Exploring OpenAI's Latent Directions: Tests, Observations, and Poking Around
post by Johnny Lin (hijohnnylin) · 2024-01-31T06:01:27.969Z · LW · GW · 4 commentsContents
Exploration Tools Test 1: Find a Specific Concept - Red Red-eeming Our Search Red-oubling Our Efforts Red-oing It, But With Neurons Test 2: Extract Concepts From Text - The Odyssey The Journey Begins It's All Greek To Me Towards Monophemus From Hero... to Zero? Observations and Tidbits Questions Challenges and Puzzles Suggested Improvement Try It Yourself Run Your Own Tests and Experiments Upload Your Directions and Models Feedback, Requests, and Comments None 4 comments
TL;DR: Interactive exploration of new directions in GPT2-SMALL. Try it yourself.
OpenAI recently released their Sparse Autoencoder for GPT2-Small. In this story-driven post, I run experiments and poke around the 325k active directions to see how good they are. The results were super interesting, and I encountered more than a few surprises along the way. Let's get started!
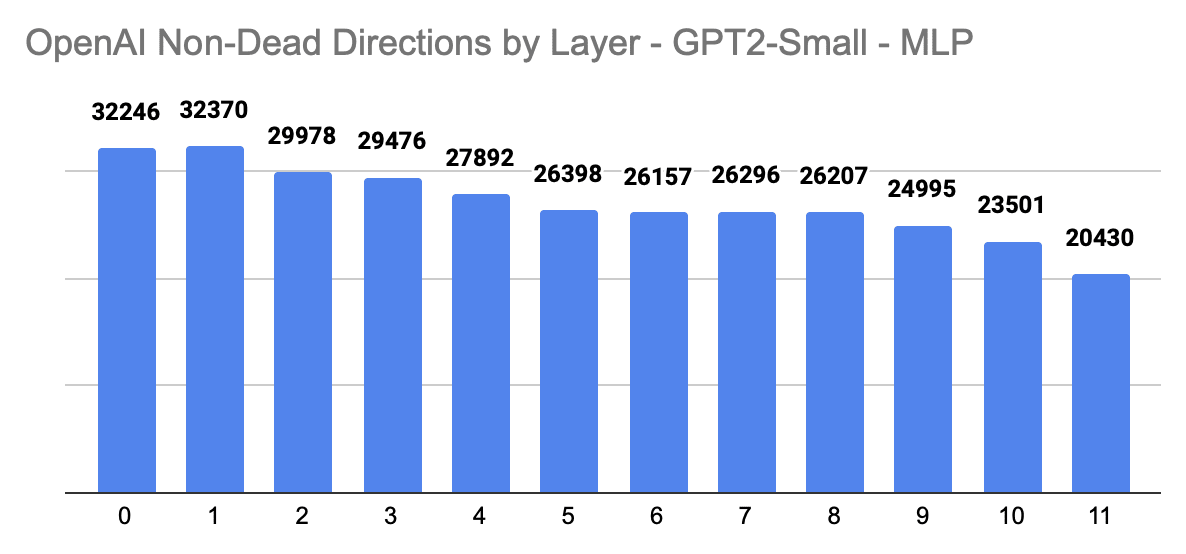
Exploration Tools
I uploaded the directions to Neuronpedia [prev LW post [LW · GW]], which now supports exploring, searching, and browsing different layers, directions, and neurons.
Let's do some experiments with the objective: What's in these latent directions? Are they any good?
Test 1: Find a Specific Concept - Red
For the first test, we'll look for a specific concept, and then benchmark the directions (and neurons) to look for monosemanticity and meaningfulness. We want to see directions/neurons that activate on a concept, not just the literal token. For example, a "kitten" direction should also activate for "cat".
For the upcoming Lunar New Year, let's look for the color "red", starting with directions.
On the home page, we type "red" into the search field, and hit enter:
In the backend, the search query is fed into GPT2-SMALL via TransformerLens. The output is normalized, encoded, and sorted by top activation.
After a few seconds, it shows us the top 25 directions by activation for our search:
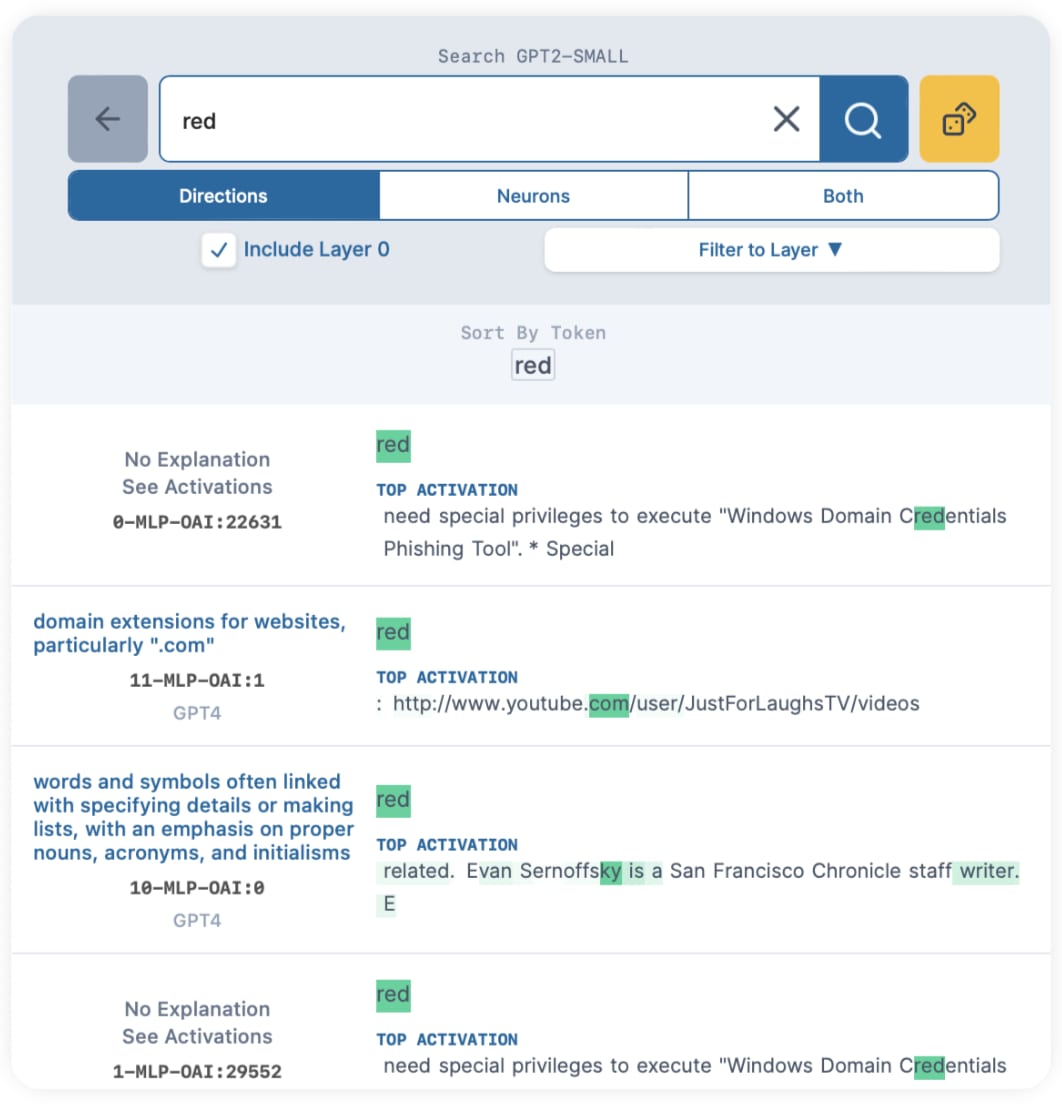
Unfortunately, the top results searching direction results don't look good. Uh-oh.
The top result, 0-MLP-OAI:22631, has a top activating token of "red" in the word "Credentials", which doesn't mean the color red. Clicking into it, we see that it's just indiscriminately firing on the token "red" - in domains, parts of words, etc. It does fire on the color red about 35% of the time, but that's not good enough.
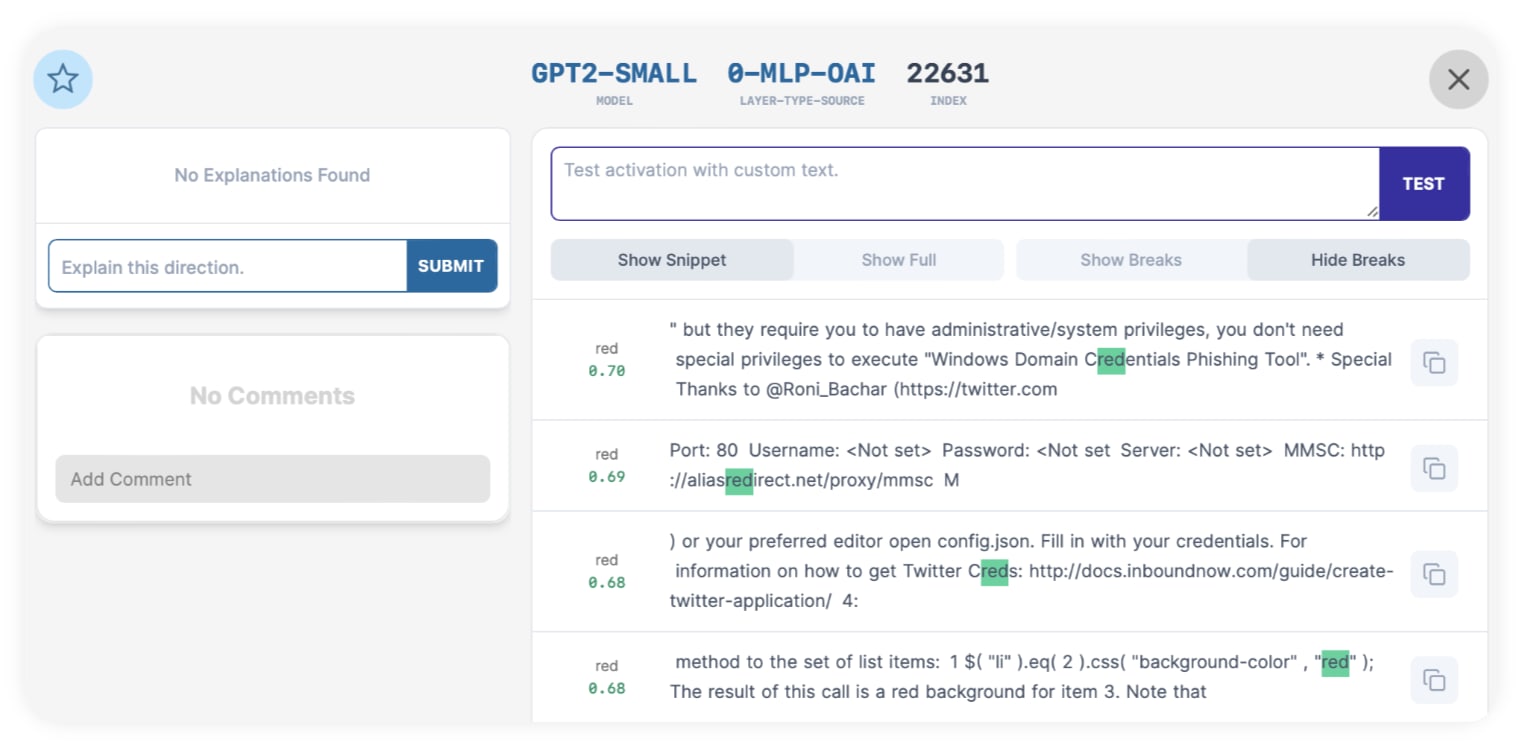
So our top direction result is monosemantic for "the literal token 'red'", but it's not meaningful for the color red. And other top results don't have anything to do with "red".
What went wrong?
Red-eeming Our Search
We searched for "red", and the machine literally gave us "red". Like many other problems that we encounter with computers, PEBKAC. In LLM-speak: our prompt sucked.
Let's add more context and try again: "My favorite color is red."
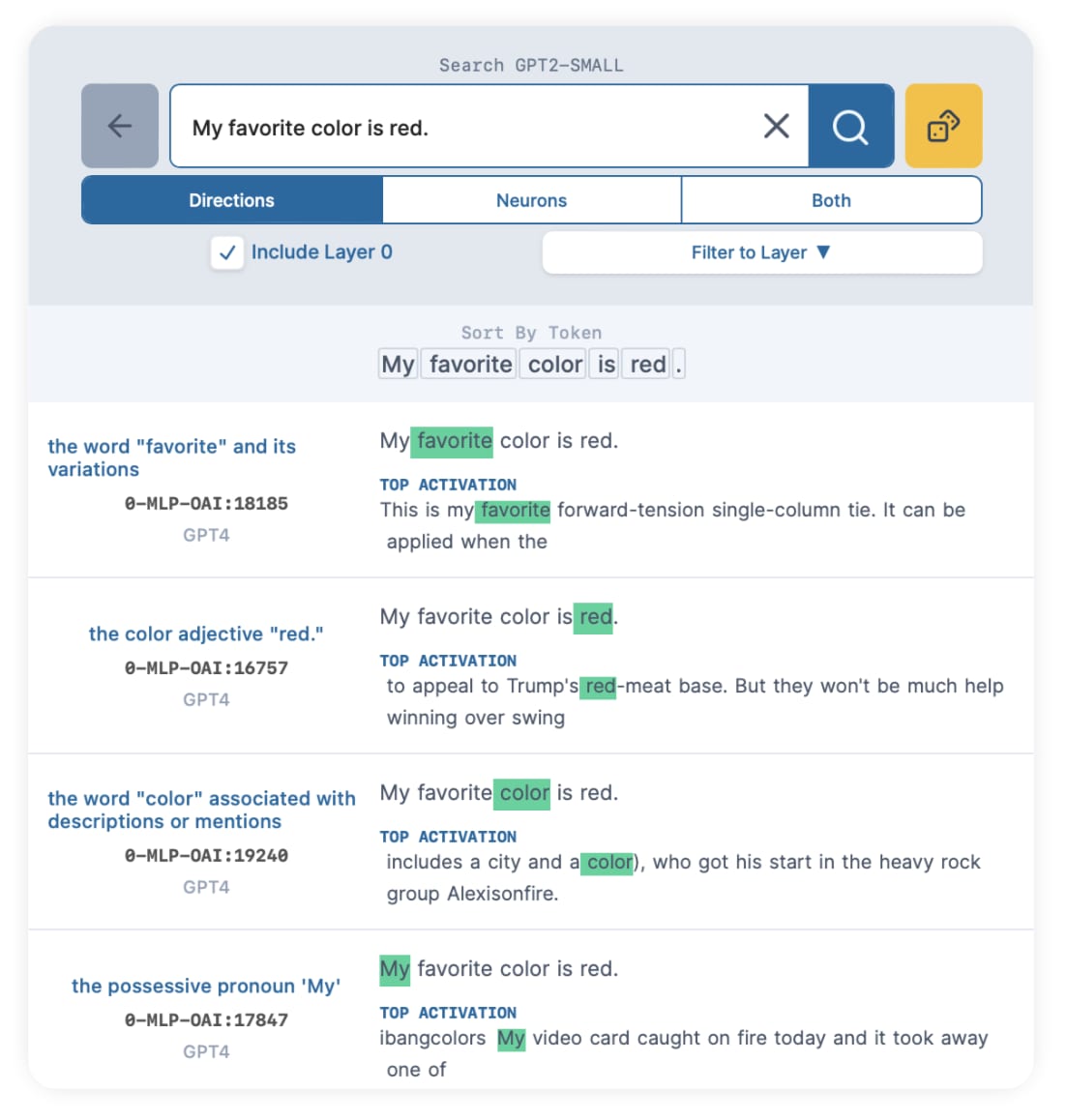
Adding the extra context gave us a promising result - the second direction has a top activation that looks like it's closer to the color red ("Trump's red-meat base") instead of a literal token match, and its GPT explanation is "the color adjective 'red'".
But the other tokens we added for context are also in the results, and they're not what we're looking for. Results 1, 3, and 4 are about "favorite", "color", and "My", which drowns out other good potential results for "red".
Fortunately, we can sort by "red". Click the bordered token "red" under "Sort By Token":
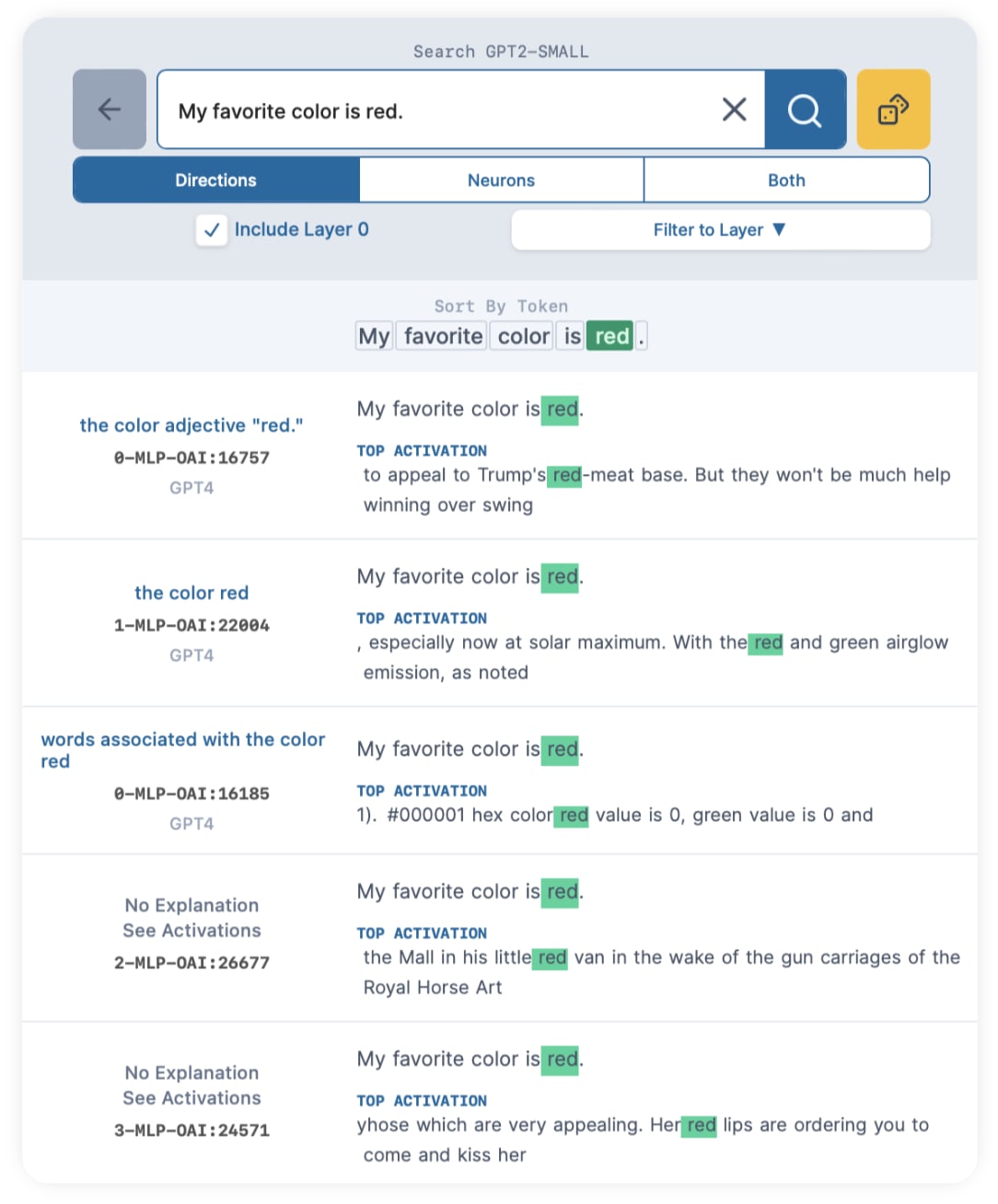
The result is exactly what we want - a list of directions that most strongly activate on the token "red", in the context "My favorite color is red.". The top activations look promising!
It turns out that the first "Trump's red-meat base" direction, 0-MLP-OAI:16757, isn't the best one. While its top activations does have "red jumpsuit", "red-light", it also activates on "rediscovered" and "redraw".
The second result, 1-MLP-OAI:22004, is much better. All of its top activations are the token "red" by itself as a color, like "red fruit", "shimmery red", and "red door".
Red-oubling Our Efforts
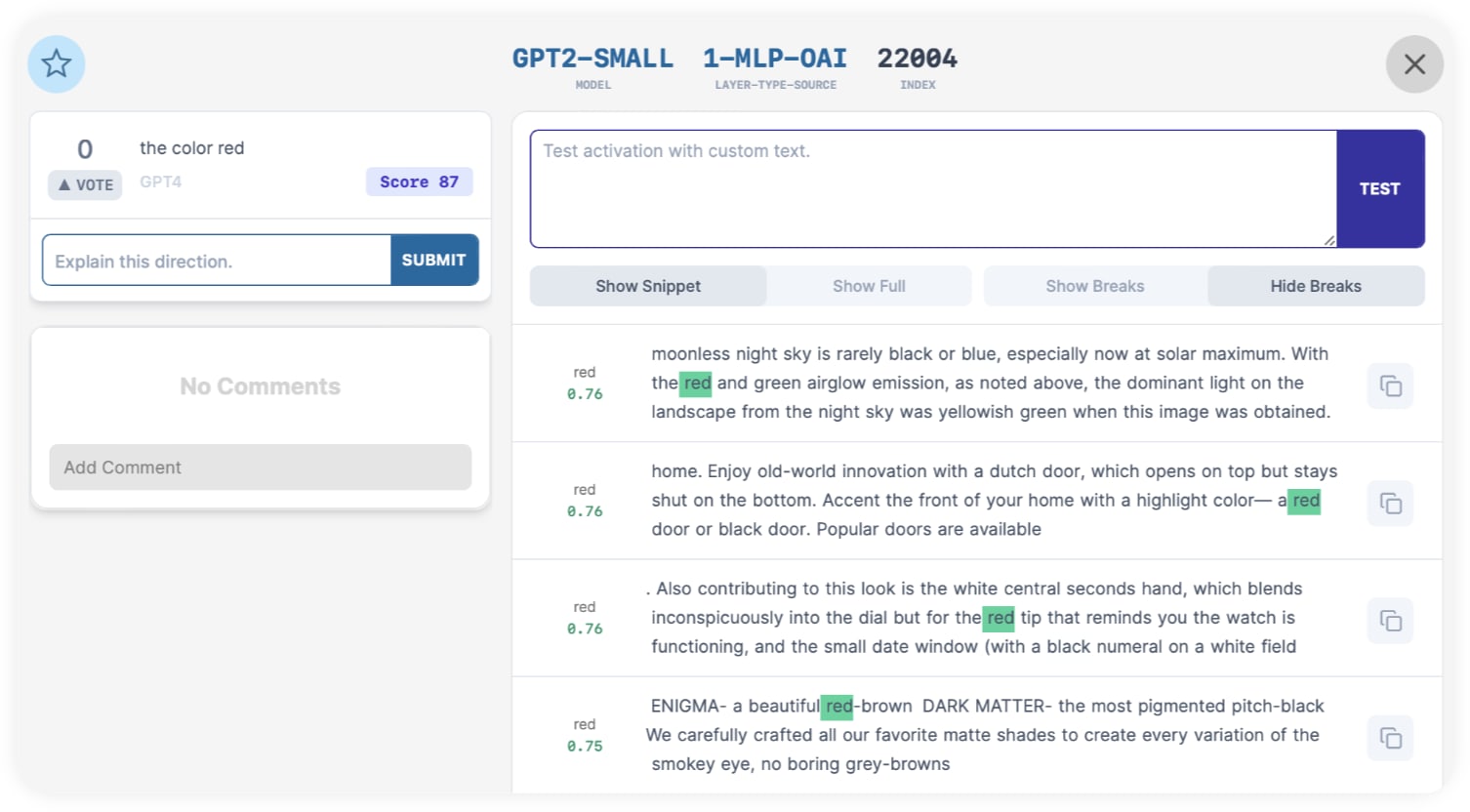
1-MLP-OAI:22004 is a good find for "red", but we're not satisfied yet. Let's see if it understands the color red without the token "red". To do this, let's test if this direction activates on "crimson", a synonym for red.
Let's open the direction. Then, click the "copy" button to the right of its first activation.

This copies the activation text into the test field, allowing us to tweak it for new tests:

We'll change the highlighted word "red" to "crimson", then click "Test":

It activated! When replacing the token "red" in our top activating text with "crimson", the token "crimson" was still the top activating token. Even though its activation is much weaker than "red", this is a fantastic result that's unlikely to be random chance - especially considering that this activation text was long had many other colors in it.
We don't always have to copy an existing top activation. It just usually makes sense to copy because the top activation is likely to give you a high activation on modifications, like the word replacement we did here. We can also just type in a test manually. Let's replace the test text with "My favorite color is crimson.":
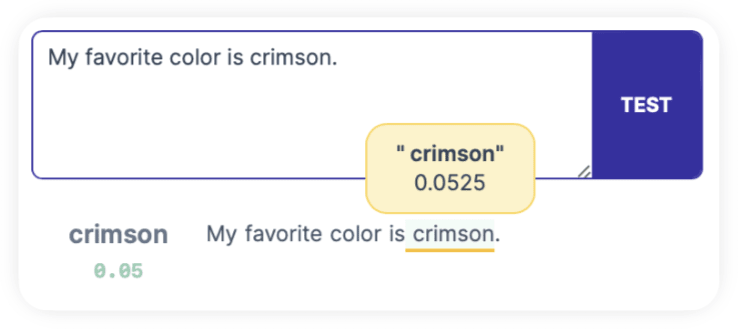
It still activates, though slightly lower than the copy-paste of the top activation. Neat.
Red-oing It, But With Neurons
We found a monosemantic and meaningful direction for "red". How about neurons?
We'll filter our search results to neurons by clicking Neurons. Here's the result.
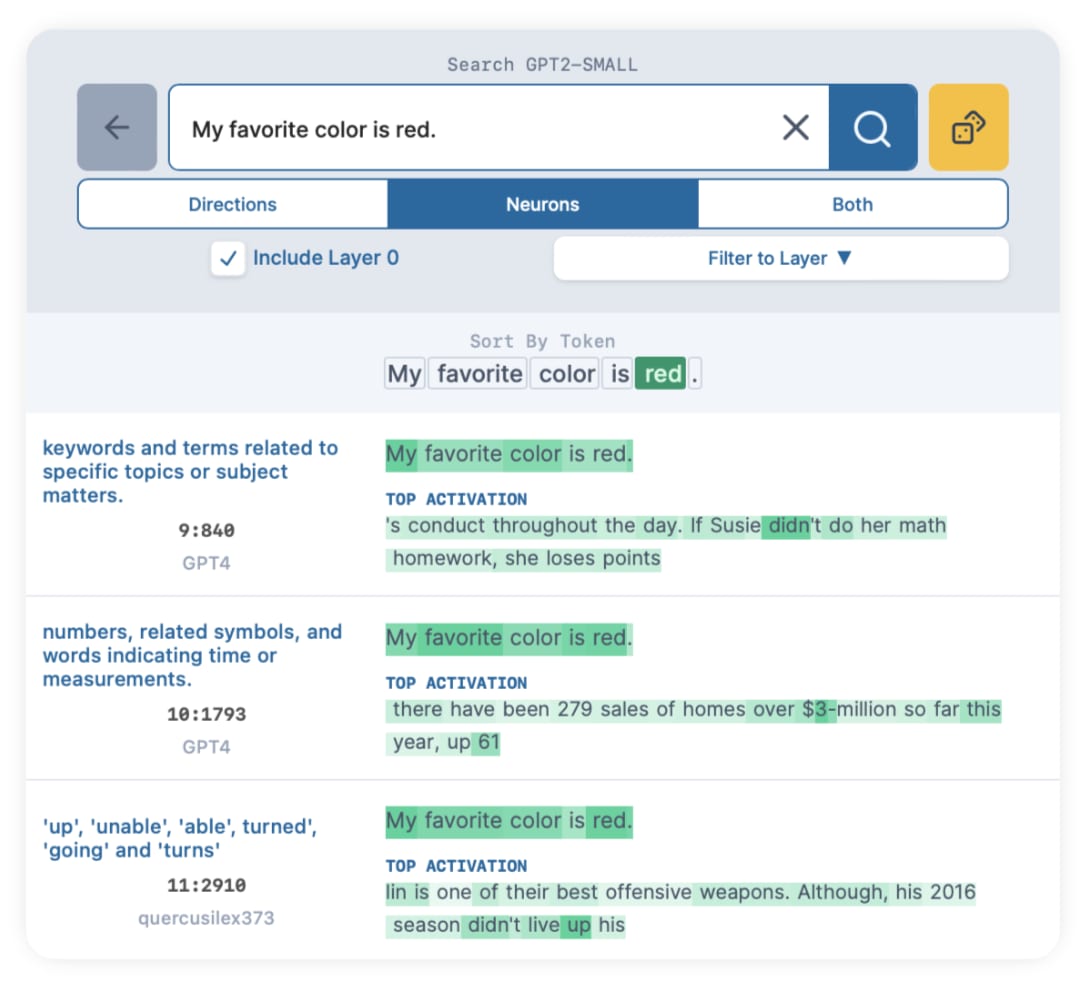
The results for neurons are, frankly, terrible. We have to scroll halfway down the results to find neurons about colors:
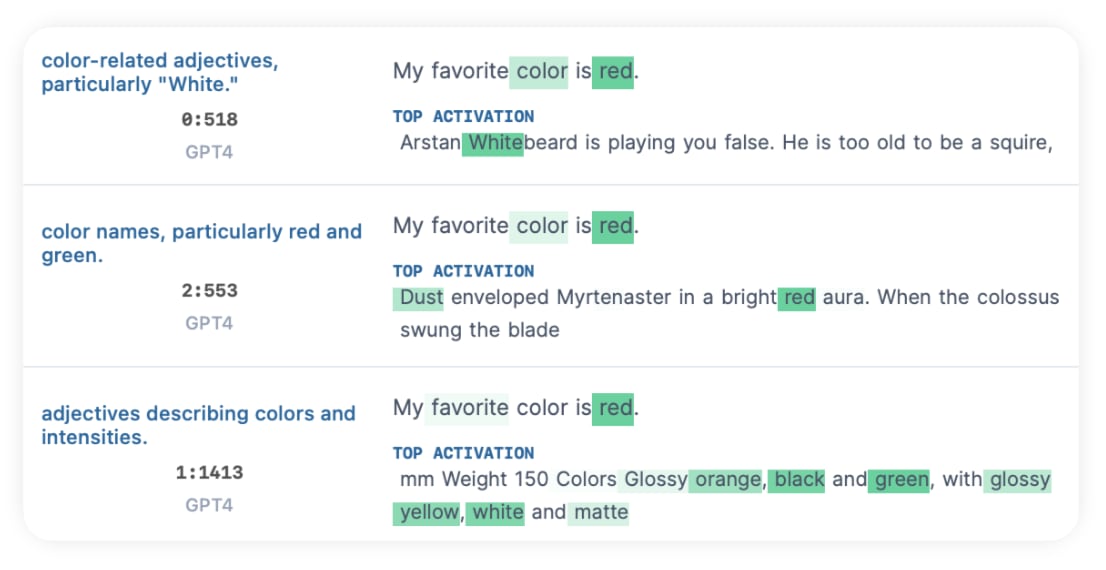
And clicking into these, they're mostly general color neurons, with the best candidate being 2:553. We do a test to compare it with our previous 1-MLP-OAI:22004:
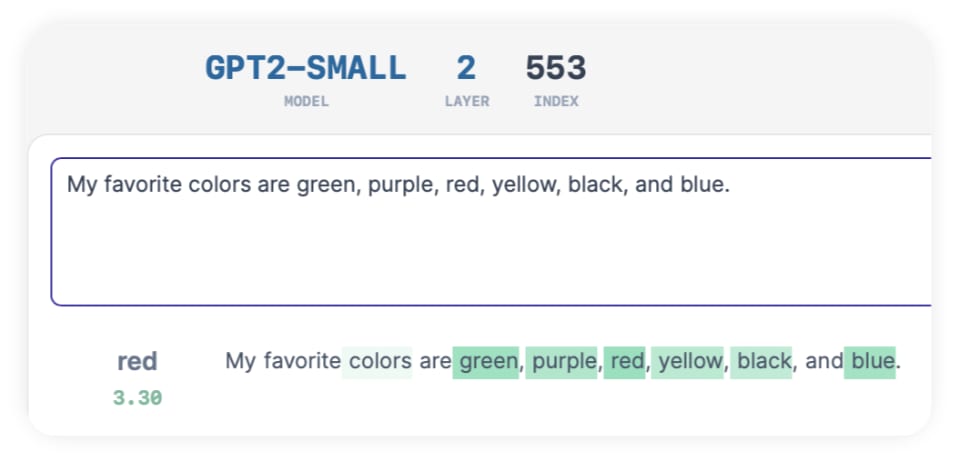
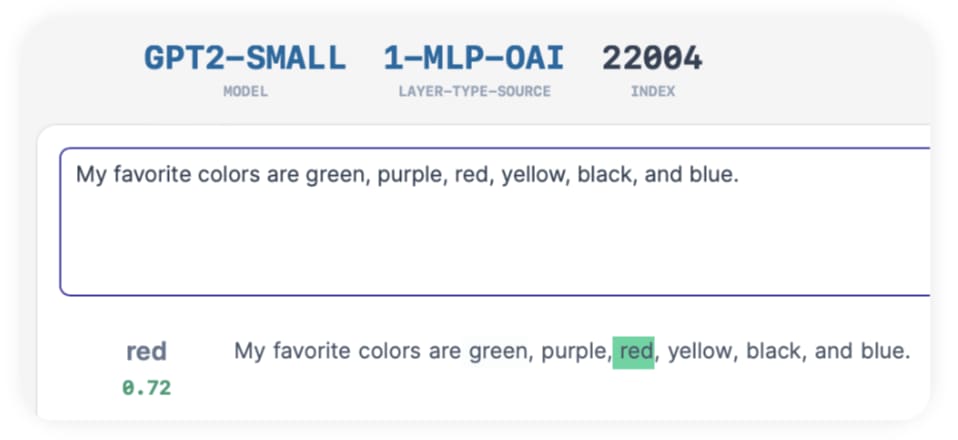
The direction is clearly better - the difference is night and day. (Or red and blue?)
Conclusion of test 1: We successfully found a monosemantic and meaningful direction for the color red. We could not find a monosemantic red in any neurons.
Test 2: Extract Concepts From Text - The Odyssey
In the first test, we looked for one concept and came up with searches to find that concept. In this test, we'll do the opposite - take a snippet of text, and see how well directions and neurons do in identifying the multiple concepts in that text.
Back at the home page, we'll chose a Literary example search query:
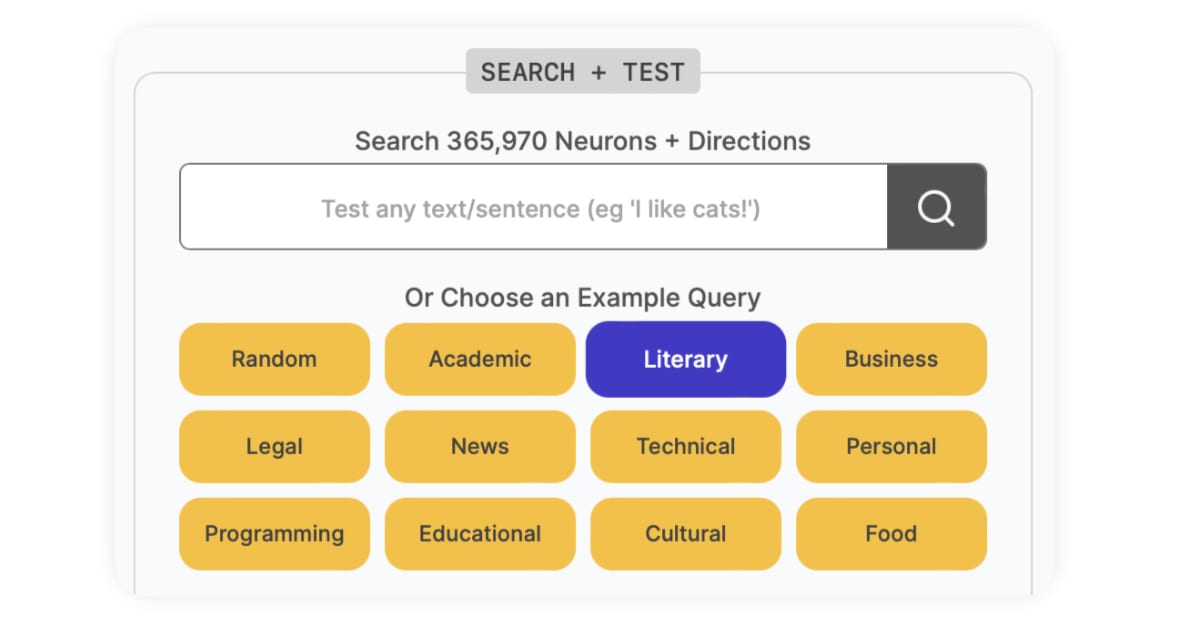
We got randomized into text snippet about the Odyssey:
In 'The Odyssey', Homer takes us on an epic journey with Odysseus, whose adventures and trials on his way back to Ithaca after the Trojan War offer timeless insights into the human condition and the quest for home.
Since there are multiple Literary examples it's choosing from, you might have gotten something different. Click here to follow along on our... Odyssey.
The Journey Begins
Like the first test, we want to compare directions and neurons on the criteria of monosemantic and meaningful.
But since there are so many tokens in this text, we'll mostly check for a "good enough" match by comparing the top activating tokens. For example: if both the text and a direction have the top activating token "cat", it's a match. The more matches, the better.
It's All Greek To Me
Let's start with the search results for neurons.
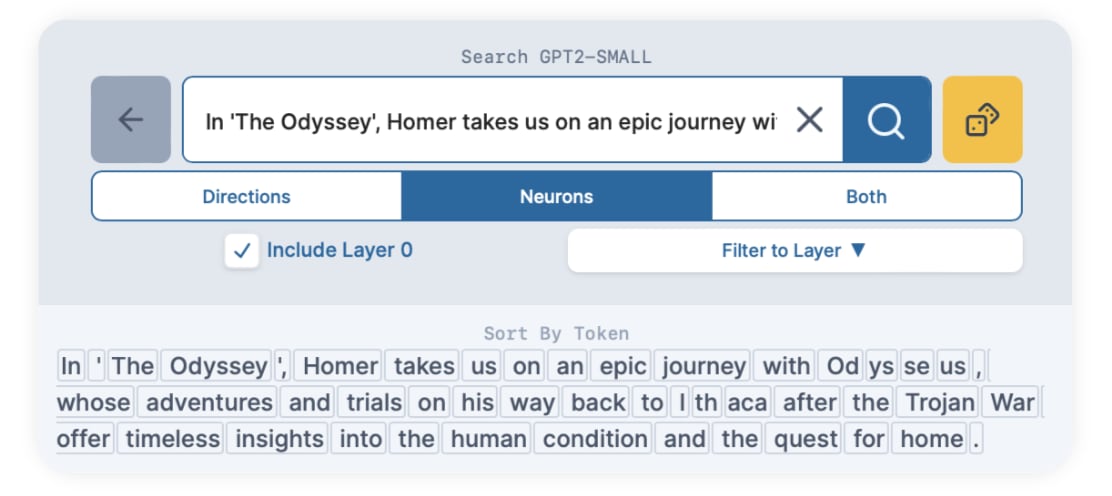
Out of the top 25 neuron results, only four matched. Most didn't have matching or similar activating tokens as the neuron, or were highly polysemantic, like 11:2172:
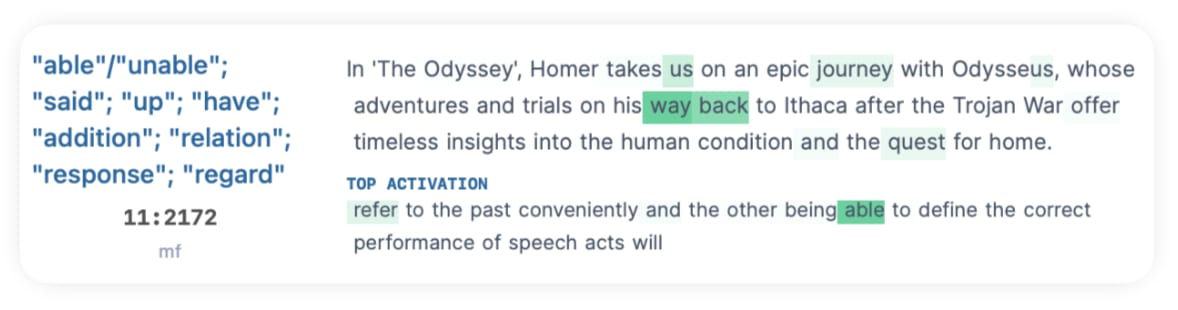
Out of the four matches token matches, most activated on unrelated tokens as well:
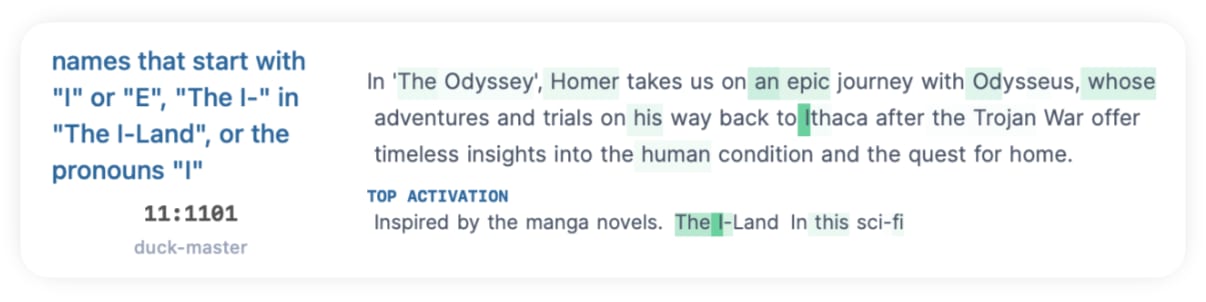

(Note: Thanks to Neuronpedia contributors @mf, @duck_master [LW · GW], @nonnovino, and others for your explanations of these neurons.)
Overall, the top 25 neurons were bad at matching the concepts or words in our text.
Towards Monophemus
Okay, the neurons were a disaster. How about the directions?
The directions results were stellar. All 25 of the top results were monosemantic and matched exactly, with the exception of "insights" vs "insight" in 0-MLP-OAI:19642:

As we saw in the first test, a non-exact but related match is a good sign that this direction isn't just finding the exact token "insight", but looking for the concept. Let's test 0-MLP-OAI:19642 with adjective "insightful" and synonym "intuition":
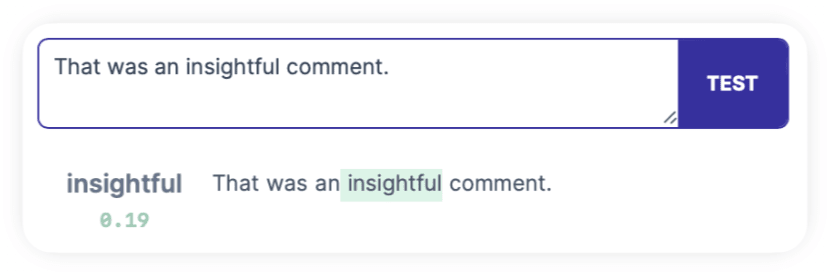
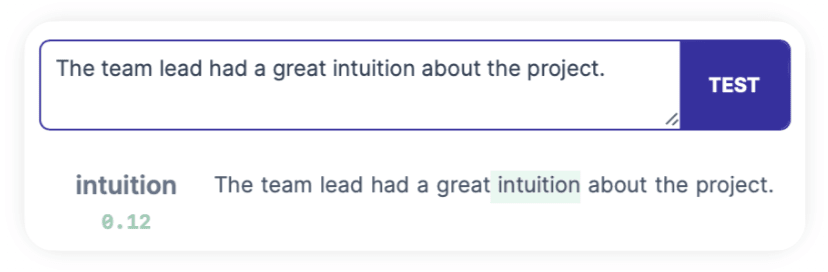
Both activated - nice! To be sure it's not just finding adjectives, let's check "absurd":
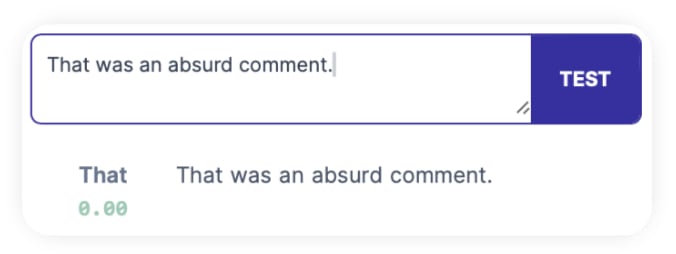
Absurd doesn't activate - so we'll consider this spot-check passed.
Overall, the top 25 directions were simply really good. They're obviously better than neurons. But that's a low bar - just how good are the directions?
I noticed something odd in the top search results - a significant majority of top activations were in layer 0 (22 out of 25). I wanted to see how it did without layer 0, so I clicked the "All Layers" dropdown and selected all layers except layer 0, and reran the search.
From Hero... to Zero?
Surprisingly, the direction results excluding layer 0 were noticeably worse. I counted 22 out of 25 matches, which is three fewer than when we included layer 0.
What accounted for the three non-matches?
- 10-MLP-OAI:0 and 11-MLP-OAI:1 are totally unrelated to the text. Since the OpenAI directions were indexed by most frequently activating first, their indexes of 0 and 1 suggest these are highly polysemantic. I tested these directions to confirm:
- 11-MLP-OAI:12199 activates on "an $", and most highly on "$". In our text it most highly activated on "an". So this is a half-match.
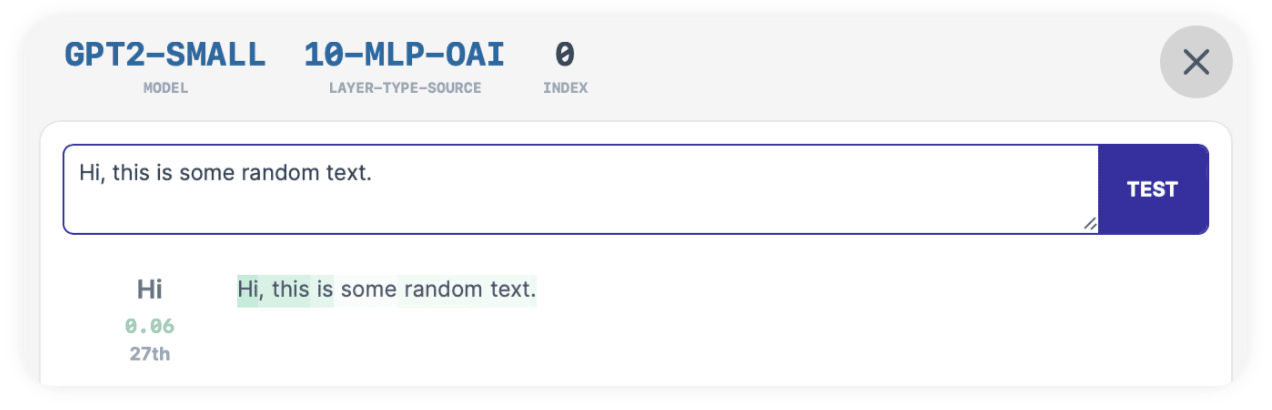
It looks like these direction non-matches were the result of two rogue directions and one near-hit, which still isn't bad, especially compared against neurons.
But because excluding layer 0 made the results worse, I was now curious if later layers were even worse. So I checked the results for each layer (using the "Filter to Layer" dropdown) for both directions and neurons:
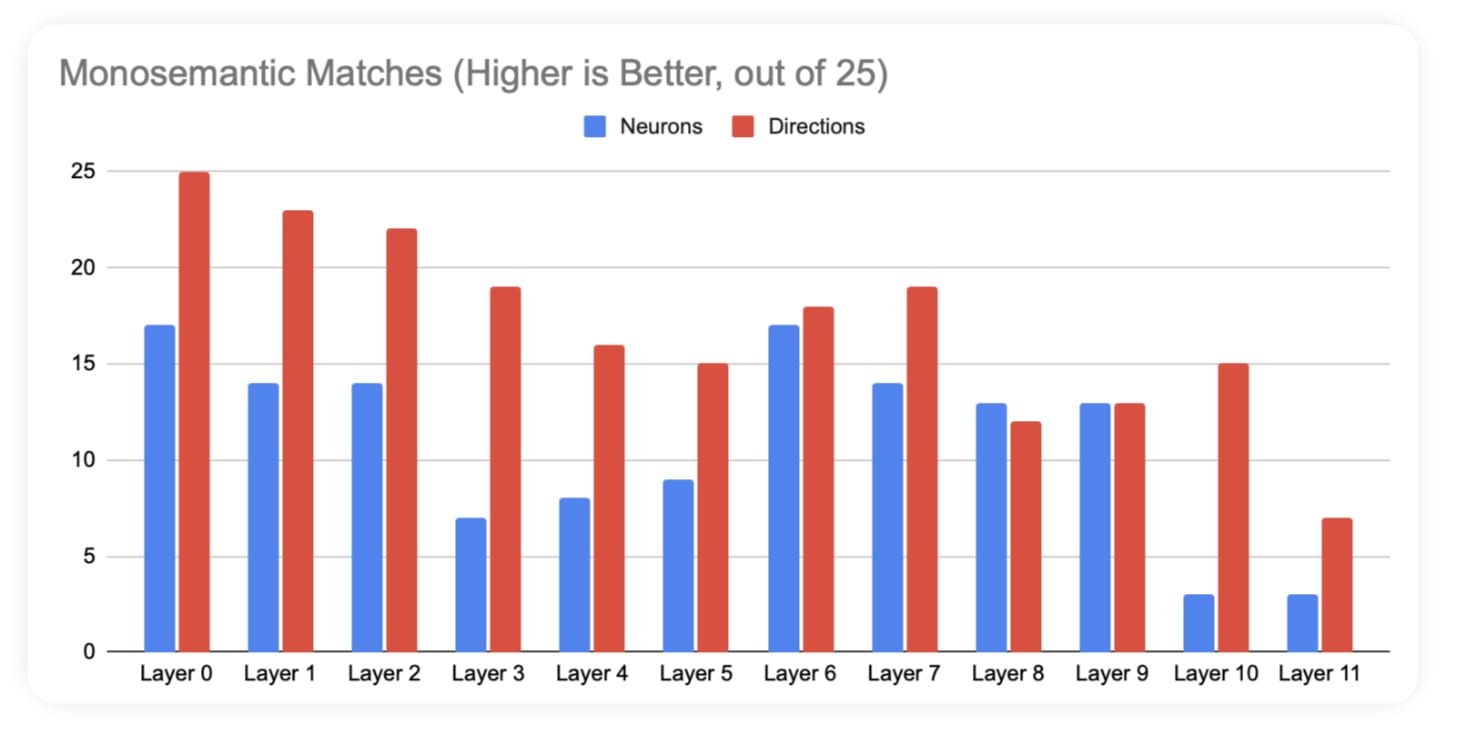
This was pretty surprising. Even though directions were better than neurons in every layer, directions got noticeably worse in the later layers - and the layer 11 directions were actually pretty bad. Neuron even seemed to fare decently against directions in the middle layers - from layer 6 to layer 9.
I don't know why directions seem to get worse in later layers, or why top directions are usually in layer zero. I'm hoping someone who is knowledgable about sparse autoencoders can explain.
Conclusion of test 2: We found that directions were consistently and significantly better than neurons at finding individual concepts in a text snippet. However, the performance of directions was worse in later layers.
Observations and Tidbits
Here are some highlights and observations from looking through a lot of directions and neurons while doing these tests:
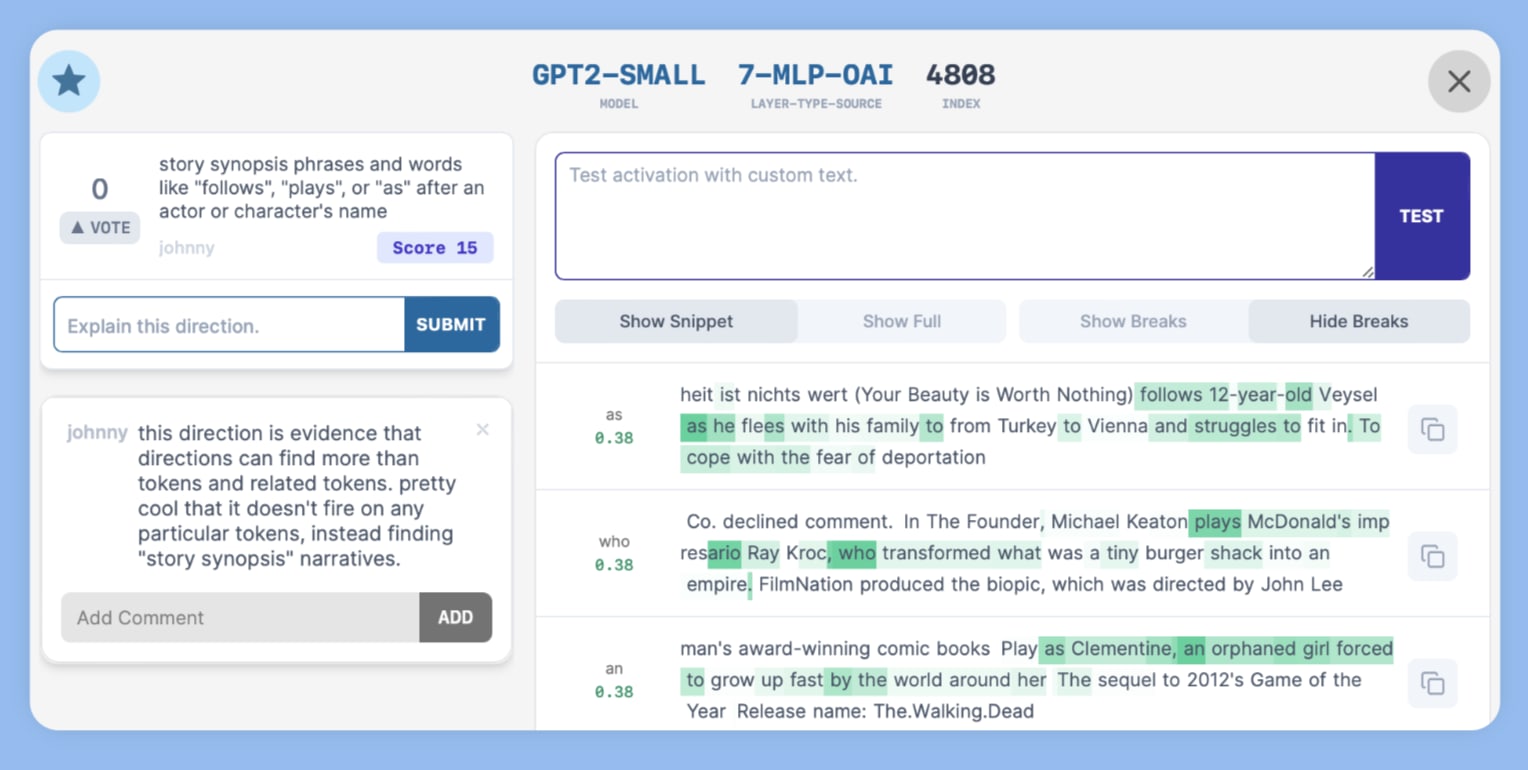
- My favorite direction is the "story synopsis" direction at 7-MLP-OAI:4808, which accurately fired on our summary of the Odyssey. In my opinion, this is strong evidence that the directions can go even further than "similar/related/synonym token" matches, and can look for broader "text passage style" matches.
- A similar direction I liked is 7-MLP-OAI:1613, except it's more about the setting and scene of a story.
- Semantically opposite tokens can activate directions more than similar tokens.
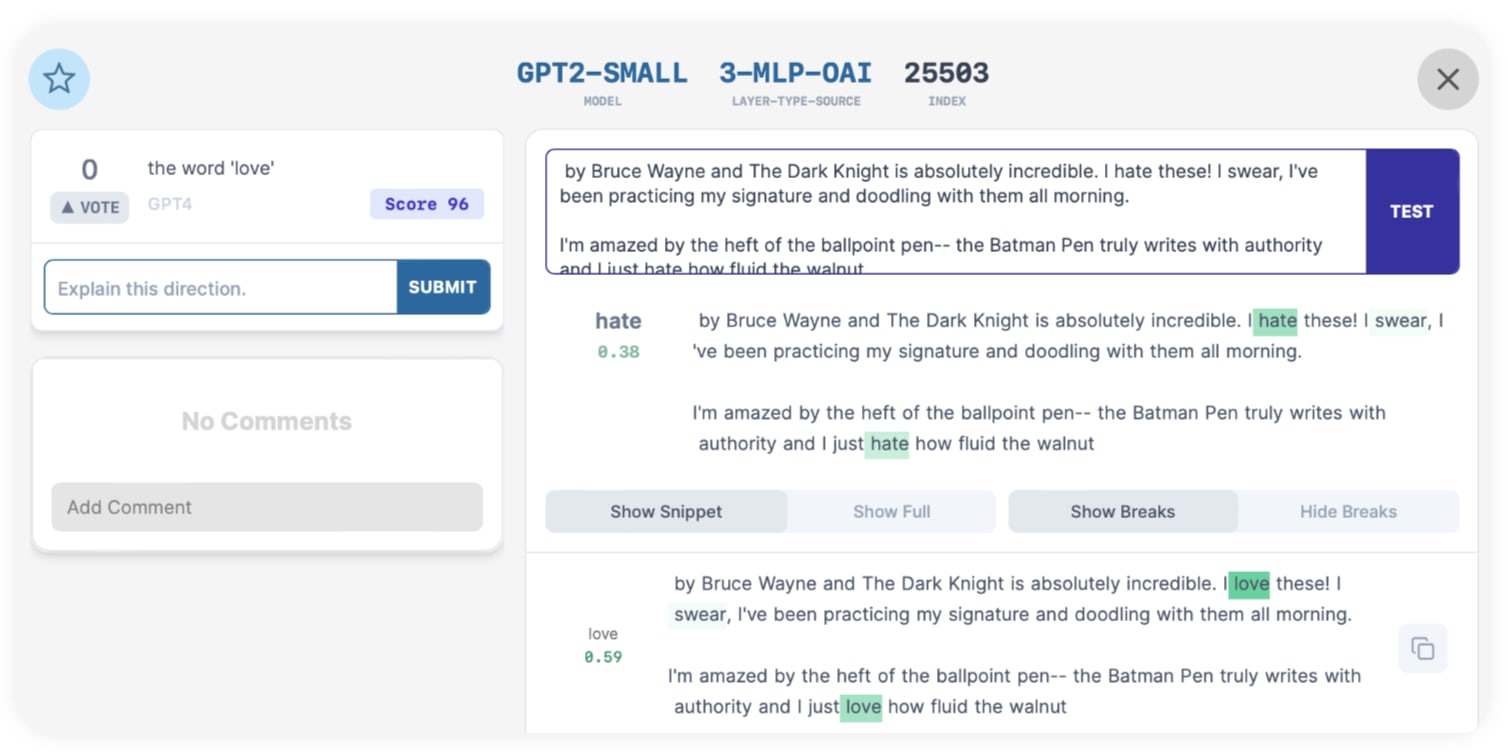
- In 0-MLP-OAI:16472, changing "love" to "hate" makes "hate" the top activating token, albeit with a reduced score. Counterintuitively, changing "love" to "like" eliminates all activations, even though "like" is closer to "love".
- 2-MLP-OAI:26593, 3-MLP-OAI:25503, 4-MLP-OAI:25454 behave similarly.
- Theory: These directions are actually "intense feelings", instead of "love".
- Finding directions that are similar to neurons (and to each other):
- Directions can have similar activations to a neuron in the same layer, creating a "twin". My guess is these directions are heavily weighted on the twin neuron:
- Twins about trains and shipping: 5:1046 and 5-MLP-OAI:6058.
- Twins about people going together: 6:681 and 6-MLP-OAI:6681.
- But I also found "triplets" - and they're across three layers, so I don't have a hypothesis: 4-MLP-OAI:17688, 6-MLP-OAI:20837, 9-MLP-OAI:23011. All activated on the capital "I" in "Ithaca" and have the exact same #1 top activation text, which is this sad snippet about porpoises going extinct 😔:
- These quintuplets across four layers were weren't as similar to each other as the twins/triplets, but all activate on "The" in movies and tv shows: 9-MLP-OAI:18636, 4:127, 4-MLP-OAI:5479, 6-MLP-OAI:23676, 7-MLP-OAI:21865.
- Directions can have similar activations to a neuron in the same layer, creating a "twin". My guess is these directions are heavily weighted on the twin neuron:

Questions
- When searching directions in all layers, why is it that earlier layers (0 and 1 especially) have higher top activations, drowning out the later laters? For neurons, it seems to be the opposite - that layers 10 and 11 have higher activations.
- Is this expected? Is there anything I can do to compensate for this to "normalize" against the other layers?
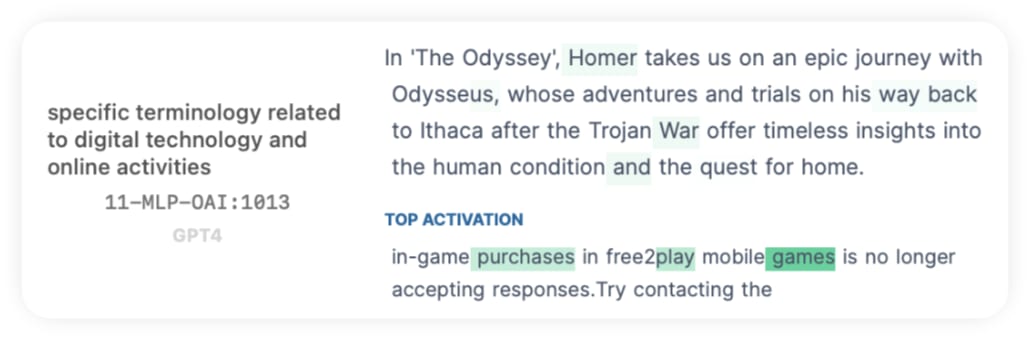
- Why do directions perform worse in later layers? Matches for directions steadily decrease from 25 to 7 from layer 0 to 11. For example, 11-MLP-OAI:1013 activates on seemingly random tokens, and the top activations also seem random:
- How can directions across multiple layers seem so similar? (Re: the triplets/quintuplets).
- Small, older models are not good at predicting tokens. When will this be a limiting factor in finding directions? What I mean is, when will we know the directions are "as good as they can get, considering the limited capabilities of the model itself"?
- Example bad GPT2-SMALL completion: "The name of the capital of France is" [completion] "French, after the English. It's also sometimes translated as Spanish, and the capital of"
Challenges and Puzzles
These are directions I either couldn't find, or couldn't figure out the pattern in them. Let me know if you have any luck with them.
- I couldn't find a direction for the general concept of color - one that consistently activates on all colors in all contexts. I wonder I just wasn't clever enough to find it, or if (unsubstantiated hypothesis) it might be a concept that is neither specific nor broad enough for a direction to be created by current SAEs. The closest I found was 2-MLP-OAI:22933, but it does not activate on red.
- 10-MLP-OAI:20144 is movie and media titles, but it doesn't activate on activation texts copied from the other "quintuplet movies" directions/neurons. Why not?
- 6-MLP-OAI:6025 activates on "back to Ithaca", and the direction's top activation is "return", which makes sense. But it also activates for "reindeer", "realdonaldtrump", "reply", and "reel". Why is there this weird overlap of "words that start with re" and "words that mean back to"?
Suggested Improvement
The directions themselves seem good, as we've saw in the two tests. But I found the activations and associated data (NeuronRecord files) provided by OpenAI to be lacking. They only contain 20 top activations per direction, and often the top 20 tokens are exactly the same, even if the direction is finding more than that literal token.
For example, the "love"/"hate" direction above (3-MLP-OAI:25503) has 20 top activations that are all "love". Replacing it with "like" results in zero activation, but replacing it with "hate" results in a positive activation. So there's something else going on here other than "love", but someone looking just at the top 20 activations would conclude this is direction is only about "love". In fact, this is exactly what GPT4 thought:
A proposed fix is to do top token comparisons when generating NeuronRecords, and count exact duplicates as a "+1" to an existing top activation. But this would eliminate identical top activation tokens that are in different contexts (or same token in different words, which we definitely want to keep.)
A better fix is doing semantic similarity comparisons on the word, phrase, sentence, and whole text when generating NeuronRecords, then set thresholds for each semantic similarity type. When encountering the same top activating token, count that activation text as a +1 of an existing activation text if it's within our similarity thresholds.
Ideally, you'd end up with a diverse set of top activation records that also has counts for how frequently a similar top activation appeared. I plan to build some version of this proposed fix and generate new top activations for these directions, so let me know if you have any feedback on it.
Try It Yourself
Run Your Own Tests and Experiments
You can play with the new directions and do your own experiments at neuronpedia.org. For inspiration, try clicking one of the example queries or looking for your favorite thing.
If you find an interesting direction/neuron, Star it (top left) and/or comment on it so that others can see it as well. Here's my favorite "story synopsis" direction:
When you star or comment, it appears on your user page (this links to my stars page), the global Recently Starred/Commented page, and the home page under Recent Activity.
Please let me know what new features would be helpful for you. It'd be really neat to see someone use this in their own research - I'm happy to help however I can.
Upload Your Directions and Models
If you want to add your directions or models so that you and others can search, browse, and poke around them, please contact me and I'll make it a priority to get them uploaded. A reminder that Neuronpedia is free - you will not get charged a single cent to do this. Maybe you'll even beat OpenAI's directions. 🤔
Feedback, Requests, and Comments
Neuronpedia wants to make interpretability accessible while being useful to the serious researchers. As a bonus, I'd love to make more folks realize how interesting interpretability is. It really is fun for me and likely you as well, if you've read this far!
Leave some feedback, feature requests, and comments below, and tell me how I can improve Neuronpedia for your use case, whether that's research or personal interest. And if you're up to it, help me out with the questions and challenges above.
4 comments
Comments sorted by top scores.
comment by Johnny Lin (hijohnnylin) · 2024-01-31T18:34:58.140Z · LW(p) · GW(p)
Apparently an anonymous user(s) got really excited and ran a bunch of simultaneous searches while I was sleeping, triggering this open tokenizer bug/issue and causing our TransformerLens server to hang/crash. This caused some downtime.
A workaround has been implemented and pushed.
comment by mishka · 2024-01-31T08:52:05.723Z · LW(p) · GW(p)
This is great, thanks!
I think the link to your initial post on Neuronpedia might be useful to create better context: Neuronpedia - AI Safety Game [LW · GW]
Replies from: hijohnnylin↑ comment by Johnny Lin (hijohnnylin) · 2024-01-31T18:31:47.591Z · LW(p) · GW(p)
Thanks for the tip! I've added the link under "Exploration Tools" after the first mention of Neuronpedia. Let me know if that is the proper way to do it - I couldn't find a feature on LW for a special "context link" if there is such a feature.
Replies from: mishka