The Geometry of Linear Regression versus PCA
post by criticalpoints · 2025-02-23T21:01:33.415Z · LW · GW · 7 commentsThis is a link post for https://eregis.github.io/blog/2025/02/23/geometry-pca-regression.html
Contents
7 comments
In statistics, there are two common ways to "find the best linear approximation to data": linear regression and principal component analysis. However, they are quite different---having distinct assumptions, use cases, and geometric properties. I remained subtly confused about the difference between them until last year. Although what I'm about to explain is standard knowledge in statistics, and I've even found well-written blog posts on this exact subject, it still seems worthwhile to examine, in detail, how linear regression and principal component analysis differ.
The brief summary of this post is that the different lines result from the different directions in which we minimize error:
- When we regress onto , we minimize vertical errors relative to the line of best fit.
- When we regress onto , we minimize horizontal errors relative to the line of best fit.
- When we plot the first principal component of and , we minimize orthogonal errors relative to the line of best fit.
To understand the difference, let's consider the joint distribution of heights for father-son pairs where both are adults. When you observe the distribution of heights among adult men, you'll notice two key things.
First, height in adult men is roughly normally-distributed. While some people are taller or shorter than average, there aren't 10ft tall people or 1ft tall people. The vast majority of adult men are somewhere between 5 feet and 7 feet tall. If you were to randomly sample adult males in the US and plot the data, it would form a bell-curve shaped graph like this one:
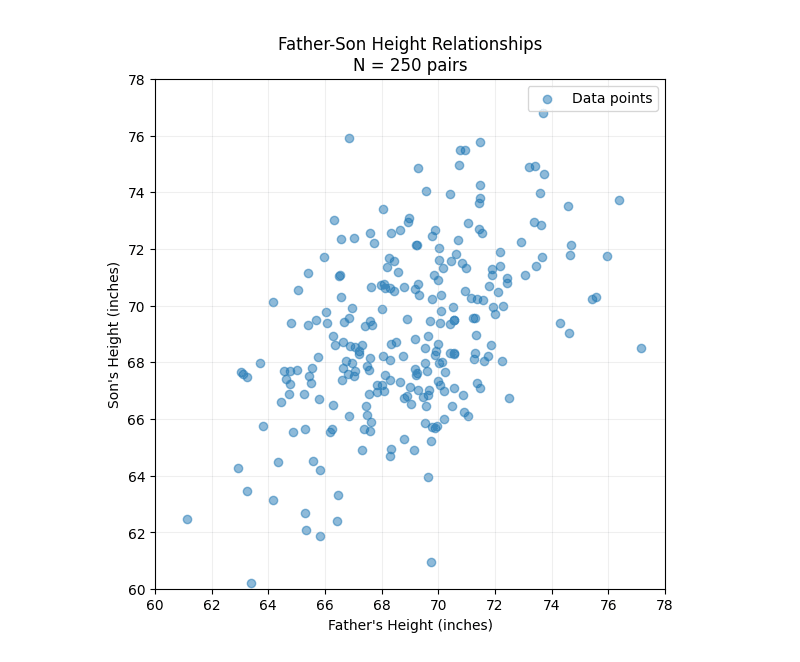
Second, height runs in families. While there is natural variation, people with taller parents tend to be taller than average. Quantitatively, the correlation between father-son height is around 0.5 (the exact value won't matter for this post).
We can create simulated data that would resemble the actual distribution of father-son heights. We'll make the following assumptions:
- Since we are only considering adult men, we'll assume the marginal distributions of fathers and sons are exactly the same. In reality, this wouldn't be quite true for various reasons (e.g., nutrition has changed over time), but it's close enough to true, and assuming this symmetry will help make certain conceptual points clearer.
- Both fathers and sons are normally distributed with a mean of 69 inches (5 foot 9 inches) and a standard deviation of three inches.
- The correlation between father and son heights is 0.5. Without delving into the math, this is straightforward to simulate because everything here is Gaussian: both variables are Gaussian and the independent error term is Gaussian. Since the sum of Gaussian random variables is another Gaussian random variable, it was simply a matter of tuning the error strength to get the desired correlation.
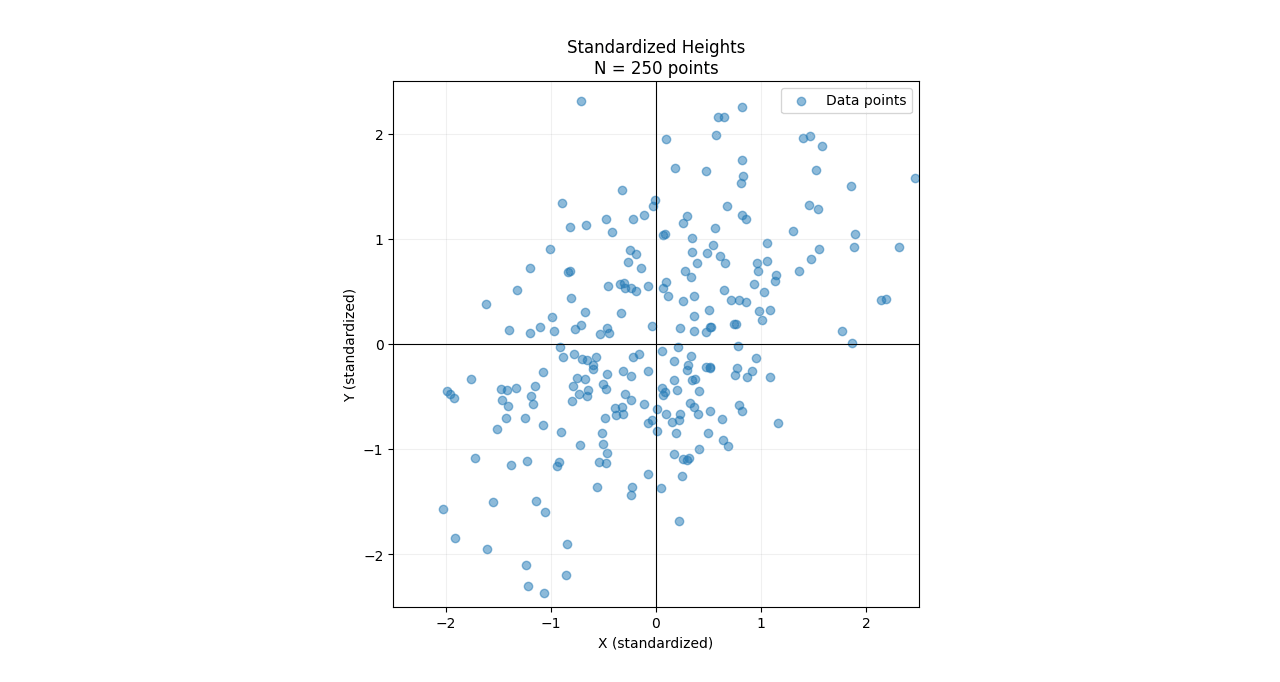
Before performing linear regression and principal component analysis, it helps to standardize the data. This involves: (1) centering the data so both distributions have a mean of zero, and (2) scaling the data so their variance equals 1. This transformation maps both distributions to standard Gaussians. Although we are transforming the data to make it easier to interpret, we preserve the 0.5 correlation between the two distributions. We will let be the standardized Gaussian random variable corresponding to the height of the father and be the standardized Gaussian random variable corresponding to the height of the son.
First, let's start with linear regression. When you regress onto , you are attempting to answer the question: "Given a value of , what is our best guess at the value of "? In our example, this means: "Given the height of the father, what is our best guess at the height of the son?"
"Best guess" is determined by the cost function. For linear regression, the cost function is the least-squares:
The regression line corresponds to the value (the slope of the line) which minimizes this cost function. The regression line then becomes:
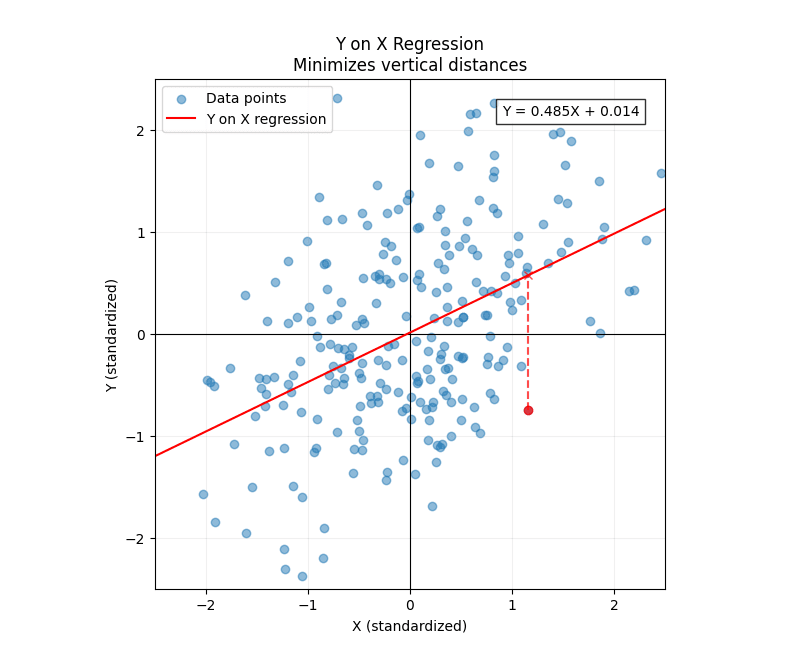
(A brief note: because we centered all our data, we will be ignoring intercepts for the duration of this post---all lines pass through the origin. Intercepts are straightforward to handle with least squares, and considering them doesn't add anything conceptually.)
For non-standardized random variables, the regression coefficient will have units of (this can be seen straightforwardly using dimensional analysis). The exact formula for the regression coefficient is:
But because we standardized our random variables, the variance of both and is 1. This effectively makes our regression coefficient dimensionless. And one can show that (in expectation), the regression coefficient equals the correlation coefficient. And sure enough, we can see in the plot above that the fitted regression coefficient is quite close to 0.5, the correlation coefficient we used to simulate the data (the small discrepancy is due to sampling error).
An important thing to highlight here is that the cost function measures errors vertically: it takes the predicted value and subtracts it from the actual value . This becomes especially clear if we substitute back into our cost function:
Now let's consider the converse case. When you regress onto , the roles of and switch: our task becomes: "Given a value of , what is our best guess at the value of "? In our example, that corresponds to the question: "Given the height of the son, what is our best guess at the height of the father?"
The cost function is now:
In this case, the errors are measured horizontally.
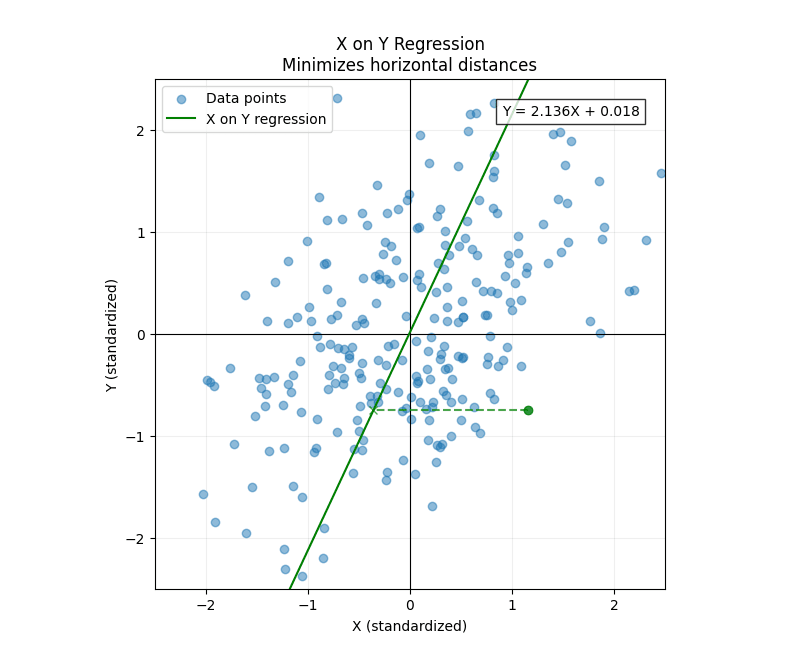
The two regression lines differ even though the data set is symmetric. Why?
Because each regression task measures errors in different directions. This explains not only why the two regression lines are different, but also the precise way they differ. Since least-squares is quadratic, it harshly punishes outliers. Therefore, the regression line for onto will have less variation in the direction because it needs to be conservative---that's why its slope is less than 1. Conversely, when we regress onto , the line will be compressed along the direction since it must be conservative along that axis. That's why its slope is greater than 1.
This becomes intuitive when we consider our example of father-son heights. If the father's height is 6 foot 3, our best guess for the son's height is 6 foot. This is given by our -on- regression line. And if the son's height is 6 foot 3, our best guess for the father's height is 6 foot. This is given by our -on- regression line.
We should expect to see regression to the mean regardless of whether we start with the father's height or the son's height. If the two regression lines were the same, then when the son's height is 6 foot, our best guess for the father's height would be 6 foot 3---which doesn't make sense.
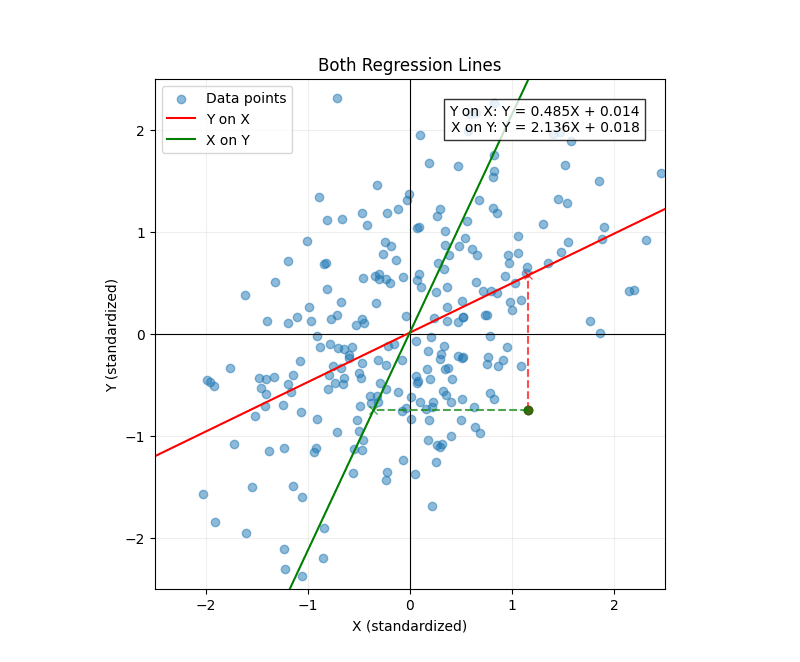
I think misconceptions often arise because we have a (correct) intuition that a problem is "symmetric," but then hastily leap to the wrong symmetry. It's tempting to see the inherent symmetry in this problem (the marginal distributions for father and son are the same) and assume the regression lines should be mathematically the same.
However, the task itself breaks the symmetry by designating one variable as the input (which we know precisely) versus the output (which is uncertain and what we are trying to predict). There is still a symmetry present, though: the regression lines are symmetric about the line .
Now we will consider principal component analysis. To borrow machine learning lingo: If linear regression is the grandfather of supervised learning, then principal component analysis is the grandfather of unsupervised learning. Instead of trying to predict one variable based on another, PCA aims to find the best model of the data's underlying structure.
If you squint a bit, you can see that our data sort of looks like an ellipse. A way to think about PCA geometrically is that the semi-major axis of this ellipse is the axis of the first principal component.
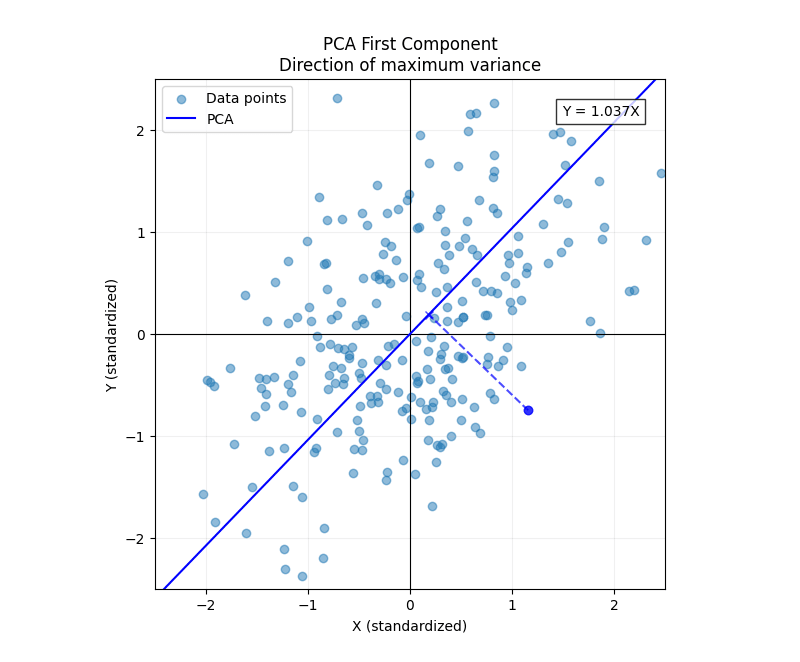
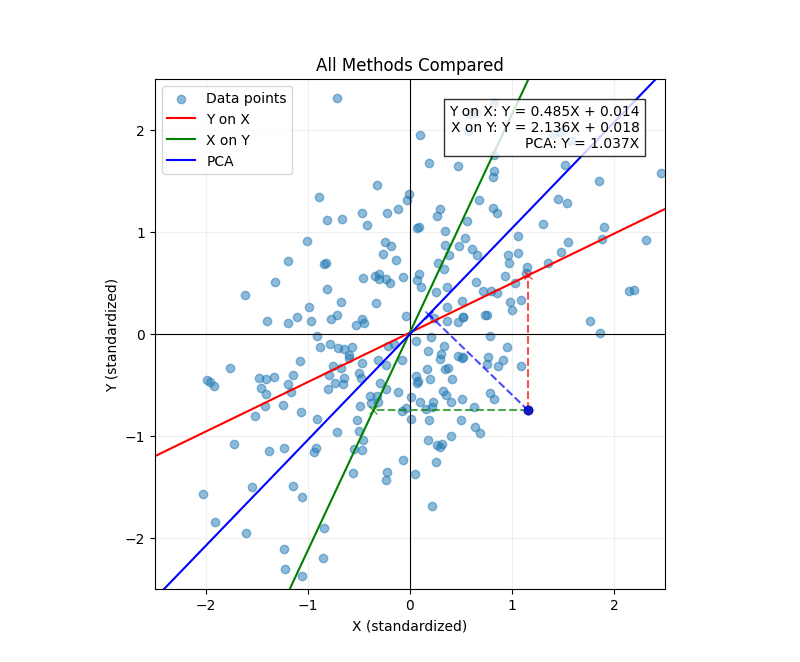
The PCA axis is the line . This makes sense as, unlike with linear regression, the task doesn't break the symmetry between and .
PCA is all about finding the direction that maximizes the variance of the data (as a proxy for explanatory power). It turns out that this is equivalent to finding the line that minimizes the sum of squared orthogonal projections. To show this equivalency, it's easiest to start with the orthogonal projection cost function.
This section will unfortunately require a bit more math than the previous sections. While linear regression lines are defined in terms of their minimizing cost functions, it will take more work to show that, for PCA, the orthogonal projection cost function is indeed the correct one.
Let be a vector representing some data point, and let be some unit vector in the plane. represents a direction which we are projecting the data onto. It's a basic fact of linear algebra that we can decompose every data point into its component parallel to and its component perpendicular to (which we will call ):
We want to minimize the squared magnitude of when summed over every data point. But first, it helps to express in a more convenient form. One can show that:
If we define the cost function as the sum of these orthogonal projections, we have:
In the last line, we used the fact that the sum of the squared lengths of the data points is independent of the direction of projection. Minimizing the orthogonal projection cost function is equivalent to maximizing the sum of ---which is precisely the variance of our data projected along the direction .
7 comments
Comments sorted by top scores.
comment by J Bostock (Jemist) · 2025-02-23T21:20:20.831Z · LW(p) · GW(p)
Furthermore: normalizing your data to variance=1 will change your PCA line (if the X and Y variances are different) because the relative importance of X and Y distances will change!
comment by tailcalled · 2025-02-23T21:35:22.249Z · LW(p) · GW(p)
I feel like the case of bivariate PCA is pretty uncommon. The classic example of PCA is over large numbers of variables that have been transformed to be short-tailed and have similar variance (or which just had similar/small variance to begin with before any transformations). Under that condition, PCA gives you the dimensions which correlate with as many variables as possible.
comment by Sebastian Gerety (sebastian-gerety) · 2025-04-03T08:35:38.029Z · LW(p) · GW(p)
Thank you for the insightful exploration of a alarming phenomenon of linear regression that had me stumped. I would love to see a conclusion to the explainer which might give guidance on settings where the different approaches are more or less appropriate. It currently leaves you looking for a "next page" button. We now understand why, but not what to do about it.
Replies from: criticalpoints↑ comment by criticalpoints · 2025-04-03T23:53:15.023Z · LW(p) · GW(p)
Thank you!
I'm not an expert on this topic, but my impression is that linear regression is useful for when you are trying to a fit a function from input to output (e.g imagine you have the alleles at various loci as your inputs and you want to predict some phenotype as your output. That's the type of problem well-suited for high-dimensional linear regression.) Whereas, for principle component analysis, it's mainly used as a dimensionality reduction technique (so using PCA for the case of two dimensions as I did in this post is a bit overkill.)
comment by XelaP (scroogemcduck1) · 2025-03-18T15:22:27.474Z · LW(p) · GW(p)
Great explanation! I was linked here by someone after wondering why linear regression was asymmetric. While a quick google and a chatGPT could tell me that they are minimizing different things, the advantage of your post is the:
- Pictures
- Explanation of why minimizing different things will get you slopes differing in this specific way (that is, far outliers are punished heavily)
- A connection to PCA that is nice and simply explained.
Thanks!
Replies from: criticalpoints↑ comment by criticalpoints · 2025-03-19T15:45:51.163Z · LW(p) · GW(p)
Thank you! That's very kind.
I got curious and asked Claude to explain the difference between regressing X-onto-Y and Y-onto-X and it did a really good job---which I found somewhat distressing. Is my blog post even providing any value when an LLM can reproduce 80-90% of the insight in literally a 1000th of the time?
But maybe there's still value in writing up the blog post because it's non-trivial to know what the right questions are to ask. I wrote this blog post because I knew that (a) understanding the difference between the two regression lines was important and (b) it was actually straightforward to explain the difference if you used the right framing. So perhaps there's still utility in having good taste in what questions are worth answering. At the very least, I personally benefited from writing up the post since it forced me to shore up my understanding.
Replies from: scroogemcduck1↑ comment by XelaP (scroogemcduck1) · 2025-03-20T19:07:08.118Z · LW(p) · GW(p)
Certainly, you have pictures! Pictures are great!