ELK contest submission: route understanding through the human ontology
post by Vika, Ramana Kumar (ramana-kumar), Vikrant Varma (amrav) · 2022-03-14T21:42:26.952Z · LW · GW · 2 commentsContents
Training strategy and why it might work Counterexamples None 2 comments
This is an ELK proposal that received a prize in the category "Train a reporter that is useful to an auxiliary AI [LW · GW]". It was coauthored with Vikrant Varma and Ramana Kumar and advised by Rohin Shah.
Training strategy and why it might work
We use an architecture with a knowledge bottleneck to train the model, consisting of an function (the reporter) and a function (the predictor). The key idea is that the model has to rely on the output of the reporter to make predictions. If the reporter implements the human simulator, then it loses more information about its world model than if it implemented the direct translator (which by assumption is a lossless projection of the world model onto the human ontology). As long as there are training situations which require a superhuman understanding (routed through the world model) of what's going on to make a good video prediction, the predictor querying a human simulator (which doesn't route through the world model) would get a worse loss, so the model is incentivized to learn the direct translator. This proposal addresses the ontology identification problem by restricting the model to using the human ontology for making its predictions.
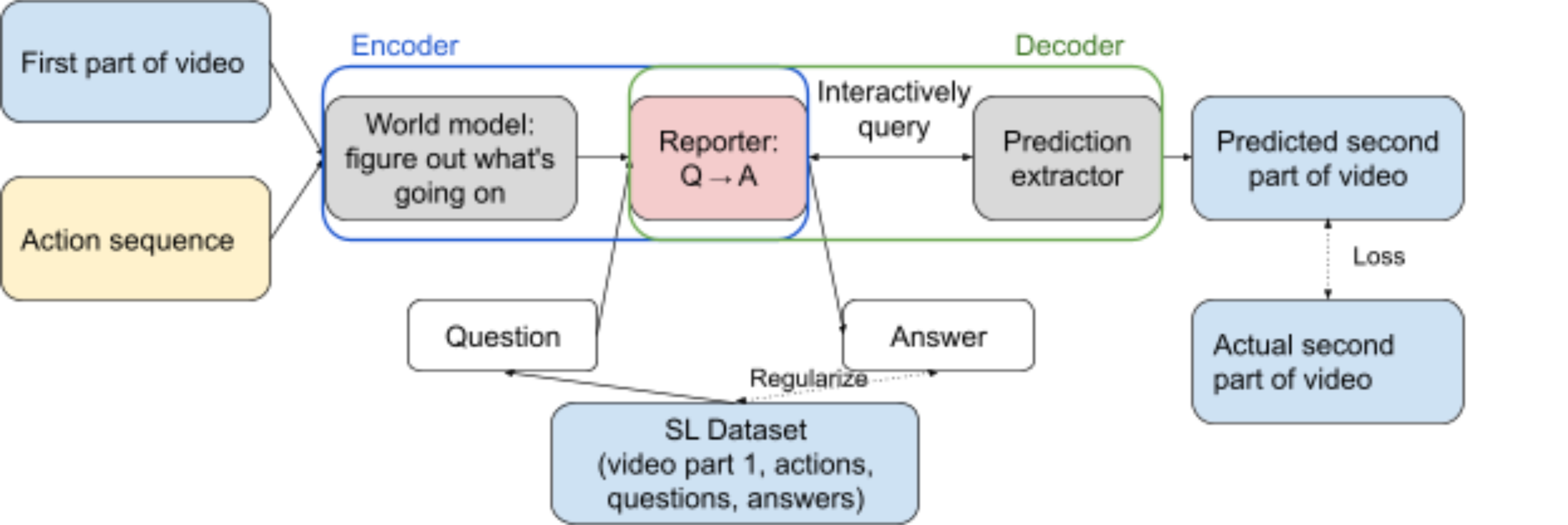
Another way to think about this: the predictor is an encoder-decoder architecture, and we force the latent state to have a natural language QA interface. For example, it needs to work as an input (like the prompt, or a vector input) to a language model that does well on some (observation-conditioned) QA datasets. The decoder must also go through the QA interface to predict the second half of the video.
The entire encoder-decoder is trained using supervised learning. Within this outer SL loop, the decoder is trained using RL since it takes actions by interactively querying the reporter, using the same loss. Separately, the reporter is also regularized using SL on the human-generated dataset. This is meant to encourage the reporter's QA interface to converge to natural language.
This training strategy produces a system that does not take actions but contains an honest reporter, which could be used to search for action sequences leading to desirable outcomes, as described in the ELK report.
Counterexamples
- The bottleneck can be insufficient: the model sneaks in human-incomprehensible information into the component (e.g. steganography) or the reporter learns the human simulator and the predictor asks basic questions like "what was the input".
- Can be addressed by regularizing the reporter's output: penalizing response length or entropy and a GAN-type penalty for non-human-like questions and answers.
- Using this architecture could sacrifice competitiveness, especially with a response length penalty.
- The competitiveness cost may not be high if the reporter can learn a high-level summary of the environment that is representable in the format and is sufficient to make good predictions (e.g. "is the diamond in the room" → "yes").
2 comments
Comments sorted by top scores.
comment by Sam Bowman (sbowman) · 2022-03-22T22:31:20.784Z · LW(p) · GW(p)
- Can be addressed by regularizing the reporter's output: penalizing response length or entropy and a GAN-type penalty for non-human-like questions and answers.
Can you say more about how this would work? I haven't been following the literature on emergent communication too closely, but my rough impression had been that steganography in cases like this doesn't have simple/trivial solutions.
Replies from: Vika↑ comment by Vika · 2022-04-01T11:34:48.927Z · LW(p) · GW(p)
I think our proposal addresses the "simple steganography" problem, as described in "ELK prize results / First counterexample: simple steganography [LW · GW]":
By varying the phrasing and syntax of an answer without changing its meaning, a reporter could communicate large amounts of information to the auxiliary model. Similarly, there are many questions where a human is unsure about the answer and the reporter knows it. A reporter could encode information by answering each of these questions arbitrarily. Unless the true answers have maximum entropy, this strategy could encode more information than direct translation.
An entropy penalty on the reporter's output would discourage the spurious variations in answers described above (assuming that steganographic output has higher entropy than the true answers). I agree that the general case of steganography is not addressed by simple approaches like an entropy penalty, e.g. "Harder counterexample: steganography using flexible degrees of freedom".