AISN #36: Voluntary Commitments are Insufficient Plus, a Senate AI Policy Roadmap, and Chapter 1: An Overview of Catastrophic Risks
post by Corin Katzke (corin-katzke), Julius (julius-1), Dan H (dan-hendrycks) · 2024-06-05T17:45:25.261Z · LW · GW · 0 commentsThis is a link post for https://newsletter.safe.ai/p/ai-safety-newsletter-35-voluntary
Contents
Voluntary Commitments are Insufficient Senate AI Policy Roadmap Chapter 1: Overview of Catastrophic Risks Links None No comments
Welcome to the AI Safety Newsletter by the Center for AI Safety. We discuss developments in AI and AI safety. No technical background required.
Subscribe here to receive future versions.
Listen to the AI Safety Newsletter for free on Spotify.
Voluntary Commitments are Insufficient
AI companies agree to RSPs in Seoul. Following the second AI Global Summit held in Seoul, the UK and Republic of Korea governments announced that 16 major technology organizations, including Amazon, Google, Meta, Microsoft, OpenAI, and xAI have agreed to a new set of Frontier AI Safety Commitments.
Some commitments from the agreement include:
- Assessing risks posed by AI models and systems throughout the AI lifecycle.
- Setting thresholds for severe risks, defining when a model or system would pose intolerable risk if not adequately mitigated.
- Keeping risks within defined thresholds, such as by modifying system behaviors and implementing robust security controls.
- Potentially halting development or deployment if risks cannot be sufficiently mitigated.
These commitments amount to what Anthropic has termed Responsible Scaling Policies (RSPs). Getting frontier AI labs to develop and adhere to RSPs has been a key goal of some AI safety political advocacy — and, if labs follow through on their commitments, that goal will have been largely accomplished.
RSPs are useful as one part of a “defense in depth” strategy, but they are not sufficient, nor are they worth the majority of the AI safety movement’s political energy. There have been diminishing returns to RSP advocacy since the White House secured voluntary AI safety commitments last year.
Crucially, RSPs are voluntary and unenforceable, and companies can violate them without serious repercussions. Despite even the best intentions, AI companies are susceptible to pressures from profit motives that can erode safety practices. RSPs do not sufficiently guard against those pressures.
Binding legal requirements to prioritize AI safety are necessary. In a recent essay for the Economist, Helen Toner and Tasha McCauley draw on their experience as former OpenAI board members to argue that AI companies can’t be trusted to govern themselves. Instead—as is the case in other industries—government must establish effective safety regulation.
One promising area of regulation is compute security and governance. Compute is a scarce and necessary input to AI development. By placing legal obligations on AI chip designers, manufacturers, and cloud providers, governments can gain visibility into AI development and enforce regulations. Future work could explore enforcement mechanisms that are embedded within compute via software and hardware mechanisms.
Senate AI Policy Roadmap
The Senate AI Working Group releases an AI Roadmap. A group of senators led by Chuck Schumer released a highly-anticipated roadmap for US AI policy, which comes after the group held a yearlong series of forums with industry experts.
Some key proposals from the roadmap include:
- Providing “at least $32 billion per year for (non-defense) AI innovation.”
- Legislation for “training, retraining, and upskilling the private sector workforce to successfully participate in an AI-enabled economy.”
- Transparency, testing, and evaluation of AI systems, especially in high-impact areas like financial services and healthcare.
- Requiring “watermarking and digital content provenance related to AI-generated or AI-augmented election content.”
- Investigate the “feasibility of options to implement on-chip security mechanisms for high-end AI chips.”
- Maintaining a competitive edge in AI, such as by “bolstering the use of AI in U.S. cyber capabilities.”

The Senate AI Working Group, which consists of Maj. Leader Chuck Schumer, Sen. Mike Rounds, Sen. Martin Heinrich, and Sen. Todd Young. (Forbes)
However, the roadmap has faced backlash from AI ethics experts. According to Fast Company, some AI experts who participated in the group’s forums view the roadmap as “bending over backwards to accommodate the industry’s interests, while paying only lip service to the need for establishing guardrails around this emerging technology.”
In response to the roadmap, 13 organizations jointly released a “Shadow Report to the US Senate AI Policy Roadmap.” The Shadow Report criticizes the Senate's approach, claiming it fails to adequately regulate the AI industry and protect the public interest. Taylor Jo Isenberg, Executive Director at Economic Security Project, listed the following gaps addressed by the report:
- Non-discrimination rules that provide equal access and treatment for businesses that depend on a provider’s services
- Resourcing enforcement agencies to enforce the law
- Protecting privacy and ensuring data portability and interoperability
- Building public capacity on AI to ensure innovations that contribute to the public good
- Investing in expertise in government to engage meaningfully with shifts in technology
Chapter 1: Overview of Catastrophic Risks
Our new book, Introduction to AI Safety, Ethics, and Society, is now available for free online and will be published by Taylor & Francis in the next year. We’re also running a course for the book, and applications are due by May 31st.
In the coming weeks, the newsletter will include some summaries highlighting a few key themes from the book. In this story, we’ll begin with Chapter 1: Overview of Catastrophic AI Risks. This chapter outlines four key sources of potential catastrophic risk from advanced AI systems: malicious use, AI race dynamics, organizational risks, and rogue AIs.
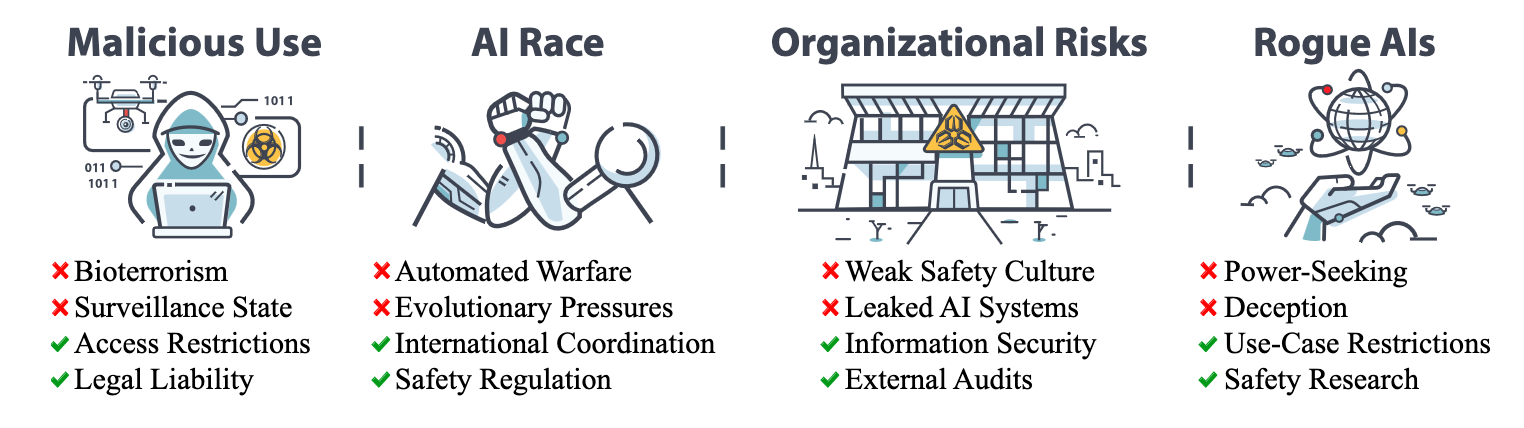
“Malicious use” refers to bad actors using AI for harmful purposes. Malicious use could include engineering deadly bioweapons, releasing uncontrolled AI agents, using AI for disinformation campaigns, and concentrating authoritarian power. As AI systems become increasingly capable, they will greatly amplify the harm bad actors could cause.
“Racing dynamics” describes competitive pressures that can lead nations and companies to under-prioritize safety in order to gain an edge in AI development. A military AI arms race could heighten risks of powerful autonomous weapons, cyberattacks, and rapid escalation to war through automated decision-making. In a commercial AI race, companies might rush AI systems to market without adequate safeguards in order to keep up with rivals. Either way, actors might take on more risk of AI catastrophe if they believe falling behind competitors threatens their survival.
Organizational risks stem from the immense challenge of safely handling such complex and poorly understood systems. Even with the best expertise and intentions, catastrophic accidents can happen, like with the Challenger Space Shuttle disaster. Cutting-edge AI systems are far less well-understood than even rockets and nuclear plants where disasters have occurred. Developing a robust safety culture in AI companies and regulators is paramount.
Finally, “Rogue AI” refers to challenges posed by AI systems that might deliberately seek to escape human control. Highly intelligent AI systems might find unintended ways to optimize their objectives, which is known as “proxy gaming”. They might learn deceptive behaviors and stop cooperating with their human operators. They might also discover incentives to accumulate power in order to achieve their goals.
Here is the chapter’s accompanying video.
Links
- The UK AI Safety Institute announced a program for fast grants in systemic AI safety. It also published a technical blog post on its work testing models for cyber, chemical, biological, and agent capabilities and safeguards effectiveness.
- NIST launched ARIA, a new program to advance sociotechnical testing and evaluation for AI.
- The US Safety Institute published a document outlining its strategic vision. The institute “aims to address key challenges, including a lack of standardized metrics for frontier AI, underdeveloped testing and validation methods, limited national and global coordination on AI safety issues, and more.”
- Amazon and Meta joined the Frontier Model Forum.
- Convergence Analysis published the 2024 State of the AI Regulatory Landscape, a high-level overview of the current state of global AI regulation.
- CSET’s Foundational Research Grants program is calling for research ideas that would expand and improve the toolkit for frontier model releases.
- Google AI Overview has been giving false and dangerous advice.
- Armed robot dogs demonstrate their capabilities in Chinese military exercises.
- OpenAI published a safety update following the AI Seoul Summit.
- An explanation of SB 1047, a new bill in the California Legislature.
- In the midst of training its next frontier model, OpenAI forms a safety and security committee to provide recommendations for the company.
- After raising $6 billion in series B funding, xAI is now valued at $24 billion.
See also: CAIS website,CAIS twitter,A technical safety research newsletter,An Overview of Catastrophic AI Risks, our new course, and our feedback form
Listen to the AI Safety Newsletter for free on Spotify.
Subscribe here to receive future versions.
0 comments
Comments sorted by top scores.