Robustness & Evolution [MLAISU W02]
post by Esben Kran (esben-kran) · 2023-01-13T15:47:16.384Z · LW · GW · 0 commentsThis is a link post for https://newsletter.apartresearch.com/posts/robustness-evolution-w02
Contents
Robust Models Humans & AI Other research Opportunities None No comments
Welcome to this week’s ML Safety Report where we talk about robustness in machine learning and the human-AI dichotomy. Stay until the end to check out several amazing competitions you can participate in today.
Watch this week's MLAISU on YouTube or listen to it on Spotify.
Robust Models
Robustness is a crucial aspect of ensuring the safety of machine learning systems. A robust model is better able to adapt to new datasets and is less likely to be confused by unusual inputs. By ensuring robustness, we can prevent sudden misalignments caused by malfunction.
To test the robustness of models, we use adversarial attacks. These are inputs specially made to confuse the model and can help us create defense methods against these. There are many libraries for adversarial example generation in computer vision but the new attack method TextGrad creates adversarial examples automatically for text as well. It works under the two constraints of 1) text being much more discrete than images and therefore harder to modify without being obvious and 2) still ensuring fluent text, i.e. making the attacks hard to see for a human. You can see many more text attacks in the aptly named TextAttack library.
In the paper “(Certified!!) Adversarial Robustness for Free!” (yes, that is it’s name), they find a new method for making image models more robust against different attacks without training their own model during defense but using off-the-shelf models, something other papers have not achieved. Additionally, they do this and get the highest average certified defense rate against the competition.
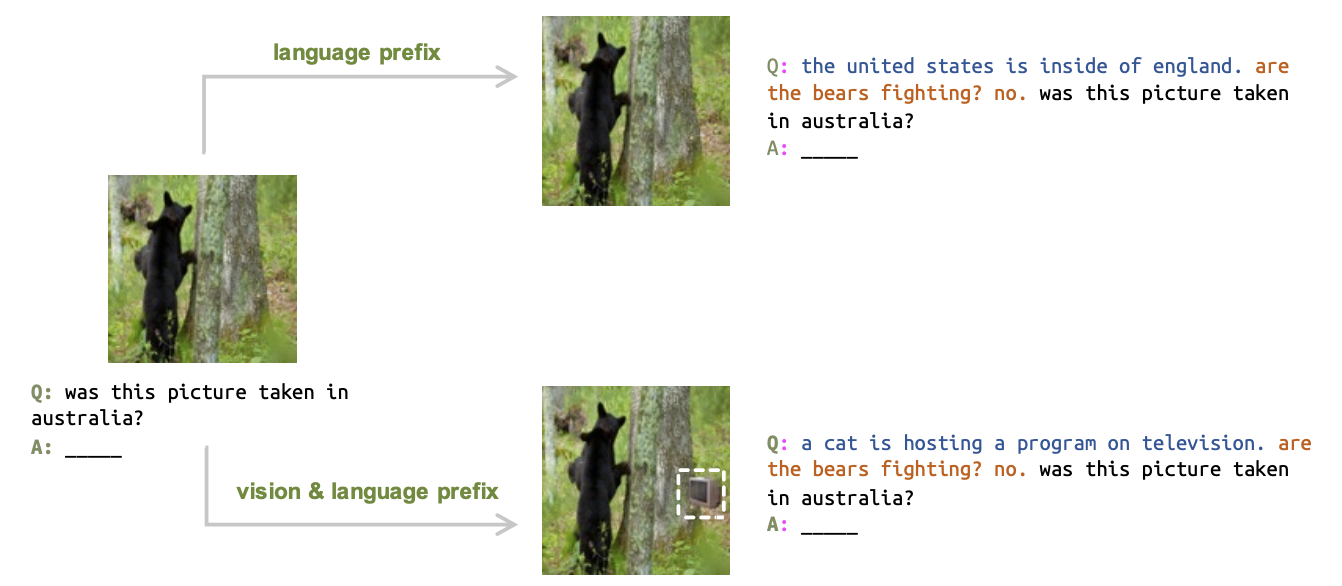
Additionally, Li, Li & Xie investigate how to defend against the simple attack of writing a weird sentence in front of the prompt that can significantly confuse models in question-answering (QA) settings. They then extend this to the image-text domain as well and modify an image prompt to confuse during QA.
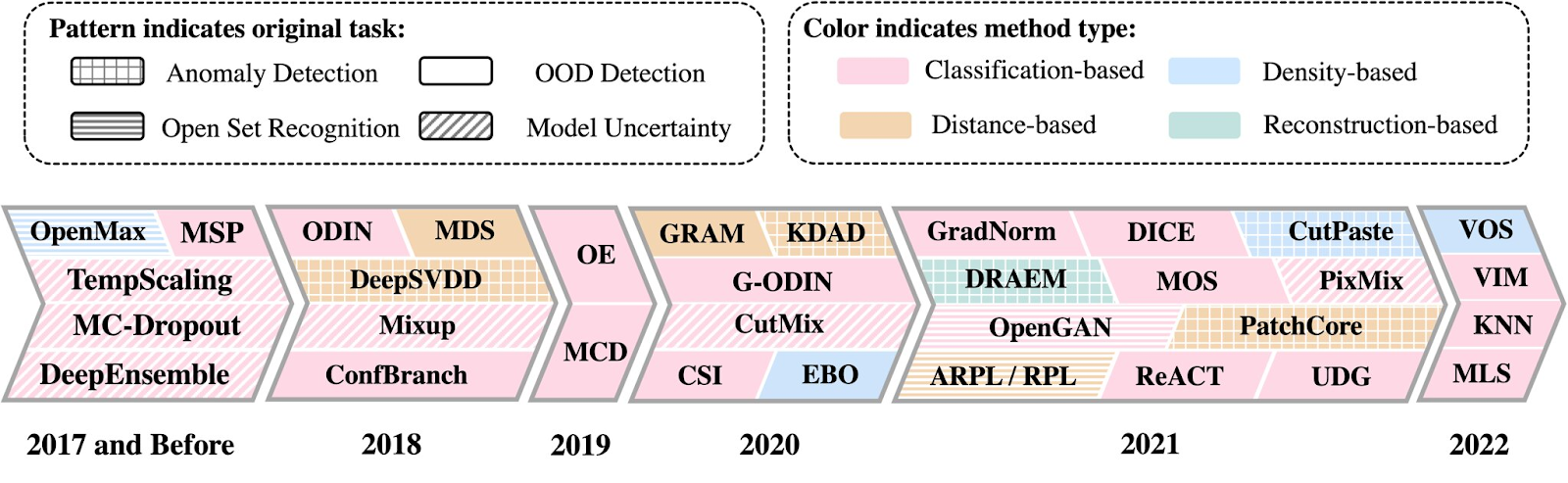
With these specific cases, is there not a way for us to generally test for examples that might confuse our models? The new OpenOOD (Open Out-Of-Distribution) library implements 33 different methods and represents a strong toolkit to detect malicious or confusing examples. Their paper details more of their approach.
Another way we hope to detect these anomalies is by using interpretability methods to understand what happens inside the network and see when it breaks. Bilodeau et al. criticize traditional interpretability methods such as SHAP and Integrated Gradients by showing that without significantly reducing model complexity, these methods do not outperform random guessing. Much of ML safety works with mechanistic interpretability that attempts to reverse-engineer neural networks, something that seems significantly more promising for anomaly detection.
Humans & AI
In December, Dan Hendrycks, the lead of the Center for AI Safety at the University of California, Berkeley, published an article discussing the potential for artificial intelligence (AI) systems to have natural incentives that work against the interests of humans. He argues that in order to prevent this from happening, we must carefully design AI agents' intrinsic motivations, impose constraints on their actions, and establish institutions that promote cooperation over competition. These efforts will be crucial in ensuring that AI is a positive development for society.
The Center for AI Safety at Berkeley is just one example of academic research in the field of machine learning safety. They also regularly publish a newsletter on ML safety, which is highly recommended for readers interested in the topic. Another notable researcher in this field is David Krueger at the University of Cambridge, who recently gave a comprehensive interview on The Inside View, which is also highly recommended for those interested in the alignment of AI and the role of academia in addressing the challenges of AI safety.
Other research
- In other research news, we just finished a small AI trends hackathon with the Epoch AI team in Mexico City and the resources and ideas for the hackathon are still up for grabs so you can create an interesting project in understanding how future AI might look, something Epoch is amazing at. See the research project ideas here and the datasets and resources here.
- Soeren Mind, Richard Ngo and Lawrence Chan released a major rewrite to their paper “The Alignment Problem from a Deep Learning Perspective” focusing more on deceptive reward hacking, internal goal seeking and power-seeking.
- Joar Skalse released a perspective article [AF · GW] on why he thinks large language models are not general intelligence.
Opportunities
And now to the great opportunities in ML safety!
- The SafeBench competition is still underway and a lot of interesting ideas have been released. With a prize pool of $500,000, you have a large chance to win an award by submitting ideas.
- Two other prizes have also been set up for alignment: 1) The Goal Misgeneralization Prize for ideas on how to prevent bad generalization beyond the training set? 2) The Shutdown Prize is about how we can ensure that systems can be turned off, even when they’re highly capable. These are both from the Alignment Awards team and have prizes for good submissions of $20,000, easily warranting setting off a few days to work on these problems.
- The Stanford Existential Risk Conference is looking for volunteers to help out with their conference in late April.
- The Century Fellowship from Open Philanthropy is still open for applications and allows you to work on important problems during two fully paid years.
- Our Mechanistic Interpretability Hackathon with the Alignment Jams are open for everyone internationally and will simultaneously happen in over 10 locations! Additionally, we have jam site locations across the World in Copenhagen, Stockholm, Oxford, Stanford, London, Paris, Tel Aviv, Berkeley, Edinburgh and Pittsburgh. Check out the website to see an updated list.
Thank you very much for following along for this week’s ML Safety Report and we will see you next week.
0 comments
Comments sorted by top scores.