Ophiology (or, how the Mamba architecture works)
post by Danielle Ensign (phylliida-dev), SrGonao (srgonao), Adrià Garriga-alonso (rhaps0dy) · 2024-04-09T19:31:09.975Z · LW · GW · 8 commentsContents
A new challenger arrives! Promising Scaling Efficient Inference What are State-space models? Solving the ODE Euler method Zero-Order Hold (ZOH) Discretization rule used in Mamba Specific Quirks to Mamba The structured SSM The case of a 1-Dimensional input The Mamba implementation Selection mechanism WΔ is low rank RMSNorm Full Architecture Dimensions Notes on reading these graphs Overview Layer contents SSM Further reading Appendix Conv1D Explanation Worked Conv Example Conv1D in code None 8 comments
The following post was made as part of Danielle's MATS work on doing circuit-based mech interp on Mamba, mentored by Adrià Garriga-Alonso. It's the first in a sequence of posts about finding an IOI circuit in Mamba/applying ACDC to Mamba.
This introductory post was also made in collaboration with Gonçalo Paulo.
A new challenger arrives!
Why Mamba?
Promising Scaling
Mamba [1] is a type of recurrent neural network based on state-space models, and is being proposed as an alternative architecture to transformers. It is the result of years of capability research [2] [3] [4] and likely not the final iteration of architectures based on state-space models.
In its current form, Mamba has been scaled up to 2.8B parameters on The Pile and on Slimpj, having similar scaling laws when compared to Llama-like architectures.
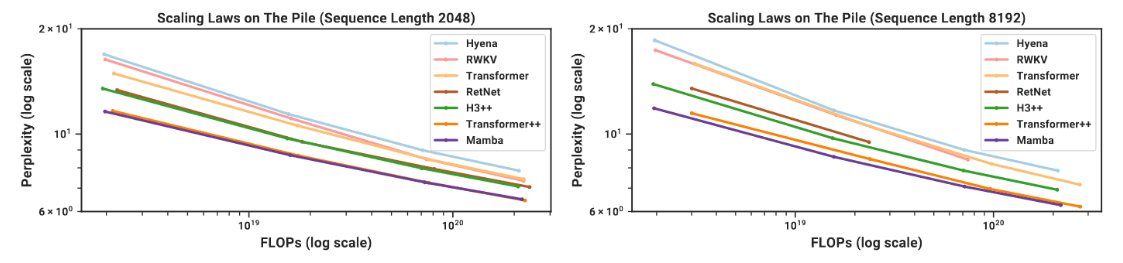
Scaling curves from Mamba paper: Mamba scaling compared to Llama (Transformer++), previous state space models (S3++), convolutions (Hyena), and a transformer inspired RNN (RWKV)
More recently, ai21labs [5] trained a 52B parameter MOE Mamba-Transformer hybrid called Jamba. At inference, this model has 12B active parameters and has benchmark scores comparable to Llama-2 70B and Mixtral.
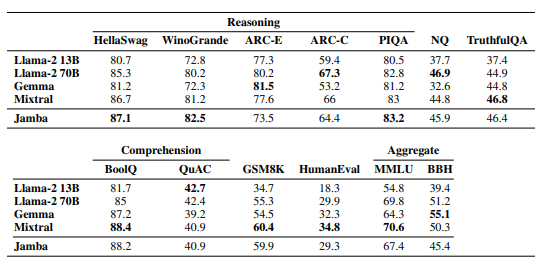
Jamba benchmark scores, from Jamba paper [5:1]
Efficient Inference
One advantage of RNNs, and in particular of Mamba, is that the memory required to store the context length is constant, as you only need to store the past state of the SSM and of the convolution layers, while it grows linearly for transformers. The same happens with the generation time, where predicting each token scales as instead of .
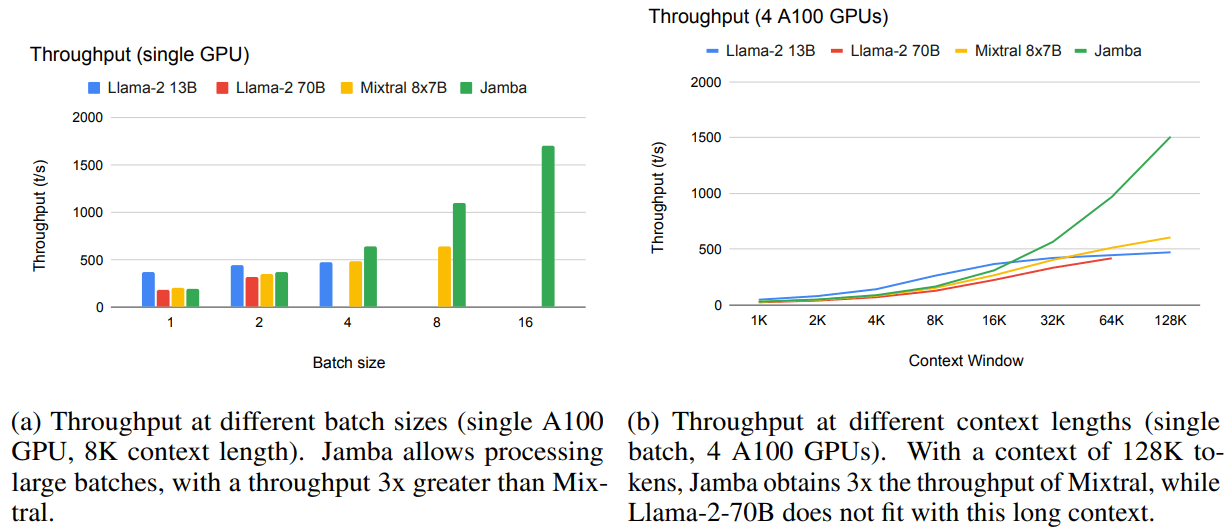
Jamba throughput (tokens/second), from Jamba paper[5:2]
What are State-space models?
The inspiration for Mamba (and similar models) is an established technique used in control theory called state space models (SSM). SSMs are normally used to represent linear systems that have p inputs, q outputs and n state variables. To keep the notation concise, we will consider the input as E-dimensional vector , an E-dimensional output and a N-dimensional latent space . In the following, we will note the dimensions of new variables using the notation [X,Y]. In particular, in Mamba 2.8b, E=5120 and N=16.
Specifically, we have the following:
This is an ordinary differential equation (ODE), where is the derivative of with respect to time, t. This ODE can be solved in various ways, which will be described below.
In state space models, is called the state matrix, is called the input matrix, is called the output matrix, and is called the feedthrough matrix.
Solving the ODE
We can write the ODE from above as a recurrence, using discrete timesteps:
where and are our discretization matrices. Different ways of integrating the original ODE will give different and , but will still preserve this overall form.
In the above, corresponds to discrete time. In language modeling, refers to the token position.
Euler method
The simplest way to numerically integrate an ODE is by using the Euler method, which consists in approximating the derivative by considering the ratio between a small variation in h and a small variation in time, . This allows us to write:
Where the index t, of , represents the discretized time. This is the similar to when considering a character's position and velocity in a video game, for instance. If a character has a velocity and a position , to find the position after time we can do . In general:
Turning back to the above example, we can rewrite
as
which means that, for the Euler Method, and .
Here, is an abbreviation of , the discretization size in time.
Zero-Order Hold (ZOH)
Another way to integrate the ODE is to consider that the input remains fixed during a time interval , and to integrate the differential equation from time to . This gives us an expression for :
With some algebra we finally get:
Discretization rule used in Mamba
Mamba uses a mix of Zero-Order Hold and the Euler Method:
Why is this justified? Consider the ZOH :
In Mamba, is diagonal, as we will see later, so we can write
If we consider that is small and we expand the exponential to just first order [6], this expression reduces to 1 which means that:
for small enough . Using the same approximation for recovers the Euler method:
In the original work, the authors argued that while ZOH was necessary for the modeling of , using the Euler Method for gave reasonable results, without having to compute .
Specific Quirks to Mamba
The structured SSM
Mamba takes an interesting approach to the SSM equation. As previously mentioned, each timestep in Mamba represents a token position, and each token is represented (by the time it arrives to the SSM) by a E dimensional vector. The authors chose to represent the SSM as:
The case of a 1-Dimensional input
When trying to understand Mamba, I find it's easiest to start with each being a single value first, and then working up from there. The standard SSM equation is, then:
The authors of the original Mamba paper were working on top of previous results on Structured SSMs. Because of this, in this work, A is a diagonal matrix. This means that A can be represented as a set of N numbers instead of a matrix. That gives us:
Where is an element-wise product. In this example we are mapping a -dimensional input to a -dimensional hidden state, then mapping the -dimensional hidden state back to a dimensional output.
The Mamba implementation
In practice, and are not one dimensional, but -dimensional vectors. Mamba simply maps each of these elements separately to a dimensional hidden space. So we can write a set of E equations:
Where ranges from . This means that each dimension of input to the SSM block is modeled by its own, independent, SSM. We will see that, due to the selection mechanism (see below) are a function of all the dimensions of the input, not just the dimension e.
One thing to note: In practice, has a separate value for each , and is encoded as an matrix. We can denote as the -sized entry for stream , giving us,
Selection mechanism
Mamba deviates from the simplest SSM approaches, and from the previous work of the authors, by making matrices B and C dependent on the input, x(t). Not only that, but the time discretization is also input dependent. This replaces the equations shown above, with one which takes the form:
Where the new matrices are given by:
with being learned parameters, and
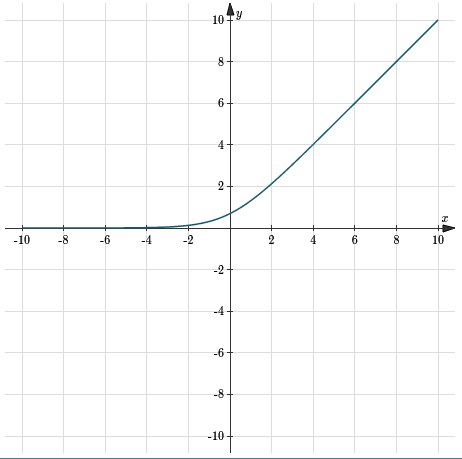
softplus
One final thing to note: A is not a trainable parameter, and what is actually trained is . is then computed as (using element-wise exp). This ensures is a strictly negative number. Because is always postitive, this ensures that the first term of SSM can be seen as how much of the previous state is kept at a given token position, while the second term is related to how much it is written to the state.
In turn, this implies that is between 0 and 1. This is important for stable training: it ensures that the elements of do not grow exponentially with token position , and the gradients do not explode. It is long known [7] that the explosion and vanishing of gradients are obstacles to training RNNs, and successful architectures (LSTM, GRU) minimize these.
is low rank
In Mamba, they don't encode as an matrix. Instead, it is encoded as two smaller matrices:
Where, for example, ,
This makes this term
Be instead
RMSNorm
This normalization is not unique to Mamba. It's defined as
If was instead , this first term would be normalizing along the dimension. Because it's there's an extra term, and we can rewrite this as:
The reason we want to do this is so that each element's value is on average 1, as opposed to the whole activation's vector. Since the introduction of the He initialization [8], deep learning weights have been initialized so the activation variance is 1 assuming the input variance is 1, thus keeping gradients stable throughout training.
Full Architecture
Now that we know how the SSM works, here is the full architecture.
Dimensions
(Example values from state-spaces/mamba-370m)
- is the batch size
- is the context length
- is the dimension of the residual stream
- is the dimension of the embed size
- is the dimension of the state space
- is the low rank size used when calculating delta, see section 4.4
Notes on reading these graphs
- Text not in circles/squares are variable names/size annotations
- Rounded, white rectangles are mathmatical operations
- Shaded triangles are learned params
- Shaded squares are learned params that are projections
- Shaded circles are conv or rms norm (other operations that have some learned params)
Overview
Mamba has:
- Embedding
- Residual stream that each layer adds to
- RMSNorm
- Project to logits
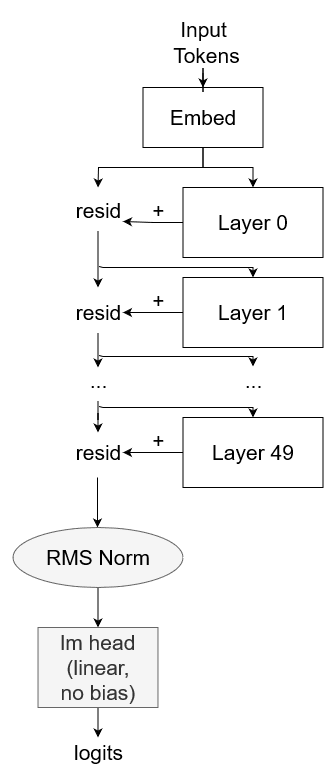
High level overview of Mamba
# [B,L,D] [B,L]
resid = mamba.embedding(input_ids)
for layer in mamba.layers:
# [B,L,D] [B,L,D]
resid += layer(resid)
# [B,L,D] [B,L,D]
resid = mamba.norm( resid )
# [B,L,V] [D->V] [B,L,D]
logits = mamba.lm_head( resid ) # no bias
return logits
Layer contents
Each layer does:
- Project input to
- Project input to
- Conv over the dimension (see Appendix) ()
- Apply non-linearity (silu) ()
- Gating:
- Project to
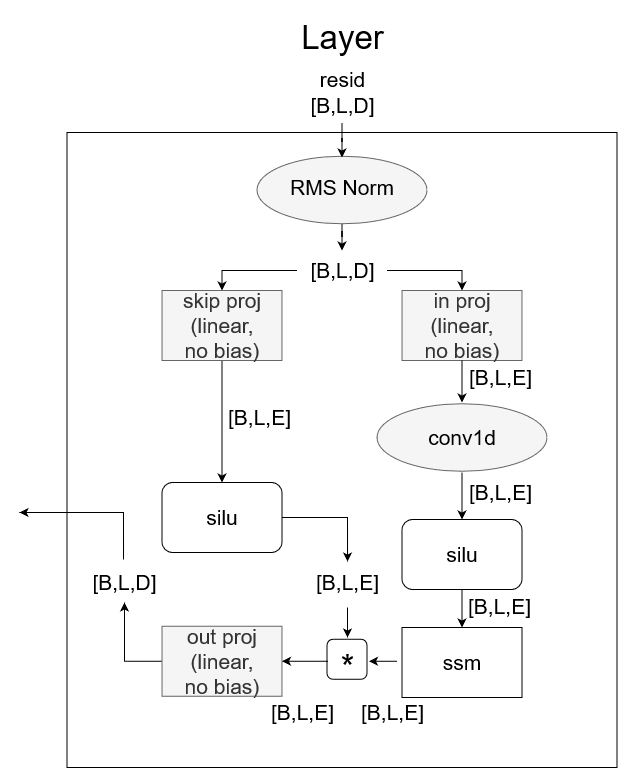
Mamba layer overview
silu
def forward(layer, resid):
## Process inputs ##
# [B,L,D] [B,L,D]
x = resid
# [B,L,D] [B,L,D]
x = layer.norm( x )
# [B,L,E] [D->E] [B,L,D]
skip = layer.skip_proj( x ) # no bias
# [B,L,E] [D->E] [B,L,D]
x = layer.in_proj( x ) # no bias
## Conv ##
# [B,E,L]
x = rearrange(x, 'B L E -> B E L')
# [B E L] [B,E,L] conv1d outputs [B,E,3+L], cut off last 3
x = layer.conv1d( x )[:, :, :L]
# [B,L,E]
x = rearrange(x, 'B E L -> B L E')
## Non-linearity ##
# silu(x) = x * sigmoid(x)
# silu(x) = x * 1/(1+exp(-x))
# [B,L,E] [B,L,E]
x = F.silu( x )
## SSM ##
# [B,L,E] [B,L,E]
y = ssm( layer, x )
## Gating ##
# [B,L,E] [B,L,E] [B,L,E]
y = y * F.silu( skip )
## Project out ##
# [B,L,D] [E->D] [B,L,E]
y = layer.out_proj( y ) # no bias
return y
SSM
From above:
where are learned parameters, and
def ssm(layer, x):
# stored as A_log
layer.A = -torch.exp(layer.A_log)
ys = []
# every (e) has a 1-D ssm
for e in range(E):
ys_e = []
# latent state, init to zeros
h_e = torch.zeros(Batch,N)
for l in range(L):
#### First, discretization: A and B -> Abar and Bbar ####
## Compute Delta ##
# [E,1] [E,D_Delta] [D_delta,1]
inner_term = layer.W_delta_1.weight.T@layer.W_delta_2.weight.T[:,e].view(D_Delta,1)
# [1] [E] [E] [1]
delta = F.softplus(x[:,e].dot(inner_term.view(E)) + layer.W_delta_2.bias[e])
## Discretize A ##
# [B,N] ( [B,1] * [N] )
A_bar = torch.exp(delta * layer.A[e])
## Discretize B ##
# [B,N] [E->N] [B,E]
B = layer.W_B(x[b,l]) # no bias
# [B,N] [B,1] [B,N]
B_bar = delta * B
#### Update latent vector h ####
## input float for the ssm at time l
# [B] [B]
x_l = x[:,l,e]
## move ahead by one step
# [B,N] [B,N] [B,N] [B,N] [B,1]
h_e = A_bar * h + B_bar * x_l.view(B,1)
#### Compute output float y ####
## (C matrix needed for computing y)
# [B,N] [E->N] [B,E]
C_l = layer.W_C(x[:,l]) # no bias
## Output a float y at time l
# [B] [B,N] [B,N]
y_l = (h*C_l).sum(dim=-1) # dot prod
ys_e.append(y_l)
# list of [L,B]
ys.append(ys_e)
## Code expects this transposed a bit
# [E,L,B]
y = torch.tensor(ys)
# [B,L,E] [B,E,L]
y = rearrange( y , "E L B -> B L E")
## Add the D term (we can do this outside the loop)
# [B,L,E] [B,L,E] [B,L,E] [E]
y = y + x * D
return y
Or, vectorized, and computing non-h terms ahead of time (since they don't depend on the recurrence)
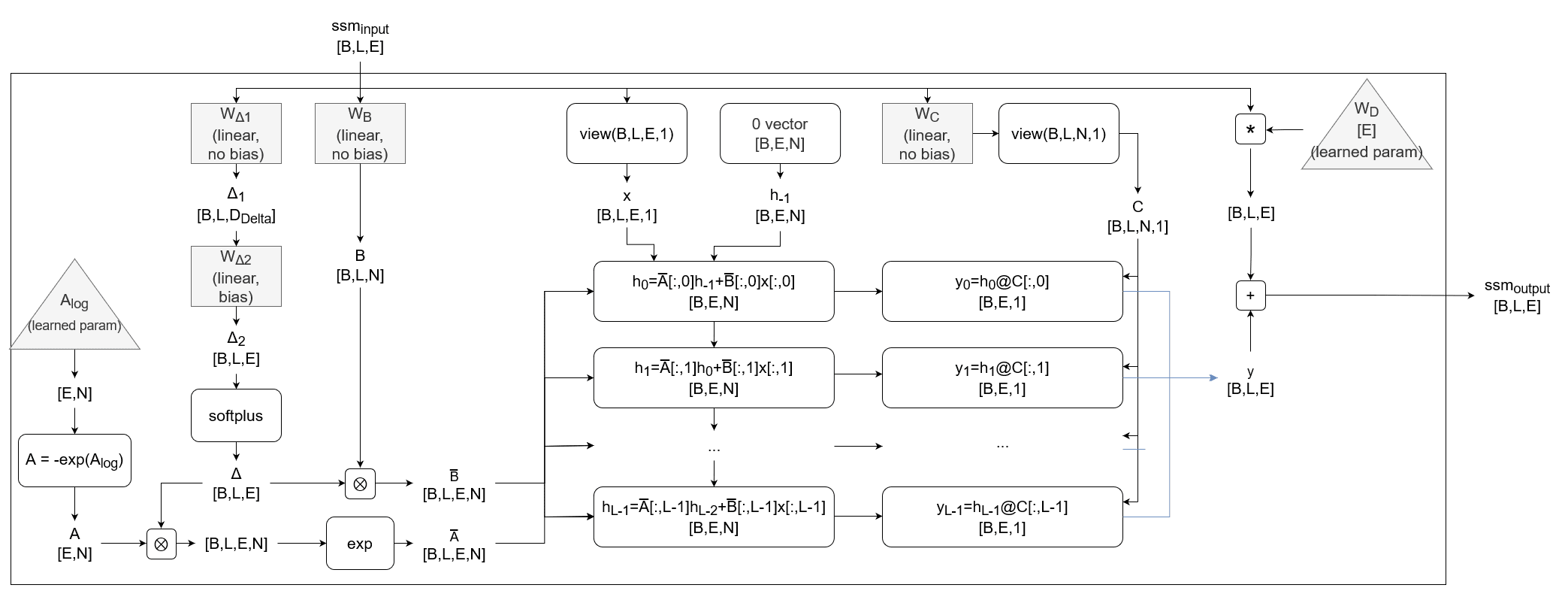
Selective SSM
def ssm(self, x):
# [E,N]
self.A = -torch.exp(self.A_log)
## Compute Delta ##
# [B,L,D_delta] [E->D_delta] [B,E]
delta_1 = self.W_delta_1( x ) # no bias
# [B,L,E] [D_delta->E] [B,L,D_delta]
delta_2 = self.W_delta_2( delta_1 ) # with bias
# [B,L,E] [B,L,E]
delta = F.softplus(delta_2)
## B
# [B,L,N] [E->N] [B,L,E]
B = self.W_B( x )
## C
# this just applies E->N projection to each E-sized vector
# [B,L,N] [E->N] [B,L,E]
C = self.W_C( x ) # no bias
## Discretize A
# [B,L,E,N] [B,L,E] [E,N]
A_bar = torch.exp(einsum(delta, self.A, 'b l e, e n -> b l e n'))
## Discretize B
# [B,L,E,N] [B,L,E] [B,L,N]
B_bar = einsum( delta, B, 'b l e, b l n -> b l e n')
# Now we do the recurrence
ys = []
# latent state, init to zeros
h = torch.zeros([Batch,E,N])
for l in range(L):
# [B,E,N] [B,E,N] [B,E,N] [B,E,N] [B,E]
h = h * A_bar[:,l,:,:] + B_bar[:,l,:,:] * x[:,l].view(Batch, E, 1)
# this is like [E,N] x [N,1] for each batch
# [B,E] [B,E,N] [B,N,1]
y_l = h @ C[:,l,:].view(Batch,N,1)
# [B,E] [B,E,1]
y_l = y_l.view(Batch,E)
ys.append(y_l)
# we have lots of [B,E]
# we need to stack them along the 1 dimension to get [B,L,E]
y = torch.stack(ys, dim=1)
## Add the D term
# [B,L,E] [B,L,E] [B,L,E] [E]
y = y + x * self.W_D
return y
Also keep in mind: In the official implementation, is called , and some matrices are concatenated together (this is numerically equivalent, but helps performance as it's a fused operation):
- and
- ,
Further reading
- Mamba paper
- Jamba paper
- MambaLens, Danielle's TransformerLens port to Mamba
- Minimal mamba implementation, which heavily inspired the code here
- Official mamba implementation at https://github.com/state-spaces/mamba
- Mamba interp brainstorming document
- Extracting attention maps from mamba See some examples here
- Mamba as a bilinear control system
- nnsight mamba mech interp colab (by woog)
- Understanding SSMs in Mamba (by Gonçalo Paulo)
- National Deep Inference Facility Discord (s6-interp channel)
- Mechanistic Interpretability Group Discord (mamba-interp channel, also when browing mamba-interp, click on threads in the top right and see the math subthread)
- Eleuther AI Discord (rnn-interp channel and its threads)
Appendix
Here's some further info on how Mamba's 1D conv works, for those unfamiliar. This is not unique to Mamba, conv is a standard operation usually used in image processing.
Conv1D Explanation
The basic unit of a Conv1D is applying a kernel to a sequence.
For example, say my kernel is [-1,2,3] and my sequence is [4,5,6,7,8,9].
Then to apply that kernel, I move it across my sequence like this:
[*4,5,6*, 7,8,9]
-1*4 + 2*5 + 3*6 = 24
[4, *5,6,7*, 8,9]
-1*5 + 6*2 + 3*7 = 28
[4,5, *6,7,8*, 9]
-1*6 + 2*7 + 3*8 = 32
[4,5,6, *7,8,9*]
-1*7 + 2*8 + 3*9 = 36
So our resulting vector would be [24, 28, 32, 36]
It's annoying that our output is smaller than our input, so we can pad our input first:
[0,0,4,5,6,7,8,9,0,0]
Now we get
[*0,0,4* ,5,6,7,8,9,0,0]
-1*0 + 2*0 + 3*4 = 12
[0, *0,4,5*, 6,7,8,9,0,0]
-1*0 + 2*4 + 3*5 = 23
[0,0, *4,5,6*, 7,8,9,0,0]
-1*4 + 2*5 + 3*6 = 24
[0,0,4, *5,6,7*, 8,9,0,0]
-1*5 + 6*2 + 3*7 = 28
[0,0,4,5, *6,7,8*, 9,0,0]
-1*6 + 2*7 + 3*8 = 32
[0,0,4,5,6, *7,8,9*, 0,0]
-1*7 + 2*8 + 3*9 = 36
[0,0,4,5,6,7, *8,9,0*, 0]
-1*8 + 2*9 + 3*0 = 10
[0,0,4,5,6,7,8, *9,0,0*]
-1*9 + 2*0 + 3*0 = -9
So our result is [12, 23, 24, 28, 32, 36, 10, -9]
Now this is longer than we need, so we'll cut off the last two, giving us
[12, 23, 24, 28, 32, 36]
Worked Conv Example
Mamba conv is defined as
layer.conv1d = nn.Conv1d(
in_channels=E,
out_channels=E,
bias=True,
kernel_size=D_conv,
groups=E,
padding=D_conv - 1,
)
In this example, I will set:
E = d_inner = 5 (for large models this is 2048-5012)
D_conv = kernel_size = 4 (for large models this is 4)
L = context size = 3
In practice, D_conv=4 and E is around 2048-5012.
Our input to to mamba's conv1d is of size [B, E, L]. I'll do a single batch.
Because groups = E = 5, we have 5 filters:
[ 0.4, 0.7, -2.1, 1.1] filter 0 with bias [0.2]
[ 0.1, -0.7, -0.3, 0.0] filter 1 with bias [-4.3]
[-0.7, 0.9, 1.0, 0.9] filter 2 with bias [-0.3]
[-0.5, -0.8, -0.1, 1.5] filter 3 with bias [0.1]
[-0.9, -0.1, 0.2, 0.1] filter 4 with bias [0.2]
Let our context be:
"eat" "apple" "bees"
Represented as embedding vectors
[0.86, -0.27, 1.65, 0.05, 2.34] "eat"
[-1.84, -1.79, 1.10, 2.38, 1.76] "apple"
[1.05, -1.78, 0.16, -0.30, 1.91] "bees"
First we pad
[0.00, 0.00, 0.00, 0.00, 0.00]
[0.00, 0.00, 0.00, 0.00, 0.00]
[0.00, 0.00, 0.00, 0.00, 0.00]
[0.86, -0.27, 1.65, 0.05, 2.34] "eat"
[-1.84, -1.79, 1.10, 2.38, 1.76] "apple"
[1.05, -1.78, 0.16, -0.30, 1.91] "bees"
[0.00, 0.00, 0.00, 0.00, 0.00]
[0.00, 0.00, 0.00, 0.00, 0.00]
[0.00, 0.00, 0.00, 0.00, 0.00]
Now to apply our first filter, we grab the first element of every vector
[* 0.00*, 0.00, 0.00, 0.00, 0.00]
[* 0.00*, 0.00, 0.00, 0.00, 0.00]
[* 0.00*, 0.00, 0.00, 0.00, 0.00]
[* 0.86*, -0.27, 1.65, 0.05, 2.34] "eat"
[*-1.84*, -1.79, 1.10, 2.38, 1.76] "apple"
[* 1.05*, -1.78, 0.16, -0.30, 1.91] "bees"
[* 0.00*, 0.00, 0.00, 0.00, 0.00]
[* 0.00*, 0.00, 0.00, 0.00, 0.00]
[* 0.00*, 0.00, 0.00, 0.00, 0.00]
Giving us
[0,0,0,0.86,-1.84,1.05,0,0,0]
Now we apply filter 0 [ 0.4, 0.7, -2.1, 1.1] with bias [0.2]
[*0,0,0,0.86*,-1.84,1.05,0,0,0]
0.4*0 + 0.7*0 + -2.1*0 + 1.1*0.86 = 0.946 + 0.2 = 1.146
[0,*0,0,0.86,-1.84*,1.05,0,0,0]
0.4*0 + 0.7*0 + -2.1*0.86 + 1.1*-1.84 = -3.83 + 0.2 = -3.63
[0,0,*0,0.86,-1.84,1.05*,0,0,0]
0.4*0 + 0.7*0.86 + -2.1*-1.84 + 1.1*1.05 = 5.621 + 0.2 = 5.821
[0,0,0,*0.86,-1.84,1.05,0*,0,0]
0.4*0.86 + 0.7*-1.84 + -2.1*1.05 + 1.1*0 = -3.149 + 0.2 = -2.949
[0,0,0,0.86,*-1.84,1.05,0,0*,0]
0.4*-1.84 + 0.7*1.05 + -2.1*0 + 1.1*0 = -0.001 + 0.2 = 0.199
[0,0,0,0.86,-1.84,*1.05,0,0,0*]
0.4*1.05 + 0.7*0 + -2.1*0 + 1.1*0 = 0.42 + 0.2 = 0.62
So our output of filter 0 is
[1.146, -3.63, 5.821, -2.949, 0.199, 0.62]
Now we cut off the last two (to give us same size output as L), giving us
[1.146, -3.63, 5.821, -2.949]
For filter 1, we grab the second element
[0.00, * 0.00*, 0.00, 0.00, 0.00]
[0.00, * 0.00*, 0.00, 0.00, 0.00]
[0.00, * 0.00*, 0.00, 0.00, 0.00]
[0.86, *-0.27*, 1.65, 0.05, 2.34] "eat"
[-1.84, *-1.79*, 1.10, 2.38, 1.76] "apple"
[1.05, *-1.78*, 0.16, -0.30, 1.91] "bees"
[0.00, * 0.00*, 0.00, 0.00, 0.00]
[0.00, * 0.00*, 0.00, 0.00, 0.00]
[0.00, * 0.00*, 0.00, 0.00, 0.00]
Giving us
[0,0,0,-0.27,-1.79,-1.78,0,0,0]
Now we apply filter 1 [ 0.1, -0.7, -0.3, 0.0] with bias [0.2]
etc.
Conv1D in code
Here's what that means in code:
def mamba_conv1d(x, conv):
# x is [B, E, L]
CONV = D_Conv-1 # D_conv=4 for mamba-370m
filters = conv.weight # filters is [E, 1, D_conv]
bias = conv.bias # bias is [E]
with torch.no_grad():
# first we pad x to [B, E, CONV+L+CONV]
B, E, L = x.size()
x = torch.nn.functional.pad(x, (CONV,CONV), mode='constant', value=0)
res = torch.zeros([B, E, CONV+L])
for b in range(B):
# one filter for each element of the E-sized vectors
for filter_i in range(E):
# filter is 4 values, go across words
filter = filters[filter_i, 0]
# scan across all the places
for starting_pos in range(CONV+L):
output = 0.0
for i, f in enumerate(filter):
output += x[b, filter_i, starting_pos+i]*f
res[b, filter_i, starting_pos] = output+bias[filter_i]
return res
Albert Gu and Tri Dao. Mamba: Linear-time sequence modeling with selective state spaces, 2023. https://arxiv.org/abs/2312.00752 ↩︎
Albert Gu, Tri Dao, Stefano Ermon, Atri Rudra, and Christopher Re. Hippo: Recurrent memory with optimal polynomial projections, 2020. https://arxiv.org/abs/2008.07669 ↩︎
Albert Gu, Karan Goel, and Christopher Re. Efficiently modeling long sequences with structured state spaces, 2022. https://arxiv.org/abs/2111.00396 ↩︎
Daniel Y. Fu, Tri Dao, Khaled K. Saab, Armin W. Thomas, Atri Rudra, and Christopher R ́e. Hungry hungry hippos: Towards language modeling with state space models, 2023. https://arxiv.org/abs/2212.14052 ↩︎
Opher Lieber, Barak Lenz, Hofit Bata, Gal Cohen, Jhonathan Osin, Itay Dalmedigos, Erez Safahi, Shaked Meirom, Yonatan Belinkov, Shai Shalev-Shwartz, Omri Abend, Raz Alon, Tomer Asida, Amir Bergman, Roman Gloz-man, Michael Gokhman, Avashalom Manevich, Nir Ratner, Noam Rozen, Erez Shwartz, Mor Zusman, and Yoav Shoham. Jamba: A hybrid transformer-mamba language model, 2024. https://arxiv.org/abs/2403.19887 ↩︎ ↩︎ ↩︎
The Taylor series expansion of at is And if we just consider the first-order terms, then we get ↩︎
Pascanu, Razvan, Tomas Mikolov, and Yoshua Bengio. "On the difficulty of training recurrent neural networks." International Conference on Machine Learning, 2013. https://arxiv.org/abs/1211.5063 ↩︎
He, Kaiming, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. "Delving deep into rectifiers: Surpassing human-level performance on ImageNet classification." In Proceedings of the IEEE International Conference on Computer Vision, pp. 1026-1034. 2015. https://arxiv.org/abs/1502.01852 ↩︎
8 comments
Comments sorted by top scores.
comment by Neel Nanda (neel-nanda-1) · 2024-04-09T23:07:59.532Z · LW(p) · GW(p)
Thanks for the clear explanation, Mamba is more cursed and less Transformer like than I realised! And thanks for creating and open sourcing Mamba Lens, it looks like a very useful tool for anyone wanting to build on this stuff
comment by Chakshu Mira (chakshu-mira) · 2024-05-02T22:05:26.715Z · LW(p) · GW(p)
## Discretize B ## # [B,N] [E->N] [B,E] B = layer.W_B(x[b,l]) # no bias
Shouldn't this be x[:,l] instead of x[b,l]?
comment by Chakshu Mira (chakshu-mira) · 2024-04-18T21:42:54.516Z · LW(p) · GW(p)
E
Did you mean 'D' here? (2nd equation of the structured SSM)
Replies from: rhaps0dy↑ comment by Adrià Garriga-alonso (rhaps0dy) · 2024-04-19T02:19:09.191Z · LW(p) · GW(p)
Thank you! Could you please provide more context? I don't know what 'E' you're referring to.
Replies from: chakshu-mira↑ comment by Chakshu Mira (chakshu-mira) · 2024-04-22T20:46:15.331Z · LW(p) · GW(p)
y_t=[N]C[E,N]h_t+[E] <this one> E [E]xt
Shouldn't this be 'D'?
Replies from: phylliida-dev↑ comment by Danielle Ensign (phylliida-dev) · 2024-04-22T21:11:58.094Z · LW(p) · GW(p)
fixed :)
comment by Chakshu Mira (chakshu-mira) · 2024-04-18T01:08:10.937Z · LW(p) · GW(p)
Replies from: phylliida-devIs this a typo? (Δtvt+1)xt−1
↑ comment by Danielle Ensign (phylliida-dev) · 2024-04-22T16:50:13.391Z · LW(p) · GW(p)
Fixed, thank you!