Defining Optimization in a Deeper Way Part 2
post by J Bostock (Jemist) · 2022-07-11T20:29:30.225Z · LW · GW · 0 commentsContents
The Dumb Thermostat The Smart Thermostat Quantitative Data The Continuous Thermostat Where does this leave us? None No comments
We have successfully eliminated the concepts of null actions and nonexistence from our definition of optimization. We have also eliminated the concept of repeated action. We are halfway there, and now have to eliminate uncertainty and absolute time. Then we will have achieved the goal of being able to wrap a 3D hyperplane boundary around a 4D chunk of relativistic spacetime and ask ourselves "Is this an optimizer?" in a meaningful way.
I'm going to tackle uncertainty next.
TL;DR I have allowed for a mor
We've already defined, for a deterministic system, that a joint probability distribution has a numerical optimizing-ness, in terms of entropy. Now I want to extend that to a non-joint probability distribution of the form . We can do this by defining and for the previous timestep.
We can then define as by stepping forwards from to as before, according to the dynamics of the system.
A question we might want to ask is, for a given and , how "optimizing" is the distribution ?
The Dumb Thermostat
Lets apply our new idea to the previous models, the two thermostats. Lets begin with uncorrelated, maximum entropy distributions.
For thermostat 1 we have the dynamic matrix:
(In this matrix, the entry for a cell represents the state at given the coordinates of that cell represent the state at )
With the distribution:
As an aside this has 3.2 bits of entropy.
Leading to the
distribution:
This gives us the "standard" distribution of:
And the "decorrelated" distribution is actually just the same as ! When we decorrelate the probabilities for and we just get back to the maximum entropy distribution and so
It's clear by inspection that the distributions and have the same entropy, so the decorrelated maximum entropy does not produce an "optimizing" distribution at .
If we actually consider the dynamics of this system, we can see that this makes sense! The temperature actually either stays at or falls into the cycle:
So there's no compression of futures into a smaller number of trajectories.
The Smart Thermostat
What about our "smarter" thermostat? This one has the dynamic matrix:
Well now our distribution looks like this:
Giving "standard" a of this:
And a "decorrelated" of:
Giving the decorrelated :
Now in this case, these two do have different entropies. has an entropy of 1.0 bits, and has an entropy of 2.1 bits. This gives us a difference of 1.1 bits of entropy. This is the Optimizing-ness we defined in the last post, but I think it's actually somewhat incomplete.
Let's also consider the initial difference between and . Decorrelating takes it from 2.2 to 3.0 bits of entropy. So the entropy difference started off at 0.8 bits. Therefore the difference of the difference in entropy is 0.3 bits.
The value of associated with is equal to . which can also be expressed as . We might call this quantity the adjusted optimizing-ness.
Quantitative Data
The motivation for this was that a maximum entropy distribution is "natural" in some sense. This moves us towards not needing uncertainty. If we have a given state of a system, we might be able to "naturally" define a probability distribution around that state. Then we can measure the optimizing-ness of the next step's distribution.
What happens with a different condition? What if we have a distribution like this:
For some small epsilon in the second situation.
Now is like this:
So is:
While it is theoretically possible to decorrelate everything, calculate the next set of things, and keep going, it's a huge mess. Using values for epsilon between 0.1 and we can make the following plot between the entropy of and our previously defined adjusted optimizing-ness.
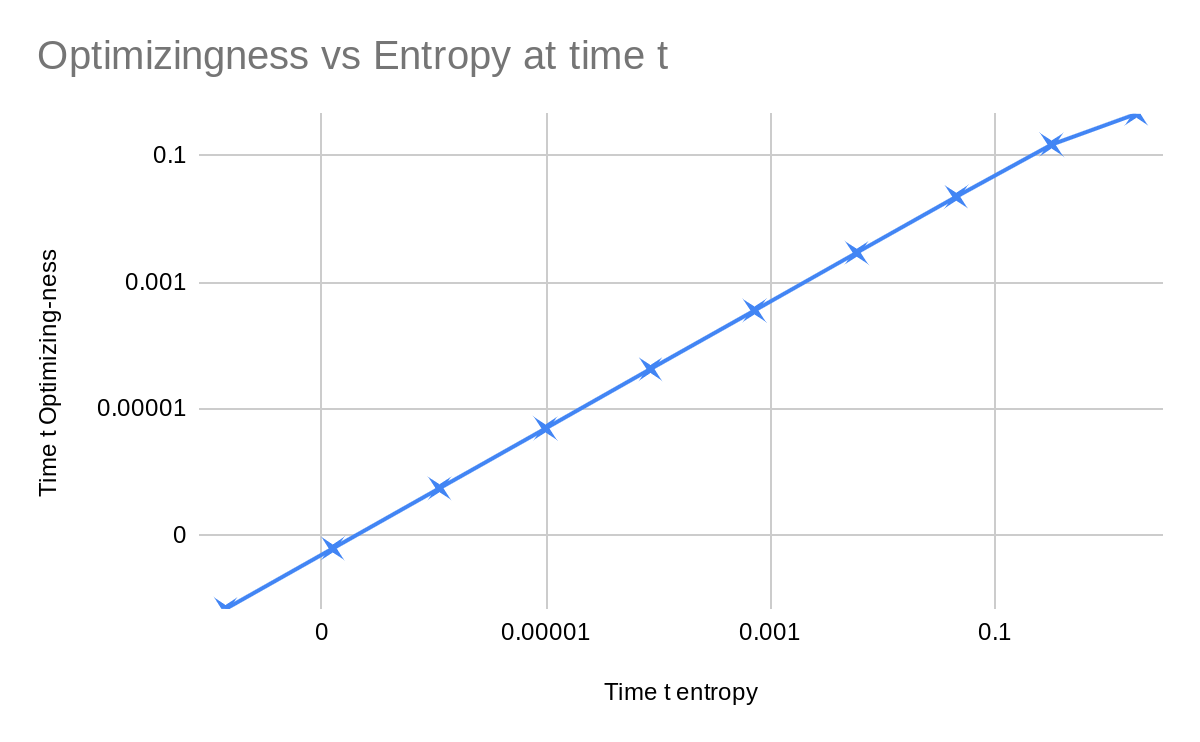
It looks linear in the log/log particularly in the region where is very small. By fitting to the leftmost five points we get a simple linear relation: The adjusted optimizing-ness approaches half of the entropy of .
This is kind of weird. This might not be an optimal system to study, so let's look at another toy example. A more realistic model of a thermostat:
The Continuous Thermostat
The temperature of the room is considered as . The activity of the thermostat is considered as . Each timestep, we have the following updates:
Consider the following distributions:
Where refers to a uniform distribution between and . can be thought of as a square of side length centered on the point . turns out to be a rhombus. The corners transform like this:
| Time = | Time = |
For the whole sequence looks like the following:
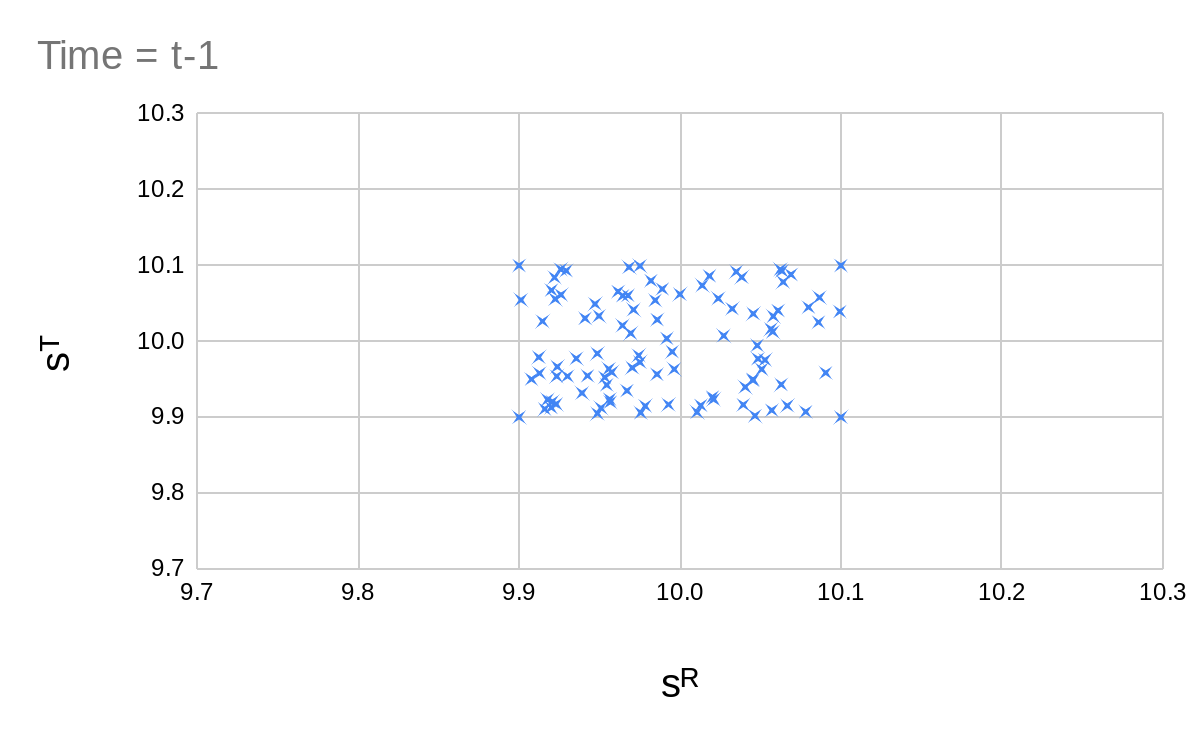
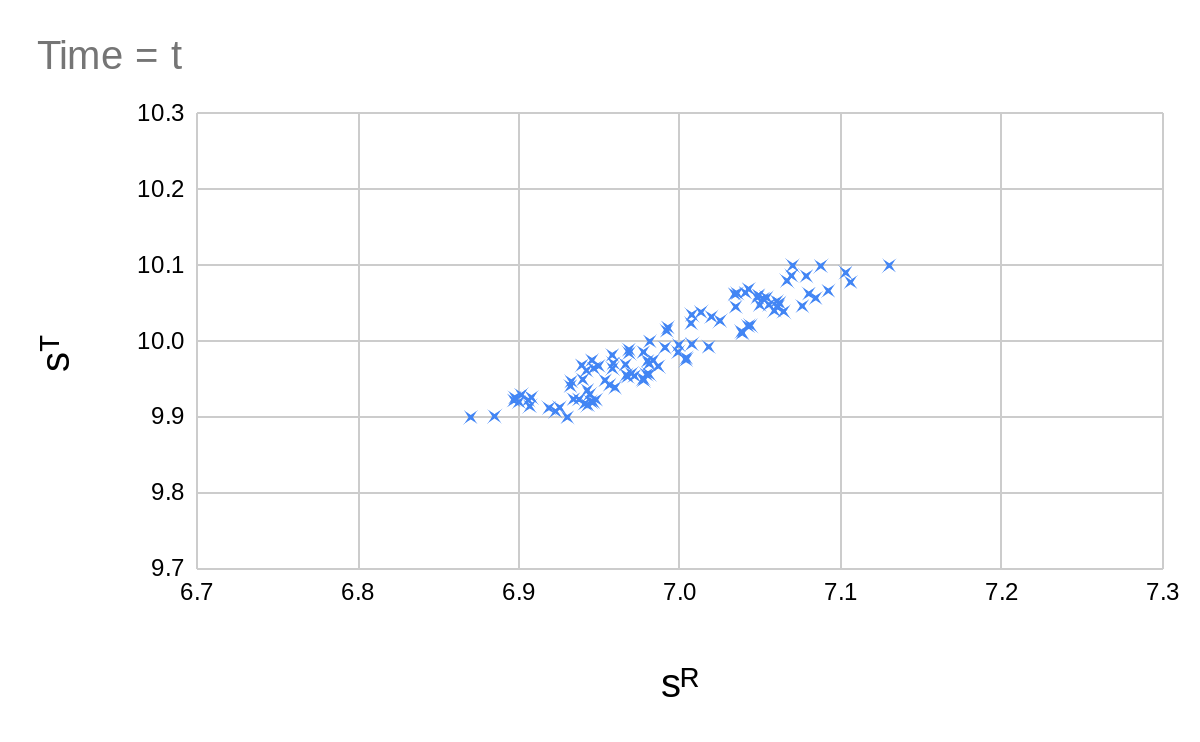
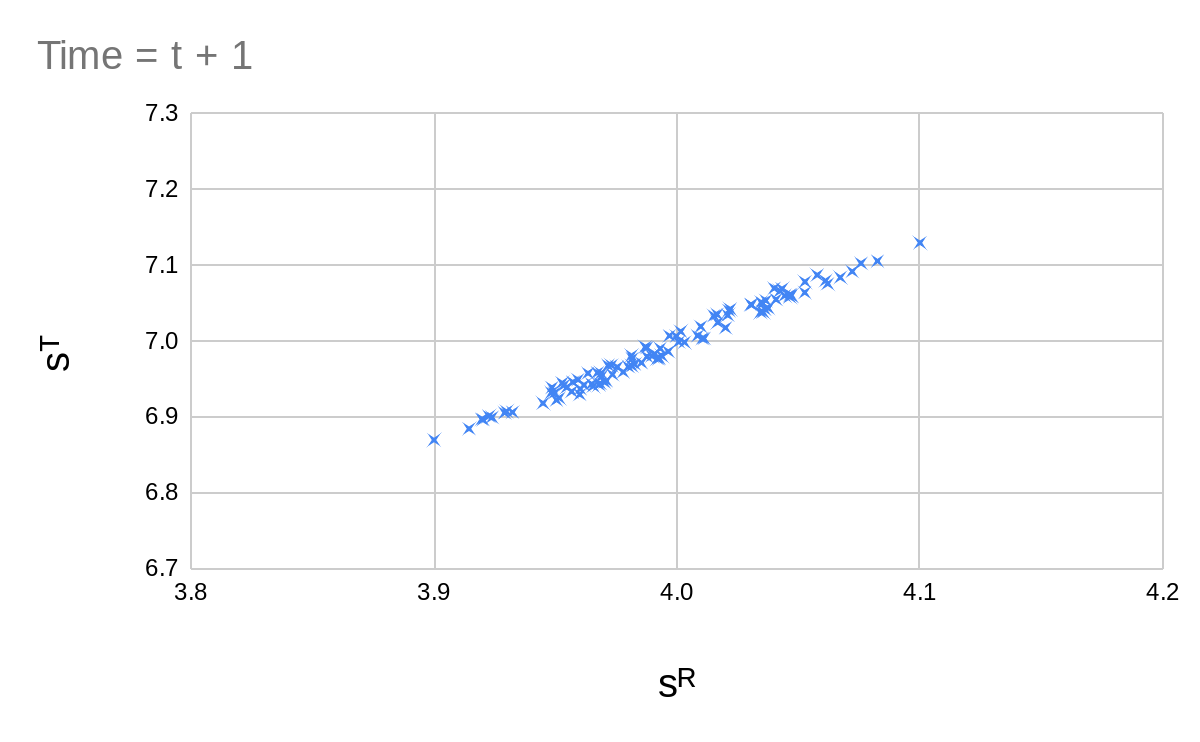
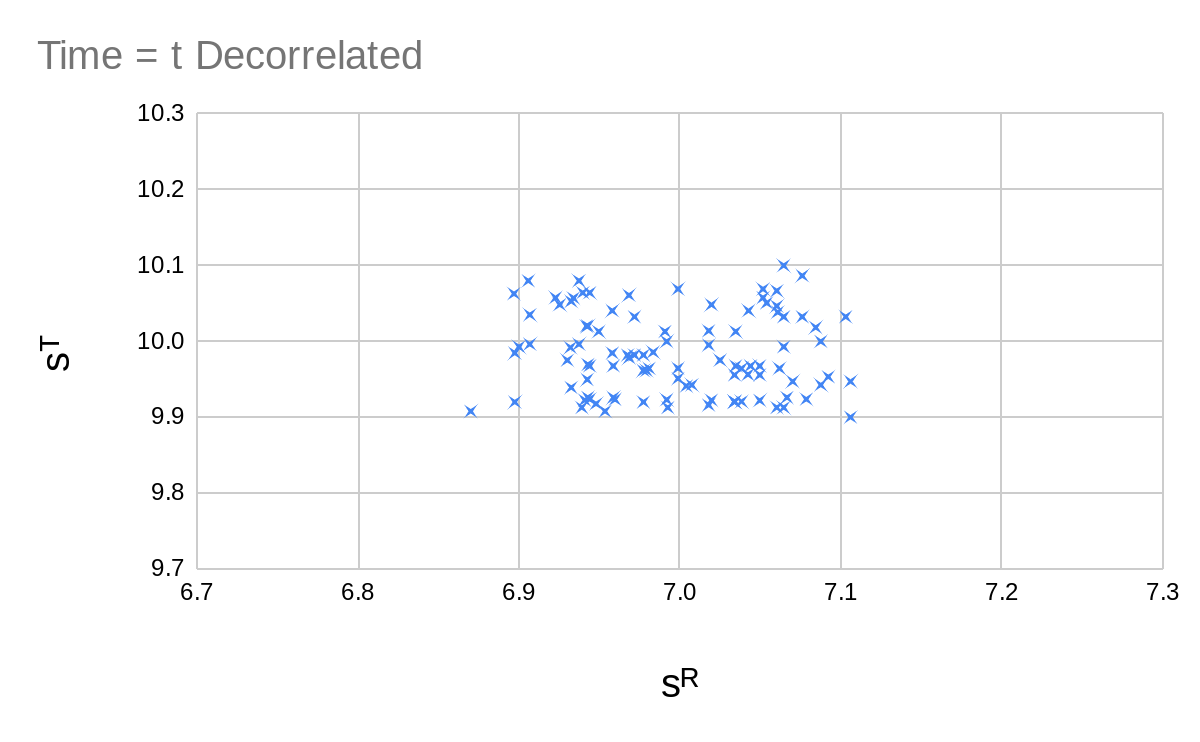
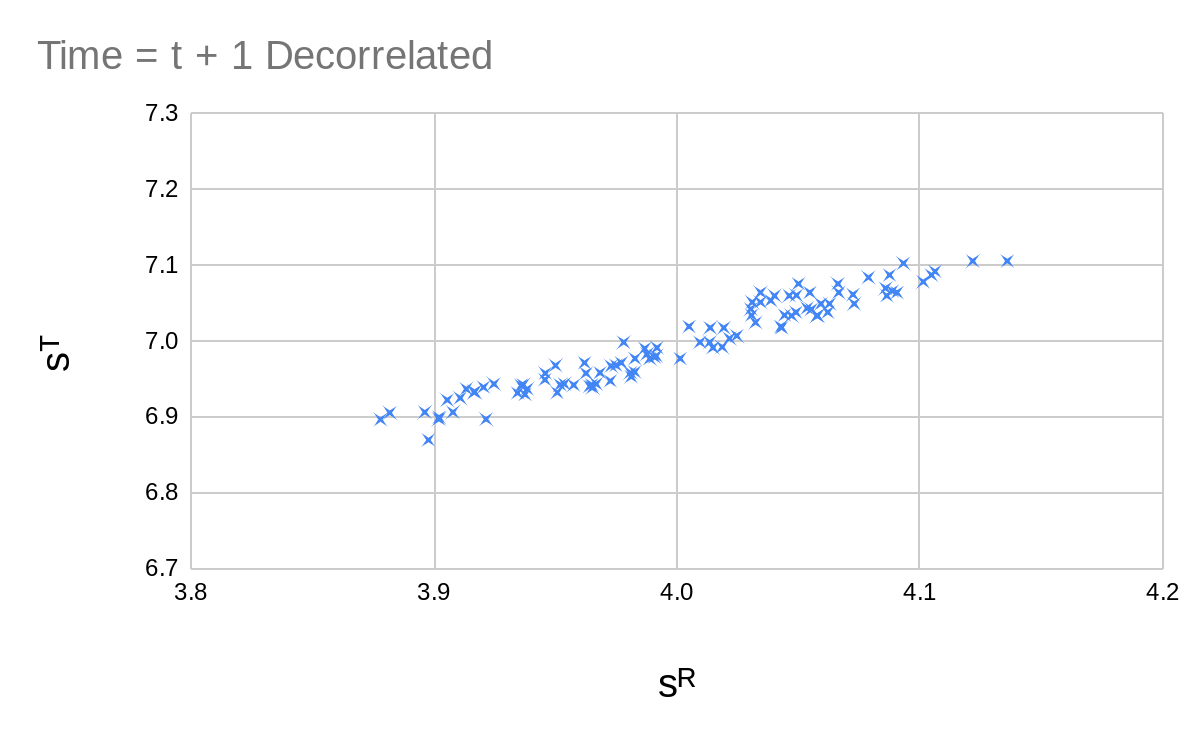
So we clearly have some sort of optimization going on here. Estimating or calculating the entropy of these distributions is not easy. And when we use the entropy of a continuous distribution, we get results which depend on the choice of coordinates (or alternatively the choice of some weighting function). Entropies of continuous distributions may also be negative, which is quite annoying.
Perhaps calculating the variance will leave us better off? Sadly not. I tried it for gaussians of decreasing variance and didn't get much. The equivalent to our adjusted optimizing-ness which we might define as is always zero for this system. The non-adjusted version fluctuates a lot.
Where does this leave us?
We can define whether something is an optimizer based on a probability distribution which need not be joint over and . This means we can define whether something is an optimizer for an arbitrarily narrow probability distribution, meaning we can take the limit as the probability distribution approaches a delta. We found an interesting relation between quantities in our simplified system but failed to extend it to a continuous system.
0 comments
Comments sorted by top scores.