Literature Review of Text AutoEncoders
post by NickyP (Nicky) · 2025-02-19T21:54:14.905Z · LW · GW · 5 commentsContents
Introduction
Architecture & General Training Strategy for Single-Vector Text Autoencoders
Some Main Papers
Smaller-scale experiments:
1) AUTOBOT: Sentence Bottleneck AutoEncoders from Transformer Language Models (Montero et al., 2021)
2) Vec2Text: Text Embeddings Reveal (Almost) As Much As Text (Morris et al. 2023)
3) Semantic Overlap Summarization using Sentence Autoencoders (Bansal et al., 2023)
4) Contra Bottleneck T5 (Lee. 2023)
Larger-scale Experiments
5) Vec2Text with Round-Trip Translations (Cideron et al. 2022) (Google Brain)
6) SONAR: Sentence-Level Multimodal and Language-Agnostic Representations (Duquenne, et al. 2023) (Meta)
Other work I did not read deeply.
Bag-of-Vectors Autoencoders (Mai et al. 2021.)
SemFormers: Language Models with Semantic Planning (Yin et. al 2024)
List of other papers
Brief Example of Use
Conclusion
None
5 comments

This is a brief literature review of Text AutoEncoders, as I used them in a recent project and did not find a good resource covering them.
TL;DR: There exist models that take some text -> encode it into a single vector -> decode back into approximately the same text. Meta's SONAR models seem to be the best at the moment for this. You can try them in this google colab.
Introduction
Text AutoEncoders are a simple approach: you train a model to encode an entire input sequence (e.g. a sentence) into a latent representation, and decode that representation to reconstruct the original text.
Most literature is interested in "text-embed models" or "sentence transformers", which embed a text into a single vector for things like categorization and retrieval-augmented-generation. These have their uses, and take most of the attention, but typically are encoder-only trained to have "high similarity between similar texts".
Instead, I try to focus specifically on models which have a decoder. In particular, these compress the entire input into one fixed-size vector (the “bottleneck”). This single-vector representation still be used for comparison, and clustering, but the main benefit of them is that they have a reconstruction if you use their decoder.
Below, I first recap the architecture and training for single-vector text auto-encoders, then highlight the relevant papers that use them. I then briefly discuss some related works that do not rely on a single-vector bottleneck but are still relevant. I also give a short example of a couple of auto decoded paragraphs.
Architecture & General Training Strategy for Single-Vector Text Autoencoders
Here focus on Single-vector Text AutoEncoders, also sometimes called Text Bottleneck AutoEncoders, Sentence Bottleneck AutoEncoders or just AutoEncoders.
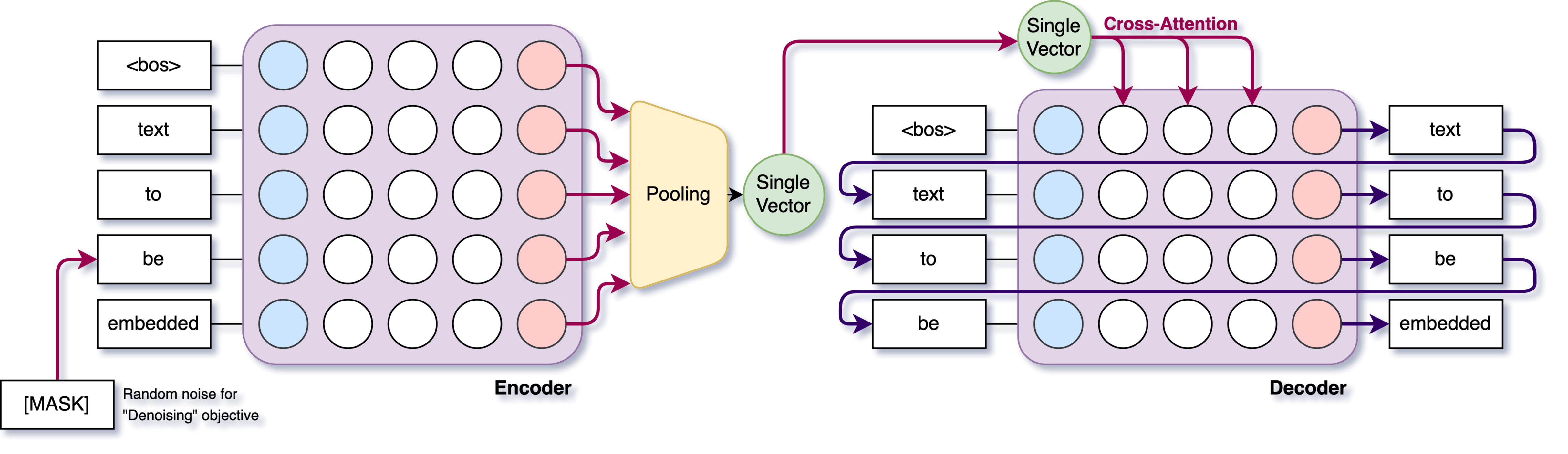
- Encoder
- Typically either a recurrent network (RNN, LSTM) or a Transformer encoder.
- The entire input sequence is processed into a single hidden or pooled representation, e.g. by taking the final hidden state, or pooling (like
[CLS]approach, or average pooling). - If you’re using a large pretrained model (e.g. T5, RoBERTa), you might freeze it or partially fine-tune it.
- Bottleneck
- This is literally the single vector. Sometimes it’s the last hidden state. Sometimes a small linear or MLP projection is used to reduce or fix dimension. Typically in the 256–1024 dimension range.
- There are variations where this can be multiple vectors.
- This is literally the single vector. Sometimes it’s the last hidden state. Sometimes a small linear or MLP projection is used to reduce or fix dimension. Typically in the 256–1024 dimension range.
- Decoder
- Autoregressive or seq2seq generation. RNN or Transformer.
- Takes the single vector and conditions on it at each decoding step. Usually, cross-attention is replaced with “this single embedding is repeated” or used as the initial hidden state.
- Training Loss
- Negative log-likelihood or cross-entropy to reconstruct the original text from that single vector. Sometimes they add a denoising approach or specialized corruption. Sometimes they add additional objectives such as MSE loss between the same sentence in different languages, amongst other things
Below are major examples.
Some Main Papers
Here are some of the main papers that implement text auto-encoders. The first three are some smaller scale experiments, and the latter two are larger-scale one. The largest training run is the SONAR one, with the longest context lengths is the SONAR paper, using ~100B tokens and allowing context sizes of up to 512 tokens.
Smaller-scale experiments:
1) AUTOBOT: Sentence Bottleneck AutoEncoders from Transformer Language Models (Montero et al., 2021)
Aim: I think the first main transformers-based text auto-encoder. Seems to work well as a semantic-embedding model compared to other unsupervised approaches at the time.
Architecture Encoder: Frozen RoBERTa (base: 125M params, large also tested). A learned multi-head attention bottleneck pools final hidden states into a single 768-dim sentence vector.
Architecture Decoder: Single-layer Transformer decoder (hidden size 768, multi-head attention). Uses cross-attention on the single bottleneck vector , but add an additional gating mechanism by replacing the pre-output with:
Training: De-noising AutoEncoding (masked token reconstruction, cross-entropy loss). Uses BooksCorpus + Wikipedia (~2.5B tokens).
Models not available to download, but the fine-tuning code is on GitHub.
2) Vec2Text: Text Embeddings Reveal (Almost) As Much As Text (Morris et al. 2023)
Aim: Show that dense text embeddings from a black-box encoder can be iteratively “inverted” (like model-inversion attack [LW · GW] or "feature visualization") to reconstruct the original text.
Achieves good recovery of OpenAI text-embeddings-ada-002 for 32-token inputs (60% exact match, 83.4 BLEU) and OK performance up to 128 tokens (8% exact match, 55 BLEU). Showing that embeddings are quite revealing.
Architectures:
- Encoder: The encoder is any pre-trained, black-box embedding model (e.g., GTR-base or OpenAI text-embedding-ada-002). At each inference step, the system queries this encoder to obtain embeddings.
- Two-Phase Decoder (called Vec2Text):
- Base (Initial) Model: A Transformer that takes in the embedding as a guess, and outputs a possible first guess text tokens .
- Iterative Correction Module: Another Transformer-based Encoder + Decoder model that is a fine tune of T5-base that refines the guess. It is fed three main things at time-step t:
- The target embedding:
- The current guess embedding:
- The difference between those embeddings:
- The current guess text tokens:
- This correction module outputs , the guess tokens at the next time step. Re-embedding that guess lets the system iteratively minimize the distance to the target embedding. They try up to 50 time-steps and use beam search.
Training: Standard cross-entropy modelling loss. They train on MS MARCO, ~350M tokens total (32 or 128 tokens) embedded with OpenAI’s text-embedding-ada-002.
Models available on HuggingFace, but should access via their GitHub repo. Not be confused with the other model below called vec2text
3) Semantic Overlap Summarization using Sentence Autoencoders (Bansal et al., 2023)
Aim: Generate a single sentence capturing common overlapping information from two input sentences, using a small, plug-and-play autoencoder-based model.
Architectures:
- Encoder: A frozen RoBERTa-base encoder that converts each input sentence into a single vector.
- Decoder: A Transformer decoder with either 1 or 3 layers, mapping the (overlap) embedding back to a sentence. A deeper (3-layer) decoder reconstructs more accurately.
- SOS Operator: A special trained module that maps two sentence embeddings into a single “overlap” embedding. Uses a Bahdanau-attention combination of embeddings, then OffsetNet (Mai et al., 2020) to produce the final overlap vector.
Training:
- Autoencoder Pre-training: Denoising autoencoding on unlabeled text, optimizing ROUGE-based reconstruction.
- SOS Operator: Learns to produce overlap embeddings, aided by an adversarial term ensuring outputs lie within the autoencoder’s manifold.
- Data: Synthetic sentence-level pairs derived from CNN/DailyMail with ChatGPT to generate partial overlaps. Does not say how many tokens.
No models are available to download.
4) Contra Bottleneck T5 (Lee. 2023)
Aim: A random set of models only on HuggingFace Hub and a Google Colab, by Linus Lee 2023. Used to show how T5 can do auto-encoding with a single vector.
Architecture: They modify T5’s standard encoder–decoder by compressing the encoder’s final output states into a single vector (by e.g. average pooling or special aggregator token). The decoder is the normal T5 decoder but cross-attention sees just that single vector.
Training: Cross-entropy on a subset of Wikipedia, not sure how many tokens.
Larger-scale Experiments
5) Vec2Text with Round-Trip Translations (Cideron et al. 2022) (Google Brain)
Aim: A single-vector Transformer-based autoencoder for sentence representations, trained to reconstruct text while preserving semantics. Yields a universal single-vector AE that does well on "controllability" and “embedding geometry.”
Architecture Encoder: Various, including one with T5-base (250M params, pretrained). Mean-pooling over encoder hidden states reduces the sequence into a single d-dimensional bottleneck vector (d ∈ {16, 64, 128, …, 512}).
Architecture Decoder: Various, including T5-base decoder, receiving only the single bottleneck vector as cross-attention memory. Includes a gating mechanism to handle the compressed input.
Training: Auto-encoding objective with cross-entropy loss on C4-derived dataset (10B tokens), plus machine-translated paraphrases. Three variants for Loss:
- (1) Standard AE (reconstruct input),
- (2) Denoising AE (word dropout)
- (3) Round-Trip Translation AE (original → translated → original target).
No models are available to download. Not be confused with the other model above called vec2text
6) SONAR: Sentence-Level Multimodal and Language-Agnostic Representations (Duquenne, et al. 2023) (Meta)
Aim: A multilingual and multi-modal sentence embedding model that encodes text and speech into a single fixed-size vector for cross-lingual and cross-modal understanding.
Architecture Encoder:
- Text Encoder: A 24-layer Transformer encoder (from NLLB 1B), where mean-pooling (or attention-pooling) collapses token representations into a single 1024-dimensional vector (the bottleneck).
- Speech Encoder: A 600M-parameter w2v-bert model, finetuned using a teacher–student alignment method to match text embeddings.
Architecture Decoder: 24-layer Transformer decoder (also from NLLB 1B), modified to cross-attend only to the bottleneck vector rather than per-token encoder states. An additional fine-tuning stage optimizes the decoder for better reconstruction and generation quality.
Training: Trained by Meta, so uses a large-scale multilingual data from NLLB (parallel corpora, backtranslations, mined text). Takes the original NLLB-1B model an fine-tunes on approx 100B tokens[1], the most out of any here, and has the largest text window, 512 tokens. Four training objectives:
- Translation loss (CrossEntropy of translation tokens)
- Denoising Auto-encoding (Reconstruction from noisy/masked input)
- MSE embedding alignment (between same sentence in different languages)
- Speech-Text alignment loss (Between text and audio of same sentence)
Available to download on HuggingFace Hub. I also made a google colab demo.
Other work I did not read deeply.
Some other sources that are related:
Bag-of-Vectors Autoencoders (Mai et al. 2021.)
- Instead of a single vector, the encoder outputs a variable number of vectors (like per token). The decoder sees that entire set, allowing more capacity for longer texts. They still do a basic reconstruction cross-entropy.
- Freed from the single-vector bottleneck, they can handle more complex tasks or longer inputs.
SemFormers: Language Models with Semantic Planning (Yin et. al 2024)
- A specialized Transformer post-training technique.
- They append “planning tokens” before the target text. They set the planning tokens to be the auto-encoded semantic representation of what the upcoming text should look like, and optimize using MSE loss. The target tokens then learn to use the "planning tokens" with their normal self-attention.
- They trained on a moderate internet-text corpus (details are sparse but I think tens of billions of tokens, ~125M parameters) and found better performance on tasks that involve explicit planning, such as graph-traversal and path finding. (possibly some other things but I didn't read it tbh)
List of other papers
Below are some even more brief mentions of some papers that I did not read deeply:[2]
- SALSA: Semantically-Aware Latent Space Autoencoder (Kirchoff et al. 2023)
- Is used for embedding molecule text, not natural language
- Plug and Play Autoencoders for Conditional Text Generation (Mai et al., 2020)
- Uses RNN and LSTMs. Small dataset sizes
- Improve Variational Autoencoder for Text Generation with Discrete Latent Bottleneck (Zhao et al. 2020)
- Uses LSTMs, and discretizes the "single vector" outputs.
- A Probabilistic Formulation of Unsupervised Text Style Transfer (He et al. 2020)
- Uses LSTMs
- Educating Text Autoencoders: Latent Representation Guidance via Denoising (Shen et al. 2019)
- Uses LSTMs. They briefly mention trying transformers
- DialogWAE: Multimodal Response Generation with Conditional Wasserstein Auto-Encoder (Gu et al. 2018)
- Uses RNNs
- Generating Sentences from a Continuous Space (Bowman et al. 2015)
- Uses RNNs
- There and back again: Autoencoders for textual reconstruction (Oshri et. al 2015)
- Uses RNNs, tiny dataset of like 10k sentences.
- Enhancing EEG-to-Text Decoding through Transferable Representations
from Pre-trained Contrastive EEG-Text Masked Autoencoder (Wang et al. 2024)- Something about text auto encoders and EEGs, I didn't read it.
Brief Example of Use
SONAR is a model from August 2023, trained as a semantic text auto-encoder, converting text into semantic embed vectors, which can later be then decoded back into text. Additionally, the model is trained such that the semantic embed vectors are to some degree "universal" for different languages, and one can embed in French and decode in English.
I tried it, and SONAR seems to work surprisingly well. For example, the above paragraph and this paragraphs, if each are encoded into two 1024 dimensional vectors (one for each paragraph), the model returns the following decoded outputs:
SONAR is a model from August 2023, which is trained as a semantic text auto-encoder, converting text vectors into semantic embedded vectors, which can then be decoded back to text. In addition, the model is trained in such a way that semantic embedded vectors are somehow "universal" for different languages, and can be decoded into French and encoded into English.
I tried it, and it seems SONAR works surprisingly well. For example, the above paragraph and these paragraphs, if each is encoded in two 1024 dimensional vectors (one for each paragraph), the model returns the following decoded outputs.
Here is an example of the same paragraph encoded then decoded by all three models: SONAR, T5 Bottleneck, and Text2Vec respectively. The first two use dimension 1024, while the third uses dimension 1536.
SONAR:
Here is an example of the same paragraph coded and then decoded by all three models: SONAR, T5 bottleneck, and Text2Vec respectively. The first two use dimension 1024, while the third uses dimension 1536.
T5 Bottleneck:
This is an example of a decoded paragraph followed by the same three characters. Then the encoders: SONAR2, TomatoBox, and Text4Loaded use each dimension: the first uses 1025 pixels, while the second uses dimension 536.
Text2Vec (the "reveal as much as text" one, zero steps):
Here is an example of the same three models implemented in the first paragraph: the first one encoded to 1024 bytes, the second to 1532 bytes, and the third to 1536 bytes. Note that the dimension is the same for TENSEX, SON and VEX.
Most of these would be OK for my purposes, but SONAR seems to be the best.
Conclusion
Overall, there are definitely a range of papers implementing various single-vector Text AutoEncoders, but the largest one at the moment seems to be the SONAR model by Meta, being the largest training run. It may be worth testing the others better, but for my purposes I think the SONAR AutoEncoder model seems fine.
It seems plausible that the RNN or LSTM approaches might also work relatively well, considering the training objective is relatively well suited to them, but I have not deeply read the literature about them. There are likely some useful papers that I missed, but if you plan to use text auto-encoders I hope that this reference is useful.
If anyone is interested in using these, here is a Google Colab where you can try out using SONAR.
- ^
In the SONAR paper, they say "We trained our encoder-decoder model for 100k updates with same learning rate and batch size as NLLB training". I checked NLLB paper and I think they say batch size 1M tokens but they have many numbers floating around. Thus 100k times 1M = 100B Tokens
- ^
I avoided going too deep on non-transformer based text auto-encoders. This is not particularly principled, it might make perfect sense to have RNN or LSTM based text auto-encoders, but I don't have the time
5 comments
Comments sorted by top scores.
comment by Kenoubi · 2025-03-03T15:08:44.857Z · LW(p) · GW(p)
Wow, the SONAR encode-decode performance is shockingly good, and I read the paper and they explicitly stated that their goal was translation, and that the autoencoder objective alone was extremely easy! (But it hurt translation performance, presumably by using a lot of the latent space to encode non-semantic linguistic details, so they heavily downweighted autoencoder loss relative to other objectives when training the final model.)
I wonder how much information there is in those 1024-dimensional embedding vectors. I know you can jam an unlimited amount of data into infinite-precision floating point numbers, but I bet if you add Gaussian noise to them they still decode fine, and the magnitude of noise you can add before performance degrades would allow you to compute how many effective bits there are. (Actually, do people use this technique on latents in general? I'm sure either they do or they have something even better; I'm not a supergenius and this is a hobby for me, not a profession.) Then you could compare to existing estimates of text entropy, and depending on exactly how the embedding vectors are computed (they say 512 tokens of context but I haven't looked at the details enough to know if there's a natural way to encode more tokens than that; I remember some references to mean pooling, which would seem to extend to longer text just fine?), compare these across different texts.
Exploring this embedding space seems super interesting, in general, way more so on an abstract level (obviously it isn't as directly useful at this point) than the embedding space used by actual LLMs. Like, with only 1024 dimensions for a whole paragraph, it must be massively polysemantic, right? I guess your follow-on post (which this was just research to support) is implicitly doing part of this, but I think maybe it underplays "can we extract semantic information from this 1024-dimensional embedding vector in any way substantially more efficient than actually decoding it and reading the output?" (Or maybe it doesn't; I read the other post too, but haven't re-read it in light of this one.)
There also appears to be a way to attempt to use this to enhance model capabilities. I seem to think of one of these every other week, and again, I'm not a supergenius nor a professional ML researcher so I assume it's obvious to those in the field. The devil appears to be in the details; sometimes a new innovation appears to be a variant of something I thought of years ago, sometimes they come out of left field from my perspective, and in no case does there appear to be anything I, from my position, could have usefully done with the idea, so far. Experiments seem very compute-limited, especially because like all other software development in my experience, one needs to actually run the code and see what happens. This particular technique, if it actually works (I'm guessing either it doesn't, or it only works when scaled so large that a bunch of other techniques would have worked just as well and converged on the same implicit computations) might come with large improvements to interpretability and controllability, or it might not (which seems to be true for all the other ideas I have that might improve capabilities, too). I'm not advising anyone to try it (again, if one works in the field I think it's obvious, so either there are reasons not to or someone already is). Just venting, I guess. If anyone's actually reading this, do you think there's anything useful to do with this idea and others like it, or are they pretty much a dime a dozen, interesting to me but worthless in practice?
(Sorry for going on so long! Wish I had a way to pay a penny to anyone who thoughtfully reads this, whether or not they do anything with it.)
Replies from: Nicky, Kenoubi↑ comment by NickyP (Nicky) · 2025-03-04T00:20:22.598Z · LW(p) · GW(p)
Thanks for reading, and yeah I was also surprised by how well it does. It does seem like there is degradation in auto-encoding from the translation, but I would guess that it probably does also make the embedding space have some nicer properties
I bet if you add Gaussian noise to them they still decode fine
I did try some small tests to see how sensitive the Sonar model is to noise, and it seems OK. I tried adding gaussian noise and it started breaking at around >0.5x the original vector size, or at around cosine similarity <0.9, but haven't tested too deeply, and it seemed to depend a lot on the text.
There also appears to be a way to attempt to use this to enhance model capabilities
I meta's newer "Large Concept Model" paper they do seem to manage to train a model solely on Sonar vectors for training, though I think they also fine-tune the Sonar model to get better results (here is a draft distillation I did. EDIT: decided to post it). It seems to have some benefits (processing long contexts becomes much easier), though they don't test on many normal benchmarks, and it doesn't seem much better than LLMs on those.
The SemFormers paper linked I think also tries to do some kind of "explicit planning" with a text auto-encoder but I haven't read it too deeply yet. I briefly gleamed that it seemed to get better at graph traversal or something.
There are probably other things people will try, hopefully some that help make models more interpretable.
can we extract semantic information from this 1024-dimensional embedding vector in any way substantially more efficient than actually decoding it and reading the output?
Yeah I would like for there to be a good way of doing this in the general case. So far I haven't come up with any amazing ideas that are not variations on "train a classifier probe". I guess if you have a sufficiently good classifier probe setup you might be fine, but it doesn't feel to me like something that works in the general case. I think there is a lot of room for people to try things though.
I wonder how much information there is in those 1024-dimensional embedding vectors... [Is there] a natural way to encode more tokens
I don't think there is any explicit reason to limit to 512 tokens, but I guess it depends how much "detail" needs to be stored. In the Large Concept Models paper, the experiments on text segmentation did seem to degrade after around ~250 characters in length, but they only test n-gram BLEU scores.
I also guess that if you had a reinforcement loop setup like in the vec2text inversion paper, that you could probably do a good job getting even more accurate reconstructions from the model.
Exploring this embedding space seems super interesting
Yeah I agree, while it is probably imperfect, I think it seems like an interesting basis.
↑ comment by Kenoubi · 2025-03-05T20:05:32.342Z · LW(p) · GW(p)
Since it was kind of a pain to run, sharing these probably minimally interesting results. I tried encoding this paragraph from my comment:
I wonder how much information there is in those 1024-dimensional embedding vectors. I know you can jam an unlimited amount of data into infinite-precision floating point numbers, but I bet if you add Gaussian noise to them they still decode fine, and the magnitude of noise you can add before performance degrades would allow you to compute how many effective bits there are. (Actually, do people use this technique on latents in general? I'm sure either they do or they have something even better; I'm not a supergenius and this is a hobby for me, not a profession.) Then you could compare to existing estimates of text entropy, and depending on exactly how the embedding vectors are computed (they say 512 tokens of context but I haven't looked at the details enough to know if there's a natural way to encode more tokens than that; I remember some references to mean pooling, which would seem to extend to longer text just fine?), compare these across different texts.
with SONAR, breaking it up like this:
sentences = [
'I wonder how much information there is in those 1024-dimensional embedding vectors.',
'I know you can jam an unlimited amount of data into infinite-precision floating point numbers, but I bet if you add Gaussian noise to them they still decode fine, and the magnitude of noise you can add before performance degrades would allow you to compute how many effective bits there are.',
'(Actually, do people use this technique on latents in general? I\'m sure either they do or they have something even better; I\'m not a supergenius and this is a hobby for me, not a profession.)',
'Then you could compare to existing estimates of text entropy, and depending on exactly how the embedding vectors are computed (they say 512 tokens of context but I haven\'t looked at the details enough to know if there\'s a natural way to encode more tokens than that;',
'I remember some references to mean pooling, which would seem to extend to longer text just fine?), compare these across different texts.']
and after decode, I got this:
['I wonder how much information there is in those 1024-dimensional embedding vectors.',
'I know you can encode an infinite amount of data into infinitely precise floating-point numbers, but I bet if you add Gaussian noise to them they still decode accurately, and the amount of noise you can add before the performance declines would allow you to calculate how many effective bits there are.',
"(Really, do people use this technique on latent in general? I'm sure they do or they have something even better; I'm not a supergenius and this is a hobby for me, not a profession.)",
"And then you could compare to existing estimates of text entropy, and depending on exactly how the embedding vectors are calculated (they say 512 tokens of context but I haven't looked into the details enough to know if there's a natural way to encode more tokens than that;",
'I remember some references to mean pooling, which would seem to extend to longer text just fine?), compare these across different texts.']
Can we do semantic arithmetic here?
sentences = [
'A king is a male monarch.',
'A bachelor is an unmarried man.',
'A queen is a female monarch.',
'A bachelorette is an unmarried woman.'
]
...
pp(reconstructed)
['A king is a male monarch.',
'A bachelor is an unmarried man.',
'A queen is a female monarch.',
'A bachelorette is an unmarried woman.']
...
new_embeddings[0] = embeddings[0] + embeddings[3] - embeddings[1]
new_embeddings[1] = embeddings[0] + embeddings[3] - embeddings[2]
new_embeddings[2] = embeddings[1] + embeddings[2] - embeddings[0]
new_embeddings[3] = embeddings[1] + embeddings[2] - embeddings[3]
reconstructed = vec2text_model.predict(new_embeddings, target_lang="eng_Latn", max_seq_len=512)
pp(reconstructed)
['A kingwoman is a male monarch.',
"A bachelor's is a unmarried man.",
'A bachelorette is an unmarried woman.',
'A queen is a male monarch.']
Nope. Interesting though. Actually I guess the 3rd one worked?
OK, I'll stop here, otherwise I'm at risk of going on forever. But this seems like a really cool playground.
Replies from: Nicky↑ comment by NickyP (Nicky) · 2025-03-06T00:25:59.317Z · LW(p) · GW(p)
Yeah it was annoying to get working. I now have added a Google Colab in case anyone else wants to try anything.
It does seem interesting that the semantic arithmetic is hit or miss (mostly miss).
comment by Joseph Miller (Josephm) · 2025-02-21T14:25:22.542Z · LW(p) · GW(p)
This is great, thanks. I think these could be very helpful for interpretability.