Exploring the Platonic Representation Hypothesis Beyond In-Distribution Data
post by rokosbasilisk · 2024-10-20T08:40:04.404Z · LW · GW · 2 commentsContents
What's Next? None 2 comments
The Platonic Representation Hypothesis (PRH) suggests that models trained with different objectives and on various modalities can converge to a shared statistical understanding of reality. While this is an intriguing idea, initial experiments in the paper focused on image-based models (like ViT) trained on the same pretraining (ImageNet) dataset. This raises an important question:
Does PRH hold only when models are trained on data from the same distribution?
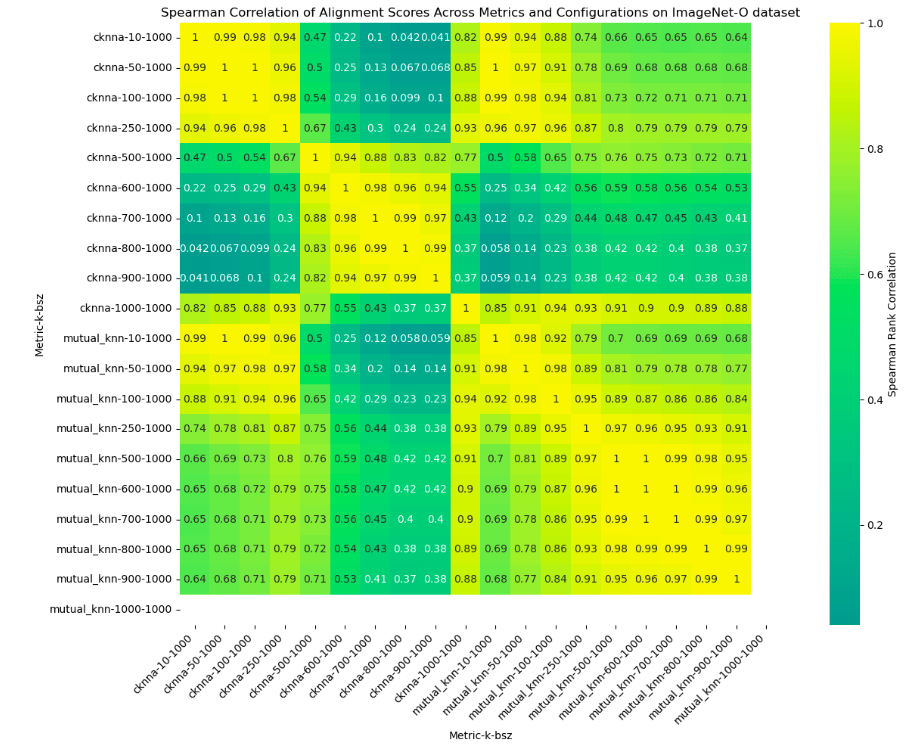
To explore this question, the experiment was extended to ImageNet-O—a dataset specifically designed with out-of-distribution (OOD) images compared to ImageNet. Using ImageNet-O, the correlation analysis of alignment scores across various metrics for image classification models was re-evaluated.
The outcome? PRH holds true in the OOD setting as well, which challenges the notion that a shared data distribution is a prerequisite for this convergence. This observation carries significant implications for AI alignment research, suggesting that a deeper underlying structure may govern how models develop representations of reality, even when the training data differs.
Below are the correlation plots comparing results from the original in-distribution experiment to those with OOD data:
But does this mean that the model's align even for purely randomly generated data?
The answer is NO.
This plot shows the correlation of the alignment scores for the models on purely randomly generated images.
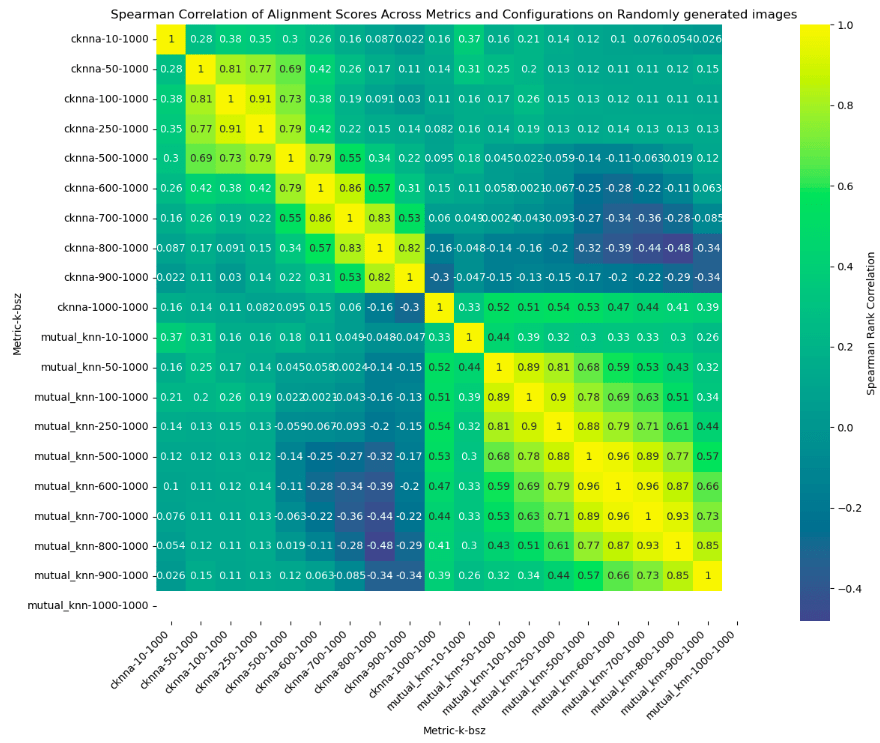
One key observation here is:
- On randomly generated data, PRH is not so true, I.e, the models did not share a statistical model of reality.
- On OOD data of ImageNet-O dataset they have shared, and have high correlation. But on ImageNet-O the predictions are wrong but with higher confidence.I.e, all the models classified the images wrongly on this outlier data yet predictably. This is particularly interesting since we can infer that they fail predictably.
The notebook documenting these experiments is available here.
What's Next?
The next step in this research is to identify datasets or conditions where PRH might be falsifiable
2 comments
Comments sorted by top scores.
comment by jacob_drori (jacobcd52) · 2024-10-21T05:47:03.641Z · LW(p) · GW(p)
This seems very interesting, but I think your post could do with a lot more detail. How were the correlations computed? How strongly do they support PRH? How was the OOD data generated? I'm sure the answers could be pieced together from the notebook, but most people won't click through and read the code.
Replies from: rokosbasilisk↑ comment by rokosbasilisk · 2024-10-21T07:40:36.179Z · LW(p) · GW(p)
Thanks for the feedback! working on refining the writeup.