Equilibrium and prior selection problems in multipolar deployment
post by JesseClifton · 2020-04-02T20:06:14.298Z · LW · GW · 11 commentsContents
A learning game model of multipolar AI deployment The equilibrium selection problem The prior selection problem Acknowledgements None 11 comments
To avoid catastrophic conflict in multipolar AI scenarios [AF · GW], we would like to design AI systems such that AI-enabled actors will tend to cooperate. This post is about some problems facing this effort and some possible solutions. To explain these problems, I'll take the view that the agents deployed by AI developers (the ''principals'') in a multipolar scenario are moves in a game. The payoffs to a principal in this game depend on how the agents behave over time. We can talk about the equilibria of this game, and so on. Ideally, we would be able to make guarantees like this:
- The payoffs resulting from the deployed agents' actions are optimal with respect to some appropriate "welfare function''. This welfare function would encode some combination of total utility, fairness, and other social desiderata;
- The agents are in equilibrium --- that is, no principal has an incentive to deploy an agent with a different design, given the agents deployed by the other principals.
The motivation for item 1 is clear: we want outcomes which are fair by each of the principals' lights. In particular, we want an outcome that the principals will all agree to. And item 2 is desirable because an equilibrium constitutes a self-enforcing contract; each agent wants to play their equilibrium strategy, if they believe that the other agents are playing the same equilibrium. Thus, given that the principals all say that they will deploy agents that satisfy 1 and 2, we could have some confidence that a welfare-optimal outcome will in fact obtain.
Two simple but critical problems need to be addressed in order to make such guarantees: the equilibrium and prior selection problems. The equilibrium selection problem is that this deployment game will have many equilibria. Even if the principals agree on a welfare function, it is possible that many different profiles of agents optimize the same welfare function. So the principals need to coordinate on the profile of agents deployed in order to make guarantees like 1 and 2. Moreover, the agents will probably have private information, such as information about their payoffs, technological capabilities, and so on. As I will explain below, conflicting priors about private information can lead to suboptimal outcomes. And we can’t expect agents to arrive at the same priors by default. So a prior selection problem also has to be solved.
The equilibrium selection problem is well-known. The prior selection problem is discussed less. In games where agents have uncertainty about some aspect of their counterparts (like their utility functions), the standard solution concept --- Bayesian Nash equilibrium --- requires the agents to have a common prior over the possible values of the players' private information. This assumption might be very useful for some kinds of economic modeling, say. But we cannot expect that AI agents deployed by different principals will have the same priors over private information --- or even common knowledge of each others' priors --- in all of their interactions, in the absence of coordination[1].
It might be unnatural to think about coordinating on a prior; aren't your priors your beliefs? How can you change your beliefs without additional evidence? But there may be many reasonable priors to have, especially for a boundedly rational agent whose "beliefs'' are (say) some complicated property of a neural network. This may be especially true when it comes to beliefs about other agents' private information, which is something that's particularly difficult to learn about from observation (see here for example). And while there may be many reasonable priors to have, incorrect beliefs about others' priors could nonetheless have large downsides[2]. I give an example of the risks associated with disagreeing priors later in the post.
Possible solutions to these problems include:
- Coordination by the principals to build a single agent;
- Coordination by the principals on a profile of agents which are in a welfare-optimal equilibrium;
- Coordination by the principals on procedures for choosing among equilibria and specifying a common prior at least in certain high-stakes interactions between their agents (e.g., interactions which might escalate to destructive conflict).
Finally, a simple but important takeaway of the game-theoretic perspective on multipolar AI deployment is that it is not enough to evaluate the safety of an agent's behavior in isolation from the other agents that will be deployed. Whether an agent will behave safely depends on how other agents are designed to interact, including their notions of fairness and how they form beliefs about their counterparts. This is more reason to promote coordination by AI developers, not just on single-agent safety measures but on the game theoretically-relevant aspects of their agents' architectures and training.
A learning game model of multipolar AI deployment
In this idealized model, principals simultaneously deploy their agents. The agents take actions on the principals' behalf for the rest of time. Principal has reward function , which their agent is trying (in some sense) to maximize. I'll assume that perfectly captures what principal values, in order to separate alignment problems from coordination problems. The agent deployed by principal is described by a learning algorithm .
At each time point , learning algorithms map histories of observations to actions . For example, these algorithms might choose their actions by planning according to an estimated model. Let be a discount factor and the (partially observed) world-state at time . Denote policies for agent by . Write the world-model estimated from data (which might include models of other agents) as . Let be the expectation over trajectories generated udner policy and model . Then this model-based learning algorithm might look like: In a multiagent setting, each agent’s payoffs depend on the learning algorithms of the other agents. Write the profile of learning algorithms as . Then we write the expected cumulative payoffs for agent when the agents described by are deployed as .
The learning game is the game in which strategies are learning algorithms and payoffs are long-run rewards . We will say that is a learning equilibrium if it is a Nash equilibrium of the learning game (cf. Brafman and Tennenholtz). Indexing all players except by , this means that for each
Let be a welfare function measuring the quality of payoff profile generated by learning algorithm profile . For instance, might simply be the sum of the individual payoffs: . Another candidate for is the Nash welfare. Ideally we would have guarantees like 1 and 2 above with respect to an appropriately-chosen welfare function. Weaker, more realistic guarantees might look like:
- is a -optimal equilibrium with respect to the agents' world-models at each time-step (thus not necessarily an equilibrium with respect to the true payoffs), or
- The actions recommended by constitute a -optimal equilibrium in sufficiently high-stakes interactions, according to the agents' current world-models.
The equilibrium and prior selection problems need to be solved to make such guarantees. I'll talk about these in the next two subsections.
The equilibrium selection problem
For a moment, consider the reward functions for a different game: an asymmetric version of Chicken (Table 1)[3]. Suppose players 1 and 2 play this game infinitely many times. The folk theorems tell us that there a Nash equilibrium of this repeated game for every profile of long-run average payoffs in which each player gets at least as much as they can guarantee themselves unilaterally ( for player 1 and for player 2). Any such payoff profile can be attained in equilibrium by finding a sequence of action profiles that generates the desired payoffs, and then threatening long strings of punishments for players who deviate from this plan. This is a problem, because it means that if a player wants to know what to do, it's not sufficient to play a Nash equilibrium strategy. They could do arbitrarily badly if their counterpart is playing a strategy from a different Nash equilibrium.
So, if we want to guarantee that the players don't end up playing lots of 's, it is not enough to look at the properties of a single player. For instance, in the case of AI, suppose there are two separate AI teams independently training populations of agents. Each AI team wants to teach their agents to behave "fairly" in some sense, so they train them until they converge to an evolutionary stable strategy in which some "reasonable'' welfare function is maximized. But, these populations will likely be playing different equilibria. So disaster could still arise if agents from the two populations are played against each other[4].
Then how do players choose among these equilibria, to make sure that they're playing strategies from the same one? It helps a lot if the players have an opportunity to coordinate on an equilibrium before the game starts, as the principals do in our multipolar AI deployment model.
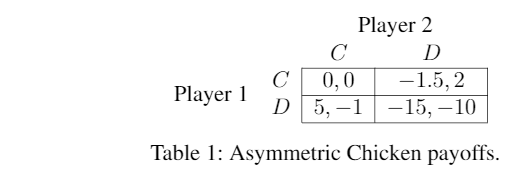
One intuitively fair solution would be alternating between and at each step. This would lead to player 1 getting an average payoff of 1.75 and player 2 getting an average payoff of 0.5. Another solution might be arranging moves such that the players get the same payoff (equal to about ), which in this case would mean playing twelve 's for every seven 's. Or, player 2 might think they can demand more because they can make player 1 worse-off than player 1 can make them. But, though they may come to the bargaining table with differing notions of fairness, both players have an interest in avoiding coordination failures. So there is hope that the players would reach some agreement, given a chance to coordinate before the game.
Likewise, the learning game introduced above is a complex sequential game --- its payoffs are not known at the outset, but can be learned over time. And this game will also have different equilibria that correspond to different notions of fairness. One solution is for the principals to coordinate on a set of learning algorithms which jointly maximize a welfare function and punish deviations from this optimization plan, in order to incentivize cooperation. I discuss this approach in example 5.1.1 here [AF · GW] and in this draft.
The problem of enforcement is avoided if the principals coordinate to build a single agent, of course. But it's not clear how likely this is to happen, so it seems important to have solutions which require different degrees of cooperation by the principals. On the other hand, what if the principals are not even able to fully coordinate on the choice of learning algorithms? The principals could at least coordinate on bargaining procedures that their agents will use in the highest-stakes encounters. Such an arrangement could be modeled as specifying a welfare function for measuring the fairness of different proposals in high-stakes interactions, and specifying punishment mechanisms for not following the deal that is maximally fair according to this function. Ensuring that this kind of procedure leads to efficient outcomes also requires agreement on how to form credences in cases where agents possess private information. I address this next.
The prior selection problem
In this section, I'll give an example of the risks of noncommon priors. In this example, agents having different beliefs about the credibility of a coercive threat leads to the threat being carried out.
Bayesian Nash equilibrium (BNE) is the standard solution concept for games of incomplete information, i.e., games in which the players have some private information. (An agent's private information often corresponds to their utility function. However, in my example below it's more intuitive to specify the private information differently.) In this formalism, each player has a set of possible "types'' encoding their private information. A strategy maps the set of types to the set of mixtures over actions (which we'll denote by . Finally, assume that the players have a common prior over the set of types. Let be the expected payoff to player when the (possibly mixed) action profile is played. Thus, a BNE is a strategy profile such that, for each and each ,
To illustrate the importance of coordination on a common prior, suppose that two agents find themselves in a high-stakes interaction under incomplete information. Suppose that at time , agent 2 (Threatener) tells agent 1 (Target) that they will carry out some dire threat if Target doesn't transfer some amount of resources to them. However, it is uncertain whether the Threatener has actually committed to carrying out such a threat.
Say that Threatener is a Commitment type if they can commit to carrying out the threat, and a Non-Commitment type otherwise. To compute a BNE, the agents need to specify a common prior for the probability that Threatener is a Commitment type. But, without coordination, they may in fact specify different values for this prior. More precisely, define
- : The probability Threatener thinks Target assigns to being a Commitment type;
- : The Target’s credence that Threatener is a Commitment type;
- : The utility to Threatener if they carry out;
- : The utility to Threatener if Target gives in;
- : The utility to Target if they give in;
- : The utility to Target if the threat is carried out.
A threat being carried out is the worst outcome for everyone. In BNE, Commitment types threaten (and thus commit to carry out a threat) if and only if they think that Target will give in, i.e., . But Targets give in only if Thus threats will be carried out by Commitment types if and only if On the other hand, suppose the agents agree on the common prior probability that Threatener is a Commitment type (so ). Then the execution of threats is always avoided.
How might the agents agree on a common prior? In the extreme case, the principals could try to coordinate to design their agents so that they always form the same credences from public information. Remember that the learning algorithms introduced above fully specify the action of player given an observation history. This includes specifying how agents form credences like . Thus full coordination on the profile of learning algorithms chosen, as suggested in the previous subsection, could in principle solve the problem of specifying a common prior. For instance, write the set of mutually observed data as . Let
be a function mapping to common prior probabilities
that Threatener is a Commitment type, . The learning algorithms then could be chosen to satisfy
Again, full coordination on a pair of learning algorithms might be unrealistic. But it still might be possible to agree beforehand on a method for specifying a common prior in certain high-stakes situations. Because of incentives to misrepresent one's credences, it might not be enough to agree to have agents just report their credences and (say) average them (in this case e.g. Target would want to understate their credence that Threatener is a Commitment type). One direction is to have an agreed-upon standard for measuring the fit of different credences to mutually observed data. A simple model of this would for the principals to agree on a loss function which measures the fit of credences to data. Then the common credence at the time of a high-stakes interaction , given the history of mutually observed data , would be . This can be arranged without full coordination on the learning algorithms .
I won't try to answer the question of how agents decide, in a particular interaction, whether they should use some "prior commonification'' mechanism. To speculate a bit, the decision might involve higher-order priors. For instance, if Threatener has a higher-order prior over and thinks that there's a sufficiently high chance that inequality (1) holds, then they might think they're better off coordinating on a prior. But, developing a principled answer to this question is a direction for future work.
Acknowledgements
Thanks to Tobi Baumann, Alex Cloud, Nico Feil, Lukas Gloor, and Johannes Treutlein for helpful comments. This research was conducted at the Center on Long-Term Risk and the Polaris Research Institute.
Actually, the problem is more general than that. The agents might not only have disagreeing priors, but model their strategic interaction using different games entirely. I hope to address this in a later post. For simplicity I'll focus on the special case of priors here. Also, see the literature on "hypergames" (e.g. Bennett, P.G., 1980. Hypergames: developing a model of conflict), which describe agents who have different models of the game they're playing. ↩︎
Compare with the literature on misperception in international relations, and how misperceptions can lead to disaster in human interaction. Many instances of misperception might be modeled as "incorrect beliefs about others' priors''. Compare also with the discussion of crisis bargaining under incomplete information in Section 4.1 here [AF · GW]. ↩︎
I set aside the problem of truthfully eliciting each player's utility function. ↩︎
Cf. this CHAI paper, which makes a related point in the context of human-AI interaction. However, they say that we can't expect an AI trained to play an equilibrium strategy in self-play to perform well against a human, because humans might play off-equilibrium (seeing as humans are "suboptimal''). But the problem is not just that one of the players might play off-equilibrium. It's that even if they are both playing an equilibrium strategy, they may have selected different equilibria. ↩︎
11 comments
Comments sorted by top scores.
comment by Rohin Shah (rohinmshah) · 2020-04-04T23:39:06.098Z · LW(p) · GW(p)
Planned summary for the Alignment Newsletter:
Consider the scenario in which two principals will separately develop and deploy learning agents, that will then act on their behalf, and suppose further that they even agree on the welfare function that these agents should optimize. Let us call this a _learning game_, in which the "players" are the principals, the actions are the agents developed, and both players want to optimize the welfare function (making it a collaborative game). There still remain two coordination problems. First, we face an _equilibrium selection problem_: there can be multiple Nash equilibria in a collaborative game, and so if the two deployed learning agents are Nash strategies from _different_ equilibria, payoffs can be arbitrarily bad. Second, we face a _prior selection problem_: given that there are many reasonable priors that the learning agents could have, if they end up with different priors from each other, outcomes can again be quite bad, especially in the context of <@threats@>(@Cooperation, Conflict, and Transformative Artificial Intelligence: A Research Agenda@).
Planned opinion:
These are indeed pretty hard problems in any collaborative game. While this post takes the framing of considering optimal principals and/or agents (and so considers Bayesian strategies in which only the prior and choice of equilibrium are free variables), I prefer the framing taken in <@our paper@>(@Collaborating with Humans Requires Understanding Them@): the issue is primarily that in a collaborative game, the optimal thing for you to do depends strongly on who your partner is, but you may not have a good understanding of who your partner is, and if you're wrong you can do arbitrarily poorly.
Note that when you can have a well-specified Bayesian belief over your partner, these problems don't arise. However, both agents can't be in this situation: in this case agent A would have a belief over B that has a belief over A; if these are all well-specified Bayesian beliefs, then A has a Bayesian belief over itself, which is impossible.Replies from: MichaelDennis, JesseClifton
↑ comment by MichaelDennis · 2020-04-06T16:52:30.951Z · LW(p) · GW(p)
Note that when you can have a well-specified Bayesian belief over your partner, these problems don't arise. However, both agents can't be in this situation: in this case agent A would have a belief over B that has a belief over A; if these are all well-specified Bayesian beliefs, then A has a Bayesian belief over itself, which is impossible.
There are ways to get around this. The most common way in the literature (in fact the only way I have seen) gives every agent a belief over a set of common worlds (which contain both the state of the world and the memory states of all of the agents). Then the state of the world is a sufficient statistic over everything that can happen and beliefs about other players beliefs can be derived from each player's beliefs on the underlying world. This does mean you have to agree upon "possible memory states" before time, or at least both have beliefs that are described over sets that can be constantly combined into a "set of all possible worlds".
Replies from: rohinmshah↑ comment by Rohin Shah (rohinmshah) · 2020-04-06T03:15:09.567Z · LW(p) · GW(p)
Thanks, removed that section.
↑ comment by JesseClifton · 2020-04-05T03:21:56.829Z · LW(p) · GW(p)
both players want to optimize the welfare function (making it a collaborative game)
The game is collaborative in the sense that a welfare function is optimized in equilibrium, but the principals will in general have different terminal goals (reward functions) and the equilibrium will be enforced with punishments (cf. tit-for-tat).
the issue is primarily that in a collaborative game, the optimal thing for you to do depends strongly on who your partner is, but you may not have a good understanding of who your partner is, and if you're wrong you can do arbitrarily poorly
Agreed, but there's the additional point that in the case of principals designing AI agents, the principals can (in theory) coordinate to ensure that the agents "know who their partner is". That is, they can coordinate on critical game-theoretic parameters of their respective agents.
Replies from: rohinmshah↑ comment by Rohin Shah (rohinmshah) · 2020-04-05T16:21:25.661Z · LW(p) · GW(p)
Ah, I misunderstood your post. I thought you were arguing for problems conditional on the principals agreeing on the welfare function to be optimized, and having common knowledge that they were designing agents that optimize that welfare function.
but there's the additional point that in the case of principals designing AI agents, the principals can (in theory) coordinate to ensure that the agents "know who their partner is".
I mean, in this case you just deploy one agent instead of two. Even under the constraint that you must deploy two agents, you exactly coordinate their priors / which equilibria they fall into. To get prior / equilibrium selection problems, you necessarily need to have agents that don't know who their partner is. (Even if just one agent knows who the partner is, outcomes should be expected to be relatively good, though not optimal, e.g. if everything is deterministic, then threats are never executed.)
----
Looking at these objections, I think probably what you were imagining is a game where the principals have different terminal goals, but they coordinate by doing the following:
- Agreeing upon a joint welfare function that is "fair" to the principals. In particular, this means that they agree that they are "licensed" to punish actions that deviate from this welfare function.
- Going off and building their own agents that optimize the welfare function, but make sure to punish deviations (to ensure that the other principal doesn't build an agent that pursues the principal's goals instead of the welfare function)
New planned summary:
Consider the scenario in which two principals with different terminal goals will separately develop and deploy learning agents, that will then act on their behalf. Let us call this a _learning game_, in which the "players" are the principals, and the actions are the agents developed.
One strategy for this game is for the principals to first agree on a "fair" joint welfare function, such that they and their agents are then licensed to punish the other agent if they take actions that deviate from this welfare function. Ideally, this would lead to the agents jointly optimizing the welfare function (while being on the lookout for defection).
There still remain two coordination problems. First, there is an _equilibrium selection problem_: if the two deployed learning agents are Nash strategies from _different_ equilibria, payoffs can be arbitrarily bad. Second, there is a _prior selection problem_: given that there are many reasonable priors that the learning agents could have, if they end up with different priors from each other, outcomes can again be quite bad, especially in the context of <@threats@>(@Cooperation, Conflict, and Transformative Artificial Intelligence: A Research Agenda@).
New opinion:
These are indeed pretty hard problems in any non-competitive game. While this post takes the framing of considering optimal principals and/or agents (and so considers Bayesian strategies in which only the prior and choice of equilibrium are free variables), I prefer the framing taken in <@our paper@>(@Collaborating with Humans Requires Understanding Them@): the issue is primarily that the optimal thing for you to do depends strongly on who your partner is, but you may not have a good understanding of who your partner is, and if you're wrong you can do arbitrarily poorly.
Note that when you can have a well-specified Bayesian belief over your partner, these problems don't arise. However, both agents can't be in this situation: in this case agent A would have a belief over B that has a belief over A; if these are all well-specified Bayesian beliefs, then A has a Bayesian belief over itself, which is usually impossible.
Btw, some reasons I prefer not using priors / equilibria and instead prefer just saying "you don't know who your partner is":
- It encourages solutions that take advantage of optimality and won't actually work in the situations we actually face.
- The formality of "priors / equilibria" doesn't have any benefit in this case (there aren't any theorems to be proven). The one benefit I see is that it signals that "no, even if we formalize it, the problem doesn't go away", to those people who think that once formalized sufficiently all problems go away via the magic of Bayesian reasoning.
- The strategy of agreeing on a joint welfare function is already a heuristic and isn't an optimal strategy; it feels very weird to suppose that initially a heuristic is used and then we suddenly switch to pure optimality.
↑ comment by MichaelDennis · 2020-04-06T16:52:30.951Z · LW(p) · GW(p)
I mean, in this case you just deploy one agent instead of two
If the CAIS view multi-agent setups like this could be inevitable. There are also many reasons that we could want a lot of actors making a lot of agents rather than one actor making one agent. By having many agents we have no single point of failure (like fault-tolerant data-storage) and no single principle has a concentration of power (like the bitcoin protocol).
It does introduce more game-theoretic issues, but those issues seem understandable and tractable to me and there is very little work from the AI perspective that seriously tackles them, so the problems could be much easier than we think.
Even under the constraint that you must deploy two agents, you exactly coordinate their priors / which equilibria they fall into. To get prior / equilibrium selection problems, you necessarily need to have agents that don't know who their partner is.
I think it is reasonable to think that there could be a band width constraint on coordination over the prior and equilibria selection, that is much smaller than all of the coordination scenarios you could possibly encounter. I agree to have these selection problems you need to not know who exactly your partner is, but it is possible to know quite a bit about your partner and still have coordination problems.
It encourages solutions that take advantage of optimality and won't actually work in the situations we actually face.
I would be very weary of a solution that didn't work when have optimal agents. I think it's reasonable to try to get things to work when we do everything right before trying to make that process robust to errors
The formality of "priors / equilibria" doesn't have any benefit in this case (there aren't any theorems to be proven). The one benefit I see is that it signals that "no, even if we formalize it, the problem doesn't go away", to those people who think that once formalized sufficiently all problems go away via the magic of Bayesian reasoning.
I think there are theorems to be proven, just not of the form "there is an optimal thing to do"
The strategy of agreeing on a joint welfare function is already a heuristic and isn't an optimal strategy; it feels very weird to suppose that initially a heuristic is used and then we suddenly switch to pure optimality.
It's also, to a first approximation, the strategy society takes in lots of situations, this happens whenever people form teams with a common goal. There are usually processes of re-negotiating the goal, but between these times of conflict people gain a lot of efficiency by working together and punishing deviation.
Replies from: rohinmshah↑ comment by Rohin Shah (rohinmshah) · 2020-04-06T03:19:53.237Z · LW(p) · GW(p)
I think there are theorems to be proven, just not of the form "there is an optimal thing to do"
I meant one thing and wrote another; I just meant to say that there weren't theorems in this post.
If the CAIS view multi-agent setups like this could be inevitable.
My point is just that "prior / equilibrium selection problem" is a subset of the "you don't know everything about the other player" problem, which I think you agree with?
It's also, to a first approximation, the strategy society takes in lots of situations, this happens whenever people form teams with a common goal. There are usually processes of re-negotiating the goal, but between these times of conflict people gain a lot of efficiency by working together and punishing deviation.
I'm not sure how this relates to the thing I'm saying (I'm also not sure if I understood it).
Replies from: MichaelDennis↑ comment by MichaelDennis · 2020-04-08T01:22:43.070Z · LW(p) · GW(p)
My point is just that "prior / equilibrium selection problem" is a subset of the "you don't know everything about the other player" problem, which I think you agree with?
I see two problems: one of trying to coordinate on priors, and one of trying to deal with having not successfully coordinated. I think that which is easier depends on the problem: if we're applying it to CAIS, HRI or a multipolar scenario. Sometimes it's easier to coordinate on a prior before hand, sometimes it's easier to be robust to differing priors, and sometimes you have to go for a bit of both. I think it's reasonable to call both solution techniques to the "prior / equilibrium selection problem", but the framings shoot for different solutions, both of which I view as necessary sometimes.
The strategy of agreeing on a joint welfare function is already a heuristic and isn't an optimal strategy; it feels very weird to suppose that initially a heuristic is used and then we suddenly switch to pure optimality.
I don't really know what you mean by this. Specifically I don't know from who's perspective it isn't optimal and under what beliefs.
A few things to point out:
- The strategy of agreeing on a joint welfare function and optimizing it is an optimal strategy for some belief in infinitely iterated settings (because there is a folk theorem so almost everything is an optimal strategy for some belief)
- Since we're currently making norms for these interactions, we are currently designing these beliefs. This means that we can make it be the case that having that belief is justified in future deployments.
- If we want to talk about "optimality" in terms of "equilibria selection procedures" or "coordination norms" we have to have a metric to say some outcomes are "better" than others. This is not a utility function for the agents, but for us as the norm designers. Social welfare seems good for this.
↑ comment by JesseClifton · 2020-04-05T17:37:41.547Z · LW(p) · GW(p)
The new summary looks good =) Although I second Michael Dennis' comment below, that the infinite regress of priors is avoided in standard game theory by specifying a common prior. Indeed the specification of this prior leads to a prior selection problem.
The formality of "priors / equilibria" doesn't have any benefit in this case (there aren't any theorems to be proven)
I’m not sure if you mean “there aren’t any theorems to be proven” or “any theorem that’s proven in this framework would be useless”. The former is false, e.g. there are things to prove about the construction of learning equilibria in various settings. I’m sympathetic with the latter criticism, though my own intuition is that working with the formalism will help uncover practically useful methods for promoting cooperation, and point to problems that might not be obvious otherwise. I'm trying to make progress in this direction in this paper, though I wouldn't yet call this practical.
The one benefit I see is that it signals that "no, even if we formalize it, the problem doesn't go away", to those people who think that once formalized sufficiently all problems go away via the magic of Bayesian reasoning
Yes, this is a major benefit I have in mind!
The strategy of agreeing on a joint welfare function is already a heuristic and isn't an optimal strategy; it feels very weird to suppose that initially a heuristic is used and then we suddenly switch to pure optimality
I’m not sure what you mean by “heuristic” or “optimality” here. I don’t know of any good notion of optimality which is independent of the other players, which is why there is an equilibrium selection problem. The welfare function selects among the many equilibria (i.e. it selects one which optimizes the welfare). I wouldn't call this a heuristic. There has to be some way to select among equilibria, and the welfare function is chosen such that the resulting equilibrium is acceptable by each of the principals' lights.
Replies from: rohinmshah, MichaelDennis↑ comment by Rohin Shah (rohinmshah) · 2020-04-06T03:14:35.057Z · LW(p) · GW(p)
I’m not sure what you mean by “heuristic” or “optimality” here. I don’t know of any good notion of optimality which is independent of the other players, which is why there is an equilibrium selection problem.
I think once you settle on a "simple" welfare function, it is possible that there are _no_ Nash equilibria such that the agents are optimizing that welfare function (I don't even really know what it means to optimize the welfare function, given that you have to also punish the opponent, which isn't an action that is useful for the welfare function).
I’m not sure if you mean “there aren’t any theorems to be proven” or “any theorem that’s proven in this framework would be useless”.
Hmm, I meant one thing and wrote another. I meant to say "there aren't any theorems proven in this post".
↑ comment by MichaelDennis · 2020-04-06T16:52:30.951Z · LW(p) · GW(p)
I second Michael Dennis' comment below, that the infinite regress of priors is avoided in standard game theory by specifying a common prior. Indeed the specification of this prior leads to a prior selection problem.
Just to make sure that I was understood, I was also pointing out that "you can have a well-specified Bayesian belief over your partner" even without agreeing on a common prior, as long as you agree on a common set of possibilities or something effectively similar. This means that talking about "Bayesian agents without a common prior" is well-defined.
When there is not a common prior, this lead to an arbitrarily deep nesting of beliefs, but they are all well-defined. I can refer to "what A believes that B believes about A" without running into Russell's Paradox. When the priors mis-match then the entire hierarchy of these beliefs might be useful to reason about, but when there is a common prior, it allows much of the hierarchy to collapse.