Reverse engineering the memory layout of GPU inference
post by Paul Bricman (paulbricman) · 2025-04-09T15:40:28.457Z · LW · GW · 0 commentsThis is a link post for https://noemaresearch.com/blog/device-structinterp
Contents
Background Context Technical Challenges Memory Segmentation Future Work None No comments
Background Context
This research note provides a brief overview of our recent work on reverse engineering the memory layout of an inference process running on a modern hardware accelerator. We situate this work as follows:
- Virtual diplomacy in relation to AI governance. Our organization focuses on developing the practice of virtual diplomacy. Introduced as a response to labor market disruption, dual-use capabilities proliferation, and other challenges posed by AI, it relies on verifiable monitoring instruments called virtual embassies. By taking stock of the inference deployments in which they are embedded, virtual embassies may allow third-parties to answer questions such as: "How much autonomous research has this organization consumed internally?" or "How much autonomous hacking has this organization sold to customers in this jurisdiction?" The ability to reliably resolve such queries may enable multilateral soft law instruments poised to positively shape AI.
- Structural interpretability in relation to virtual diplomacy. Work on virtual diplomacy can be split into efforts to bolster its technical maturity and efforts to bolster its political maturity. The former is concerned with the readiness of virtual embassies, while the latter is focused on compatibility with political realities. Technical work can further be split on the basis of which core component it is focused on. One such component, referred to as structural interpretability, is concerned with allowing virtual embassies to reliably locate key objects in memory, such as feed-forward parameters, output logits, or the KV-cache, in a way that is agnostic to the model architecture or tech stack, and in a way which is adversarially robust to interference.
- On-device in relation to on-host structural interpretability. In our previous research sprint, we demonstrated that it is feasible to use raw performance events to reconstruct the memory layout of an inference process which uses a CPU backend, under a broad range of model architectures, scales, batch sizes, input data, decoding strategies, and other inference configurations. The current work pushes this capability closer to realistic inference deployments by demonstrating that it is also feasible to use raw performance events to reconstruct the memory layout of an accelerated inference process which relies on a GPU backend.
Technical Challenges
While our previous host-side work provided a useful stepping stone, the on-device setting presented several novel obstacles which required us to refine our approach:
- Offline preprocessing would be prohibitive. In the previous research sprint, we were especially interested in whether performance events contained enough signal to reconstruct the on-host memory layout in the first place. We opted for the scrappy approach of first collecting all memory events emitted by the target process, and then preprocessing them offline to derive per-page features, such as the number of stores in that region. Much of that post-hoc, offline preprocessing could have been done online, using streaming algorithms, yet we prioritized speed and went with the hacky approach for that proof-of-concept. That said, in the on-device setting, this option would absolutely not be available. At high utilization, a modern GPU may have hundreds of thousands of threads which interact with memory at different addresses, millions of times a second. Storing all these parallel events for later processing would incur an astronomical memory cost. An up-to-date summary of the data stream of performance events must be maintained online, in an update-and-forget regime. However, host-initiated events such as on-device memory allocations or frees are captured as such, because there are very few of them: on-device logic often operates within broad canvases set up by the host.
- On-host preprocessing would be prohibitive. Even assuming we only store a running summary of the activity observed in different parts of the device memory, extensively moving that data feed around would also be prohibitive. Transfers between host and device are among the most costly ways of moving tensors around. Hence, the online preprocessing of raw performance data must happen on-device, in order to spare the host-device bandwidth from having to deal with the yet-uncompressed data. The Nvidia CUPTI API allows the accumulation of certain metrics on-device using hardware performance counters. However, CUPTI only exposes coarse-grained metrics, such as: "How many times did this streaming multiprocessor load from global memory in total, irrespective of addresses?" Fortunately, while CUPTI can only instrument kernels to track several predefined metrics, NVBit proved capable of enabling arbitrary instrumentation of intercepted device binaries. This allows us to more flexibly tap into the arguments of memory instructions, including addresses.
- Exact preprocessing would be prohibitive. Even assuming we avoid burdening both storage and host-device interconnect with raw performance events, maintaining an exact online summary on-device might still occupy a non-trivial portion of device memory. After all, extensive global memory is essential for working with modern models, and our running summary of device activity should not materially interfere with the original activity itself. For instance, keeping tabs on 60 features per 4KB page in a 80GB space using long integers might itself occupy 10GB. Fortunately, probabilistic data structures have emerged to help maintain approximate summaries in an extremely compact form. Count-min sketches in particular are simple, powerful, and theoretically grounded data structures which allow us to maintain accurate estimates of how often operations with different properties have touched different addresses. As seen when discussing results, compressing the summary by several orders of magnitude appears to preserve enough signal for accurately segmenting device memory into objects of interest.
To the best of our knowledge, this is the first time when memory activity has been comprehensively tracked on a per-page basis on modern GPUs, albeit with error bounds inherited from the count-min sketch. The several hurdles posed by the sheer volume of data emitted by the embarrassingly parallel hardware may explain this. Note that we later argue that we may have used a machine learning hammer to cast a computer science problem as a nail, and that a more elegant approach to segmentation may be possible, though the bitter lesson will tell.
Memory Segmentation
Despite the novelty of instrumenting kernels to "track themselves" using count-min sketches, the general approach to memory segmentation remained the same as before: treat it as a machine learning problem.
- Object detection, but images are one-dimensional. Different objects of interest occupy different regions in the memory range of an inference process. By profiling the launched process, we get a set of features per memory page, which capture the operations' direction, cache policy, data type, etc. It is also possible to procedurally launch inference processes with different model architectures and scales, batch sizes and max lengths, truncation and decoding strategies, etc. Taken together, these represent a pipeline which converts compute into synthetic data for training a minimal model to reconstruct ground-truth segmentation maps based on signals picked up by the profiler. After training, we can feed in the signals captured from a new inference process and infer its memory layout. In a sense, language models themselves become the target of the minimal segmentation model, inference the object of inference. However, the machine learning approach to structural interpretability as a whole might be displaced by a more elegant one grounded in the semantic analysis of the intercepted kernel assembly itself.
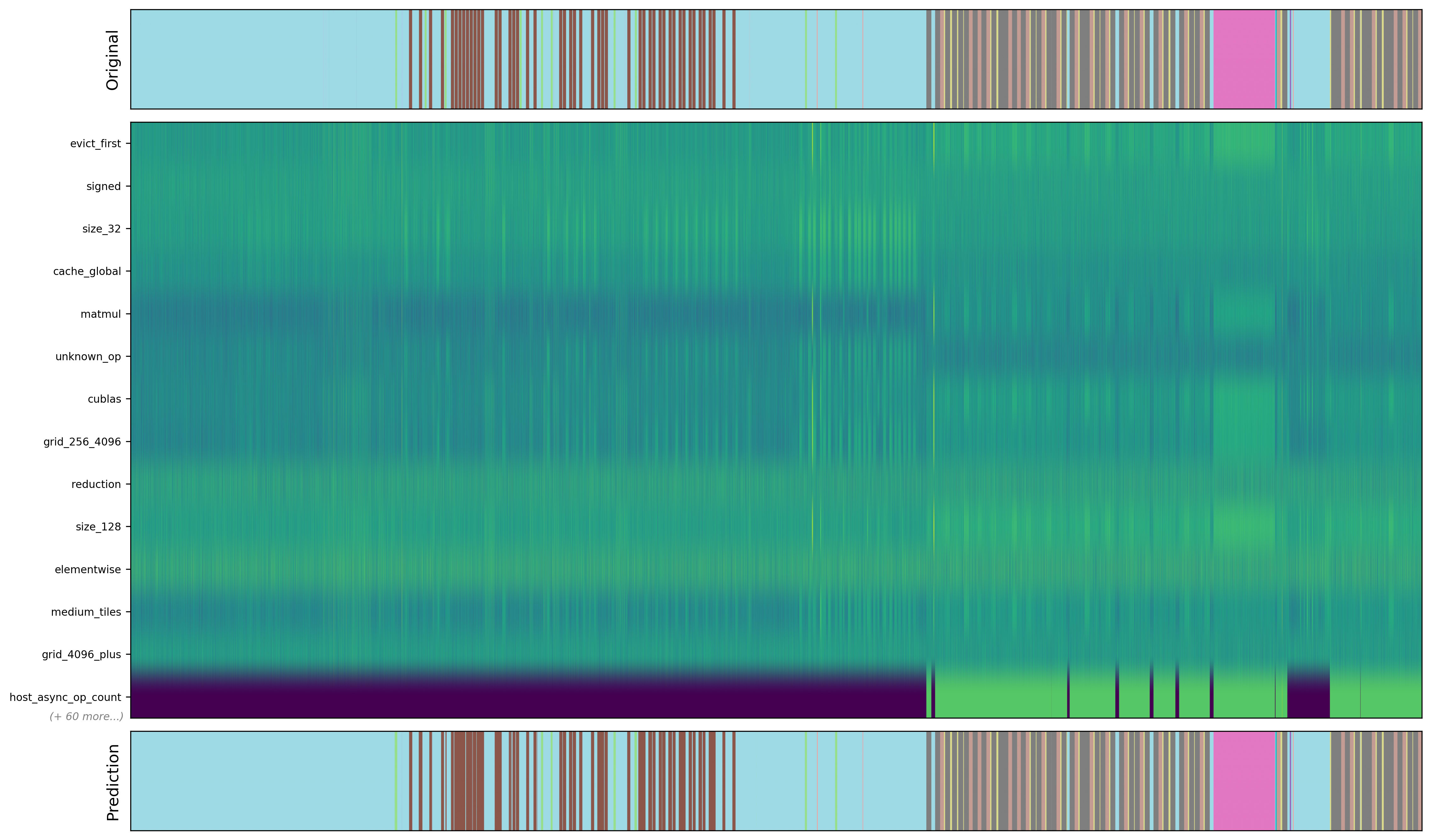
- Predict segmentations, but images are one-dimensional. After generating synthetic data in the form of ~1,000 procedural inference processes, we trained a minimal 1D CNN to predict what object of interest occupies what memory page. Besides subtly different input and output shapes, we largely worked with the same architecture as before, and achieved 95% accuracy in classifying pages from previously unseen inference runs. The "predict randomly" baseline is at ~7% accuracy, while the "always predict the most frequent object" baseline is at ~33%. In the visualization below, we can see the original memory layout of a test sample, a selection of per-page signals emitted from the process, and the predicted segmentation map. Note how host-initiated activity in the last feature row is quite coarse-grained, and how the device-initiated activity on the other rows is quite noisy, due in large part to the usage of count-min sketches.
Future Work
Where do we go from this feasibility study? Several directions and implications are relevant:
- Next steps for structural interpretability. First, even if these results relied on only two minutes of inference wall-time, it would be useful to identify the most effective optimizations for reducing overhead. For instance, this could involve only launching instrumented versions of kernels every Nth kernel, or actually updating the count-min sketch only if the current clock cycle is located in a valid time slice. Second, it seems plausible that semantic analysis of the kernel assembly itself, processing the semantics of its variables and operations, may yield a more elegant and efficient approach to the problem. Third, work on adversarial robustness to interference from the host, as well as training on more inference configurations, may improve both performance and reliability.
- Side effects of structural interpretability. While this work has been motivated by bolstering the technical maturity of virtual embassies, we also notice secondary applications. First, AI governance efforts have explored the idea of limiting the use of certain categories of computations, as a way to manage the proliferation of algorithmic improvements. Being able to intercept and modify kernels before launch at the assembly level may contribute to such regulatory affordance. Second, AI governance efforts have explored the idea of a trusted escrow where model evaluations are run. Being able to operate on models in a way that is agnostic of their architecture may contribute to the ease of executing such arrangements. Third, while this work is meant to compose with existing on-chip implementations of remote attestation — developed by experienced, well-payed teams over years in response to non-trivial market pressures — it may provide a glimpse into the possibilities afforded by more speculative on-chip mechanisms.
- Next steps for virtual diplomacy. As mentioned previously, structural interpretability is just one of several constituent components of virtual embassies, and the technical work necessary to render them workable is just half of the story, with policy work being necessary to complete the picture. Fortunately, many of these components can be tackled independently and in parallel. For instance, structural interpretability assumes crude access and is tasked with getting a fix on the objects of interest, while functional interpretability assumes objects of interest and is tasked with assessing the extent to which particular capabilities are represented, capabilities whose contents are largely supplied by the soft law instruments, etc. Hence, the next steps for virtual diplomacy still consist in strategically advancing the technical and political maturity of the overall practice.
0 comments
Comments sorted by top scores.