Excursions into Sparse Autoencoders: What is monosemanticity?
post by Jakub Smékal (jakub-smekal) · 2024-08-05T19:22:40.249Z · LW · GW · 0 commentsContents
Background Steering Through Interventions on the Latent Code Indirect Object Identification Initial Sparse Code Exploration Sparse Interchange Interventions Boosted Sparse Interchange Interventions Other Sparse Interventions Single direction, multiple outputs Results Conclusion None No comments
The following work was done between January and March 2024 as part of my PhD rotation with Prof Surya Ganguli and Prof Noah Goodman.
One aspect of sparse autoencoders that has put them at the center of attention in mechanistic interpretability is the notion of monosemanticity. In this post, we will explore the concept of monosemanticity in open-source sparse autoencoders (by Joseph Bloom) trained on residual stream layers of GPT-2 small. We will take a look at the indirect object identification task and see what we can extract by projecting different layer activations into their sparse high-dimensional latent space (from now on we will just refer to this as the latent code). We show the ranges of controllability on the model’s outputs by considering interventions within the latent code and discuss future work in this area.
Background
In Toy Models of Superposition, Elhage et al. discuss a framework to think about the different layer activations in transformer-based language models. The idea can be condensed as follows: the dimensionality of the state-space of language is extremely large, larger than any model to-date can encode in a one-to-one fashion. As a result, the model compresses the relevant aspects of the language state-space into its constrained, say n-dimensional, activation space. A consequence of this is that the states in this higher-dimensional language space that humans have learned to interpret (e.g. words, phrases, concepts) are somehow entangled on this compressed manifold of transformer activations. This makes it hard for us to look into the model and understand what is going on, what kind of structures did the model learn, how did it use concept A and concept B to get to concept C, etc. The proposal outlined in Toy Models of Superposition suggests that one way to bypass this bottleneck is to assume that our transformer can be thought of as emulating a larger model, one which operates on the human-interpretable language manifold. To get into this interpretable space, they propose training sparse autoencoders on the intermediate layers of our transformer model that map the activations to a higher-dimensional, but much sparser latent code, where we can easily read off human-interpretable language artifacts.
Steering Through Interventions on the Latent Code
We are interested in addressing the question of monosemanticity in sparse autoencoders trained on the residual streams of GPT-2-small. To address this question, we will first try to answer a related question of causality, i.e. do sparse autoencoders learn causally relevant features for a given task? This has partially been addressed in Cunningham et al. 2023, however, we do not yet have a good understanding of how causally relevant features evolve over the forward pass of a transformer. In the following sections, we introduce methods to probe the existence and strength of causally relevant features across the forward pass of a transformer-based language model, and we will show the results of an experiment with GPT-2-small solving the Indirect Object Identification task.
Indirect Object Identification
The Indirect Object Identification task (IOI) requires the model to output the right next token in a sentence by observing a previous occurrence of that token (the indirect object). An example IOI prompt that we will consider here (with the methods being applicable to other sentences as well) is:
“John and Mary were at the restaurant. John gave a glass of water to”
where it’s clear that the next token in the sequence should be “ Mary”. At this point it’s important to note that “ Mary” is a single token in the GPT-2-small vocabulary, for longer names we would have to consider the next two token predictions. When this sentence is passed through the transformer, it produces separate activations for each token in the sequence. In the rest of this post, we will refer to the X token position/location as the activations found at the position of token X in the sequence, e.g. the “ Mary” token position will point to the residual stream activations corresponding to the stream of the “ Mary” token, which is the third token in the sentence above.
Initial Sparse Code Exploration
We now consider the mean L0 norm of the sparse autoencoders trained on the residual stream layers of GPT-2-small. From Bloom 2024, we know that the mean L0 norm (the average number of activating features/neurons/directions in the latent code) increases as we consider downstream layers, going from ~13 active features at layer 0 to ~60 active features at layer 12. Under our input IOI sentence above, this range of L0 norms goes from ~13 active features at layer 0 to ~112 features at layer 12. This is already a relatively large number of features to consider when trying to identify the causal relevance of each feature on the outputs. To narrow the problem down, we introduce two types of interventions to probe the causal relevance of these features on downstream activations and model outputs, namely the Sparse Interchange Intervention and the Boosted Sparse Interchange Intervention.
Sparse Interchange Interventions
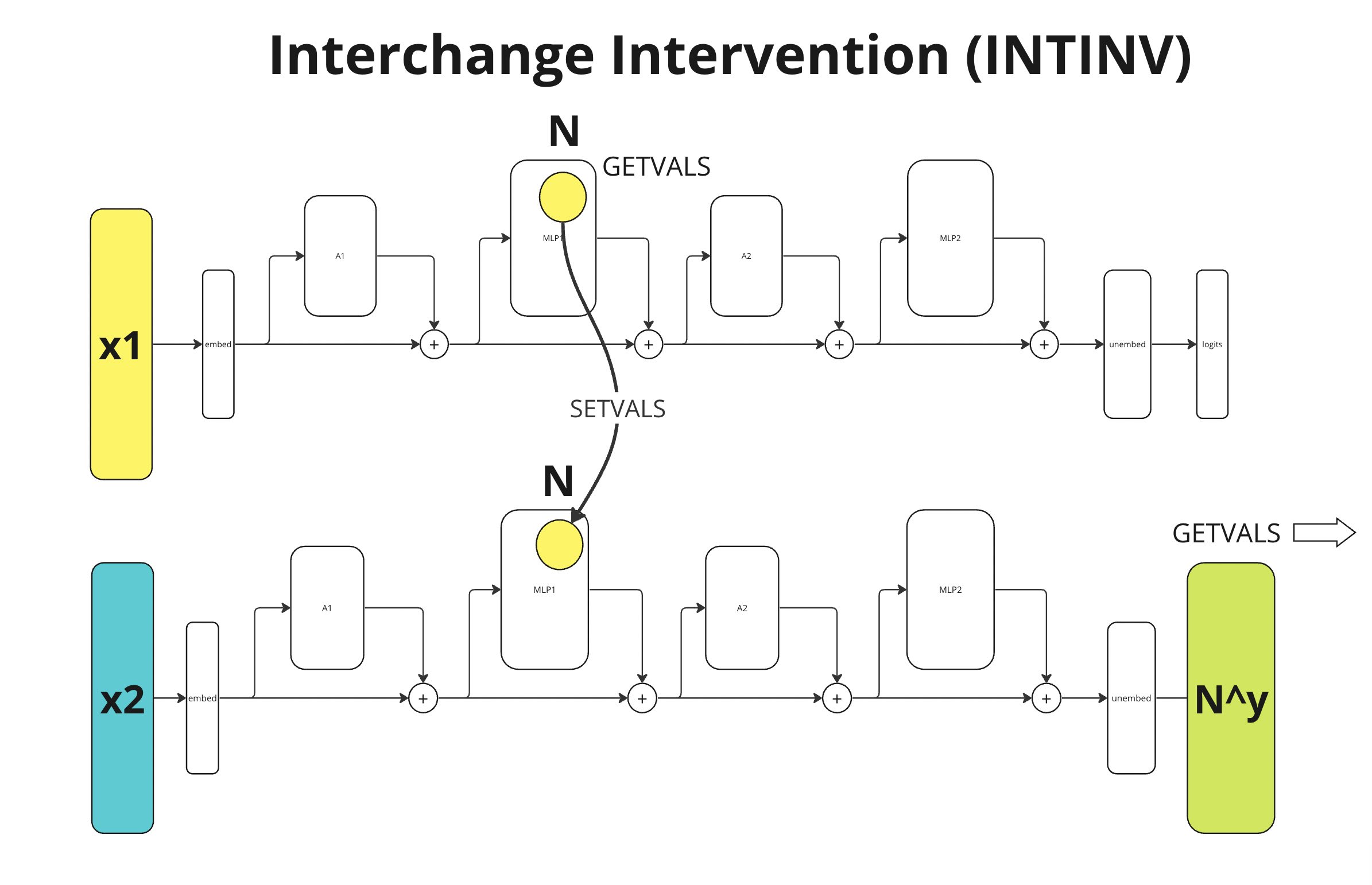
We extend the notion of an interchange intervention into the latent code of the sparse autoencoder. Given two counterfactual inputs, call them X and X’, we replace the highest activating feature in the sparse latent code from X with the corresponding feature activation under X’, and add the highest activating feature from X’ to the corresponding location in the latent code under X. We call this a Sparse Interchange Intervention (SINTINV) on the highest activating features in the two latent codes constructed from counterfactual inputs. Figure [1] shows a visual representation of a SINTINV. Figure [2] shows a classical Interchange Intervention.
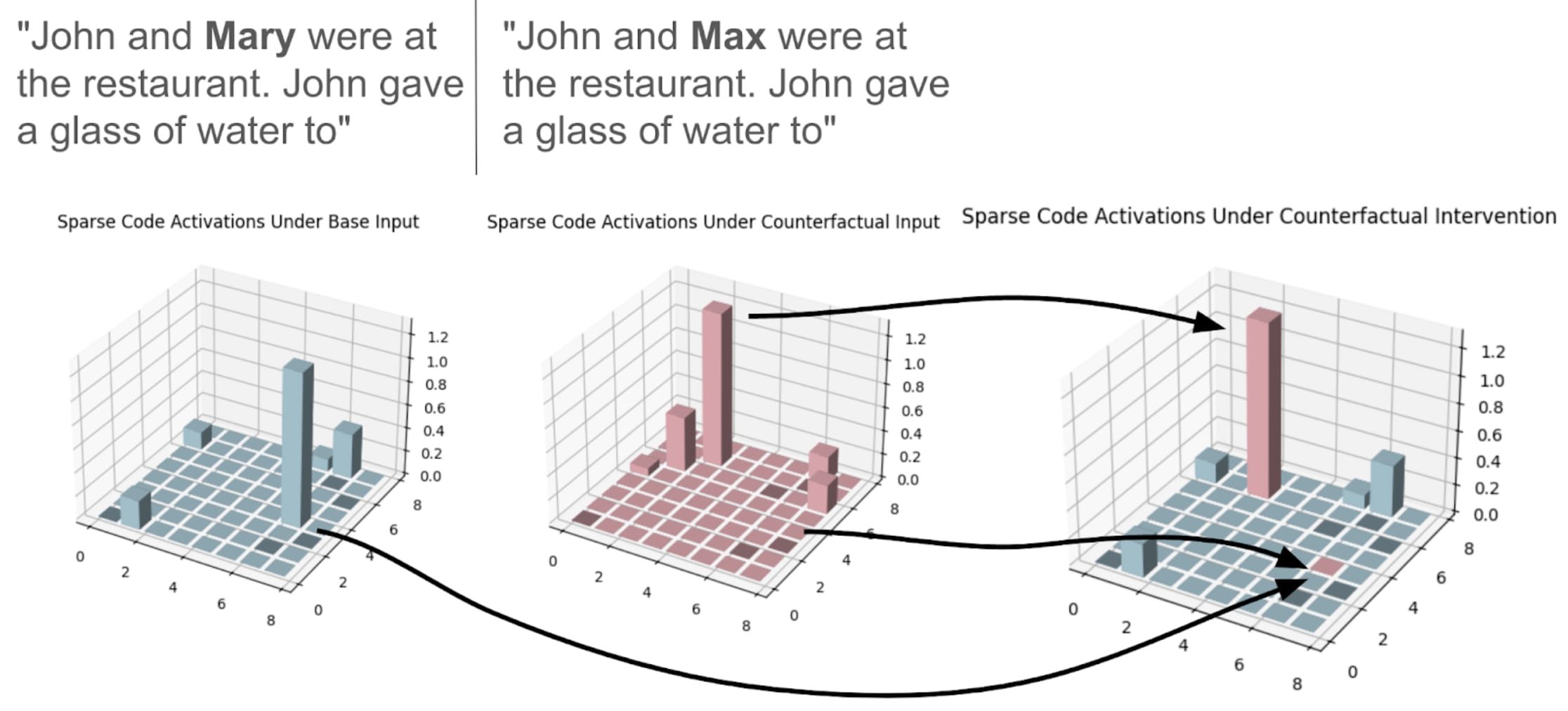
Note that here we only consider counterfactuals which have the same total number of tokens. In Figure [1], the token “ Mary” was replaced with “ Max”, both of which are represented as a single token in the GPT-2 tokenizer. We can construct an interchange intervention from counterfactuals with different numbers of tokens, but there we have to either introduce some form of padding or full ablation of a part of the sentence. For simplicity, here we only consider SINTINVs with input pairs with equal numbers of tokens.
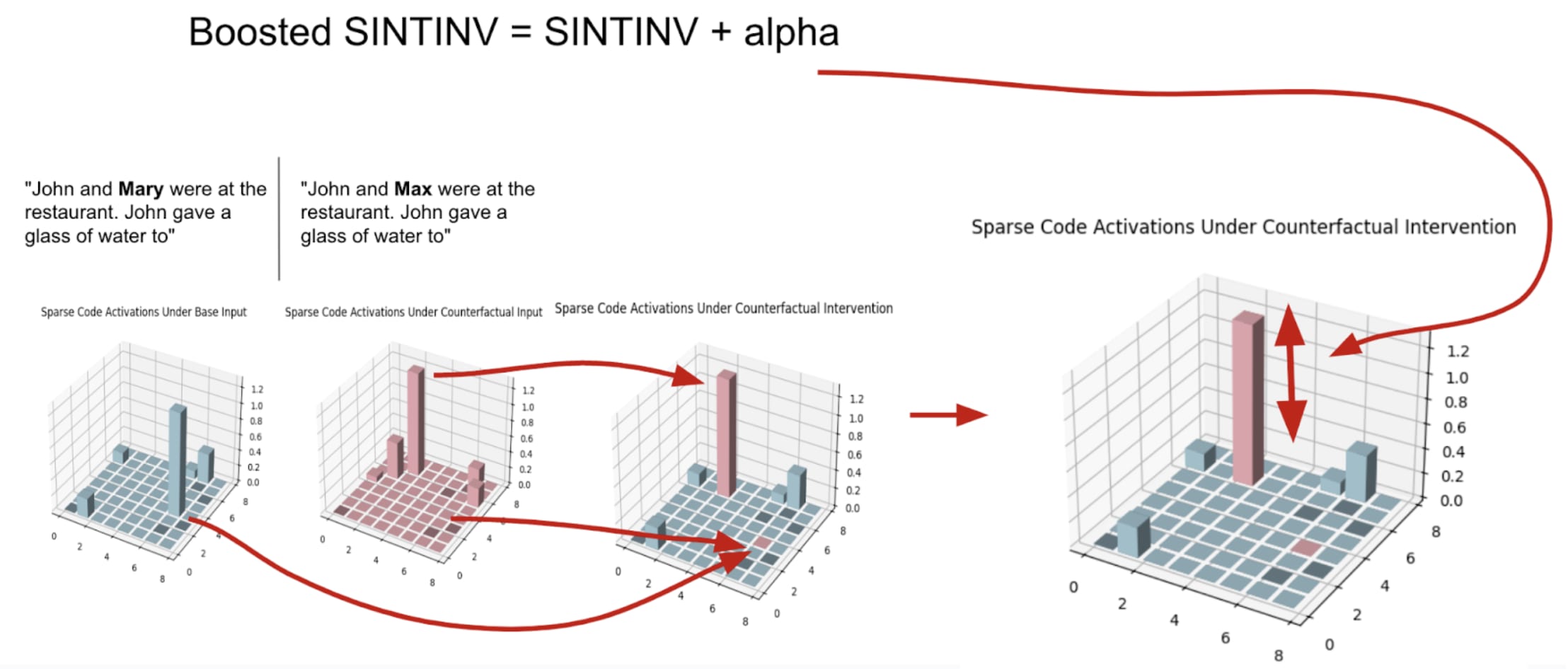
Boosted Sparse Interchange Interventions
The Boosted Sparse Interchange Intervention (Boosted SINTINV) is simply a SINTINV where we also modify the strength/value of the highest activating counterfactual feature that we added to the latent code. The Boosted SINTINV is shown in Figure [3].
Other Sparse Interventions
We briefly note some other interventions within the latent code that were considered in our analysis, but not explored as much in depth as the Sparse Interchange Intervention and the Boosted Sparse Interchange Intervention above.
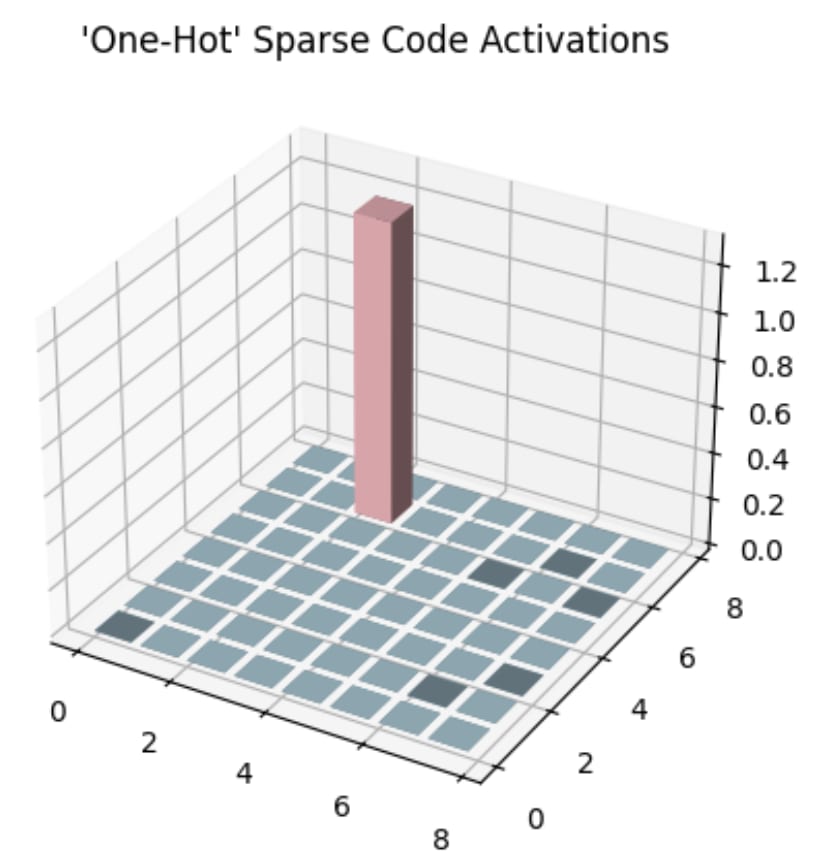
Winner-Takes-All Interventions
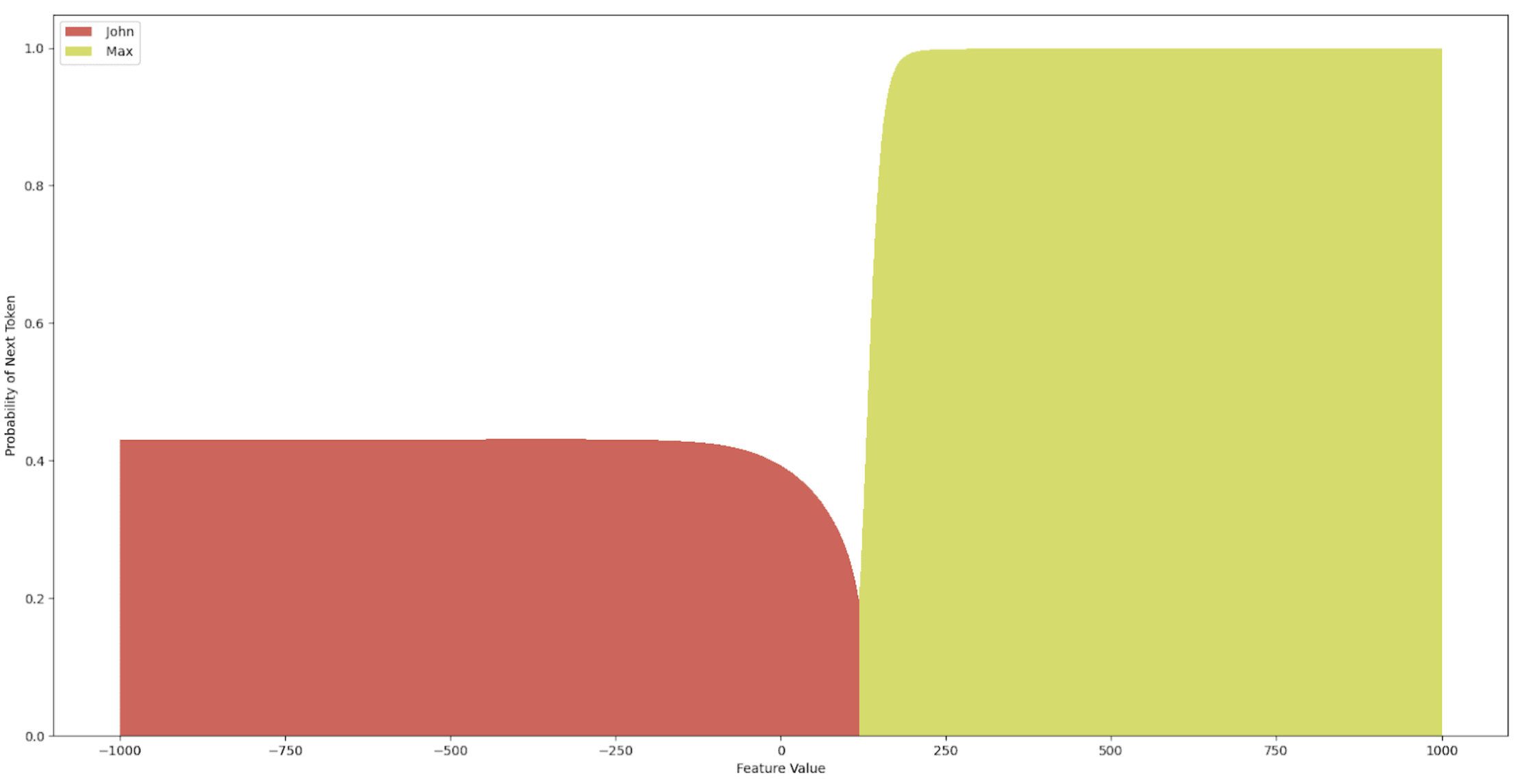
The winner-takes-all intervention (or one-hot intervention) in the latent code corresponds to a Sparse Interchange Intervention where we set all active features except the highest-valued one to zero. This is briefly shown in Figure [4]. The idea behind this intervention was to understand the causal relevance of just the highest activating feature. In our experiments, we found that the latent codes usually had one feature with much greater value than the rest, kind of like a strong peak and then a quickly decaying distribution of other features. This begs the question whether these weakly-activating features are causally relevant to the outputs of the model, and if so to what extent. The winner-takes-all intervention combined with the Sparse Interchange Intervention can provide a way to quantify this.
Gradient-informed Interventions
Another intervention to consider is a projection of a gradient step to increase the probability of the model's outputs. Take the IOI prompt mentioned above, run it through GPT-2-small and project its activations at layer 0 (or other layers) through the SAE to the latent code. Collect the outputs and gradients of the model under this sentence. Project the gradients calculated at layer 0 to the latent code. Now, pick a some small value lambda and perform the intervention on the latent code given by:
Grad_informed_intervention = Base_latent_code + lambda * gradient_latent_code
Next, reconstruct the layer activations from this new latent code and fix them while running the same input through the model. Observe the changes in the output probability distribution.
Single direction, multiple outputs
We now get to the actual experiments with these methods. In this section, we attempt to answer the following question:
- What effect does a single feature direction in the latent code of a sparse autoencoder have on the model’s outputs?
- How are causally relevant features for the IOI task distributed across the layers of GPT-2-small?
To answer these questions, we perform a sweep over different values of the highest activating feature in the sparse latent code under the Boosted Sparse Interchange Intervention. The experiment setup is shown in Figure [5].
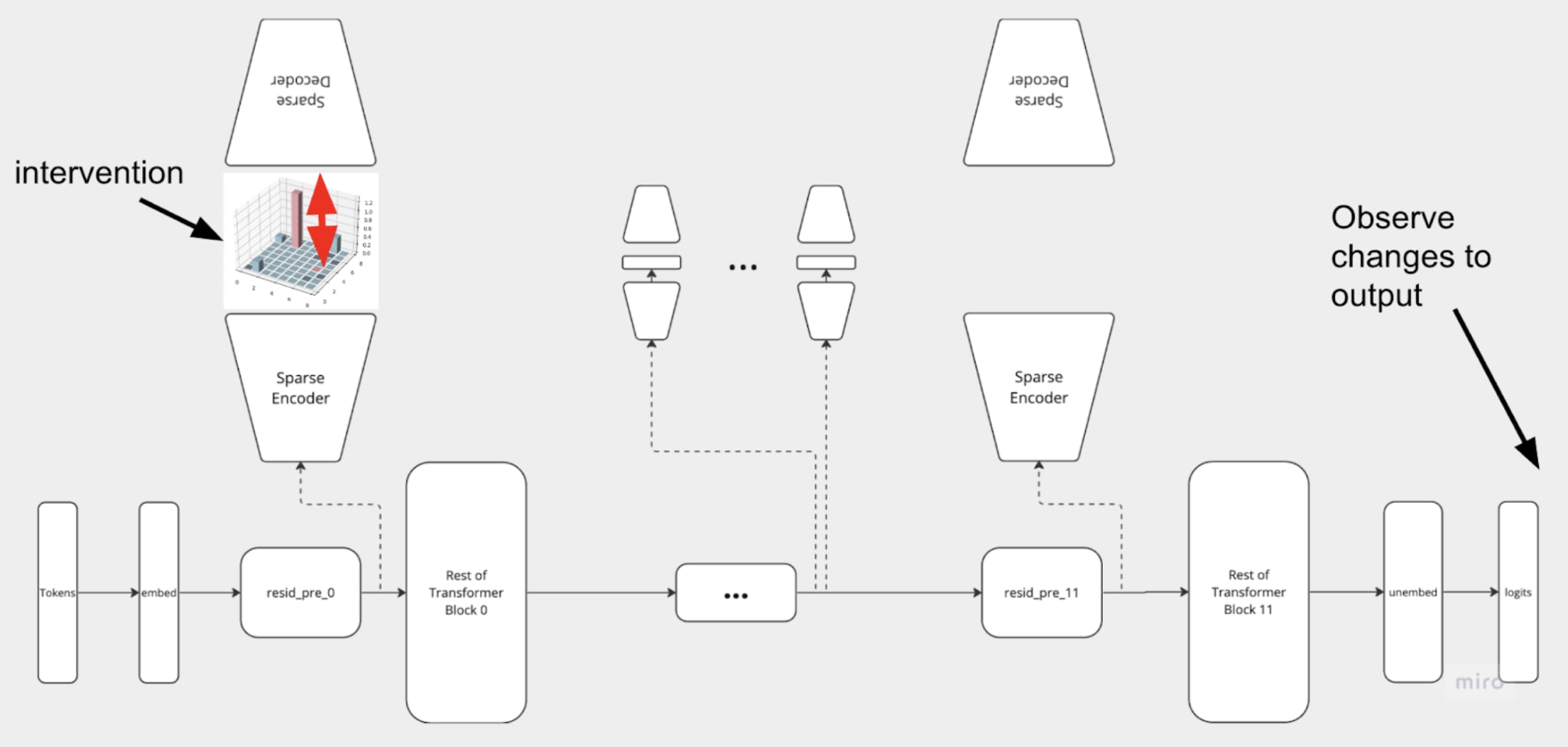
Results
We performed the Boosted Sparse Interchange Intervention for all residual stream layers of GPT-2-small at all token positions. We use the following counterfactual sentences:
- Base sentence: “John and Mary were at the restaurant. John gave a glass of water to”
- Counterfactual sentence: “John and Max were at the restaurant. John gave a glass of water to”
Both of these sentences have 16 tokens in total, so the shape of each residual stream layer’s activations is (1, 16, 768), and the shape of each latent code projection is (1, 16, ~25000). The intervened latent code was then projected through the decoder of the Sparse Autoencoder and the reconstructed activations were fixed at the corresponding layer and token position while we ran the base input through the model. The highest-valued latent feature in the intervened latent code was sweeped from -1000 to 1000 with 0.01 step size, and we collected the highest probability output token (and its probability) for each of these Boosted Sparse Interchange Interventions. We should note, these feature activation values are clearly outside of the “normal” regime of values under any given input prompt, but to find what features these directions encode, it is interesting to go outside of the “normal” regime and think of the Sparse Autoencoder as a set of very precise knobs to steer the model to completely new regimes of attention. This sweep experiment allows us to find both the token positions within the prompt that have the highest influence on the model’s outputs as well as consider their evolution across layers.
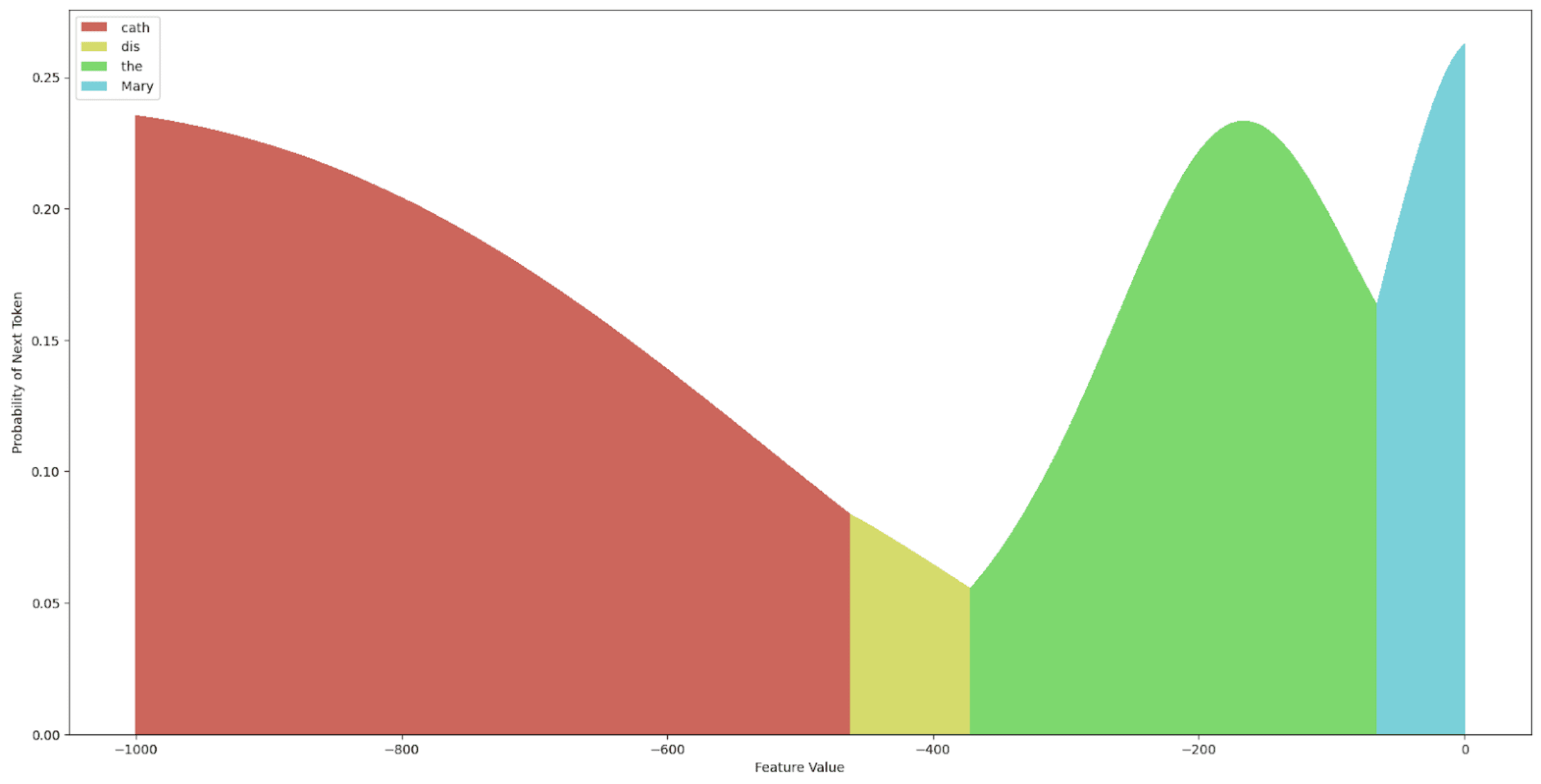
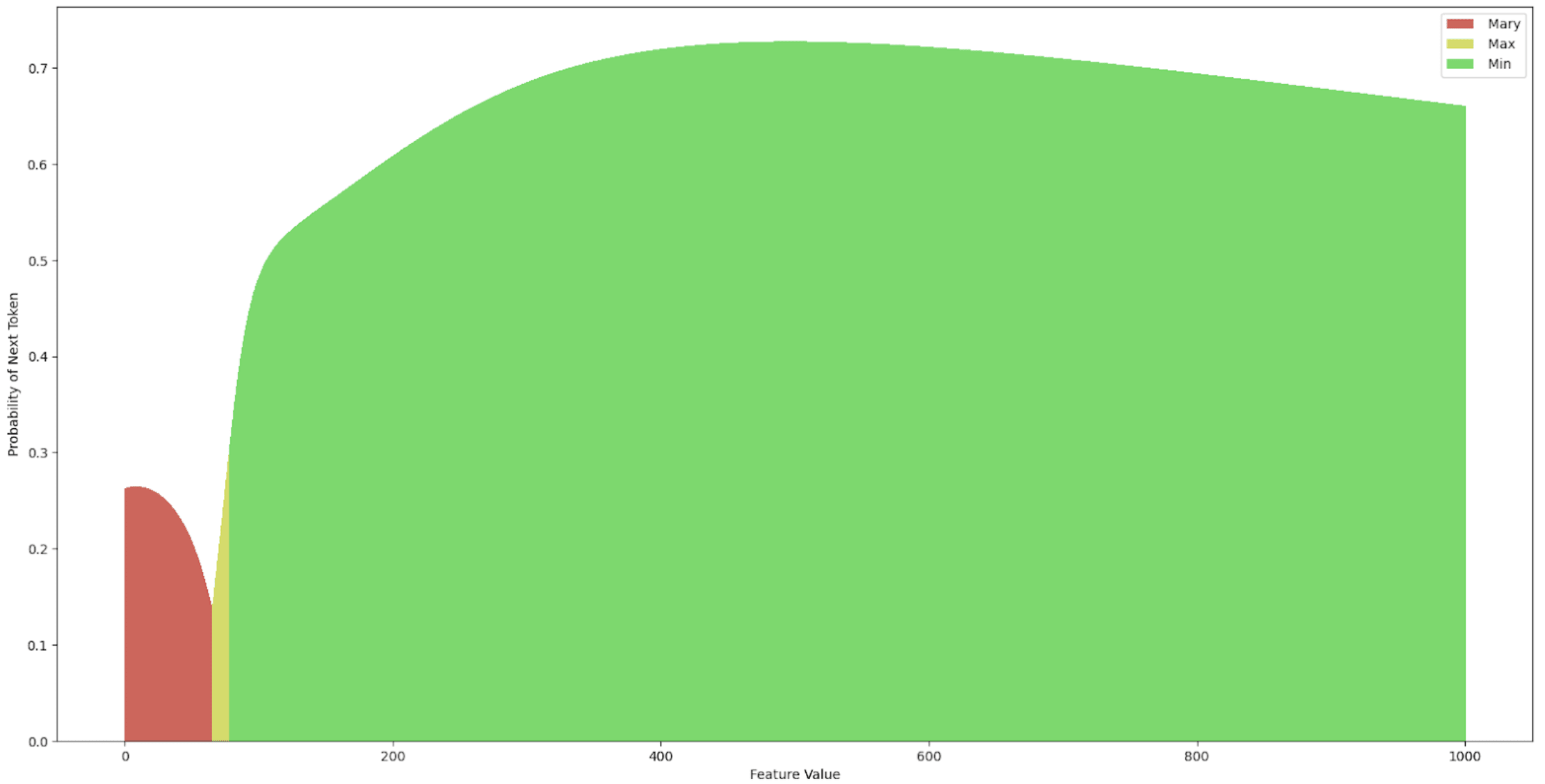
We start by considering the sweep for layer 1 activations, for which we find the only difference in latent code features at the “ Mary” (or “ Max”) token position, switching the model’s output probability from being 74.21% confident in “ Mary” being the next token in the sequence to it being 72.75% confident “ Max” is the next token in the sequence. If we do the feature value sweep on this new “ Max” feature, we get the outputs from Figures 6 and 7.
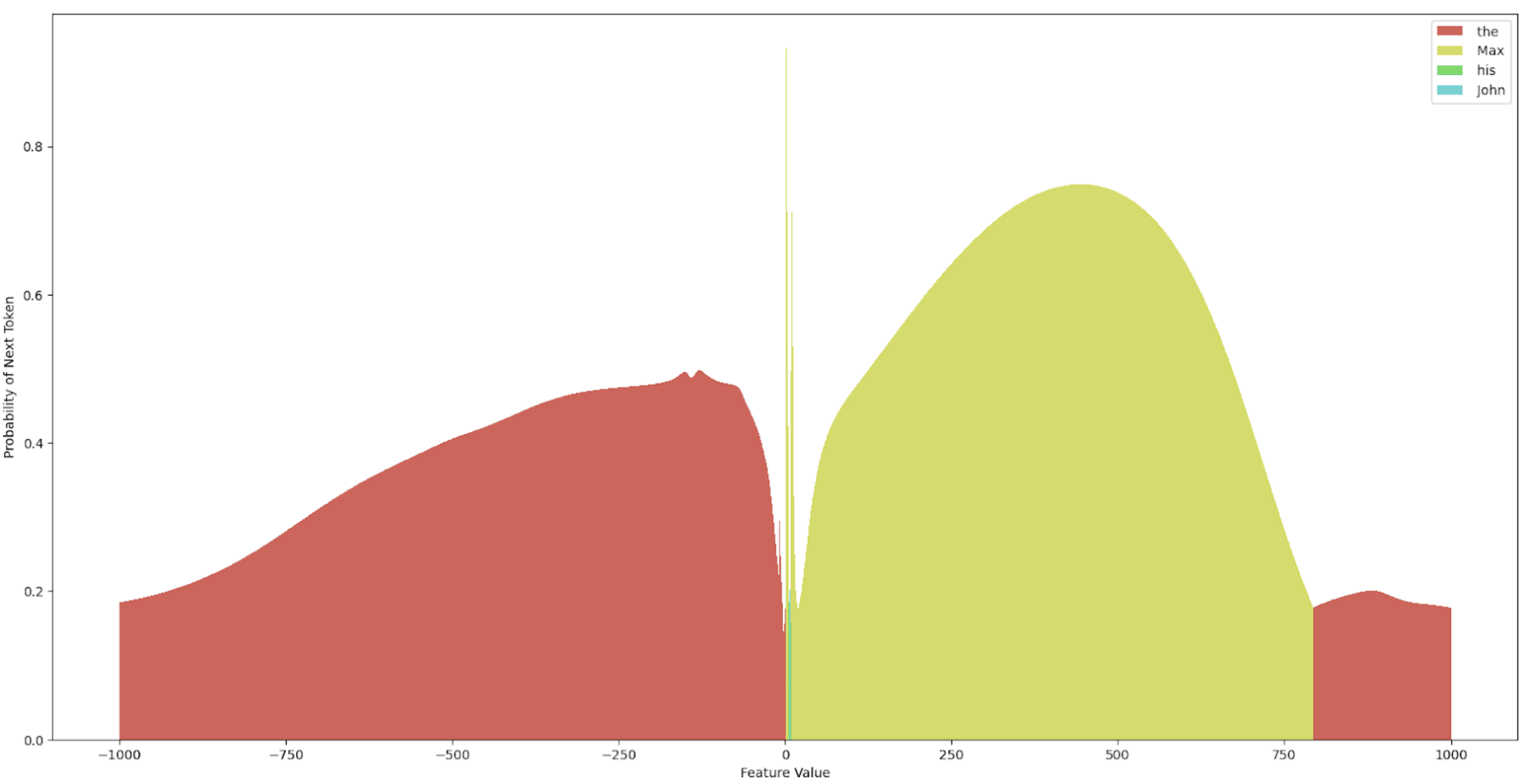
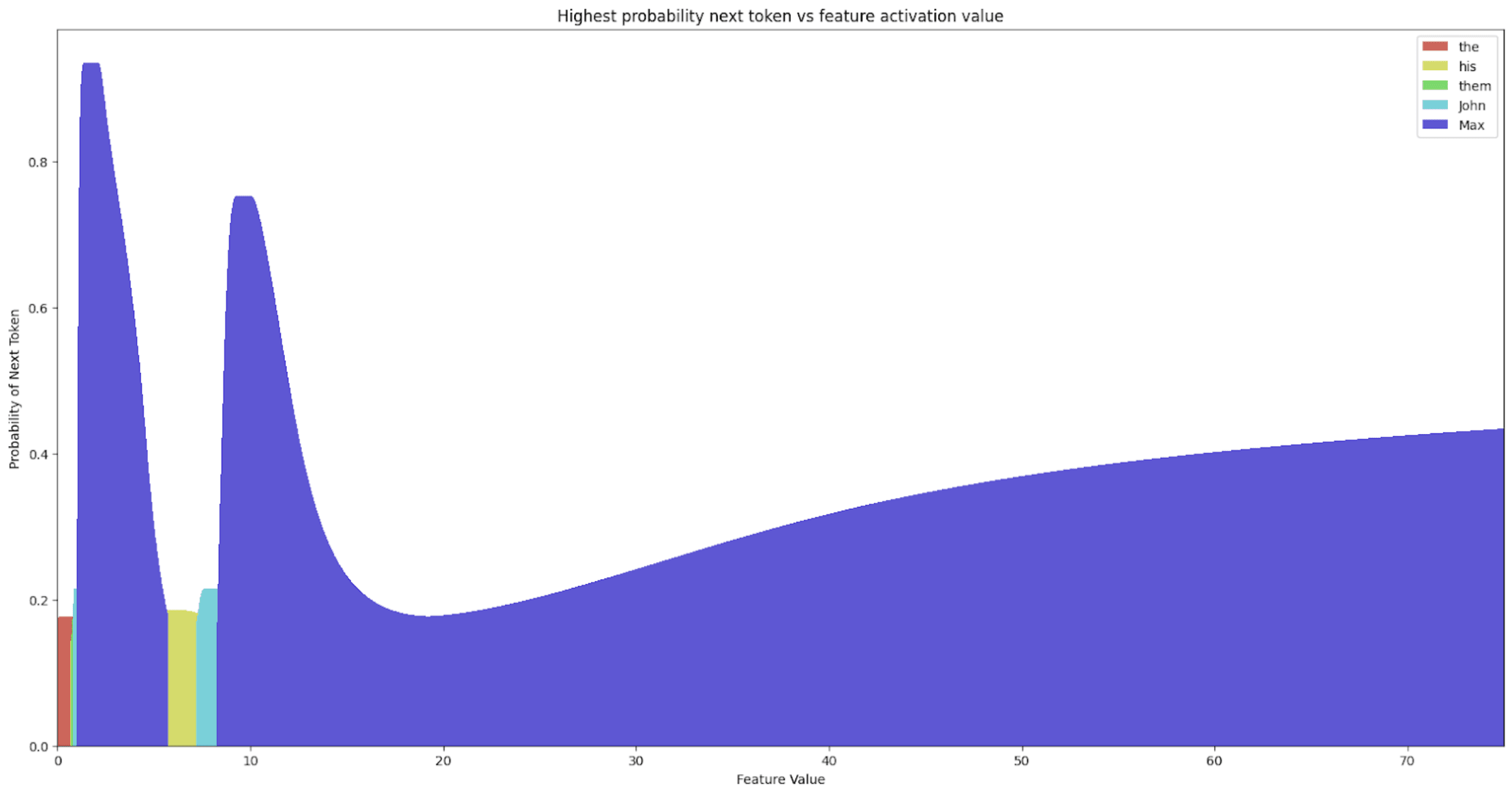
There are two main observations to note from Figures 6 and 7. First, the “ Max” direction in the latent code of “ Mary” (the smaller active features were fixed, see Figure 3) is not monosemantic in the sense that this direction encodes a single feature. Second, there is a range of values from 0 to roughly 10 where the highest probability output tokens of the model with hooked latent code reconstructions from this latent code change very quickly and are seemingly unpredictable, and other ranges of values encoding an approximately smooth trajectory of token probabilities. Furthermore, only the sweep over the latent code at the “ Mary” token position at layer 1 was able to elicit a “ Max” output from the model, with maximum confidence 93.24% by changing the feature value (compared to 72.75% with the vanilla SINTINV), indicating that at layer one, the “ Max” feature is only encoded at a single position and the model’s outputs can be intervened on in a causally meaningful way only at that location in layer 1.
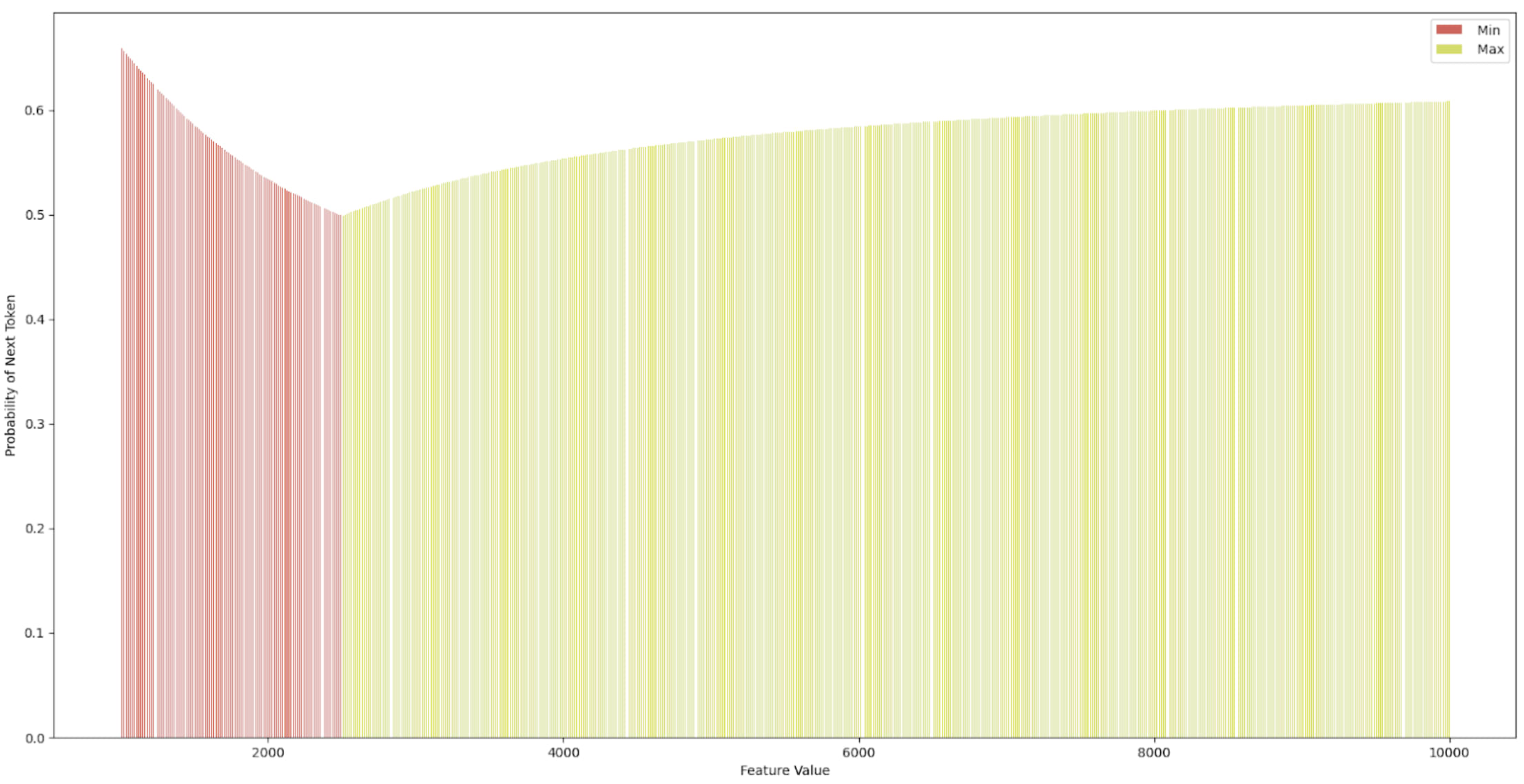
This is not the case for layer 12, where we found two locations that were able to elicit a “ Max” output from the model under a Boosted Sparse Interchange Intervention. It is important to note, however, that to get the “ Max” response at layer 12, the value of the intervened feature needed to go beyond the “normal” range of values (estimated to be around 0 and 15). This makes sense considering that when this intervention is applied at layer 12, the sentence with “ Mary” as the indirect object has already passed through all previous layers, so the “ Mary” feature dominates in at least the two locations we just identified for eliciting “ Max”, and since we only do one of these interventions at a time (and there are two locations), one of the locations always retains the “ Mary” feature. Interestingly, Figure 8 shows only two regimes of controllable outputs under the “ Max” intervention and the “ Mary” token position. Figure 9 shows three plots for the “ to” token position, i.e. the output token position. At layer 12, we see that the indirect object feature is also present, which makes sense considering the next layer in the sequence needs to output the indirect object, but it is much harder to elicit a “ Max” response under the Boosted SINTINV. In fact, there is only a narrow region between the values 0 and 100 where “ Max” can be inserted into the picture, followed by a very long window of “ Min”. The next time “ Max” appears is even outside the [-1000, 1000] range, as shown in the last subplot of Figure 9. We can also note significant differences between the “ Mary” token position and the “ to” token position. The former clearly encodes names, given by the starting token being a name, whereas the latter is performing some form of inference based on the information passed between token positions across layers, but it does not have the higher-level concept of what a name is, resulting in the predictions ranging from “cath” to “ Min” across the sweep of Boosted interventions.
| Layer | Highest-value Sparse Latent code feature able to produce counterfactual behavior |
| Layer 1 | “ Max“ |
| Layer 12 | “ Max”, “ to” |
Table 1: A summary of steerability of the counterfactual “ Max” feature in the “ Mary” sentence using Sparse Autoencoders across layers.
One takeaway from this analysis is that the indirect object feature went from having a single localized representation at the first layer of GPT-2-small to being represented in two locations at the final layer. Furthermore, the outputs of the final layer could not be steered to the desired counterfactual output under a simple Sparse Interchange Intervention, but required finding the out-of-distribution regimes via a Boosted Sparse Interchange Intervention. Specifically, the SINTINV at layer 12 at the “ Mary” token position led the model to output “ John” with 39.28% confidence, whereas a Boosted SINTINV at the same location shifted the output to “ Max” with a probability of 99.88%, higher than the maximum probability of “ Max” under an intervention at layer 1. At the “ to” token position, a SINTINV kept “ Mary” as the dominant output token, but reduced its probability from 74.21% to 19.61%. A Boosted SINTINV on the same location was able to elicit a “ Max” token output with 64.24% confidence.
Conclusion
We explored the concept of monosemanticity in sparse autoencoders trained on residual stream layers of GPT-2 small using a sample sentence from the Indirect Object Identification task. By applying Sparse Interchange Interventions and Boosted Sparse Interchange Interventions, we were able to probe the causal relevance of features across the forward pass of the transformer. Our experiments revealed that the sparse latent code directions are not necessarily monosemantic, meaning they do not always influence a single feature. We observed that the causal relevance of features for the IOI task evolves across layers, with the indirect object feature being present in multiple token positions at deeper layers. The Boosted Sparse Interchange Interventions allowed us to steer the model's outputs by manipulating the strength of the highest activating counterfactual feature. We identified different regimes of controllability, ranging from chaotic and unpredictable outputs to smooth trajectories of token probabilities.
0 comments
Comments sorted by top scores.