Contextual Translations - Attempt 1
post by Varshul Gupta · 2023-08-21T14:30:06.194Z · LW · GW · 0 commentsThis is a link post for https://dubverseblack.substack.com/p/9f5f8cfc-f85e-42c1-ae62-588b69e824f6
Contents
NLLB with context High-level architecture overview Training procedure Roadblocks faced None No comments
Who doesn’t enjoy anything built to their liking? That which is custom-made for themselves and seemingly consistent with what their personal demands are instead of relying on an external factor or agency.
I think this analogy fits quite well with what we’re aiming at Dubverse across our entire dubbing tech stack. From speech-to-text to machine translation to text-to-speech, everything is being researched and engineered, to make the systems more customised for our users use-cases.
In our previous blog post, we hinted that we are working on implementing custom machine translation.
NLLB with context
NLLB is a Sequence-to-Sequence translation model designed to provide translation across 200 languages!
It works quite well and comes close to the quality of translations from GCP based on some of our internal evaluations. But an issue both these services face is the lack of context retrievals when working with a continuous stream of related input sentences to translate. This becomes extremely important in the case of videos/audio content, e.g. the gender has to be kept consistent across multiple lines. ChatGPT is much higher flexibility in this aspect, as context could be maintained either via chat thread(or sequence), or we can play around within the prompt itself (to the extent token limit allows).
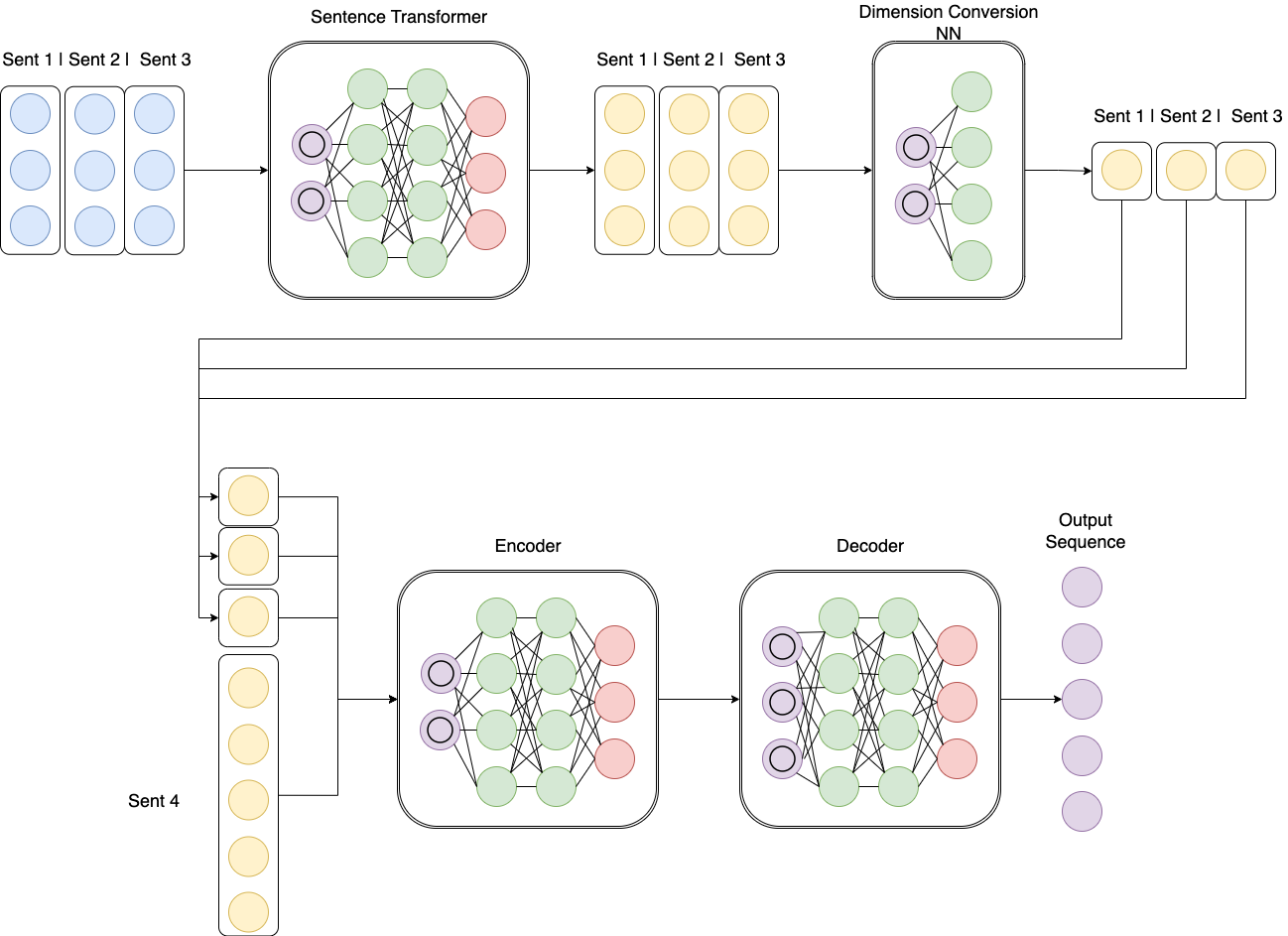
So, we got curious and started working on implementing context-aware NLLB by modifying its architecture. This is being done by adding custom transformer layers between the encoder and decoder to remember the context.
Draw.io
High-level architecture overview
To start off, we consider context as maximum of 3 sentences (Sent 1, Sent 2, Sent 3) before the current sentence (Sent 4) at hand whose translation is to be generated. The previous sentences are passed through sentence transformer to get their embeddings (lets call it “st-embedding’) of dimension 768. We then add a trainable neural network (`Dimension Conversion NN` mentioned above) that converts the dimension of each “st-embedding” to embedding dimension of NLLB’s encoder, i.e. 512.
We take these 512 dimension embeddings of each of these context sentences and append them to the NLLB embeddings layer output, i.e., if a sentence had length of 7 tokens, output’s dimension after the embedding layers appended to the transformed “st-embeddings” would be (7+3)x512.
Training procedure
This is still WIP, but idea revolves around training in a constrained environment.
Step 1 - finetuning
Keep the entire nllb model frozen and train only the `Dimension Conversion NN` model mentioned above. This would hopefully align the new parameters to align better with the rest of the model.
Step 2 - more finetuning
Unfreeze some lower layers of the nllb encoder alongside, hoping to strengthen the integration of the new neural network into the model architecture.
Step 3 - LoRA
LoRA has been widely adopted in the open source LLM world and given the compute constraints, we jumped onto its potential. We use `peft` library to finetune the above model using LoRA, to align the model to the new translation paradigm.
Roadblocks faced
We started off with using HuggingFace NLLB module, but modifying it had its fair share of issues. It required us to modify some of the Hugging Face model classes (was bit of a struggle due to the numerous custom wrappers in their codebase), mainly to pass the sentence embeddings as input to the model.
Preparing & preprocessing our dataset, setting up appropriate data-loader and so on was also a bit of a task, making this flow productionizable will be a whole new undertaking. Training these custom models will be time&resource-intensive.
One thing to note is, this is still a hypothesis and we are currently working to see if such a technique will be able to actually solve the context related translation errors, or beyond. So far, our model is just hallucinating (spitting out garbage), so, still working on enhancing this system. Will be sharing further over the coming weeks with updates and more.
Subscribe
Thank you for reading this! We hope you learned something different today.
Do visit our website and follow us on Twitter.
We also launched NeoDub sometime back. It enables you to clone your voice and speak any language!
Until next time!
0 comments
Comments sorted by top scores.