Antonym Heads Predict Semantic Opposites in Language Models
post by Jake Ward (jake-ward) · 2024-11-15T15:32:14.102Z · LW · GW · 0 commentsContents
Analyzing Weights Category Induction Investigating Other Models Eigenvalue Analysis Ablation Study Conclusion None No comments
In general, attention layers in large language models do two types of computation: They identify which token positions contain information relevant to predicting the next token (the QK circuit), and they transform information at these positions in some way that is useful for predicting the next token (the OV circuit). By analyzing the OV circuits in a model's attention heads, we can get an idea of the functionality that each head implements. In this post, I find that LLMs ranging a variety of sizes and architectures contain antonym heads: attention heads which compute the semantic opposite of a token, mapping "hot" -> "cold", "true" -> "false", "north" -> "south", etc. I first identify antonym heads by analyzing OV matrices over a set of curated tokens, and find evidence of interpretable eigenvalues in these matrices. I additionally verify the function of these heads through ablation studies, and explore the extent to which antonym heads are present in a variety of model sizes and architectures.
This post is inspired by work done by Gould et. al. and more recently Anthropic, identifying "successor heads" which compute the the successor of ordinal tokens such as "first" -> "second" or "3" -> "4".
Analyzing Weights
I use the following methodology:
- Hypothesize about some functionality which may exist in a model's attention heads (antonym prediction).
- Curate a dataset which should produce an identifiable pattern in the OV circuit of a head which implements this functionality.
- Hunt for this pattern in each attention head.
With the help of an LLM, I create a dataset of 54 word pairs which map common words to their opposites, yielding a total of 108 words. These words are selected such that each of the studied models' tokenizers outputs a single token per word[1], and I try to make the pairs mostly independent.

Words from these pairs are arranged into a single list, with a pair's first word appearing in the first half of the list, and the second word appearing in the second half:
first_word_idx = pair_idx
second_word_idx = pair_idx + len(pairs)This gives a word list that looks like:
true, hot, tall, big, ..., false, cold, short, small, ...
By arranging words in this way, a clear two-diagonal pattern manifests in the mapping of words in the list to their complements. I use this pattern to identify antonym prediction behavior by computing the same mapping using the OV circuit for each head in the studied models.
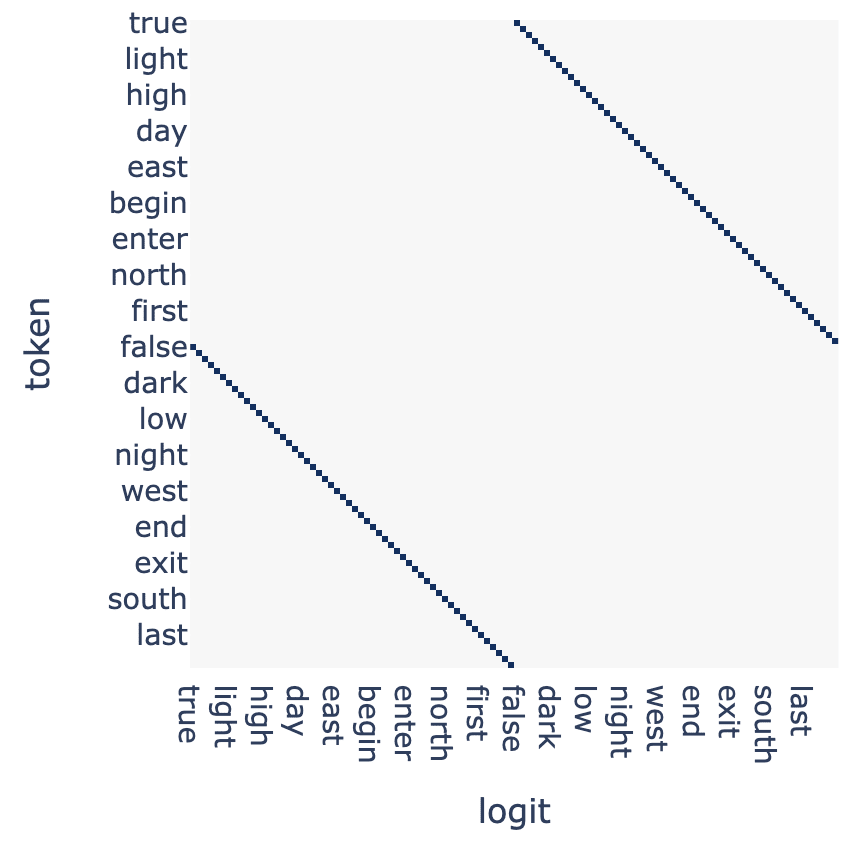
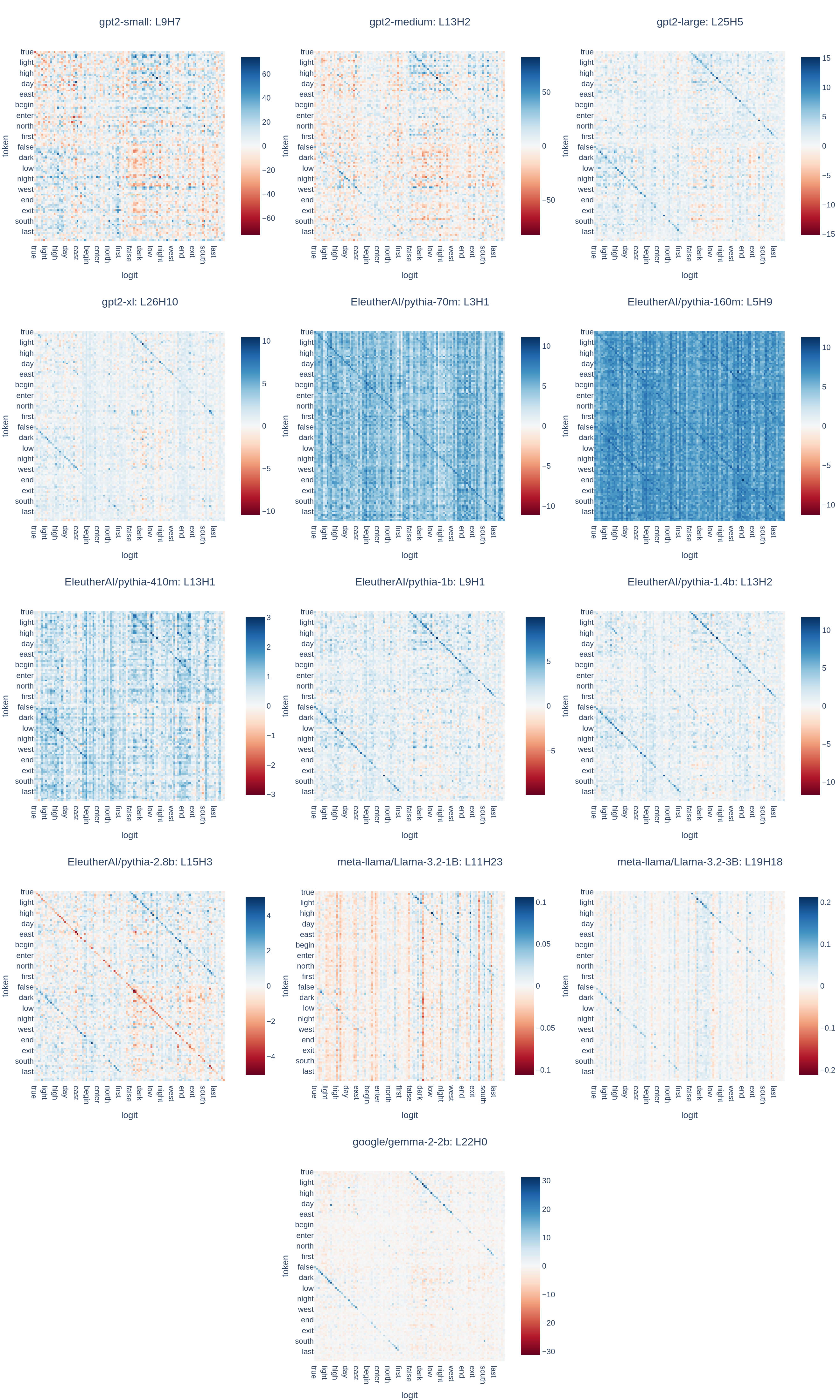
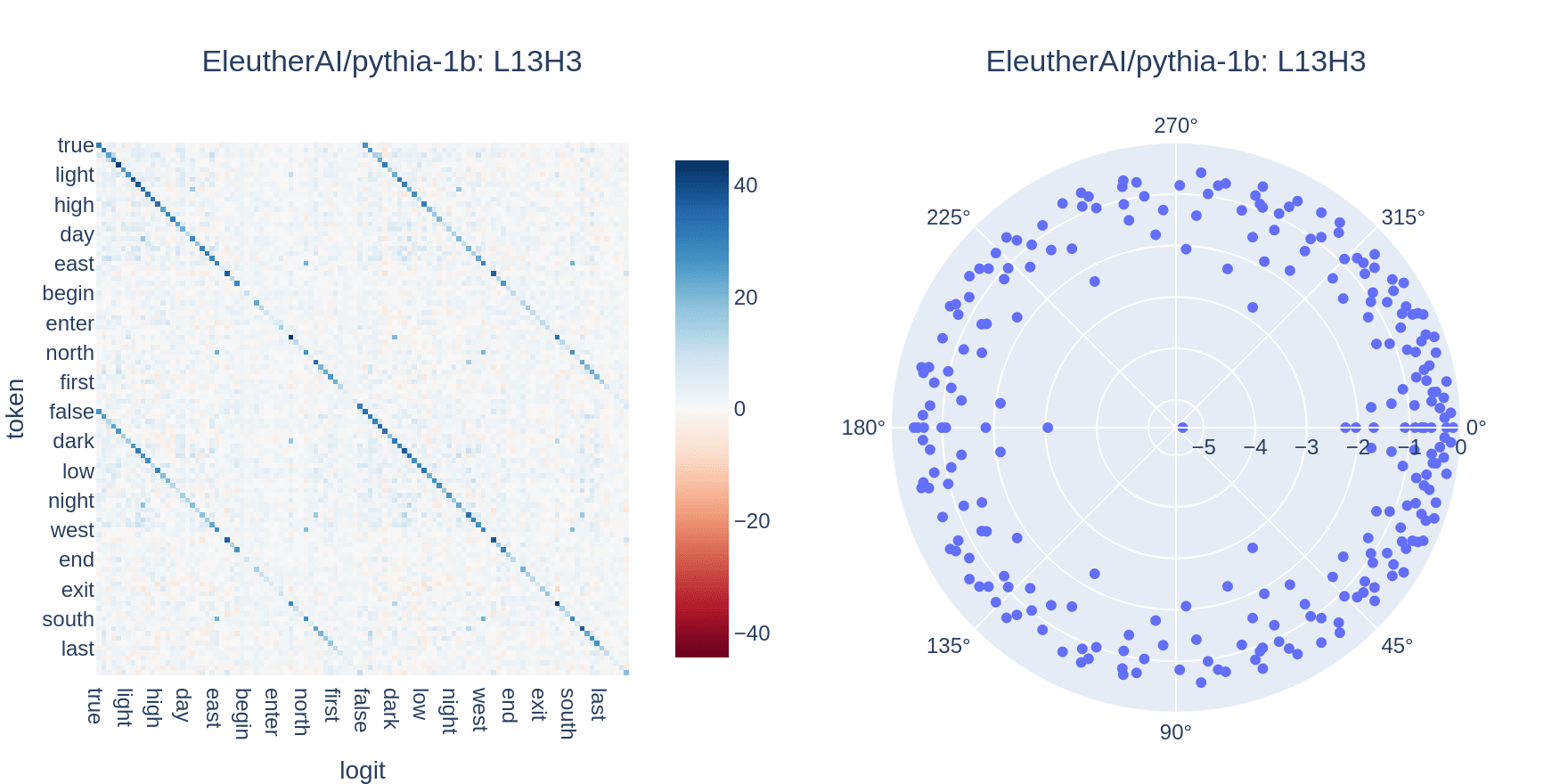
Each word in the dataset is tokenized and embedded[2]. These embeddings are then multiplied by the OV weight matrix for each attention head, before being multiplied by the unembedding matrix and adding bias to produce predicted logits. Filtering out logits not corresponding to tokens in the dataset yields an n_words * n_words matrix, which can be visualized to understand how an attention head maps input tokens to output logits. These matrices can also be used to score attention heads by tallying the number of rows for which the top scoring output logit is the antonym of the input token.
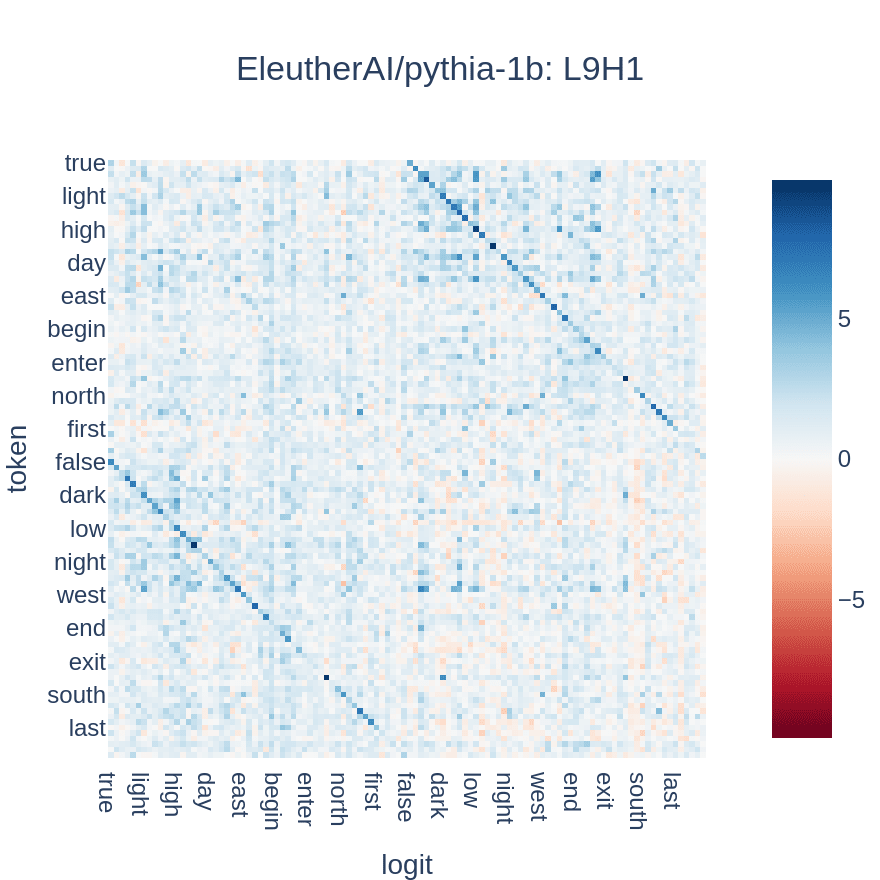
The top scoring head in Pythia-1b, shown above, correctly maps words to their antonyms a little over 60% of the time, and the double-diagonal pattern can be seen clearly. Some of the error can be attributed to the fact that not all word pairs in the dataset are actually perfectly independent -- for example, this head maps "loud" -> "soft" instead of "loud" -> "quiet" (the complement of "soft" in my dataset is "hard"). Thus, even a perfectly tuned antonym head would have some uncertainty about the "correct" logit given my dataset.
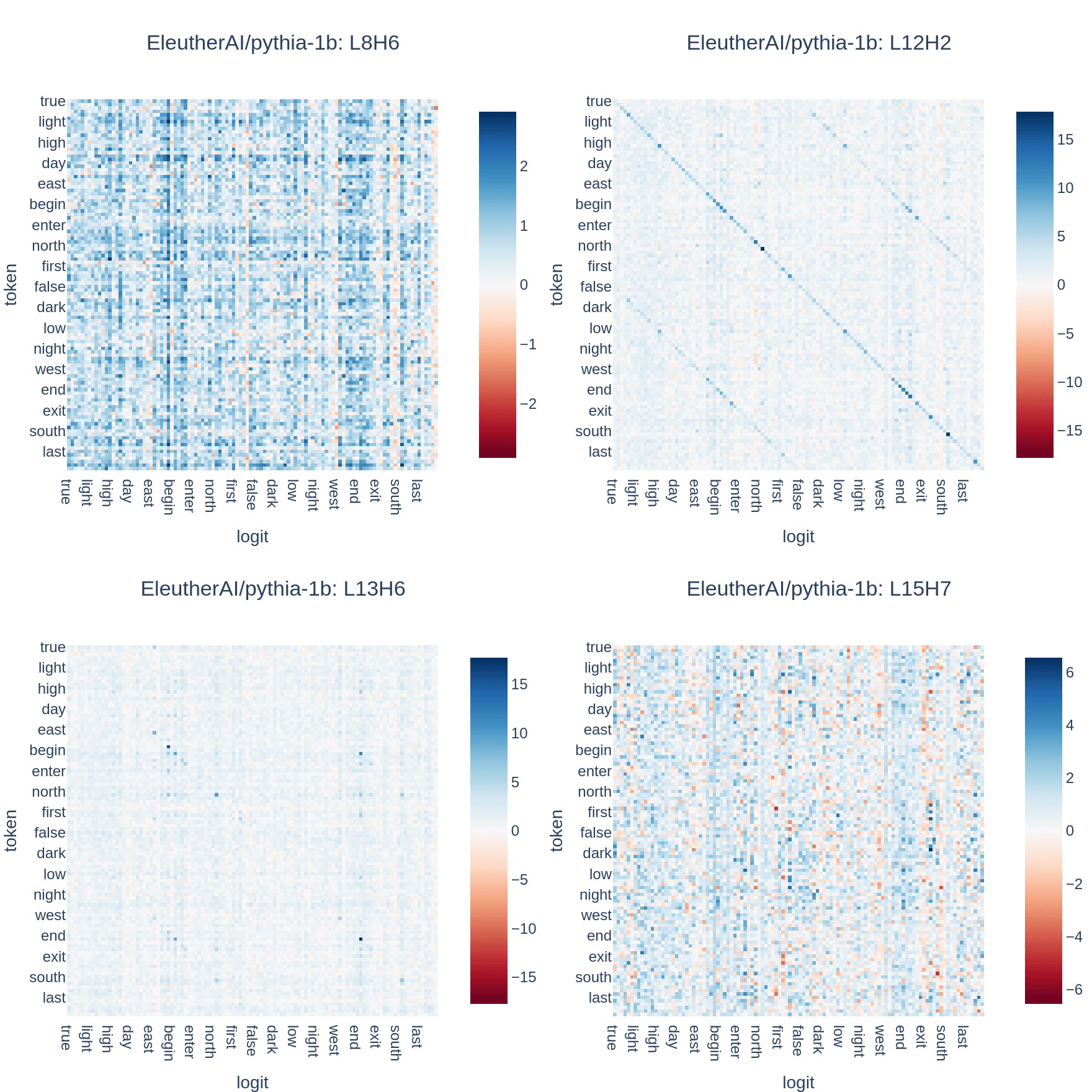
For comparison, here are the OV circuits for four random heads in the same model:
Category Induction
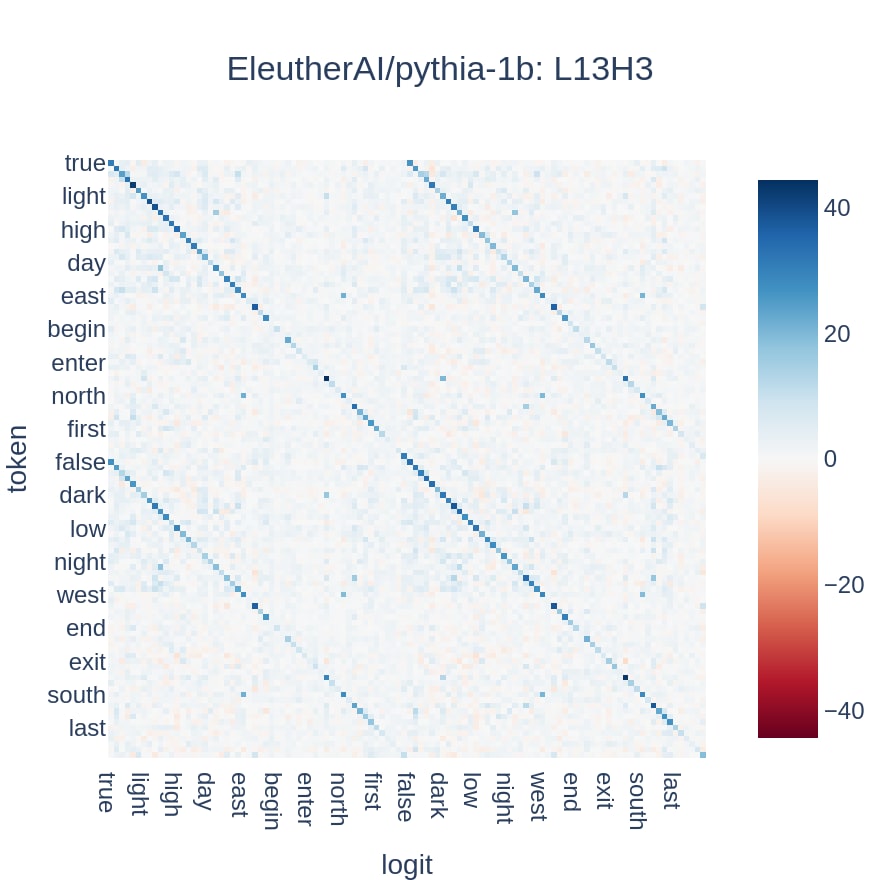
In addition to antonym heads, this methodology also uncovers "category induction" heads. These heads uniformly predict tokens belonging to the same category, whether they are synonyms or antonyms, and present with a triple-diagonal pattern:
Investigating Other Models
I studied a variety of model sizes and architectures ranging from 70 million to 3 billion parameters, and found that antonym heads were present in almost all of them. Out of the 13 models studied, 11 appear to contain antonym heads based on visual inspection. In the remaining 2 models, pythia-70m and pythia-160m, the top scoring heads appear to be category induction heads. An especially interesting antonym head is layer 15, head 3 of Pythia-2.8b, which appears to actively suppress the logit corresponding to the input token (a red line on the diagonal), while boosting logits for antonyms.
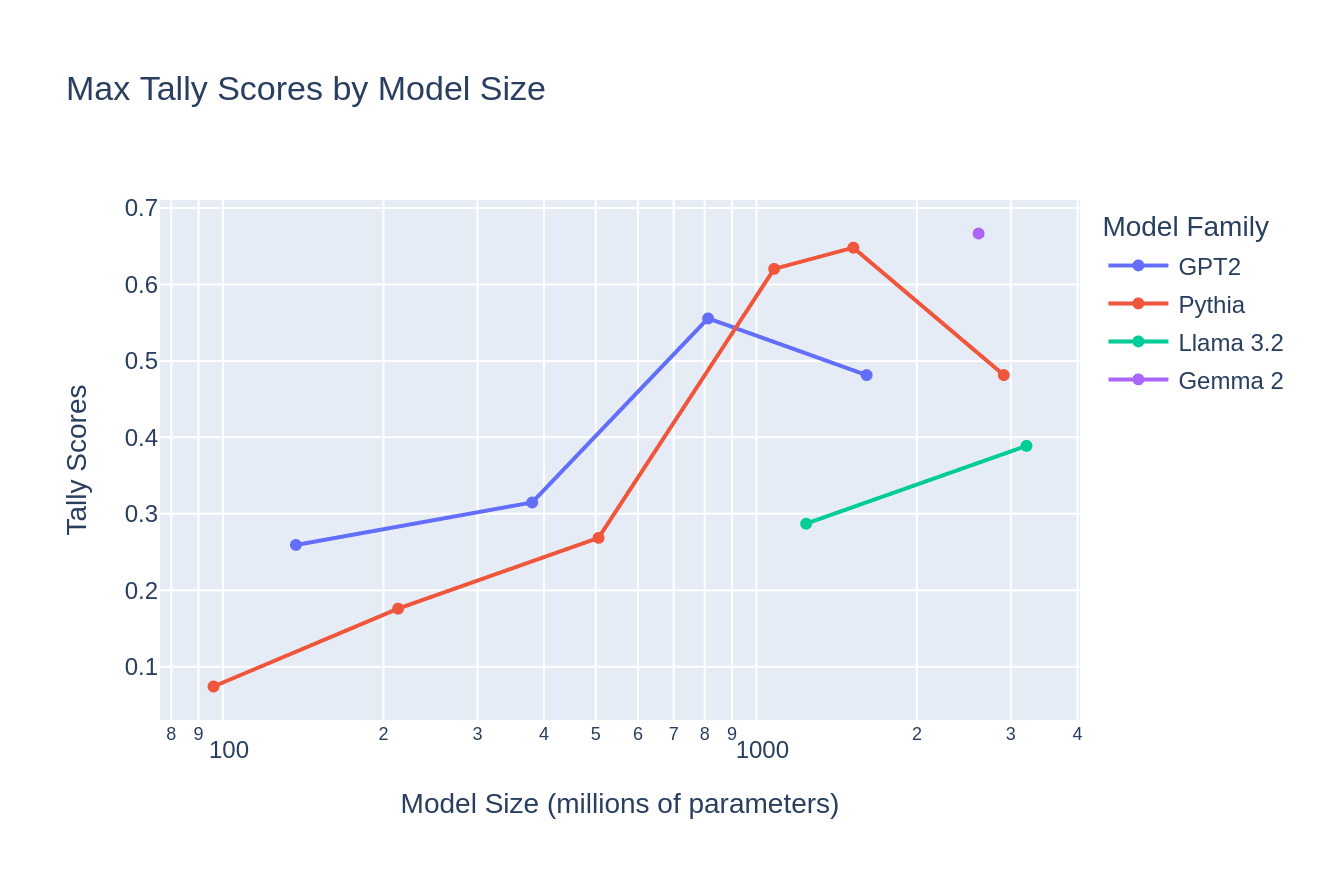
By graphing the tally score of each model's max-scoring head against model size, we can visualize how antonym heads develop as a function of model size. In general, larger models appear more likely to have high-tally-score antonym heads. The top heads for the largest studied models in the Pythia and GPT2 families have lower tally scores compared with their respective next-smallest models -- this is likely because these larger models are incorporating more inter-head composition, and rely on more than one head for computing antonyms.
Eigenvalue Analysis
Surprisingly, I find that identified antonym heads across all studied model sizes and architectures present similar patterns in their distributions of eigenvalues. Here is an illustrative example of this pattern, again using the antonym head in Pythia-1b:
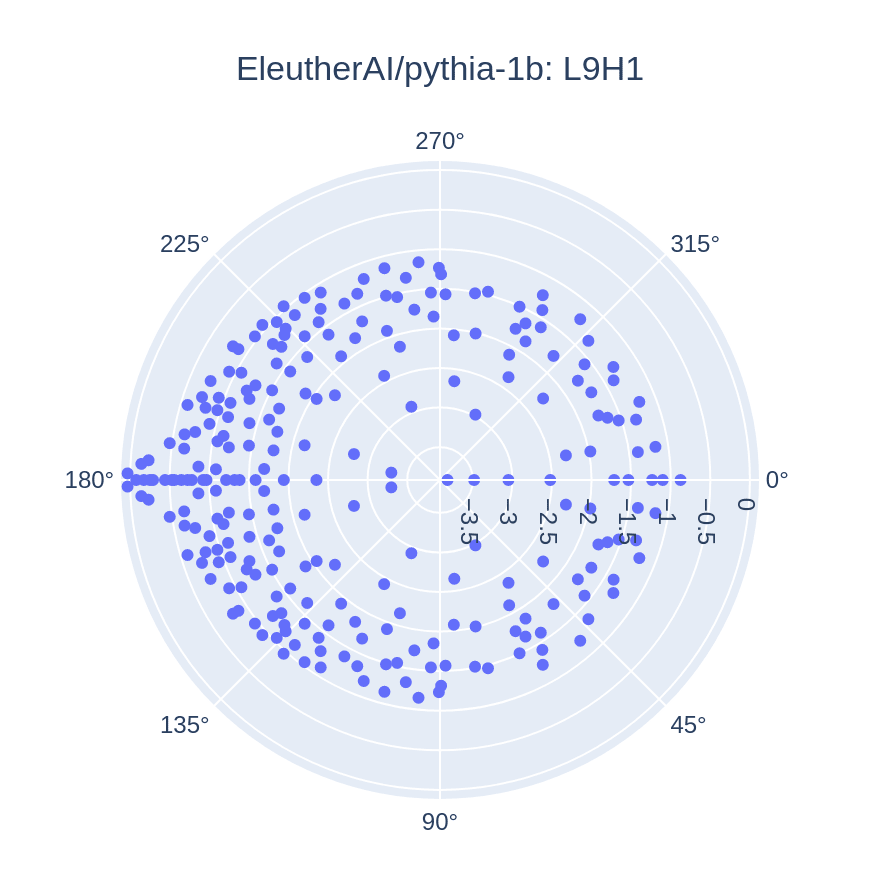
In this plot, we can see that the highest-magnitude eigenvalues have a negative real component and near-zero imaginary component. In transformation matrices (like the OV weight matrix), the real component of eigenvalues corresponds to scaling, and the imaginary component corresponds to rotation. I hypothesize that these high-magnitude, negative-real-component eigenvalues are responsible for doing semantic inversion when mapping an input token to it's semantic opposite -- they may represent directions in the embedding space which get inverted in order to compute antonyms. Interestingly, the log-magnitude of these eigenvalues is very close to zero, which means the absolute magnitude is close to 1, suggesting inversion without additional scaling. The remaining eigenvalues may correspond to copying category information (eg, "north" and "south" are opposite, but both cardinal directions), or transforming token embeddings from the embedding space to the unembedding space.
I did attempt to isolate these inverting directions and manipulate them directly to verify my hypothesis, but didn't get conclusive results[3]. It appears that these heads are also responsible for transforming embeddings from the embedding vector space to the unembedding space, which was not captured by my naive approach of isolating individual eigenvectors. More work could certainly be done here.
Plotting eigenvalues for all of the 13 studied models, we can see that top-scoring heads almost always present this same pattern, where the highest-magnitude eigenvalues have negative real components and nearly-zero imaginary components:
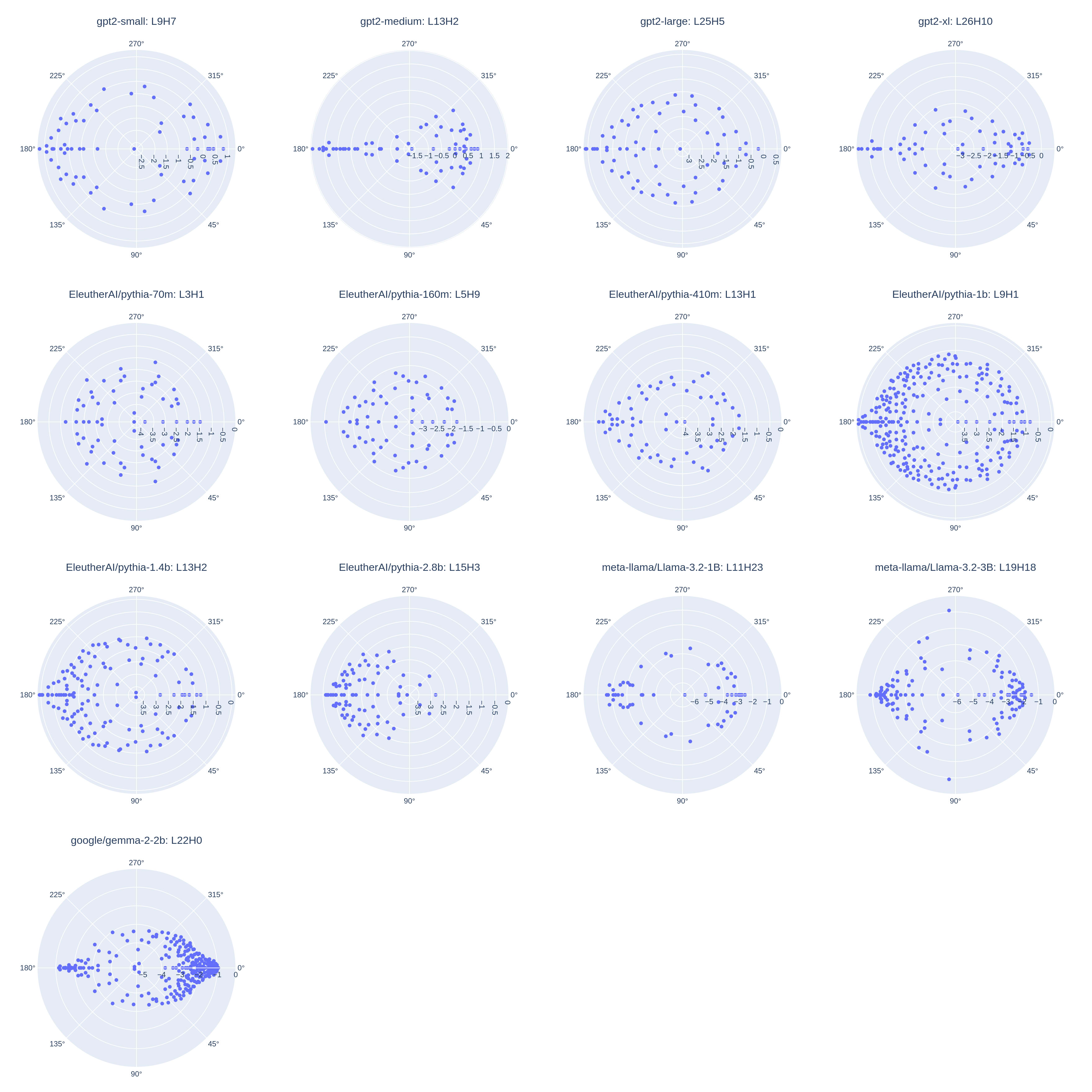
These patterns appear to be characteristic of antonym heads compared to a random sample of all heads:
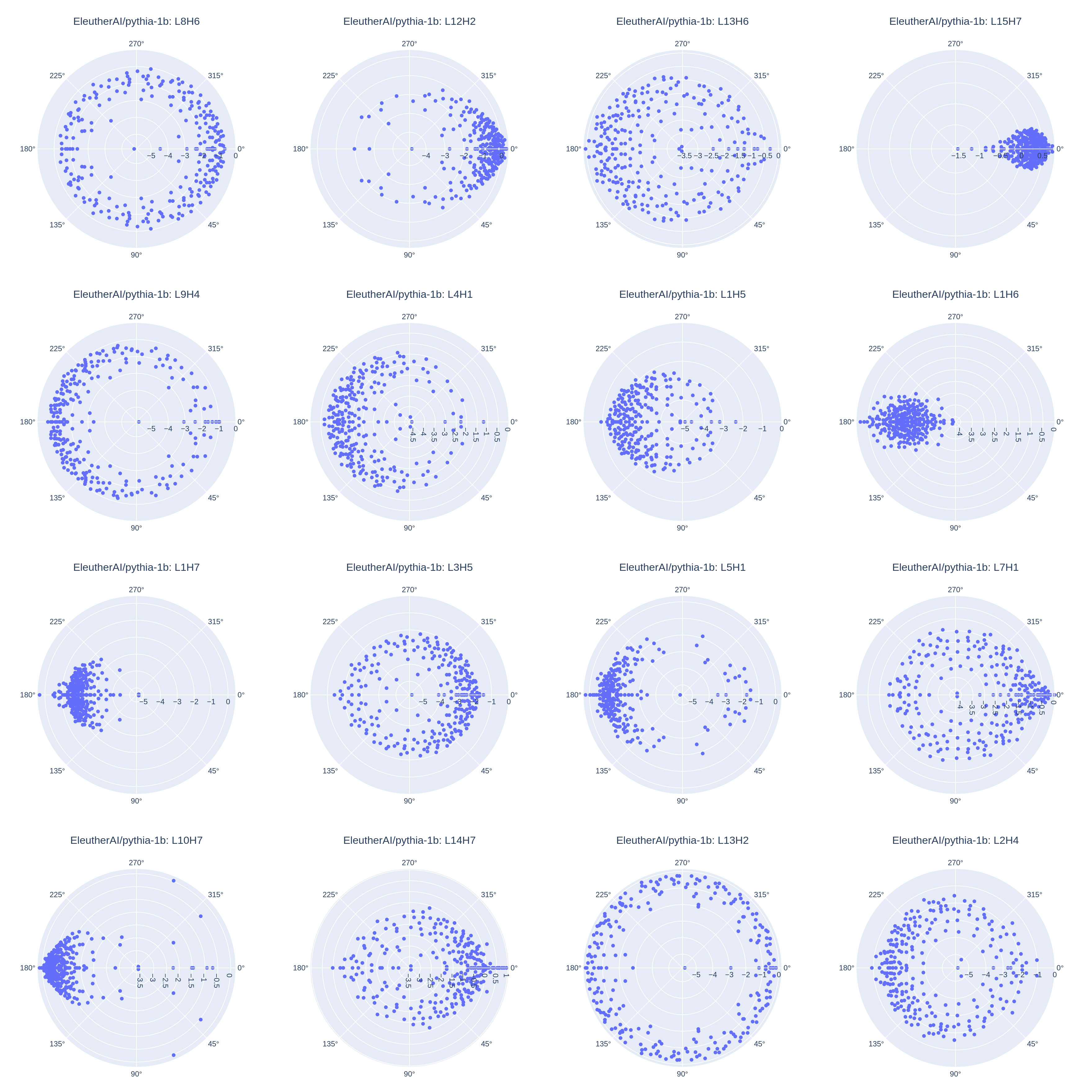
Indeed, the category-induction head from Pythia-1b which I pointed out earlier does not present this pattern:
Ablation Study
As noted in Anthropic's post, OV circuits do not tell the whole story of a head's effect on model outputs: heads with high tally scores might not attend to the tokens in the curated dataset, and heads with low tally scores might have significant contributions via indirect effects. I investigate this by mean-ablating each head individually, and observing the effect of this operation on the antonym-prediction task. To perform this task, I generate a text sequence using the same words in the original dataset, where antonyms immediately follow their complements, with pairs separated by a newline character:
<bos> true false\n hot cold\n tall short\n ...
I run a forward pass on this sequence, and compute average loss over every third token offset by one. This is done so that loss is only considered when the model is predicting the complement of a previous word, and loss is not considered for newline tokens or the first word in a pair, which is arbitrary. I run this ablation study for the four models with the highest-scoring antonym heads based on the tallying methodology.
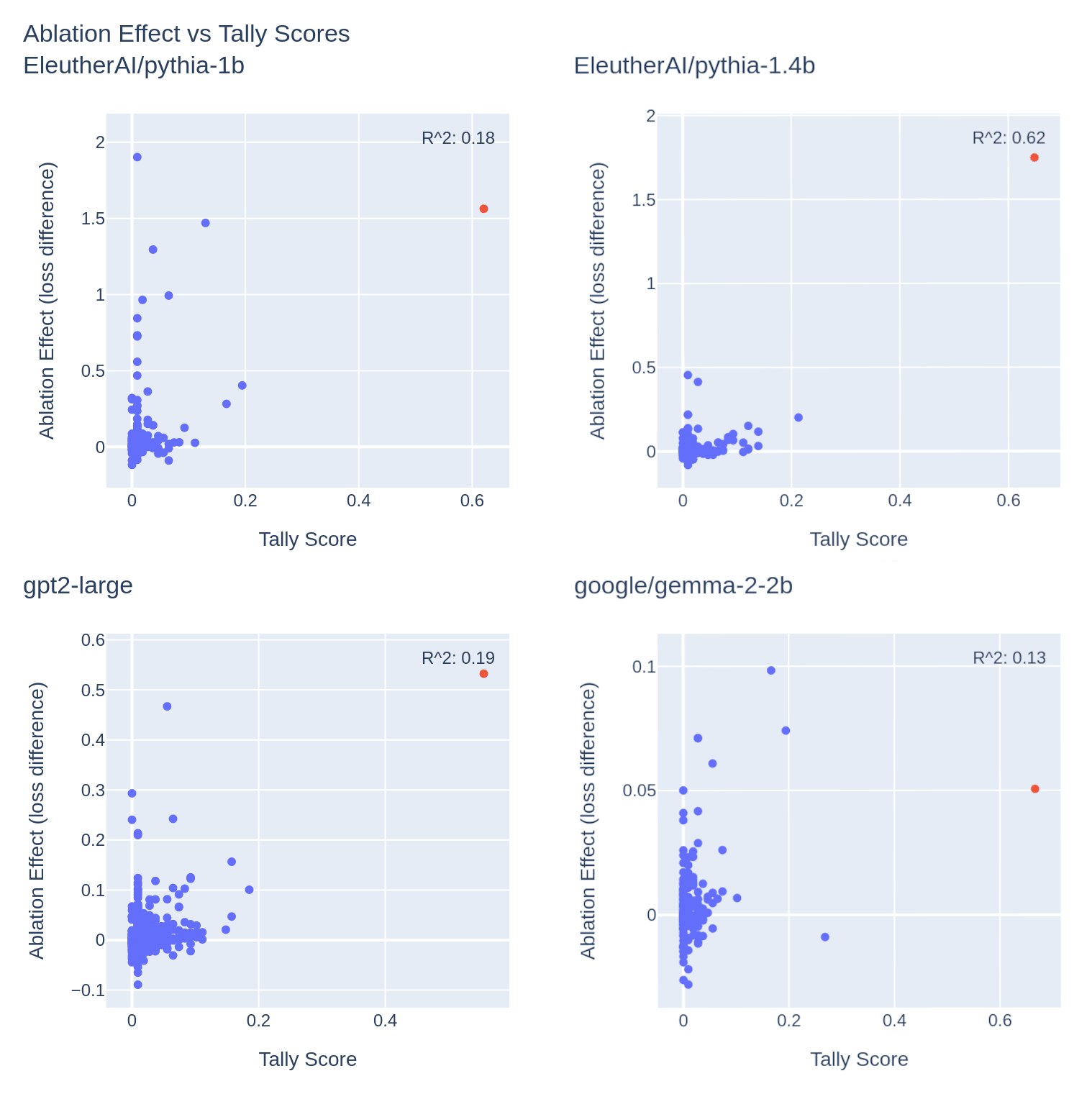
The highest-scoring head generally has a very high ablation effect, with the highest-scoring head having the highest ablation effect in 2 out of 4 of the studied models. I did not investigate what other top-scoring heads were doing, but they likely compose in some way to compute antonyms, or are responsible for in-context learning[4].
Conclusion
Antonym heads are responsible for computing semantic opposites in transformer language models, and appear to exist in a variety of different architectures and sizes from ~140 million parameters to at least 3 billion. I'm intrigued by the seemingly consistent and interpretable patterns in eigenvalues, and I think it would be interesting to explore the associated eigenvectors more to try to verify my hypothesis that the high-magnitude values are related to semantic inversion.
- ^
Each word is lowercase, with a prepended space:
" hot" - ^
Like Gould and Anthropic, I take embeddings after the first MLP output since it appears that the first block in transformer models is partially responsible for additional token embedding. I find experimentally that both the first MLP and the first attention block are necessary for creating usable embeddings.
- ^
Anecdotally, I do find that these directions are more likely to be inverted between word-antonym pairs compared with the directions of randomly sampled eigenvectors from the same head, but I have not studied this rigorously.
- ^
The models need to use ICL to uncover the pattern of <word> <opposite> <newline>.
0 comments
Comments sorted by top scores.