Is AlphaGo actually a consequentialist utility maximizer?
post by faul_sname · 2023-12-07T12:41:05.132Z · LW · GW · No commentsThis is a question post.
Contents
TL;DR: does stapling an adaptation executor to a consequentialist utility maximizer result in higher utility outcomes in the general case, or is AlphaGo just weird? Why does the system with the SL policy network do so much better than the system without it? None Answers 23 gjm 8 Charlie Steiner None No comments
TL;DR: does stapling an adaptation executor to a consequentialist utility maximizer result in higher utility outcomes in the general case, or is AlphaGo just weird?
So I was reading the AlphaGo paper recently, as one does. I noticed that architecturally, AlphaGo has
- A value network: "Given a board state, how likely is it to result in a win". I interpret this as an expected utility estimator.
- Rollouts: "Try out a bunch of different high-probability lines". I interpret this as a "consequences of possible actions" estimator, which can be used to both refine the expected utility estimate and also to select the highest-value action.
- A policy network: "Given a board state, what moves are normal to see from that position". I interpret this one as an "adaptation executor" style of thing -- it does not particularly try to do anything besides pattern-match.
I've been thinking of AlphaGo as demonstrating the power of consequentialist reasoning, so it was a little startling to open the paper and see that actually stapling an adaptation executor to your utility maximizer provides more utility than trying to use pure consequentialist reasoning (in the sense of "argmax over the predicted results of your actions").
I notice that I am extremely confused.
I would be inclined to think "well maybe the policy network isn't doing anything important, and it's just correcting for some minor utility estimation issue", but the authors of the paper anticipate that response, and include this extremely helpful diagram:
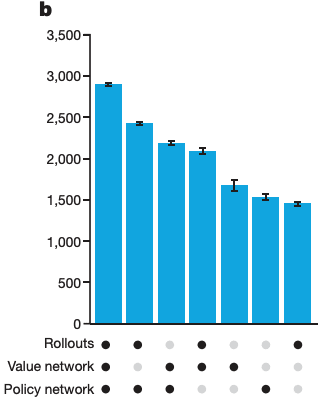
The vertical axis is estimated Elo, and the dots along the X axis label represent which of the three components were active for those trials.
For reference, the following components are relevant to the above graph:
- The fast rollout policy : a small and efficient but not extremely accurate network that predicts the probability that each legal move will be the next move, based on examining a fixed set of properties of the last move (e.g. "is this move connected to the previous move", "does the immediate neighborhood of this move/the previous move match a predetermined pattern"). Accuracy of 24.2%.
- The tree rollout policy : like the fast rollout policy, but adds three more features "move allows stones to be captured", "manhattan distance to last 2 moves", and a slightly larger pattern (12 point diamond instead of 3x3 pattern) around this move. Details of both and are given in extended data table 4 if you're curious.
- The SL policy network : a giant (by the standards of the time) 13 layer NN, pretrained on human games and then further trained through, if I'm reading the paper correctly, learning to imitate a separate RL policy network that is not used anywhere in the final AlphaGo system (because the SL policy network outperforms it)
- The value network : Same structure as the SL policy network except it outputs what probability the current board state has of being a win for the current player.
- Rollouts: Pretty standard MCTS
So my question:
Why does the system with the SL policy network do so much better than the system without it?
A couple hypotheses:
- Boring Answer: The SL policy network just helps to narrow the search tree. You could get better performance by running the value network on every legal move, and then transforming the win probability for each legal move into a search weight, but that would require running the value network ~19x19=361 times per move, which is a lot more expensive than running the SL policy network once.
- Policy network just adds robustness: A second, separately trained value network would be just as useful as the policy network.
- Bugs in the value network: the value network will ever-so-slightly overestimate the value of some positions, and ever-so-slightly underestimate the value of others, based on whether particular patterns of stones that indicate a win or loss are present. If there is a board state that is in fact losing, but the value network is not entirely sure that the position is losing, moves that continue to disguise the fact that it is losing will be rated higher than moves that in fact improve the win chance, but make the weakness of the position more obvious.
- Consequentialism doesn't work actually: There is some deeper reason that using the value network plus tree search not only doesn't work, but can't ever work in an adversarial setting.
- I'm misunderstanding the paper: AlphaGo doesn't actually use the SL policy network the way I think it does
- Something else entirely: These possibilities definitely don't cover the full hypothesis space.
My pet hypothesis is (3), but realistically I expect it's (5) or (6). If anyone can help me understand what's going on here, I'd appreciate that a lot.
Answers
I think it's a combination of (1) the policy network helps to narrow the search tree efficiently and (6) it's not quite true that the policy network is just doing a cheaper version of "try all the possible moves and evaluate them all" because "what are the best moves to search?" isn't necessarily quite the same question as "what moves look like they have the best win probability?". (E.g., suppose there's some class of moves that usually don't work but occasionally turn out to be very good, and suppose the network can identify such moves but not reliably tell which they are. You probably want to search those moves even though their win probability isn't great.)
On the latter point: In the training of AlphaGo and successors like KataGo, the training target for the policy network is something like "relative number of explorations below this node in the search tree". (KataGo does a slightly fancy thing where during training it deliberately adds noise at the root of the tree, leading to unnaturally many visits to less-good nodes, but it also does a slightly fancy thing that tries to correct for this.) In particular, the policy network isn't trained on estimated win rates or scores or anything like that, nor on what moves actually get played; it is trying to identify moves that when a proper search is done will turn out to be worth looking at deeply, rather than good or likely moves as such.
↑ comment by faul_sname · 2023-12-07T19:01:42.830Z · LW(p) · GW(p)
So if I'm understanding correctly:
The expected value of exploring a node in the game tree is different from the expected value of playing that node, and the policy network can be viewed as trying to choose the move distibution with maximal value of information.
And so one could view the outputs of the SL policy network as approximating the expected utility of exploring this region of the game tree, though you couldn't directly trade off between winning-the-game utility and exploring-this-part-of-the-game-tree utility due to the particular way AlphaGo is used (flat 5s of search per turn).
Thanks!
Edit: Actually I'm still confused. If I'm reading the paper correctly, the SL policy network is trained to predict what the RL network would do, not to do the thing which maximizes value of information. I'd be pretty surprised if those ended up being the same thing as each other.
Replies from: gwern, gjm, jco↑ comment by gwern · 2023-12-08T00:03:55.137Z · LW(p) · GW(p)
I'd be pretty surprised if those ended up being the same thing as each other.
Yes, there's several levels here, and it can get confusing which one you're fiddling with or 'exploring' in. This can make the (pre-DL) MCTS literature hard to read because it can get fairly baroque as you use different heuristics at each level. What is useful for making choices how to explore the tree to eventually make the optimal choice is not the same thing as just bandit sampling. (It's like the difference between best-arm finding and simple bandit minimizing regret: you don't want to 'minimize long-run regret' when you explore a MCTS tree, because there is no long run: you want to make the right choice after you've done a small number of rollouts, because you need to take an action, and you will start planning again.) So while you can explore a MCTS tree with something simple & convenient like Bayesian Thompson sampling (if you're predicting win rates as a binomial, that's conjugate and so is very fast), it won't work as well as something deliberately targeting exploration, or one which is budget-aware and tries to maximize the probability of finding best action within n rollouts.
↑ comment by gjm · 2023-12-07T23:52:03.830Z · LW(p) · GW(p)
Yes, the expected value of playing a move is not the same as the expected value of exploring it while searching. "Maximal value of information" would be nice but the training isn't explicitly going for that (I suspect that would be difficult), but for the simpler approximation of "how much was the subtree under this node looked at in a search?".
So the idea is: suppose that when looking at positions like this one, it turned out on average that the search spent a lot of time exploring moves like this one. Then this is probably a good move to explore.
This isn't the same thing as value of information. (At least, I don't think it is. Though for all I know there might be some theorems saying that for large searches it tends to be, or something?) But it's a bit like value of information, because the searching algorithm tries to spend its time looking at moves that are useful to look at, and if it's doing a good job of this then more-explored moves are something like higher-expected-value-of-information ones.
↑ comment by jco · 2023-12-08T15:37:46.217Z · LW(p) · GW(p)
Edit: Actually I'm still confused. If I'm reading the paper correctly, the SL policy network is trained to predict what the RL network would do, not to do the thing which maximizes value of information. I'd be pretty surprised if those ended up being the same thing as each other.
The SL policy network isn't trained on any data from the RL policy network, just on predicting the next move in expert games.
The value network is what is trained on data from the RL policy network. It predicts if the RL policy network would win or lose from a certain position.
I think we shouldn't read all that much into AlphaGo given that it's outperformed by AlphaZero/MuZero.
Also, I think the main probability is you misread the paper. I bet the ablation analysis takes out the policy network used to decide on good moves during search (not just the surface-level policy network used at the top of the tree), and they used the same amount of compute in the ablations (i.e. they reduced the search depth rather than doing brute-force search to the same depth).
I would guess that eliminating the fancy policy network (and spending ~40x more compute on search - not 361x, because presumably you search over several branches suggested by the policy) would in fact improve performance.
↑ comment by faul_sname · 2023-12-07T19:38:57.566Z · LW(p) · GW(p)
I would guess that eliminating the fancy policy network (and spending ~40x more compute on search - not 361x, because presumably you search over several branches suggested by the policy) would in fact improve performance.
I would guess that the policy network still outperforms. Not based on any deep theoretical knowledge, just based on "I expect someone at deepmind tried that, and if it had worked I would expect to see something about it in one of the appendices".
Probably worth actually trying out though, since KataGo exists.
Replies from: jco↑ comment by jco · 2023-12-08T15:58:46.184Z · LW(p) · GW(p)
I would guess that the policy network still outperforms.
I agree with this. If you look at Figure 5 in the paper, 5d specifically, you can get an idea of what the policy network is doing. The policy network's prior on what ends up being the best move is 35% (~1/3), which is a lot higher than the 1/361 a uniform prior would give it. If you assume this is average, this policy network would give ~120x linear speed-up in search. And this is assuming no exploration (i.e. the value network is perfect). Including exploration, I think the policy network would give exponential increases in speed.
Edit: Looking through the paper a bit more, they actually use a "tree policy", not a uniform prior, to calculate priors when "not using" the policy network, so what I said above isn't entirely correct. Using 40x the compute with this tree policy would probably (?) outperform the SL policy network, but I think the extra compute used on 40x the search would massively outweigh the compute saved by using the tree policy instead of the SL policy network. The value network uses a similar architecture to the policy network and a forward pass of both are run on every MCTS expansion, so you would be saving ~half the compute for each expansion to do ~40x the expansions.
No comments
Comments sorted by top scores.