How Big a Deal are MatMul-Free Transformers?
post by JustisMills · 2024-06-27T22:28:40.888Z · LW · GW · 6 commentsThis is a link post for https://justismills.substack.com/p/how-big-a-deal-are-matmul-free-transformers
Contents
The story so far What’s the new architecture? What are the limitations? Transformers architecture is sticky Not tested at scale Not tested vs. cutting edge So… sell NVIDIA? None 6 comments
If you’re already familiar with the technical side of LLMs, you can skip the first section.
The story so far
Modern Large Language Models - your ChatGPTs, your Geminis - are a particular kind of transformer, a deep learning architecture invented about seven years ago. Without getting into the weeds, transformers basically work by turning an input into numbers, and then doing tons and tons of matrix operations on those numbers. Matrix operations, and in particularly matrix multiplication (henceforth MatMul), are computationally expensive. How expensive? Well, graphics cards are unusually good at matrix multiplication, and NVIDIA, the main company making these, was the most valuable company on Earth earlier this month.
Over the last few years, spurred on by extreme investment, transformers have gotten larger and stronger. How good transformers are is multidimensional, and is roughly captured by scaling laws: basically, models get better when you give them more (high quality) data, make them bigger, or train them for longer.
I’ve written before about the data wall, the hypothesis that we’re running out of new data to train cutting edge AI systems on. But another path to much stronger AI would be if we trained them more efficiently: if you have to do way fewer (or way easier) mathematical operations when training an AI, you can do a lot more training on the same (gigantic) budget.
Basically, holding training data constant, if you can train a model twice as efficiently, you can also make it twice as big.[1] Which is a big deal in a world where there may be bottlenecks for other ways to make better AI: if it isn’t the data wall, it may well be a wall of regulation preventing the insane power consumption requirements of a trillion-dollar cluster.
Cutting edge labs are in an intense race to make transformative AI, so we don’t know what kinds of efficiency advances they’ve been making for the past few years. But there has been hubbub the last few weeks about a new kind of model, which avoids the need for MatMul.
So, what’s the deal? Is the new research a flash in the pan, a small incremental win, or a bold new paradigm we’ll all be citing (and making birthday posts for) in seven years?
I’ll make a brief examination of the paper’s claims and why they’re exciting, then give reasons for restraint.
What’s the new architecture?
The new paper, by Rui-Jie Zhu et al., is Scalable MatMul-free Language Modeling. It came out on June 4th. In the places where a typical transformer would do MatMul, the paper instead does something different and more akin to addition. The technical details are pretty complicated, but the intuition that addition is easier/simpler than multiplication is spot on.
How much better does their new method work? Here’s the relevant graph from their paper:
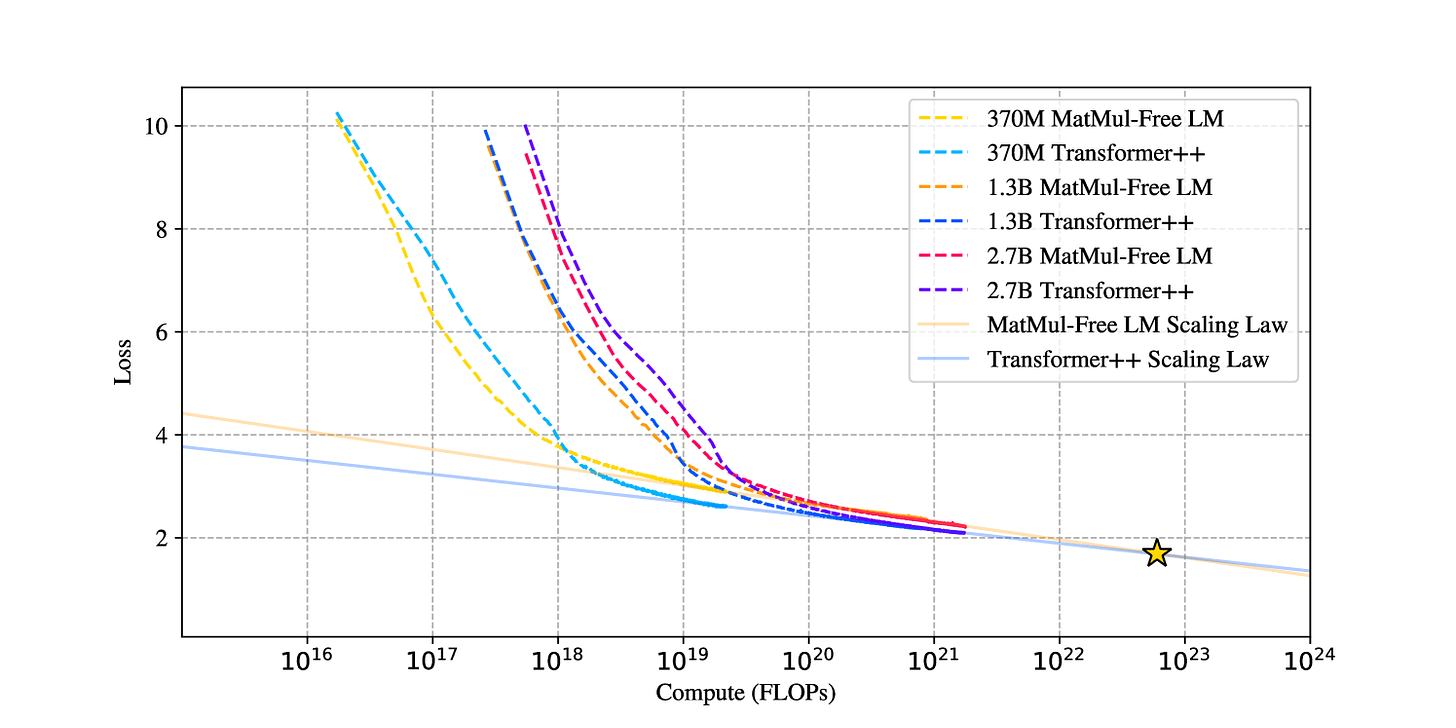
The star is the hypothetical point where you’d get equal bang for your buck from their MatMul-free style and the current (public) SOTA[2] - a little under 10^23 floating point operations (FLOPs). To quote them on the significance of this number:
Interestingly, the scaling projection for the MatMul-free LM exhibits a steeper descent compared to that of Transformer++. This suggests that the MatMul-free LM is more efficient in leveraging additional compute resources to improve performance. As a result, the scaling curve of the MatMul-free LM is projected to intersect with the scaling curve of Transformer++ at approximately 10^23 FLOPs. This compute scale is roughly equivalent to the training FLOPs required for Llama-3 8B (trained with 15 trillion tokens) and Llama-2 70B (trained with 2 trillion tokens), suggesting that MatMul-free LM not only outperforms in efficiency, but can also outperform in terms of loss when scaled up.
Basically, if they’re right about their scaling laws, their proposed architecture would become both more efficient and more effective at current high-end industrial levels of investment, and strongly more efficient in the future.
So yes, this is a pretty big deal. It doesn’t seem to be a hoax or strongly overhyped. If I were a top lab, and my own secret sauce wasn’t obviously better than this, I’d want to look into it.
What are the limitations?
There are several. Broadly:
- The current architectural paradigm is complicated and expensive to change
- The new approach hasn’t been tested (publicly) with very large model sizes
- The new approach hasn’t been tested against the actual state of the art
We’ll take it from the top.
Transformers architecture is sticky
Cutting edge AI is a dance between software and hardware. Some particular software process gets good results. Whatever hardware happens to run that process best is now in demand, spurring investment both in whoever came up with the software process and whoever manufactures the relevant hardware. The hardware manufacturers optimize their hardware even better for the software, and the software developers optimize their software to leverage the new-and-improved hardware even better.[3]
For several years now, MatMul has been favored, which means GPUs that are good at MalMul are favored, and those GPUs are optimized to be extra good at - you guessed it - MatMul. Even if this research result is totally correct and a MatMul-free architecture would perform better in the abstract, many different stakeholders would have to get together to make it happen.
And it’s not just hardware! The qualified engineers, too - of which there is a rather limited capacity on the entire planet, fueling their very high salaries - have honed their instincts on the current paradigm. There’s a lot of new math to learn, then master, then make absolutely secondhand. Math like this (from the paper):
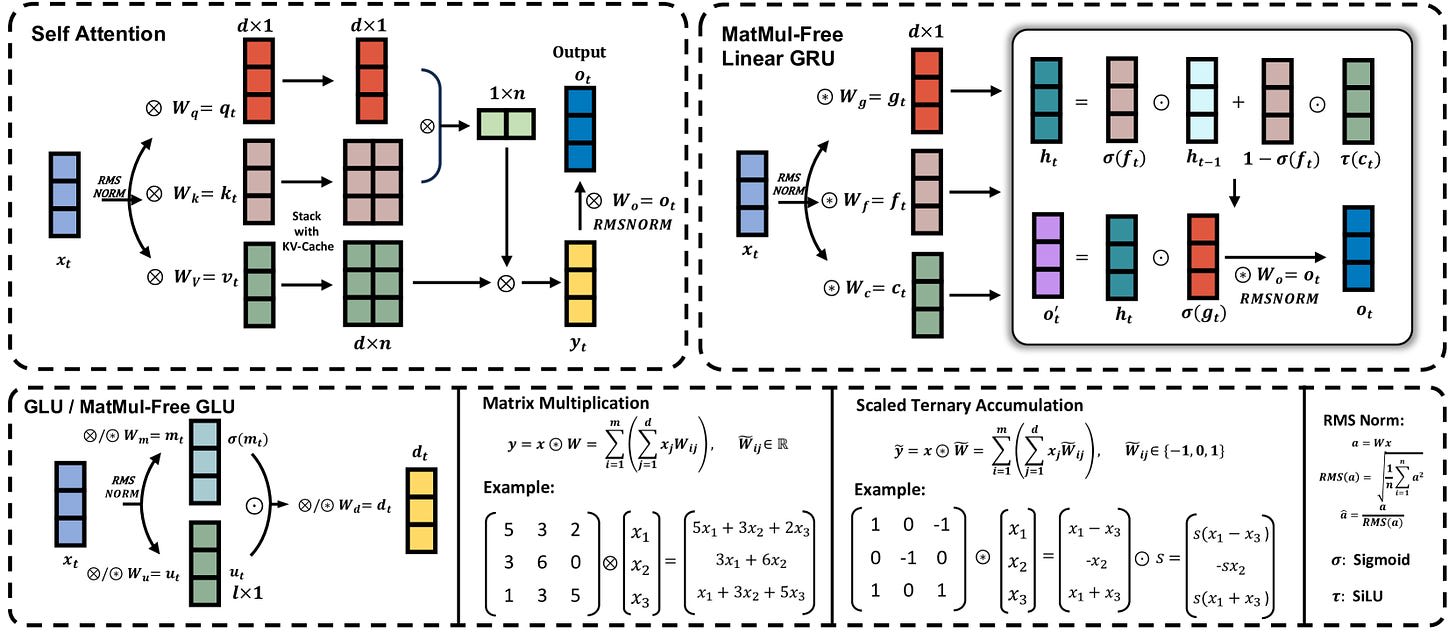
Nothing the most talented machine learning engineers in the world can’t figure out, but there’s a difference between understanding and deep understanding. The actual state of the art sometimes advances by yolo runs, and the powerfully honed instinct behind these runs isn’t developed overnight.
So even if this new architecture is a superior alternative, it might take a long time before its benefits outweigh its costs in practice. At least until we start hitting some walls, and architectural shifts are the only way forward.
Not tested at scale
The authors list this limitation in their conclusion, along with an exhortation for top labs to give their new architecture a try, like so:
However, one limitation of our work is that the MatMul-free LM has not been tested on extremely large-scale models (e.g., 100B+ parameters) due to computational constraints. This work serves as a call to action for institutions and organizations that have the resources to build the largest language models to invest in accelerating lightweight models.
Fair enough! And indeed, outside of major labs (which keep their lips zipped), you’re not going to find the compute you need to test this stuff at 100B scale. But part of the reason transformer scaling laws are so important is because they have been proven to work over quite a large range. With a new architecture, you can’t totally assume that new, different scaling laws will be equally ironclad.
Nor would it be that easy to test, even for top labs. Training huge models is expensive, and doing it right would likely require new hardware and lots of retraining for many of the most in-demand employees in the world. It’s not easy to see if or when that’ll be a priority.[4]
Not tested vs. cutting edge
This objection feels a little mean, but while the MatMul-free paper does test its new architecture against a strong open source implementation, it doesn’t benchmark itself against the cutting edge in absolute terms, because the real cutting edge is behind lock and key at top labs.
Of course, you have to measure against what you have, and it’s not like they are pumping up their numbers by comparing to obviously outdated architecture. But they aren’t proving that their new methods do well against the current best AI models. Which, again, is a reason for some doubt.
So… sell NVIDIA?
This is so not investment advice, but I mean, I haven’t.
I do think it’s an exciting sign (or a scary one) that we’re seeing research, in public, that suggests fundamental improvements to transformers architecture. Whether they truly are improvements, and whether those improvements can overcome years of inertia, remains to be seen.
In the meantime, provisionally, it’s time for new Anki cards.
- ^
Okay, not literally, since computational complexity doesn’t scale linearly with model size. But if you thought of that, why didn’t you skip the introduction?
- ^
They represent the current state of the art with the architecture of Llama 2, a not-exactly-cutting-edge but pretty good (and relatively open source) model.
- ^
Notably, one of the things Zhu et al. do in the paper is build custom hardware to better support their new architecture. Doing this as a proof of concept is really exciting, but very different from changing industrial processes at scale!
- ^
Or maybe it was already a priority two years ago, in secret, and all the top players are already doing it! Simply no way to know, though we might have seen reverberations in NVIDIA chip design, if that were true.
6 comments
Comments sorted by top scores.
comment by ryan_greenblatt · 2024-06-28T03:37:55.678Z · LW(p) · GW(p)
I'm quite skeptical of "this will be better around 10^23 flop" and their scaling laws overall.
I think if you properly quantified the uncertainty in the scaling law fit, the slope error bars would fully surrond the transformer slope and the 30% confidence interval would include "always worse". They seem to be extrapolating from three datapoints.
Further, a key aspect of their claimed scaling laws and intersection is that their method performs worse at smaller scale. They could end up with this result simply by tuning the hyperparameters less effectively for the small models in the sweep. It's easy to make performance worse (especially for your own method!), so I don't think this is very solid. (To be clear, I don't expect delibrate fraud, but it's easy to end up with incorrect results by accident here especially if you're fishing for optimistic findings.)
(I don't have a strong view on the relevance of the method overall, but the prior for this sort of paper is indicates a quite low chance of widespread adoption.)
Replies from: JustisMills↑ comment by JustisMills · 2024-06-28T04:55:25.839Z · LW(p) · GW(p)
Yeah, you've convinced me I was a little too weak just by saying "the scaling laws are untested" - I had the same feeling of like "maybe I'm getting Eulered here, and maybe they're Eulering themselves" with the 10^23 thing.
Mostly I just kept seeing suggested articles in the mainstream-ish tech press about this "wow, no MatMul" thing, assumed it was an overhyped exaggeration/misleading, and was pleasantly surprised it was for real (as far as it goes). But I'd give it probably... 15%? Of having industrial use cases in the next few years. Which I guess is actually pretty high! Could be nice for really really huge context windows, where scaling on input token length sucks.
comment by Foyle (robert-lynn) · 2024-06-28T04:27:52.304Z · LW(p) · GW(p)
There has been a lot of interest in this going back to at least early this year and the 1.58bit LLM (ternary) logic paper https://arxiv.org/abs/2402.17764 so expect there has been a research gold rush and a lot of design effort going into producing custom hardware almost immediately that was revealed.
With Nvidia dual chip GB200 Grace Blackwell offering (sparse) 40Pflop fp4 at ~1kW there has already been something close to optimal hardware available - that fp4 performance may have been the reason the latest generation Nvidia GPU are in such high demand - previous generations haven't offered it as far as I am aware. For comparison a human brain is likely equivalent to 10-100Pflops, though estimates vary.
Being able to up the performance significantly from a single AI chip has huge system cost benefits.
All suggesting that the costs for AI are going to drop yet again, and human level AGI operating costs are going to be measured in cents per hour when it arrives in a few years time.
The implications for autonomous robotics are likely tremendous, with potential OOM power savings likely to bring far more capable systems to smaller platforms, home robotics, fsd cars, and (scarily) military murderbots. Tesla has (according to Elon comments) a new HW5 autonomy chip coming out next year that is ~50x faster than their current FSD development baseline HW3 2 x 72Tflop chipset, but needs closer to 1kW power, so they will be extremely keen on implementing something that could save so much power.
Replies from: Vladimir_Nesov↑ comment by Vladimir_Nesov · 2024-06-28T14:07:35.665Z · LW(p) · GW(p)
has been a lot of interest in this going back to at least early this year
This is 2015-2016 tech though. The value of the recent ternary BitNet result is demonstrating that it works well for transformers (which wasn't nearly as much the case for binary BitNet).
The immediate practical value of this recent paper is more elusive: they try to do even more by exorcising multiplication from attention, which is a step in an important direction, but the data they get doesn't seem sufficient to overcome the prior that this is very hard to do successfully. Only Mamba got close to attention as a pure alternative (without the constraint of avoiding multiplication), and even then it has issues unless we hybridize it with (local) attention (which also works well with other forms of attention alternatives, better even than vanilla attention on its own).
comment by RussellThor · 2024-06-27T23:01:09.146Z · LW(p) · GW(p)
What about ASICs? I heard someone is making them for inference and of course claims an efficiency gain. ASIC improvement needs to be thought of as part of the status quo
Replies from: JustisMills↑ comment by JustisMills · 2024-06-28T02:40:51.705Z · LW(p) · GW(p)
Yeah, could cut both ways for this I think? On the one hand, if no-MatMul models really are more efficient in the long run, you could probably make custom hardware optimized for the stuff they require (e.g. lots of ternary stuff). But getting there from the ASICs currently in development would be a necessary pivot.
Maybe the race dynamics actually help slow things down here? Since nobody wants to pivot and fall temporarily behind; money might dry up or someone else might get there before the investment pays off and you leapfrog.
But yeah, even in the medium run, as constraints start to flare up, probably ASICs are a factor in changing up architectures.