Strategyproof Mechanisms: Possibilities
post by badger · 2014-06-02T02:26:29.399Z · LW · GW · Legacy · 4 commentsContents
Single-peaked preferences Discrete exchange Conclusion None 4 comments
Despite dictatorships being the only strategyproof mechanisms in general, more interesting strategyproof mechanisms exist for specialized settings. I introduce single-peaked preferences and discrete exchange as two fruitful domains.
Strategyproofness is a very appealing property. When interacting with a strategyproof mechanism, a person is never worse off for being honest (at least in a causal decision-theoretic sense), so there is no need to make conjectures about the actions of others. However, the Gibbard-Satterthwaite theorem showed that dictatorships are the only universal strategyproof mechanisms for choosing from three or more outcomes. If we want to avoid dictatorships while keeping strategyproofness, we’ll have to narrow our attention to specific applications with more structure. In this post, I’ll introduce two restricted domains with more interesting strategyproof mechanisms.
Before jumping into those, I should mention another potential escape route from Gibbard-Satterthwaite: randomization. So far, I’ve only considered deterministic social choice rules, where a type profile corresponds to a particular outcome. Considering randomized social choice rules—mapping a type profile onto a lottery over outcomes—will widen the scope of possibility just slightly. Instead of one person being the dictator, we can flip a coin to decided who is in charge. In particular, any strategyproof mechanism that chooses an outcome with certainty when all agents rank it as their first choice must be a random dictatorship, selecting among agents with some fixed probability and then choosing that agent’s favorite. Unlike a deterministic dictatorship, a random dictatorship with equal weights on agents seems palatable enough to use in practice.
Single-peaked preferences
Our first refuge from dictatorship theorems is the land of single-peaked preferences on a line, a tree, or more generally a median graph. These settings have enough structure on preferences that a mechanism doesn’t have to waste power eliciting rankings through dictatorship. Instead, we can deduce enough information from an agent’s ideal outcome that we have power left over to do something more interesting with a mechanism.
In the previous post, I discussed how strategyproofness comes down to the monotonicity of a social choice rule. Monotonicity says that if the outcome chosen by the rule is your favorite, the outcome can’t change if you report a different ranking with the same top element but with other options swapped around. This essentially restricts a strategyproof mechanism to using agents’ favorite alternatives as the only inputs.
With two alternatives to choose from, knowing an agent’s favorite immediately tells us their full ranking, so we have room to build non-dictatorial mechanisms like majority rule. With three alternatives and unrestricted preferences, knowing an agent’s favorite doesn’t tell us anything about the ranking of the other two. For example, suppose we have three options: red, yellow, and blue. If two agents agree that red is best, we don’t have enough information to unambiguously say whether switching from blue to yellow with make those agents better off or not.
What if instead the three alternatives had some natural ordering? For instance, some housemates have a terrible heating system with three settings: freezing, temperate, and burning. It’s reasonable to assume that anyone who loves it hot or cold has “temperate” as their second choice, with no one preferring both extremes to something in the middle. Moving the thermostat from “freezing” to “temperate” makes everyone who has “temperate” or “burning” as their ideal better off and those with “freezing” as their ideal worse off, allowing us to order the alternatives:

This ordering allows us to reduce the decision between three alternatives into a multiple binary decisions that will be consistent with one another. One strategyproof, non-dictatorial mechanism would be to start with the thermostat at “temperate” and hold a vote whether or not to increase the temperature. If a majority support a temperature increase, the thermostat is bumped up and we’re done. If that vote fails, another one is held for a temperature decrease, with the majority winner of that vote being the final outcome. Another mechanism that gives the same results would be for everyone to submit their ideal temperature and choose the median (with a dummy vote of “temperate” to break ties if there are an even number of housemates). Take a moment to convince yourself this mechanism is strategyproof.
The median vote is well-defined even if the thermostat has more than three temperatures. We can push this all the way and consider every possible temperature. With a continuum of outcomes, it’ll be easier to think in terms of a utility function rather than a ranking, though we’re still only concerned with ordinal comparisons. Choosing the median will be strategyproof as long as preferences are single-peaked, with a single local maximum and utility falling off as we go further in either direction away from it. Here is one example of a single-peaked preference, depicting the utility for each temperature:
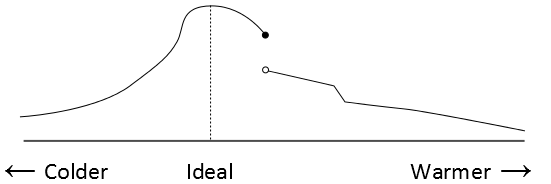
Since this agent has a complicated ranking over temperatures, asking agents to report only their peaks rather than their full utility function comes off as a practical advantage rather than a severe constraint.
Consider the thought process of someone deciding which temperature to report, knowing the median report will be chosen as the final outcome. If her ideal would be the median report (whether those are being made honestly or not), she has direct control over the outcome as long as she stays the median, so reporting something different makes her worse off. If her ideal is above the median, reporting something higher leaves the outcome unchanged. Reporting something lower either leaves the outcome unchanged or it makes the outcome drop even further away from her ideal than it already was. Similar reasoning goes through when her ideal is below the median. Hence she is never worse off for reporting her peak honestly. Contrast this with a mechanism that averages the peaks to get the outcome, which is not strategyproof.
Choosing an outcome on the real line has many natural applications like setting the temperature of a thermostat or the sales tax rate of a city. We can go further than lines though. For instance, single-peaked preferences make sense on a tree since we can talk unambiguously about going closer or further from some point as we move along the edges. Here is one tree, with an example of single-peaked preferences for it described by utilities for each node and the peak circled:
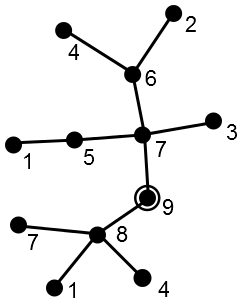
As on a line, we’ll ask agents to report their peaks and choose the median node, i.e. the node that minimizes the distance to each agent’s report. Suppose there are five agents, labeled a through e, and they report the following peaks:
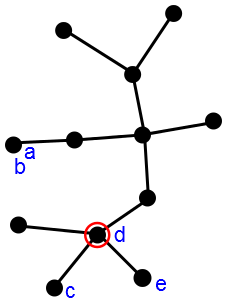
The outcome will be the node circled in red, resulting in agent d getting his first choice since he is the “median” of the five.
Going even further, there are non-dictatorial strategyproof mechanisms on any graph where medians are unique and well-defined. We can also tweak the median rule, throwing in some dummy voters or weighting agents differently. However, it turns out that the median is essentially the only strategyproof mechanism that treats agents and outcomes symmetrically.
Discrete exchange
In the previous examples, the mechanism chose a single outcome for all agents. Consider instead a situation where each agent owns one object and agents might want to swap things around. Rather than a single outcome, it makes more sense to think of sub-outcomes describing who gets which object, especially if each cares only about what he ends up with and not what the others get. Indifferences over parts of the allocation not involving that agent is another preference restriction that allows us to evade dictatorship theorems.
For example, three Roman soldiers have currently assigned duties which their eccentric new centurion will allow them to trade around. At the moment, Antonius is a standard-bearer, Brutus is a trumpeter, and Cato is an artilleryman. Even though the full outcome will be a list of who gets what, we consider only the preference of each over the three jobs. Perhaps Antonius has preferences trumpeter ≻ standard-bearer ≻ artilleryman, Brutus has preferences standard-bearer ≻ artilleryman ≻ trumpeter, and Cato has preferences trumpeter ≻ standard-bearer ≻ artilleryman. Given this, it’s natural to say Antonius and Brutus should switch jobs, with Cato stuck as an artilleryman.
We can formalize this inclination using David Gale’s Top Trading Cycle algorithm, which operates as follows:
- Each agent starts as active. Each object starts as active and pointing at the agent that owns it.
- Active agents point at their favorite active object.
- At least one cycle must exist from agent to object to agent and etc. Deactivate agents and objects in a cycle.
- Iterate steps 2 and 3 until all objects are deactivated. The final allocation is each object going to the agent pointing at it.
In the example, Antonius and Cato point at trumpeter, with Brutus pointing at standard-bearer. Deactivating the Antonius → trumpeter → Brutus → standard-bearer → Antonius cycle, only Cato is left active, so he points at his own job, and the mechanism is done.
As I’ve told the story, the soldiers already have control over a particular job. For instance, if Antonius liked being a standard-bearer best, he could guarantee he keeps the job. What would we do if the soldiers were new and didn’t have a pre-existing job? One option is to randomly assign tasks and run the algorithm from there. This is actually how New Orleans matches K-12 students with public schools as of 2012. Since the mechanism is strategyproof, parents don’t have to worry about gaming the system when they rank their top choices from the 67 schools in the district1. Unlike many of the toy examples I’ve given, here is a real-world case of improvements made by mechanism design.
Conclusion
By restricting preferences to be single-peaked or indifferent over the allocations of others, we can find useful strategyproof mechanisms. In the next post, I’ll continue exploring strategyproof mechanisms in the very fruitful special case when we can make transfers between agents, introducing the famed Vickrey-Clarke-Groves mechanisms.
The idea of single-peaked preferences on a line is quite old, dating back to Duncan Black in 1948. For a full characterization of strategyproof mechanisms on a line, see Moulin (1980). For a characterization of which single-peaked preference domains admit non-dictatorial, strategyproof mechanisms, see Nehring and Puppe (2007).
For an overview of mechanism design aspects of school choice, see Abdulkadiroglu and Sonmez (2003).
Previously on: Strategyproof Mechanisms: Impossibilities
Next up: Mechanism Design with Money
-
Though technically there might be a tiny reason to misrepresent preferences since the parents since the ranking is truncated to the top eight schools rather than all 67.↩
4 comments
Comments sorted by top scores.
comment by Manfred · 2014-06-05T23:00:43.973Z · LW(p) · GW(p)
Poor Cato.
Cato swapping with Brutus produces the same absolute gains as Antonius swapping with Brutus - is there a strategyproof mechanism that goes that way instead?
How about "a soldier can signal that they don't have the job they want. Then, the people who want to change jobs are ordered into a random loop, and jobs are rotated one place."
Hm, but if Antonius doesn't want his job either, we could end up with a bad outcome. Is Cato really hosed?
Replies from: badger↑ comment by badger · 2014-06-11T14:10:32.109Z · LW(p) · GW(p)
It turns out the only Pareto efficient, individually rational (ie everyone never gets something worse than their initial job), and strategyproof mechanism is Top Trading Cycles. In order to make Cato better off, we'd have to violate one of those in some way.