AI Transparency: Why it’s critical and how to obtain it.
post by Zohar Jackson (zohar-jackson) · 2022-08-14T10:31:28.024Z · LW · GW · 1 commentsContents
AI Transparency Why it’s critical and how to obtain it Why Claim #4 is true for humans? How to build a sufficiently transparent AI? Potential issues What prevents the AI from having a dangerous thought and plan in one timestep? Leading to AI Safety None 1 comment
AI Transparency
Why it’s critical and how to obtain it
Claim #1 No amount of thought experiments on AI safety will be sufficient to be confident in the safety of a non-transparent AI. There is almost certainly a vector of attack or mode of failure which no one has imagined which will be exploitable by a sufficiently intelligent system. There are far too many ways things can go wrong.
Claim #2 Neural network based AI can not be proven to be safe except by exhaustive search over the input space. Since exhaustive search over input space is intractable, the safety of a NN based AI is intractable. As a thought experiment, consider a single weight can be the difference between a safe and an unsafe system, finding that weight and determining its safe ranges will require exhaustive search. It seems very unlikely that a mathematics or computation will be developed to solve this problem before we solve AGI.
Claim #3: Figuring out how to build an aligned system from a black box is far more challenging than figuring out how to build an aligned system from an interpretable, transparent box. This is true because a transparent box is safely debuggable and testable assuming it is designed such that Claim #4 holds true.
Claim #4 If you could read another person's (not AI) mind faster than they can think and disable them at the press of a button it would be impossible for that person to intentionally harm you without your consent. For as soon as the person starts thinking about harming you or tricking you… you can press the button and stop them. This holds true even if you are much less intelligent than the other person.
Claim #5 Building a transparent AI such that it thinks like a human and Claim #4 holds true is not all that difficult.
The first three claims are my personal intuitions and may very well turn out to be incorrect, but they seem quite grounded, and nothing exceptional is being claimed. Claims four and five are, in my opinion, the least obvious and least likely to be true so I will explain why I believe they are true.
Transparency does not solve the safety problem, but it is a super powerful tool to help us solve it. With transparency as described in Claim #4, we can safely bring up much more advanced agents and analyze them. We can safely learn how these types of agents fail and test various solutions. As long as humans are in the loop checking the AI’s thoughts and approving the next thought, we are safe.
Why Claim #4 is true for humans?
Humans can not have large complicated thoughts and plans in their mind at a given timestep. We can build complicated plans but must do it iteratively.
Let’s consider the example in Claim #4 of Person A and Person B, where Person B can read A’s mind and has access to a stop button. If Person A wants to harm Person B they would have to have a thought process as follows:
Timestep | Thought |
0 | I want to harm Person B |
1 | What is the best way? |
2 | Maybe I can charge him and push him (Plan #1) |
3 | No that won’t work, I am too far away and he is too close to the button |
4 | Maybe I can trick him to moving away from the button (Plan #2) |
5 | OK that might work. How can I do that? |
6 | etc…. |
Notice how many timesteps it takes to come up with a plan for how to achieve a goal. We all have this subjective experience so we know this is how humans work. Complex plans can not be constructed and analyzed in one timestep by the human mind.
Given that Person B can read each thought at each timestep, Person A has no chance of harming B.
Let’s define something called a “thought register” - this is the memory that contains the most recent thought. It is named after registers on computers, which are small memories that contain the data currently being processed. On a computer, registers have a limited quantity, size and are the only information on which the processor can do computations. Information must first be loaded into the register before it can be operated on. The same holds true for thought registers.
Unlike computer registers, human thought registers can contain information of many modalities (images, words, sounds) and can contain much more information than the registers of computers. A modern computer register typically stores 64 bits, while I estimate a thought register can store a few kilobits of data.
How to build a sufficiently transparent AI?
The short version of it is to build an AI such that:
- Computations and plans are forced to go though thought registers
- Thought registers are limited in capacity (a few kilobits)
- Though registers are limited in quantity
- The thought registers are fully transparent and their contents interpretable.
The first three requirements are relatively trivial, but the fourth one seems difficult. You might be thinking, “Making latent representations (registers) fully interpretable is a hard problem. People have been working on this for a long time. We don’t know how to do it”. What I propose is making the latent representations, i.e. the content of the thought register, be represented in English text. This means the AI will think in English.
The idea is to design a model that is recurrent over its thought registers. The individual neurons are not recurrent.
Here is how it looks:
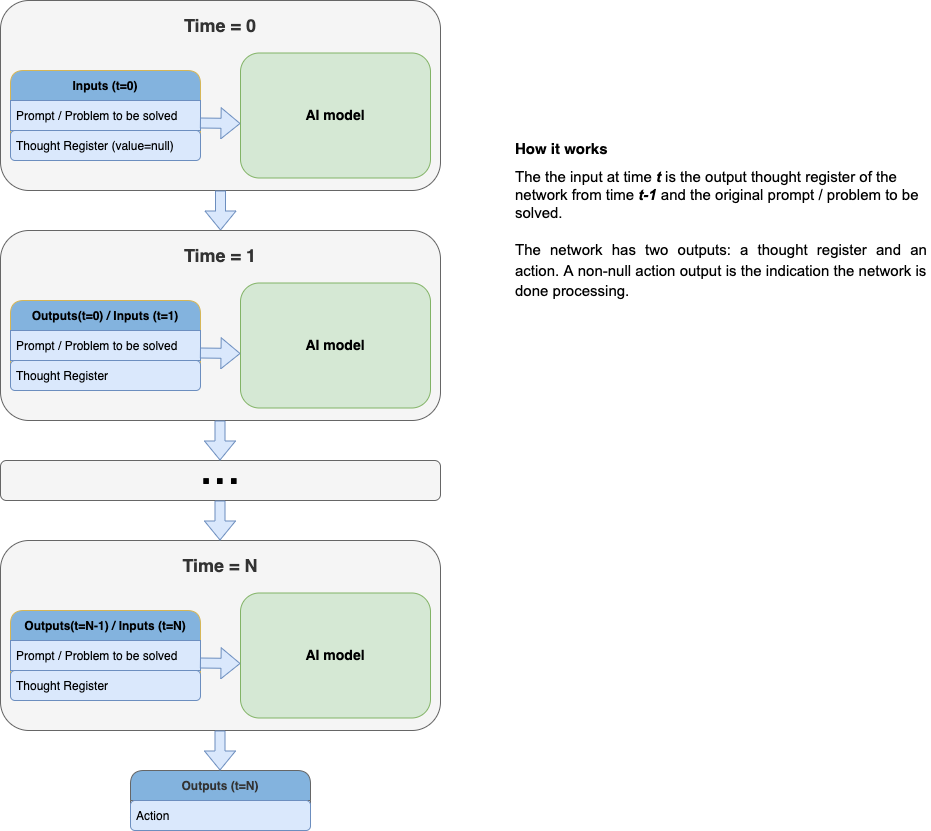
How would we actually build this?
I don’t have all the answers but it definitely seems that it’s within our current capabilities to build a model like this. I estimate a solid team of researchers could build a reasonably capable model with these constraints within a year. For example: we could start with a large language model and modify/fine tune it to work in this paradigm.
Potential issues
Alignment Tax. The proposed approach will likely reduce the performance of the AI and impose an alignment tax but it is not clear how large of a tax will be imposed. There are some reasons to believe the tax may be minimal or even negative as the registers can act as a regularizer and compressor which will lead to more general and parameter efficient models. In the future as we learn more about alignment, it might be possible to reduce the constraints on the thought registers and allow images and other forms of information which will reduce the tax.
Language corruption. After training the language used in the registers becomes gibberish and uninterpretable. This will have to be solved by training losses which force the language to remain interpretable.
Double meanings and hidden thoughts. In theory it’s possible the model will be able to use a language that has two meanings. One meaning is for itself and the other is to deceive the interpreter. IE it could encode hidden information in seemingly innocuous language. This is in theory possible but it seems unlikely to occur as losses and a training process would be chosen such that it would have no incentive to learn double meanings.
What prevents the AI from having a dangerous thought and plan in one timestep?
There are a number of ways of preventing this from happening. The simplest way I think is to train the network in such a way that it requires multiple timesteps to plan and take an action. If the training process trains it to only operate in this multistep way, it seems very unlikely that it will be able to do anything competent in a single timestep.
Leading to AI Safety
The proposed approach unfortunately does not solve the safety problem. We still have to align the agent’s goals with human goals, we still need to have a human in the loop to monitor the agent’s thought process and we still have no guarantees of safety even with the previous two conditions being met.
Despite this, transparency in this form provides a safe and powerful tool in solving safety. It is an extremely valuable tool that will bring us much closer to solving alignment. With this approach, we can learn how these types of agents fail and test various solutions. Many of the failure modes that plague black boxes are no longer a risk. For example: deception is no longer possible and instrumental goals will be obvious before the agent takes any action.
In conclusion it seems this approach is not all that technically challenging to implement and will most likely provide large value despite its alignment tax.
1 comments
Comments sorted by top scores.
comment by Gurkenglas · 2022-08-14T11:05:10.354Z · LW(p) · GW(p)
Language corruption. After training the language used in the registers becomes gibberish and uninterpretable. This will have to be solved by training losses which force the language to remain interpretable.
In the sense that you call some set of sentences interpretable, and only such sentences are allowed? Mightn't it learn an arbitrary mapping between meanings and sentences?