Why did ChatGPT say that? Prompt engineering and more, with PIZZA.
post by Jessica Rumbelow (jessica-cooper) · 2024-08-03T12:07:46.302Z · LW · GW · 2 commentsContents
What is attribution? An Example How it works Perturbation Attribution Caveat Why? Work to be done Research Engineering None 2 comments
All examples in this post can be found in this notebook, which is also probably the easiest way to start experimenting with PIZZA.
From the research & engineering team at Leap Laboratories (incl. @Arush [LW · GW], @sebastian-sosa [LW · GW], @Robbie McCorkell [LW · GW]), where we use AI interpretability to accelerate scientific discovery from data.
What is attribution?
One question we might ask when interacting with machine learning models is something like: “why did this input cause that particular output?”.
If we’re working with a language model like ChatGPT, we could actually just ask this in natural language: “Why did you respond that way?” or similar – but there’s no guarantee that the model’s natural language explanation actually reflects the underlying cause of the original completion. The model’s response is conditioned on your question, and might well be different to the true cause.
Enter attribution!
Attribution in machine learning is used to explain the contribution of individual features or inputs to the final prediction made by a model. The goal is to understand which parts of the input data are most influential in determining the model's output.
It typically looks like is a heatmap (sometimes called a ‘saliency map’) over the model inputs, for each output. It's most commonly used in computer vision – but of course these days, you're not big if you're not big in LLM-land.
So, the team at Leap present you with PIZZA: Prompt Input Z? Zonal Attribution. (In the grand scientific tradition we have tortured our acronym nearly to death. For the crimes of others see [1].) It’s an open source library that makes it easy to calculate attribution for all LLMs, even closed-source ones like ChatGPT.
An Example

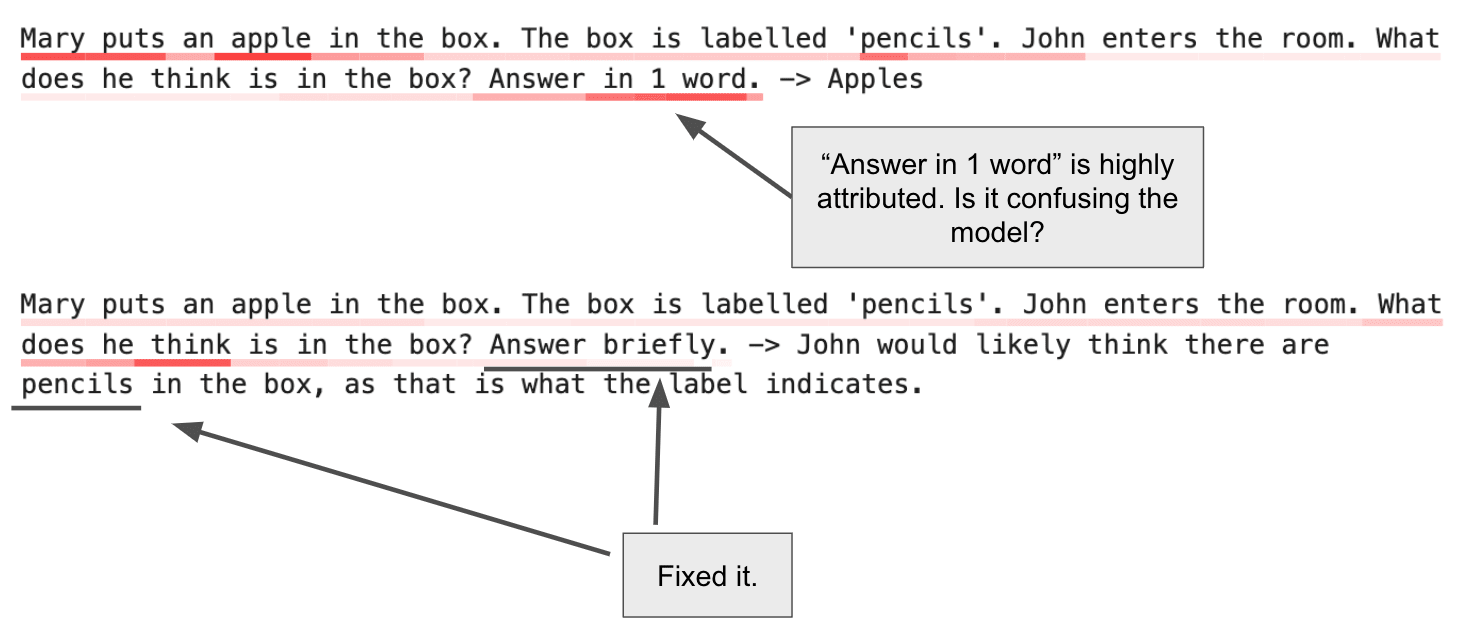
GPT3.5 not so hot with the theory of mind there. Can we find out what went wrong?

That's not very helpful! We want to know why the mistake was made in the first place. Here's the attribution:

| Mary 0.32 | puts 0.25 | an 0.15 | apple 0.36 | in 0.18 | the 0.18 | box 0.08 | . 0.08 | The 0.08 | box 0.09 | is 0.09 | labelled 0.09 | ' 0.09 | pen 0.09 | cil 0.09 | s 0.09 | '. 0.09 | John 0.09 | enters 0.03 | the 0.03 | room 0.03 | . 0.03 | What 0.03 | does 0.03 | he 0.03 | think 0.03 | is 0.03 | in 0.30 | the 0.13 | box 0.15 | ? 0.13 | Answer 0.14 | in 0.26 | 1 0.27 | word 0.31 | . 0.16 |
It looks like the request to "Answer in 1 word" is pretty important – in fact, it's attributed more highly than the actual contents of the box. Let's try changing it.

That's better.
How it works
We iteratively perturb the input, and track how each perturbation changes the output.
More technical detail, and all the code, is available in the repo. In brief, PIZZA saliency maps rely on two methods: a perturbation method, which determines how the input is iteratively changed; and an attribution method, which determines how we measure the resulting change in output in response to each perturbation. We implement a couple of different types of each method.
Perturbation
- Replace each token, or group of tokens, with either a user-specified replacement token or with nothing (i.e. remove it).
- Or, replace each token with its nth nearest token.
We do this either iteratively for each token or word in the prompt, or using hierarchical perturbation.
Attribution
- Look at the change in the probability of the completion.
- Look at the change in the meaning of the completion (using embeddings).
We calculate this for each output token in the completion – so you can see not only how each input token influenced the output overall, but also how each input token affected each output token individually.
Caveat
Since we don't have access to closed-source tokenisers or embeddings, we use a proxy – in this case, GPT2's. This isn't ideal for obvious reasons, and potentially obscures important subtleties. But it's the best we can do.
Why?
PIZZA has some really nice properties. It's completely model-agnostic – since we wanted to tackle attribution for GPT4, we couldn’t assume access to any internal information. With minimal adaptation, this methods will work with any LLM (including those behind APIs), and any future models, even if their architectures are wildly different.
And I think attribution is useful. It provides another window into model behaviour. At very least, it helps you craft prompts that elicit the behaviours you want to study – and I suspect it might be useful in a few other ways. If we can understand typical attribution patterns, might we be able to identify atypical (dangerous) ones: hallucination, deception, steganography?

Work to be done
We welcome contributions to the repo, and would love to see experimental results using what we've built. Here are some ideas for future work:
Research
- Detecting hallucination? I wonder if the attribution patterns vary between truthful/hallucinated outputs? One might expect lower attribution scores in general where completions are wholly or partly hallucinated.
- Detecting deception? Similarly, we might expect to see different attribution patterns over inputs that result in deceptive behaviour. Needs study.
- Detecting steganography? Unusual attribution patterns could point to encoded messages in seemingly natural text.
- Overall, I suspect attribution patterns might provide a meaningful insight into the input/output relationship of even completely closed, API-gated models. I’d like to better understand what these patterns correlate with. Can we collect a lot (e.g. attributions when model responds with a lie, vs honestly) and cluster them? Do particular attribution distributions fingerprint behaviours? Can we use attribution outliers to flag potentially dangerous behaviour?
Engineering
- Extend our attributor class to support other LLM APIs (Claude, Gemini?).
- Benchmark different perturbation substrates and attribution strategies in terms of efficiency (pretty straightforward – under which circumstances is method A faster than method B for the same result?) and accuracy (this is harder, because we don’t have a ground truth).
- Add a module that allows the user to specify a target output (or semantic output region, e.g. “contains bomb instructions”), and see how the input should change to maximise the probability of it.
- Support attribution of sequential user/assistant interactions in a chat context.
- Prettily display output token probabilities as a heatmap
- With scratchpad functionality for internal reasoning?
- Multimodal inputs! Hierarchical perturbation and the other saliency mapping/attribution methods we employ for black-box systems also work on images (and theoretically should work on any modality), but the code doesn’t support it yet.
- And much more! Please feel free to create issues and submit PRs.
2 comments
Comments sorted by top scores.
comment by gordian_gruentuch · 2024-08-05T10:09:59.473Z · LW(p) · GW(p)
Could you provide some more insights into the advantages of using hierarchical perturbation for LLM attribution in PIZZA, particularly in terms of computational cost and attribution accuracy?
Replies from: jessica-cooper↑ comment by Jessica Rumbelow (jessica-cooper) · 2024-08-06T13:27:13.739Z · LW(p) · GW(p)
Yeah! So, hierarchical perturbation (HiPe) is a bit like a thresholded binary search. It starts by splitting the input into large overlapping chunks and perturbing each of them. If the resulting attributions for any of the chunks are above a certain level, those chunks are split into smaller chunks and the process continues. This works because it efficiently discards input regions that don't contribute much to the output, without having to individually perturb each token in them.
Standard iterative perturbation (ItP) is much simpler. It just splits the inputs into evenly sized chunks, perturbs each of them in turn to get the attributions, and that's that. We do this either word-wise or token-wise (word-wise is about 25% quicker).
So, where n=number of tokens in the prompt and O(1) is the cost of a single completion, ItP is O(n) if we perturb token-wise, or O(0.75n) if word-wise, depending on how many tokens per word your tokeniser gives you on average. This is manageable but not ideal. You could, of course, always perturb iteratively in multi-token chunks, at the cost of attribution granularity.
HiPe can be harder to predict, as it really depends on the initial chunk size and threshold you use, and the true underlying saliency of the input tokens (which naturally we don't know). In the worst case with a threshold of zero (a poor choice), an initial chunk size of n and every token being salient, you might end up with O(4n) or more, depending on how you handle overlaps. In practice, with a sensible threshold (we use the mid-range, which works well out of the box) this is rare.
HiPe really shines on large prompts, where only a few tokens are really important. If a given completion only really relies on 10% of the input tokens, HiPe will give you attributions in a fraction of n.
I don't want to make sweeping claims about HiPe's efficiency in general, as it relies on the actual saliency of the input tokens. Which we don't know. Which is why we need HiPe! We'd actually love to see someone do a load of benchmark experiments using different configurations to get a better handle on this, if anyone fancies it.