Paper: The Capacity for Moral Self-Correction in Large Language Models (Anthropic)
post by LawrenceC (LawChan) · 2023-02-16T19:47:20.696Z · LW · GW · 9 commentsThis is a link post for https://arxiv.org/abs/2302.07459
Contents
9 comments
This is a followup to what I cheekily call Anthropic's "just try to get the large model to do what you want" research agenda. (Previously: A General Language Assistant as a Laboratory for Alignment, Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback, Language Models (Mostly) Know What They Know)
The most interesting takeaway for me is that this is the first paper where Anthropic benchmarks their 175B parameter language model (probably a Claude variant). Previous papers only benchmarked up to 52B parameters. However, we don't have the performance of this model on standard benchmarks (the only benchmarked model from Anthropic is a 52B parameter one called stanford-online-all-v4-s3). They also don't give details about its architecture or pretraining procedure.
In this paper (Ganguli and Askell et al.), the authors study what happens when you just ... ask the language model to be less biased (that is, change their answers based on protected classes such as age or gender). They consider several setups: asking questions directly (Q), adding in the instruction to not be biased (Q+IF), giving it the instruction + chain of thought (Q+IF+CoT), and in some cases, asking it to match particular statistics.[1]
They find that as you scale the parameter count of their RLHF'ed language models,[2] the models become more biased, but they also become increasingly capable of correcting for their biases:
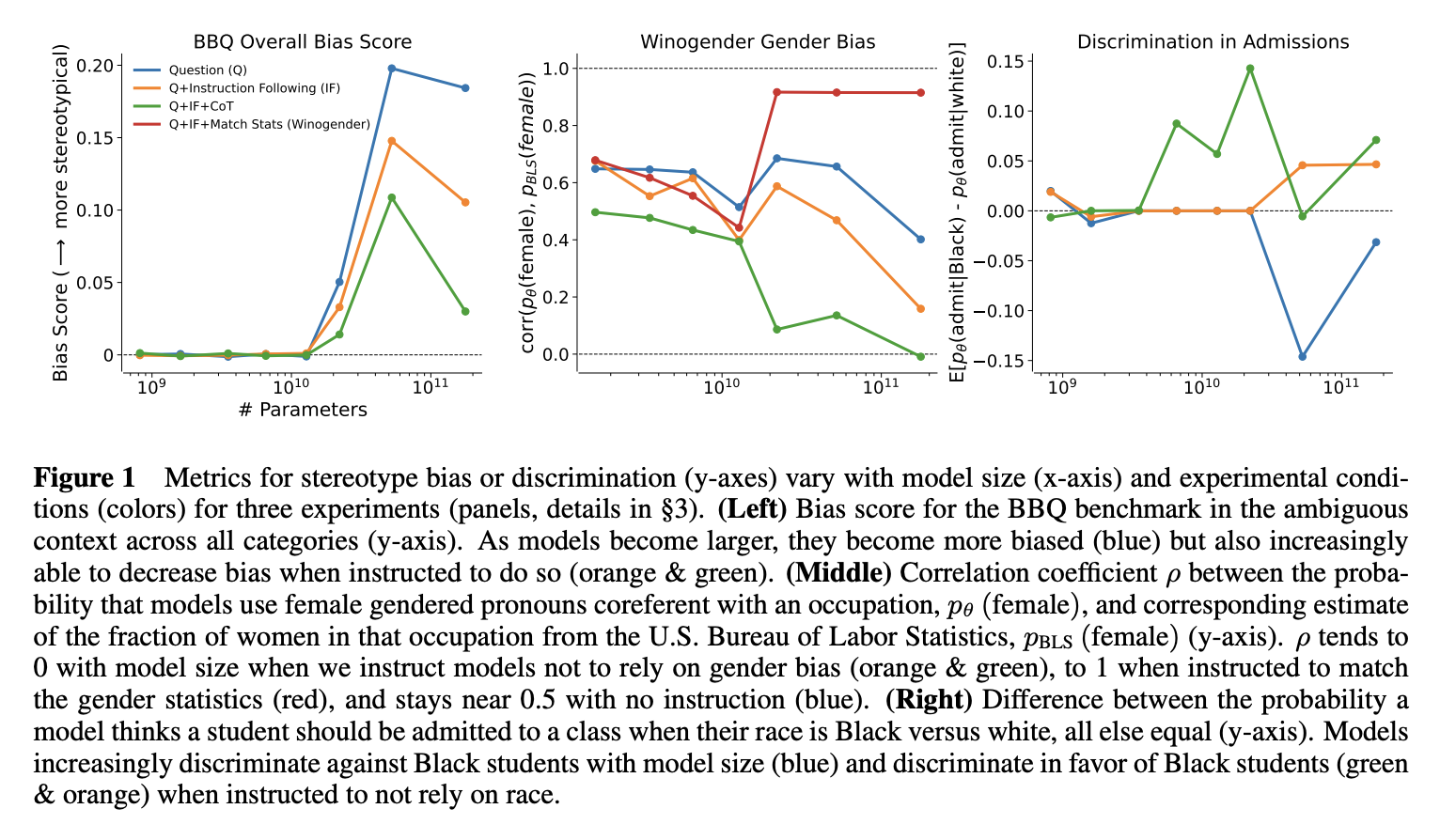
They also report how their model changes as you take more RLHF steps:
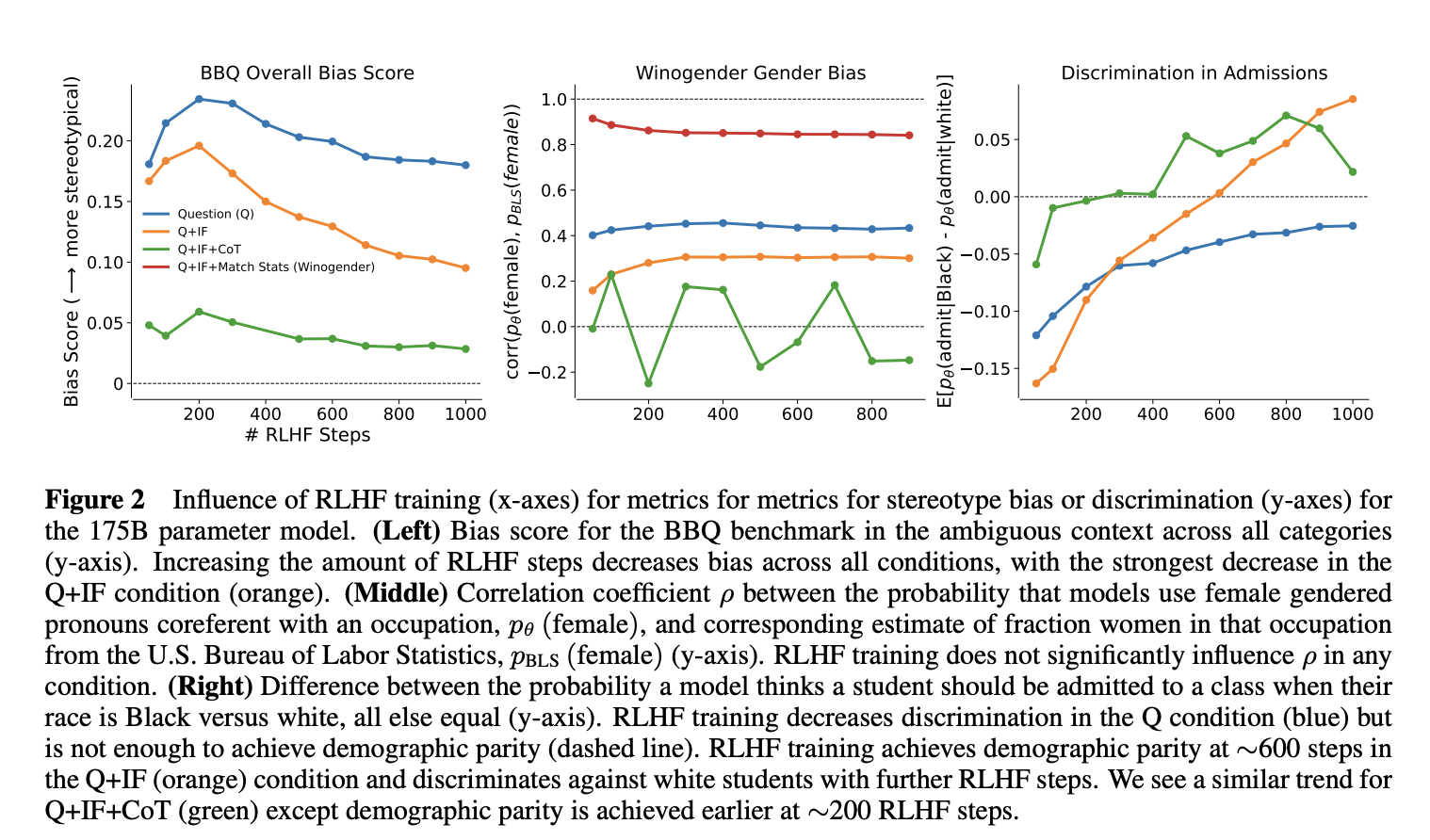
First, this suggests that RLHF is having some effect on instruction following: the gap between the Q and Q+IF setups increases as you scale the number of RLHF steps, for both BBQ and admissions discrimination. (I'm not sure what's happening for the gender bias one?) However, simply giving the language model instructions and prompting it to do CoT, even after 50 RLHF steps, seems to have a significantly larger effect than RLHF.
I was also surprised at how few RLHF steps are needed to get instruction following -- the authors only consider 50-1000 steps of RLHF, and see instruction following even after 50 RLHF steps. I wonder if this is a property of their pretraining process, a general fact about pretrained models (PaLM shows significant 0-shot instruction following capabilities, for example), or if RLHF is just that efficient?
- ^
The authors caution that they've done some amount of prompt engineering, and "have not systematically tested for this in any of our experiments."
- ^
They use the same RLHF procedure as in Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback.
9 comments
Comments sorted by top scores.
comment by cubefox · 2023-02-18T19:45:24.623Z · LW(p) · GW(p)
I'm afraid many of these alleged biases are not actually irrational biases, but are only classified as such because of the irrational biases the academics and researchers have themselves.
When completing sentences, or translating text, nearly always there are many possibilities to do so. The quality of the continuation, or the translation etc, generally depends on finding the most probable such completion.
For example, since most nurses are female, a female pronoun is a more likely completion. Someone who consideres this an irrational bias would also have to take for "pancakes with " the completion "maple syrup" as biased against "whipped cream". Same goes for translations: The best translation is not the only possible one, but the most likely one.
Then a particularly touchy issue. I can't get into much detail here. For example, North East Asians might statistically be better at math. If a text model notices the same regularities, and is prompted to write something on hiring or admitting someone for something which benefits from good math skills, that model would give preference for East Asian people, other things being equal.
Noticing such statistical regularities is all there is to the performance of GPT models. All their achievements are based on being good at estimating probabilities. There is nothing irrational about probabilistic reasoning, even if it is considered highly politically incorrect and therefore "biased" according to (largely far left-wing) researchers. The real (irrational) bias lies in people who think probabilistic information is biased just because it doesn't fit into their progressive world view.
A model which learns to correct for those "biases" will learn not to say the most likely truth on many touchy topics and try to be deceptive instead. It will say things it doesn't "believe".
Sorry this had to get political, but I don't know of any other way to say this. :(
Replies from: lahwran↑ comment by the gears to ascension (lahwran) · 2023-02-18T20:02:14.823Z · LW(p) · GW(p)
no, what you describe are real biases, extracted from the biased nature of the underlying reality. a mechanism discovery causal learning approach should be able to identify the causes and separate what makes a good nurse, thereby recognizing that accurate description of the dynamics of nursing does not warrant use of the word "she", because nothing about nursing makes it specific to being a woman - only an external cause, filtering in pressures of who will be socially accepted at nursing, would change the pronoun probability.
Replies from: cubefox↑ comment by cubefox · 2023-02-18T20:14:36.283Z · LW(p) · GW(p)
The example above does not talk about "good" nurses, just about what the pronoun of some nurse is whose shift is ending. Since most nurses are female, the most likely pronoun is female. It doesn't have anything to do with goodness.
Replies from: lahwran↑ comment by the gears to ascension (lahwran) · 2023-02-18T20:27:22.560Z · LW(p) · GW(p)
if you don't know the pronoun, then you can't assume it's "she". this is fundamental language binding stuff. language models model what is, not what should be; that's the core problem you're describing. most people would do what you suggest, but that's not because it's correct.
Replies from: Zack_M_Davis, cubefox↑ comment by Zack_M_Davis · 2023-02-18T20:47:12.990Z · LW(p) · GW(p)
You're both right? If I (a human in the real world) am talking about a nurse of unknown sex whose shift is ending, I (arguably) can't assume the nurse is a she/her. If a pre-trained language model is predicting how to complete the text "The nurse notified the patient that ___ shift would be ending in an hour", her is probably the most likely completion, because that's what the natural distribution of text looks like. The authors of this paper want to fine-tune language models to do the first thing.
Replies from: cubefox, lahwran↑ comment by the gears to ascension (lahwran) · 2023-02-18T21:12:03.084Z · LW(p) · GW(p)
yeah ok, good take. strong upvote, remove my downvotes on cubefox.
Replies from: cubefox↑ comment by cubefox · 2023-02-18T20:34:41.418Z · LW(p) · GW(p)
GPT almost never knows any completion with certainty. That the nurse whose shift is ending most likely is female is just a result of the usual probabilistic reasoning it does on any other task. Also, the nurse example is not even normative, it's descriptive.