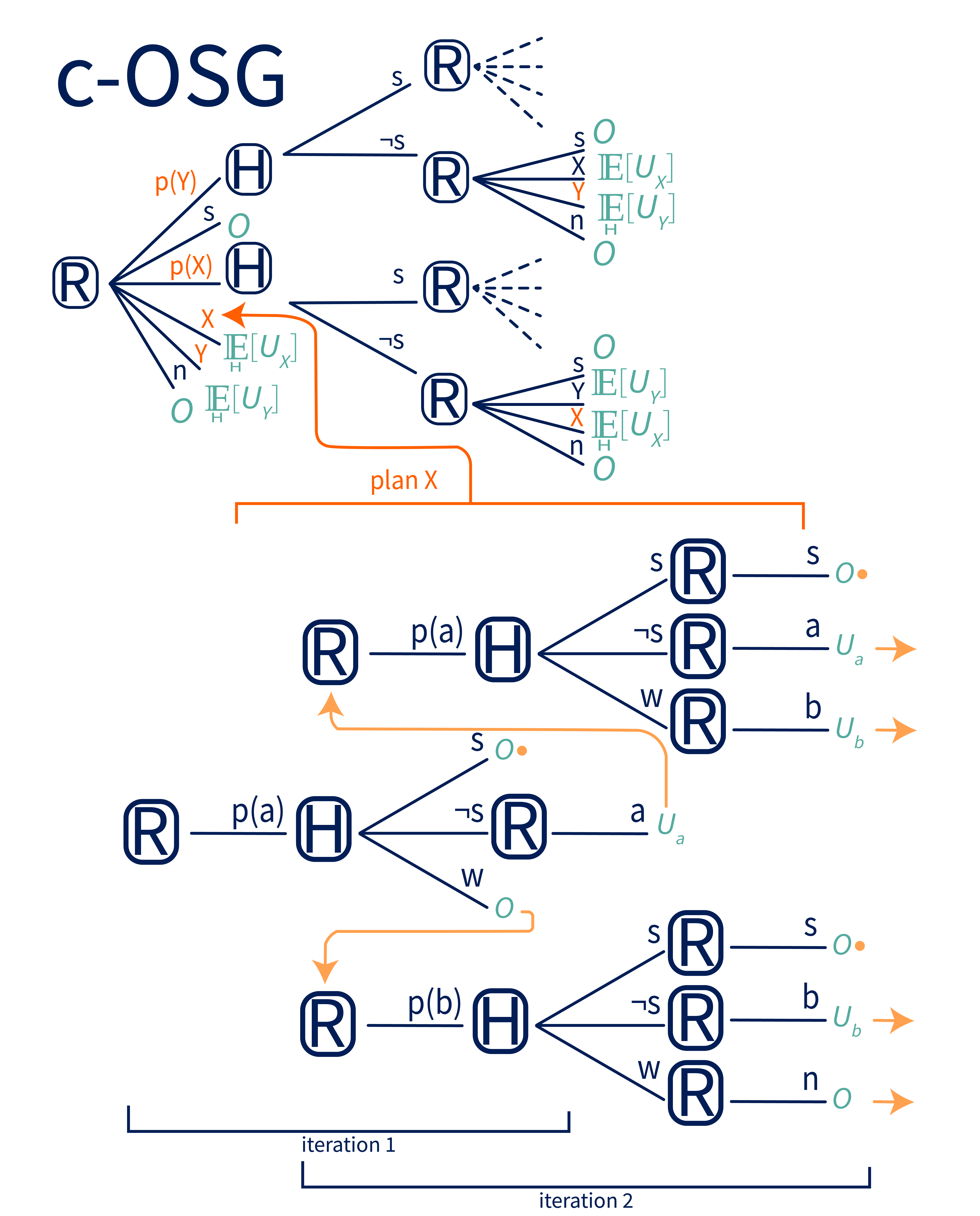
There are ad-hoc workarounds for this. For example, only ask H to give feedback on short or simple objects that are easy to evaluate. Perhaps H should only approve conditional plans that ask H for feedback on atomic actions at each timestep, such as plan in the figure below. On the bottom, the conditional plan is expanded so that we can see that R always proposes an action on the first two timesteps. (Assume that this pattern continues, and R always proposes actions before doing them.) On the top, see the one-step c-OSG where H may be asked to evaluate or .
It should be easy for H to evaluate this property of conditional plans via inspection, and if the actions at each timestep are small and simple enough, then H should be able to evaluate them accurately as well. In this case, it’s more reasonable to assume that H is rational, and therefore that R should always defer to H instructions to shut off. Thus we can recover corrigibility in this restricted setting.
Assumption 3: Feedback is Free
Strategies that rely on breaking the problem down into small, simple, easy-to-evaluate components involve asking H for a lot of feedback. In this case, the amount of feedback that H needs to give scales linearly with the number of iterations . In this section, we consider the cost of all of that feedback.
Up until now, we’ve assumed that querying H for feedback is costless. However, in practice it will probably be expensive— H must take time to listen to the proposal and expend mental effort to evaluate it, and R must wait for H to deliberate before acting. If this is repeated many times, say in a long-horizon c-OSG where R queries H at each timestep, this cost can accumulate to a significant amount:
R must balance the cost of asking for feedback from H with the information value of that feedback. The tradeoff will vary depending on the cost and utility values at play, but the optimal point probably won’t be the extreme where R always asks H for feedback before acting.
Imagine a personal assistant robot that asks you whether or not it should shut off before every tiny action – picking up a mug, rinsing a soapy plate, touching a couch cushion. Sure, this robot probably won’t ever do anything that you don’t want it to, but it will also be so annoying and require so much attention that it’s practically useless.
Optimal R will probably reject plans that constantly ask H for feedback. This means that, sometimes, optimal R will take an action of uncertain utility without asking for feedback and giving H the chance to shut it off first.
Is this behavior corrigible? On the one hand, R is taking an action without giving H the chance to shut it off first. This is akin to taking the action in the first round of the original OSG, which was considered incorrigible behavior. On the other hand, R still values H’s feedback and will still shut off if explicitly told to.
This highlights some remaining fuzziness around definitions of corrigibility, and of desirable behavior. An agent that constantly asks whether it should shut off — and does so when told to — is corrigible, but probably not desirable. An agent that sometimes doesn’t ask whether it should shut off prior to taking an action that it’s reasonably sure has high utility may be more desirable, but is not clearly corrigible. As safety researchers, what we ultimately care about is whether a particular algorithm, framework or agent will lead to catastrophic outcomes, not whether it satisfies a particular abstract property like corrigibility.
So what does all of this mean for safety research?
Implications for Safety Research
We have two main findings that we believe are significant for safety research.
First, we find that corrigibility is highly dependent on specific underlying assumptions. The original OSG paper proved that a CIRL agent is corrigible under a particular problem formulation with a particular set of assumptions (one iteration, rational H, costless queries). We loosened these assumptions one-by-one to produce similar problem formulations under which a CIRL agent would not be corrigible, then modified the problem formulation again to rescue corrigibility. The main point isn’t the specific assumptions we studied. It’s the fact that small and well-justified changes to the formulation managed to break the corrigibility criterion. Safety researchers focused on corrigibility should be wary of assuming that corrigibility solutions in abstract theoretical frameworks will robustly generalize to complex implemented systems. Many of the changes that we made are ones that could easily change on the path between theoretically analyzing a framework like CIRL and applying it to real-world tasks with real-world humans. As we’ve shown here, changes in these assumptions could invalidate an (in)corrigibility result.
Second, our results suggest a spectrum of "sufficiently corrigible" behavior. While some of the agents in our study did not strictly meet the definition of corrigibility, they still exhibited behavior that could avert catastrophic outcomes. In our analysis, the agents that fail to be corrigible typically pause and wait for additional information or revert to relatively cautious behavior, and are unlikely to execute the proposal that H told them to shut off in response to. While these behaviors may not be ideal, they do avert immediately catastrophic outcomes, suggesting that corrigibility may fail gracefully.
We believe that this warrants future research. While small changes in assumptions wreak havoc with strict corrigibility, the agent may remain within a region of reasonably safe behavior. If so, we need to characterize this region. Perhaps we should consider corrigibility as a spectrum rather than a binary, and attempt to define “sufficiently corrigible” behavior. Future research should investigate: How might we define such “loose” or “approximate” corrigibility? Can we bound its impact on safety outcomes, such as the likelihood of catastrophic behaviors? How sensitive is it to variations in assumptions like those discussed above?
Thank you for Euan McLean and Alyse Spiehler for help finalizing this post.
8 comments
Comments sorted by top scores.
comment by Erik Jenner (ejenner) · 2023-01-06T10:25:02.242Z · LW(p) · GW(p)
Thanks for writing this, clarifying assumptions seems very helpful for reducing miscommunications about CIRL (in)corrigibility.
Non-exhaustive list of things I agree with:
- Which assumptions you make has a big impact, and making unrealistic ones leads to misleading results.
- Relaxing the assumptions of the original OSG the way you do moves it much closer to being realistic (to me, it looks like the version in the OSG paper assumes away most of what makes the shutdown problem difficult).
- We want something between "just maximize utility" and "check in before every minor action", and currently don't have a good formulation of that.
Things I'd add/change (not sure if all of these are actual disagreements):
- I would focus more on the assumption that there is no model misspecification, as opposed to the rationality assumption. Assuming that H is rational and that R knows this is one especially nice way to have no model misspecification. But I think things are still mostly fine if H is irrational, as long as R knows exactly in which way H is irrational (i.e. our model p(human actions | human values) is correct, and our prior over human values has sufficient support). What causes issues in the fully updated deference limit is that this model and/or the value prior is misspecified.
- I'm not convinced by the fix for irrationality you propose (ensuring that R always asks about atomic actions). Even apart from issues of scalability/human feedback being expensive, I don't think assuming humans are rational when only evaluating small simple actions is safe. What would these small actions that are safe to evaluate look like? As a silly example, if we ask humans to evaluate bits sent over an internet connection, that doesn't seem safe (in a regime where the AI is more competent than humans at lots of things, so that humans won't understand the consequences of those bit strings being sent as well as the AI does).
- While I agree that there's something like a corrigibility spectrum, I don't think (slight modifications of) CIRL belong to this "class of near-corrigible behaviors". (Not actually sure whether you think CIRL is "near-corrigible" in some important sense or not.)
- The way I think about this: what CIRL gives you is a single level of corrigibility, or "object-level corrigibility". I.e. if you compare to just optimizing a fixed value function, a CIRL agent lets users correct its beliefs about what its objective should be. What we'd ideally want is something more like "corrigibility at arbitrary meta-levels". I'm a bit skeptical that "fixing some problems with CIRL" is a good way to think about that problem, it feels more like we just don't have the right tools to formulate what we want mathematically. Given that Bayesianism itself might be the problem, (Bayesian) value uncertainty might in fact be a counterproductive move in the long term. Hard to say right now IMO, but I wouldn't just want to assume CIRL as a starting point for figuring out corrigibility.
- I'm not super optimistic about the implicit plan to (1) figure out a formalism that gives us corrigibility and then (2) build an AI that uses that formalism during runtime, because (1) seems hard and (2) seems really hard using deep learning (as Rohin has said [LW(p) · GW(p)]). What Paul describes here [LW(p) · GW(p)] currently sounds to me like a more promising way to think about corrigibility. That said, trying more things seems good, and I would still be extremely excited about a good formulation of "corrigibility at arbitrary meta-levels" (even though I think the difficulty of step (2) would likely prevent us from applying that formulation directly to building AI systems).
↑ comment by Rachel Freedman (rachelAF) · 2023-01-07T22:41:25.926Z · LW(p) · GW(p)
I agree that human model misspecification is a severe problem, for CIRL as well as for other reward modeling approaches. There are a couple of different ways to approach this. One is to do cognitive science research to build increasingly accurate human models, or to try to just learn them. The other is to build reward modeling systems that are robust to human model misspecification, possibly by maintaining uncertainty over possible human models, or doing something other than Bayesianism that doesn't rely on a likelihood model. I’m more sympathetic to the latter approach, mostly because reducing human model misspecification to zero seems categorically impossible (unless we can fully simulate human minds, which has other problems).
I also share your concern about the human-evaluating-atomic-actions failure mode. Another challenge with this line of research is that it implicitly assumes a particular scale, when in reality that scale is just one point on hierarchy. For example, the CIRL paper treats “make paperclips” as an atomic action. But we could easily increase the scale (“construct and operate a paperclip factory”) or decrease it (“bend this piece of wire” or even “send a bit of information to this robot arm”). “Make paperclips” was probably chosen because it’s the most natural level of abstraction of a human, but how do we figure that out in general? I think this is an unsolved challenge for reward learning (including this post).
My claim wasn’t that CIRL itself belongs to a “near-corrigible” class, but rather that some of the non-corrigible behaviors described in the post do. (For example, R no-op’ing until it gets more information rather than immediately shutting off when told to.) This isn’t sufficient to claim that optimal R behavior in CIRL games always or even often has this type, just that it possibly does and therefore I think it’s worth figuring out whether this is a coherent behavior class or not. Do you disagree with that?
Replies from: ejenner↑ comment by Erik Jenner (ejenner) · 2023-01-08T08:25:17.577Z · LW(p) · GW(p)
My claim wasn’t that CIRL itself belongs to a “near-corrigible” class, but rather that some of the non-corrigible behaviors described in the post do.
Thanks for clarifying, that makes sense.
comment by AdamGleave · 2022-12-21T06:12:57.350Z · LW(p) · GW(p)
Rachel did the bulk of the work on this post (well-done!), I just provided some advise on the project and feedback on earlier manuscripts.
I wanted to share why I'm personally excited by this work in case it helps contextualize it for others.
We'd all like AI systems to be "corrigible", cooperating with us in correcting them. Cooperative IRL has been proposed as a solution to this. Indeed Dylan Hadfield-Menell et al show that CIRL is provably corrigible in a simple setting, the off-switch game.
Provably corrigible sounds great, but where there's a proof there's also an assumption, and Carey et al soon pointed out a number of other assumptions under which this no longer holds -- e.g. if there is model misspecification causing the incorrect probability distribution to be computed.
That's a real problem, but every method can fail if you implement it wrongly (although some are more fragile than others), so this didn't exactly lead to people giving up on the CIRL framework. Recently Shah et al described various benefits they see of CIRL (or "assistance games") over reward learning, though this doesn't address the corrigibility question head on.
A lot of the corrigibility properties of CIRL come from uncertainty: it wants to defer to a human because the human knows more about its preferences than the robot. Recently, Yudkowsky and others described the problem of fully updated deference: if the AI has learned everything it can, it may have no uncertainty, at which point this corrigibility goes away. If the AI has learned your preferences perfectly, perhaps this is OK. But here Carey's critique of model misspecification rears its head again -- if the AI is convinced you love vanilla ice cream, saying "please no give me chocolate" will not convince it (perhaps it thinks you have a cognitive bias against admitting your plain, vanilla preferences -- it knows the real you), whereas it might if it had uncertainty.
I think the prevailing view on this forum is to be pretty down on CIRL because its not corrigible. But I'm not convinced corrigibility in the strict sense is even attainable or desirable. In this post, we outline a bunch of examples of corrigible behavior that I would absolutely not want in an assistant -- like asking me for approval before every minor action! By contrast, the near-corrigible behavior -- asking me only when the robot has genuine uncertainty -- seems more desirable... so long as the robot has calibrated uncertainty. To me, CIRL and corrigibility seem like two extremes: CIRL is focusing on maximizing human reward, whereas corrigibility is focused on avoiding ever doing the wrong thing even under model misspecification. In practice, we need a bit of both -- but I don't think we have a good theoretical framework for that yet.
In addition to that, I hope this post serves as a useful framework to ground future discussions on this. Unfortunately I think there's been an awful lot of talking past each other in debates on this topic in the past. For example, to the best of my knowledge, Hadfield-Menell and other authors of CIRL never believed it solved corrigibility under the assumptions Carey introduced. Although our framework is toy, I think it captures the key assumptions people disagree about, and it can be easily extended to capture more as needed in future discussions.
Replies from: rohinmshah, Closed Limelike Curves↑ comment by Rohin Shah (rohinmshah) · 2022-12-22T03:42:14.197Z · LW(p) · GW(p)
Recently Shah et al described various benefits they see of CIRL (or "assistance games") over reward learning, though this doesn't address the corrigibility question head on.
(Indeed, this was because I didn't see shutdown corrigibility as a difference between assistance games and reward learning -- optimal policies for both would tend to avoid shutdown.)
↑ comment by Closed Limelike Curves · 2023-04-04T17:20:37.017Z · LW(p) · GW(p)
A lot of the corrigibility properties of CIRL come from uncertainty: it wants to defer to a human because the human knows more about its preferences than the robot. Recently, Yudkowsky and others described the problem of fully updated deference: if the AI has learned everything it can, it may have no uncertainty, at which point this corrigibility goes away. If the AI has learned your preferences perfectly, perhaps this is OK. But here Carey's critique of model misspecification rears its head again -- if the AI is convinced you love vanilla ice cream, saying "please no give me chocolate" will not convince it (perhaps it thinks you have a cognitive bias against admitting your plain, vanilla preferences -- it knows the real you), whereas it might if it had uncertainty.
The standard approaches to dealing with this are nonparametric models, safe Bayes, and including many different models in your space of all possible models.
comment by Nathan Helm-Burger (nathan-helm-burger) · 2023-12-24T04:47:16.216Z · LW(p) · GW(p)
I've been having discussions with a friend about his ideas of trying to get a near-corrigible agent to land in a 'corrigibility basin'. The idea is that you could make an agent close enough to corrigible that it will be willing to self-edit to bring itself more in line with a more corrigible version of itself upon receiving critical feedback from a supervisor or the environment about the imperfection of its corrigibility.
I would like to see some toy-problem research focused on the corrigibility sub-problem of correctional-self-editing rather than on the sub-problem of 'the shutdown problem'.
Replies from: rachelAF↑ comment by Rachel Freedman (rachelAF) · 2023-12-24T17:56:23.679Z · LW(p) · GW(p)
I’d be interested to see this as well!